本文主要是介绍GO调度模型-GMP(上),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
进程、线程、协程
进程与线程
在学习与开发的过程中,总能听到与看到CPU、核数、 进程、 线程、并发、 并行等概念,这些文字相近但却不同的概念是否经常困扰自己,我们来捋一捋以便展开后续的深入学习。
首先来说说CPU,这个大家都懂吧,就是中央处理器。其功能主要是解释计算机指令以及处理计算机软件中的数据。CPU是计算机中负责读取指令,对指令译码并执行指令的核心部件。
我们常常说的这是一台单CPU 4核 8线程的电脑,这里面的核和线程是什么概念呢?
这里4核的核是指CPU有多个核心处理器(CORE核),是一个物理元件(也即可见可触及的实体),我们平时所讨论的单核多核也就是这个层面的核;
而8线程的线程指的是逻辑内核(THREAD逻辑处理器), 这是利用超线程技术将一个物理核心模拟为2个核心,这2个核心并不是物理上独立存在的电路,所以叫做逻辑核(逻辑处理器),但其之间共享物理核心的资源,需要注意的是:CPU线程跟程序里面的线程非一个概念。
了解完CPU、核数概念,现在来看看进程和线程的概念。
进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元。每个进程都有自己的独立空间,可以执行特定的工作。所以,进程可看做是正在执行的程序,即等于程序+执行状态。
可以把它想象成是你电脑上运行的一个应用程序,比如浏览器、文档编辑器、音乐播放器等。
每个进程都有**独立的虚拟地址空间 **(Linux会给每个进程分配一个虚拟内存空间,64位系统下,虚拟内存最大支持256T),有自己独立堆栈,让应用程序在这个独立的内存空间中运行, 上级挂靠单位是操作系统。操作系统会以进程为单位,分配系统资源(CPU时间片、内存等资源,内存、磁盘IO等),进程是资源分配的最小单位。
当前的CPU虽然都是已经实现了多核处理,但是程序运行的数量往往多倍于CPU核心数量,光光靠CPU并行处理已经不能满足性能需求,如果一个比较耗时间的程序在处理,就会让后面大量的程序排队等待着,哪怕后面的程序只需要一点点时间就能很快的执行完也必须等待着。
所以结合这个问题,就有了 时间片轮询平均调度分配方案,如图所示:
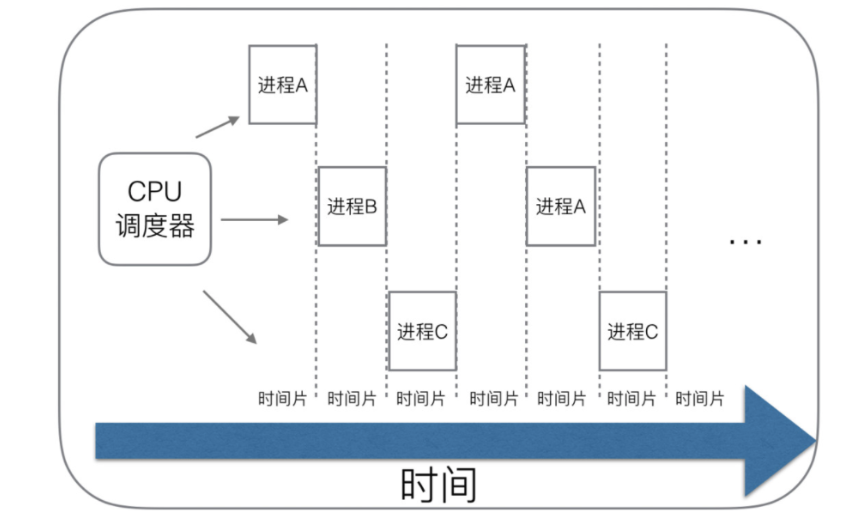
时间片轮转调度算法:每个进程被分配⼀个时间段,称为时间片,⼀般来说,时间片设为 20ms~50ms,即允许该进程在该时间段中运行:
- 如果当前运行进程的时间片用完了,立即让出
CPU给其他进程,如果该进程未执行完就放到就绪队列的队尾,重新等待时间片。 - 如果该进程在时间片结束前阻塞或结束,则
CPU立即进行切换
由于CPU以纳秒为单位的高速运转,在进程数量很少的情况下,一些程序的切换速度完全无法感知,所以看起来就跟很多程序一起运行完成一样。
但是每个进程的切换,成本是很大的,因为进程的切换是在内核态下,涉及到用户态与内核态互相切换问题,会有一个时间成本和性能开销,其中性能开销至少会有两个开销:
-
进程上下文切换,进程运行于用户态,然后因为系统调用或时间片耗尽切换到内核态执行指令,完成上下文切换后回到用户态,进程被切换。上下文主要包括寄存器、程序计数器、栈、虚拟内存地址、内核数据结构等。
-
硬件上下文切换
CPU基于进程的调度极大的提高了CPU的利用率,但是为了精益求精,我们发现基于进程的调度还是有改善的空间。因为CPU是基于进程切换的,一个进程工作时那么就意味着其他进程无法获得CPU资源。这样就好比我们在写word文档的时候就不能同时听着酷狗音乐了。 另外当一个进程任务执行一个IO时间较长的指令时,那些与IO无关系的操作也必须等待IO执行完才能执行。
所以我们的CPU选择了基于粒度更小的线程来调度执行任务。那就是线程,一个进程可以创建很多个线程来执行任务,没有了进程的界限区分,CPU会在线程之间来回切换的工作, CPU的时间片分的更细,以至他在多个线程之间切换执行,我们并没有明显的感知,这样的话我们多个进程也变得可以“同时”工作了,同时CPU等待IO的几率又更加小了。
线程是进程中的⼀个执⾏单元,是操作系统能够进行运算调度的最小单位。负责当前进程中程序的执⾏,⼀个进程中⾄少有⼀个线程。⼀个进程中是可以有多个线程的,这个应⽤程序也可以称之为多线程程序。
举个例子,多线程下载软件,可以同时运行多个线程,但是通过程序运行的结果发现,每一次结果都不一致。 因为多线程存在一个特性:随机性。造成的原因:**CPU在瞬间不断切换去处理各个线程而导致的,可以理解成多个线程在抢CPU资源。**如下图:

线程可以看做轻量级的进程,同一进程的线程共享本进程的地址空间和资源,每个线程都有自己独立的运行栈和程序计数器(PC),所以线程之间切换的开销小。
有个形象的比喻就是:进程好比是火车,线程好比是车厢(多线程):
| 对比项 | 进程 | 线程 |
|---|---|---|
| 定义 | 进程是程序运行的一个实体的运行过程,是系统进行资源分配和调配的一个独立单位 | 线程是进程运行和执行的最小调度单位 |
| 系统性能 | 创建撤销切换影响性能,资源要重新分配和收回 | 仅保存少量寄存器的内容,在进程的地址空间执行代码 |
| 拥有资产 | 资源拥有的基本单位 | 基本上不占资源,仅有不可少的资源(程序计数器,一组寄存器和栈) |
| 调度 | 资源分配的基本单位 | 独立调度分配的单位 |
| 安全性 | 进程间相互独立,互不影响 | 线程共享一个进程下面的资源,可以互相通信 |
| 地址空间 | 赋予的独立的内存地址空间 | 由相关堆栈寄存器和和线程控制表组成,寄存器可被用来存储线程内的局部变量 |
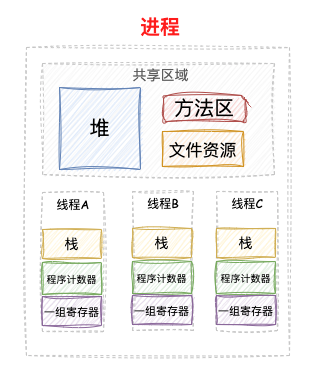
进程和线程关系图:
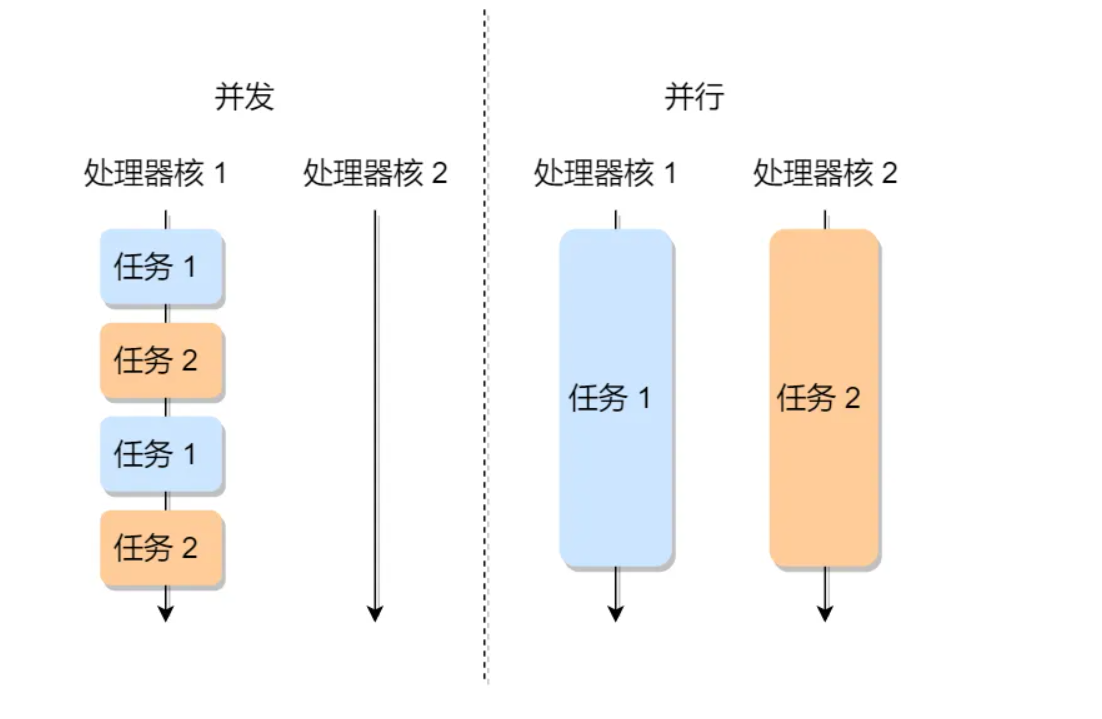
初步对进程和线程了解后,进入并发和并行两个重要概念,这两个概念与多任务处理相关,让我们用通俗易懂的语言来解释它们:
-
并发(Concurrency):并发是指在同一时间段内,多个任务交替执行,每个任务都有机会执行一部分,然后切换到下一个任务。这种切换速度非常快,以至于看起来好像多个任务都在同时进行。一般并发在单核
CPU上较为常见。举个例子:想象有一个邮局,里面有多个服务窗口,但只有一个邮政员,有很多人在邮局等着寄信,邮政员一次只能为一个人提供服务。那么,邮局中的顾客可以看起来是并发的,因为他们在等待并且轮流与邮政员交互,但实际上,在同一时刻只有一个顾客与邮政员互动。
-
并行(Parallelism):并行是指在同一时间段内,多个任务真正同时执行,每个任务都在不同的处理器或核心上独立运行。这意味着多个任务可以同时完成它们的工作。
举个例子:想象有一支田径队,队伍中有多名运动员,每个运动员都有自己的赛道。这些运动员在同一时间开始比赛,每个人在自己的赛道上独立奔跑。这就是并行,因为每个运动员都在不同的赛道上同时奔跑,互相不干扰。
并发和并行示意如图:
协程
用户级线程可称之为协程(co-routine)。什么是用户级线程呢?
用户级线程指的是通过线程库来实现线程的调度,线程库运行在用户空间中,不依赖于内核的实现,所以用户级线程(又被称之为协程)可以做到对内核无感知,内核不会参与用户级线程的调度和控制,操作系统仍对进程进行直接控制。
而Goroutine 是golang 实现的用户态、轻量级的协程。Goroutine具有以下特点:
- 相比线程,其启动的代价很小,以很小栈空间启动(
2Kb左右); - 能够动态地伸缩栈的大小,最大可以支持到
Gb级别; - 工作在用户态,切换成本很小;
- 与线程关系是
N:M,即可以在N个系统线程上多工调度M个Goroutine;
Goroutine由Go 运行时(runtime)管理,由golang自己实现的GMP调度 , 不依赖操作系统和其提供的线程,切换发生在用户态,在用户态没有时钟中断,系统调用等机制,因此效率高。
后续会重点介绍Goroutine,在此点到为止。
GMP调度模型数据结构
Golang为了减少操作系统内核级线程上下文切换的开销以及提升调度效率,提出了GPM协程调度模型,GPM模型借助了用户级线程的实现思路,通过用户态的协程调度,能够在线程上实现多个协程的并发执行。
GPM三个字母分别表示的是Goroutine、Processor及Machine:
- G(Goroutine):代表
Go协程Goroutine,通过Goroutine封装的代码片段将以协程方式并发执行,存储了Goroutine的执行栈信息、Goroutine状态以及Goroutine的任务函数等,是GPM调度器调度的基本单位。G的数量无限制,理论上只受内存的影响,创建一个G的初始栈大小为2-4K,配置一般的机器也能简简单单开启数十万个Goroutine; - M(Machine):
Go对操作系统线程(OS thread)的封装或者CPU核心(Machine),一个M与一个内核级线程一一对应,为Goroutine的执行提供了底层线程能力支持; - P(Processor):
P(Processor)是一个虚拟的执行线程或称为调度器,可以理解为Go程序的工作线程。P是Go语言运行时的逻辑处理器,它用于执行Goroutines。P负责调度Goroutines,并将它们分配到M上执行。P的数量决定了系统内最大可并行的G的数量,P的数量受本机的CPU核数影响,可通过环境变量$GOMAXPROCS或在runtime.GOMAXPROCS()来设置,默认为CPU核心数。
这边做个比喻: GMP 组合起来就像是一个高效的工厂,其中有许多工人(Goroutines)可以并行工作,由机器(Machine)执行任务,而主管(Processor)负责分配任务和管理工人。
GMP调度器示意图如下:
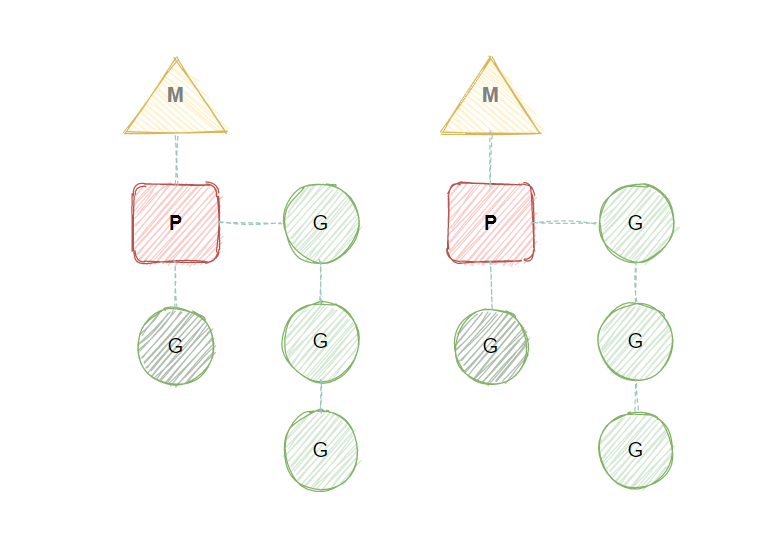
在这边我们将介绍一些比较重要的结构体,比如GMP调度中的G、 M、 P所对应的结构以及调度器的结构,这些结构体中会存在大量关于内存分配的字段或者结构,后续会在堆栈内存相关内容分析,这边聚焦在GMP调度的策略以及流程上。
G(Goroutine)
Goroutine 是 Go 语言调度器中待执行的任务,它在运行时调度器中的地位与线程在操作系统中差不多,但是它占用了更小的内存空间,也降低了上下文切换的开销。Goroutine 只存在于 Go 语言的运行时,它是 Go 语言在用户态提供的线程,作为一种粒度更细的资源调度单元,如果使用得当能够在高并发的场景下更高效地利用机器的 CPU。
Goroutine 是调度的最小单元。每个G都有一个指向调度函数的指针,并且可以被阻塞和唤醒。它包括了一个或多个栈以及它所需要的其他元数据信息。G的完整定义如下:
//go 1.20.3 path: /src/runtime/runtime2.go
type g struct {stack stack // 堆栈信息stackguard0 uintptr // 堆栈保护边界stackguard1 uintptr // 堆栈保护边界_panic *_panic // 异常信息_defer *_defer // 延迟执行的函数m *m // M的指针sched gobuf // 调度信息syscallsp uintptr // 系统调用堆栈指针syscallpc uintptr // 系统调用程序计数器stktopsp uintptr // 堆栈顶部指针param unsafe.Pointer // 参数atomicstatus atomic.Uint32 // 原子状态stackLock uint32 // 堆栈锁goid uint64 // Goroutine 的唯一标识符schedlink guintptr // 调度链接waitsince int64 // 等待开始时间waitreason waitReason // 等待原因preempt bool // 是否可以被抢占preemptStop bool // 是否已停止抢占preemptShrink bool // 是否可以缩小抢占asyncSafePoint bool // 是否在异步安全点paniconfault bool // 是否在故障时发生了 panicgcscandone bool // GC 扫描是否完成throwsplit bool // 是否抛出了分裂错误activeStackChans bool // 堆栈上是否有活跃的通道parkingOnChan atomic.Bool // 是否正在通道上停泊raceignore int8 // race 检测忽略标志sysblocktraced bool // 是否已追踪系统阻塞tracking bool // 是否正在跟踪trackingSeq uint8 // 跟踪序列trackingStamp int64 // 跟踪时间戳runnableTime int64 // 可运行时间sysexitticks int64 // 系统退出时间traceseq uint64 // 追踪序列tracelastp puintptr // 上一个 Plockedm muintptr // 加锁的 Msig uint32 // 信号writebuf []byte // 写缓冲区sigcode0 uintptr // 信号代码 0sigcode1 uintptr // 信号代码 1sigpc uintptr // 信号程序计数器gopc uintptr // Goroutine 的起始 PCancestors *[]ancestorInfo // 祖先信息startpc uintptr // 启动 PCracectx uintptr // 竞争上下文waiting *sudog // 等待的 sudog(同步队列结构)cgoCtxt []uintptr // Cgo 上下文labels unsafe.Pointer // 标签timer *timer // 定时器selectDone atomic.Uint32 // 选择完成标志goroutineProfiled goroutineProfileStateHolder // Goroutine 分析状态gcAssistBytes int64 // GC 辅助字节数
}我们整理一些核心的字段来解析下:
-
stack :该字段储存了当前协程(
G)的栈,字段类型为stack结构体,定义如下://go 1.20.3 path: /src/runtime/runtime2.go type stack struct {lo uintptr // 栈顶,低地址hi uintptr // 栈底,高地址 }其栈内存范围为 [
stack.lo,stack.hi),G的执行代码就在该内存范围的用户栈上执行的。需要注意的是:m0绑定的g0是在进程被分配的系统栈上分配协程栈的,而其他协程栈都是在堆上进行分配的。 -
stackguard0 与 stackguard1: 主要用于检查栈空间是否足够的值, 低于这个值会扩张栈。如果
stackguard0字段被设置成StackPreempt意味着当前Goroutine发出了抢占请求; -
m:负责执行当前
G的M,或者说是当前G绑定的M; -
goid:协程
id,每个协程都有一个唯一的id,该字段对开发者不可见; -
lockedm: 如果该值为正常的指针地址,则表示该
G被锁定只能在这个M运行; -
sched:存储
Goroutine的调度相关的数据(协程执行的上下文信息),其结构为gobuf,如下://go 1.20.3 path: /src/runtime/runtime2.go type gobuf struct {sp uintptr // 堆栈指针(Stack Pointer),代表cpu的rsp寄存器的值,永远指向栈顶位置pc uintptr // 程序计数器(Program Counter),表示将要执行的指令的地址g guintptr // Goroutine 的指针,表示相关联的 Goroutinectxt unsafe.Pointer // 上下文指针,可以包含一些额外的执行信息ret uintptr // 返回地址,表示函数执行完成后应该返回的地址lr uintptr // 链接寄存器(Link Register),在函数调用中用于保存返回地址bp uintptr // 基址指针(Base Pointer),通常用于栈帧操作 }这个结构体主要用于表示
Goroutine的执行上下文,其中包含了当前堆栈指针、程序计数器、Goroutine指针以及一些与执行相关的其他信息。这些字段共同组成了Goroutine的状态,用于实现Goroutine的切换和执行。这在Go语言的调度和并发执行中起到关键作用。 -
startpc :
goroutine函数的指令地址; -
atomicstatus: 当前
G的状态值,状态值定义为://go 1.20.3 path: /src/runtime/runtime2.go const (_Gidle = iota // 值为0,表示刚刚被分配并且还没有被初始化_Grunnable // 值为1,表示等待被执行,正存储在待执行队列中_Grunning // 值为2,表示正在被执行,被赋予了内核线程M和处理器P了_Gsyscall // 值为3,表示正在执行系统调用,_Gwaiting // 值为4,表示协程处于挂起态,需要等待被唤醒,gc、channel通信或者锁操作时经常会进入这种状态_Gdead // 值为6,表示协程刚初始化完成或者已经被销毁_Gcopystack // 值为8,表示协程正在栈扩容流程中_Gpreempted // 值为9,表示协程被抢占后的状态......}上述状态中比较常见是
_Grunnable、_Grunning、_Gsyscall、_Gwaiting和_Gpreempted五个状态,我们用一张图来表示goroutine状态流转图: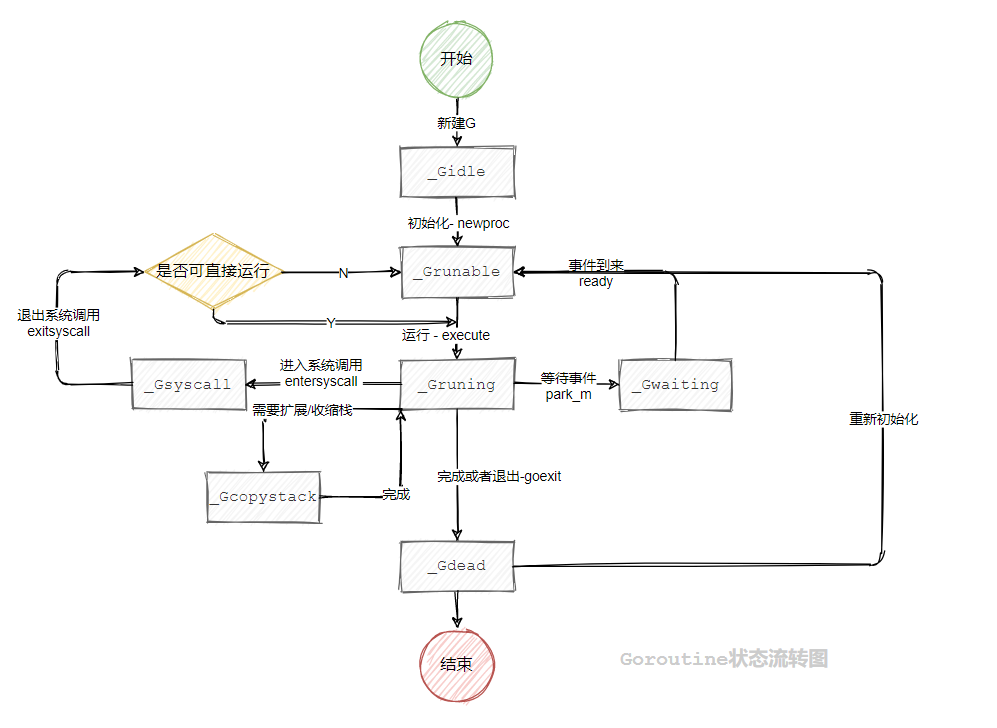
-
preempt:当前
G是否可抢占。
M(Machine)
在 Golang 中,M 指的是 Machine,表示操作系统中的一个线程。M 由 Go 运行时管理,可以看做是执行 Go 代码的内核线程。它们与操作系统线程是一一对应的。每个 M 都拥有自己的堆栈空间,以及寄存器等 CPU 状态,可以并行执行 Go 代码。
在默认情况下,运行时会将 GOMAXPROCS 设置成当前机器的核数,我们也可以在程序中使用 runtime.GOMAXPROCS 来改变最大的活跃线程数:
//go 1.20.3
func GOMAXPROCS(n int) int //GOMAXPROCS函数原型
runtime.GOMAXPROCS(5) //设置当前机器的核数为5
在默认情况下,一个四核机器会创建四个活跃的操作系统线程,每一个线程都对应一个运行时中的 runtime.m结构体:
//go 1.20.3 path: /src/runtime/runtime2.go
type m struct {g0 *g // 主协程(Goroutine),成为G0morebuf gobuf // 额外的执行上下文divmod uint32 // 除法和求余的中间结果_ uint32 // 未使用的字段procid uint64 // 进程 IDgsignal *g // 用于信号处理的 GoroutinegoSigStack gsignalStack // 信号处理栈sigmask sigset // 信号掩码tls [tlsSlots]uintptr // 线程本地存储mstartfn func() // M 启动函数curg *g // 当前 Goroutinecaughtsig guintptr // 捕获的信号p puintptr // P(处理器)的指针nextp puintptr // 下一个 P 的指针oldp puintptr // 旧的 P 的指针id int64 // M 的唯一标识符mallocing int32 // 内存分配中的标志throwing throwType // 抛出异常类型preemptoff string // 抢占关闭标志locks int32 // 锁计数dying int32 // 正在退出标志profilehz int32 // 性能分析频率spinning bool // 是否正在自旋blocked bool // 是否被阻塞newSigstack bool // 是否使用新的信号栈printlock int8 // 打印锁incgo bool // 是否增加 CGO 调用计数isextra bool // 是否是额外的 MfreeWait atomic.Uint32 // 等待释放的标志fastrand uint64 // 快速随机数needextram bool // 是否需要额外的 Mtraceback uint8 // 跟踪标志ncgocall uint64 // CGO 调用计数ncgo int32 // CGO 调用计数cgoCallersUse atomic.Uint32 // CGO 调用者使用标志cgoCallers *cgoCallers // CGO 调用者park note // 停泊标记alllink *m // 所有 M 链接schedlink muintptr // 调度链接lockedg guintptr // 锁定的 Goroutinecreatestack [32]uintptr // 创建栈lockedExt uint32 // 扩展锁定标志lockedInt uint32 // 内部锁定标志nextwaitm muintptr // 下一个等待的 Mwaitunlockf func(*g, unsafe.Pointer) bool // 等待解锁函数waitlock unsafe.Pointer // 等待的锁waittraceev byte // 等待跟踪事件waittraceskip int // 等待跟踪跳过startingtrace bool // 启动跟踪标志syscalltick uint32 // 系统调用时钟freelink *m // 空闲 M 链接libcall libcall // 库调用libcallpc uintptr // 库调用程序计数器libcallsp uintptr // 库调用堆栈指针libcallg guintptr // 库调用 Goroutinesyscall libcall // 系统调用vdsoSP uintptr // VDSO 堆栈指针vdsoPC uintptr // VDSO 程序计数器preemptGen atomic.Uint32 // 抢占计数signalPending atomic.Uint32 // 信号挂起计数dlogPerM // 调试日志mOS // 操作系统相关信息locksHeldLen intlocksHeld [10]heldLockInfo
}这个结构体用于表示 Go 语言的 M的状态和属性,其中包含了与 M 相关的各种信息,如线程状态、锁状态、调度信息、信号处理等。这些字段用于管理和控制 M 的执行和状态。这在 Go 语言的并发、调度和系统调用等方面发挥着关键作用。
下列是其中比较重要的字段:
- g0: 主协程(
Goroutine),我们称为g0。这是一个持有调度栈的Goroutine, 是一个比较特殊的Goroutine, 它深度参与运行时的调度过程。每当用户协程需要重新调度的时候(退出或被抢占),m上的 运行的curg就会切换成g0,完成调度后,再切换成curg; - curg:当前
M执行的goroutine; - p:当前
M所、绑定的P; - tls:线程的本地存储, 代表每个线程的中的本地数据,存储内容只对当前线程可见;
m.tls[0]存储的是当前运行的g,因此线程可以通过g找到当前的m、p、g0等信息; - mstartfn:
M起始函数,即代码中go携带的函数curg *g。
P(Processor)
在 Go 的并发模型中,P(Processor)是一个虚拟的执行线程,可以理解为 Go 程序的工作线程。P 是 M 和 Goroutine 的中间层,它能提供线程需要的上下文环境,也会负责调度线程上的等待队列,通过处理器 P 的调度,每一个内核线程都能够执行多个 Goroutine,它能在 Goroutine 进行一些 I/O 操作时及时让出计算资源,提高线程的利用率。
因为调度器在启动时就会创建 GOMAXPROCS 个处理器,所以 Go 语言程序的处理器P数量一定会等于 GOMAXPROCS,这些处理器会绑定到不同的内核线程上。
runtime.p是处理器的运行时表示,作为调度器的内部实现,它包含的字段也非常多,其中包括与性能追踪、垃圾回收和计时器相关的字段,这些字段也非常重要,但我们主要关注P中的线程和运行队列:
//go 1.20.3 path: /src/runtime/runtime2.go
type p struct {id int32 // P 的唯一标识符status uint32 // P 的状态标志link puintptr // P 链接,用于构建一个 P 的链表结构schedtick uint32 // 调度时钟syscalltick uint32 // 系统调用时钟sysmontick sysmontick // 系统监视时钟m muintptr // 当前持有P的M的指针mcache *mcache // P 的本地内存分配缓存pcache pageCache // 页面分配和管理的缓存raceprocctx uintptr // 竞争处理上下文deferpool []*_defer // 延迟函数池deferpoolbuf [32]*_defer // 延迟函数池缓冲区goidcache uint64 // Goroutine ID 缓存goidcacheend uint64 // Goroutine ID 缓存结束runqhead uint32 // 运行队列头runqtail uint32 // 运行队列尾runq [256]guintptr // 运行队列runnext guintptr // 下一个运行的 GoroutinegFree struct { // 空闲 Goroutine 列表gListn int32}sudogcache []*sudog // sudog 缓存sudogbuf [128]*sudog // sudog 缓存缓冲区mspancache struct { // mspan 缓存len intbuf [128]*mspan}tracebuf traceBufPtr // 跟踪缓冲区traceSweep bool // 跟踪扫描标志traceSwept, traceReclaimed uintptr // 跟踪扫描计数palloc persistentAlloc // 持久分配器timer0When atomic.Int64 // 计时器 0 的触发时间timerModifiedEarliest atomic.Int64 // 最早的计时器修改时间gcAssistTime int64 // GC 辅助时间gcFractionalMarkTime int64 // 分数标记时间limiterEvent limiterEvent // 限制器事件gcMarkWorkerMode gcMarkWorkerMode // GC 标记工作模式gcMarkWorkerStartTime int64 // GC 标记工作开始时间gcw gcWork // GC 工作wbBuf wbBuf // 写屏障缓冲runSafePointFn uint32 // 运行安全点函数标志statsSeq atomic.Uint32 // 统计序列timersLock mutex // 计时器锁timers []*timer // 计时器列表numTimers atomic.Uint32 // 计时器数量deletedTimers atomic.Uint32 // 已删除的计时器数量timerRaceCtx uintptr // 计时器竞争上下文maxStackScanDelta int64 // 最大堆栈扫描差值scannedStackSize uint64 // 已扫描的堆栈大小scannedStacks uint64 // 已扫描的堆栈数preempt bool // 抢占标志pageTraceBuf pageTraceBuf // 页面跟踪缓冲
}
这个结构体用于表示 Go 语言的 P(处理器)的状态和属性,其中包含了与 P 相关的各种信息,如调度队列、堆栈扫描、GC(垃圾回收)辅助、信号处理等。这些字段用于管理和控制 P 的执行和状态,以及与 Goroutine 调度和运行相关的操作。
下列是其中比较重要的字段:
-
id:P的唯一标识符;
-
m: 当前与
P关联的M; -
mcache:这是每个
P的本地内存分配缓存。在并发程序中,每个P都有一个专用的mcache,用于减少内存分配的锁竞争和提高内存分配性能。mcache包含了一些数据结构,用于快速分配和释放小对象(小于等于32KB)的内存块。通过减少锁竞争,它可以显著提高程序的性能; -
pcache:用于页面分配和管理的缓存。在
Go中,每个P都有一个专用的pcache,它用于减少在分配和回收内存页面时的锁竞争。pcache中包含了一些数据结构,用于管理内存页面,从而提高了内存分配和回收的效率; -
runq:它表示了
P(处理器)上的运行队列。这是一个长度是固定的,通常为256个元素的数组(循环队列),但可以根据Go运行时的配置进行调整。当一个Goroutine准备好执行时,它将被放入p.runq中的某个位置,等待被调度执行。Go调度器会从这个队列中选择一个Goroutine并将其分配给P来执行。这样,多个Goroutines可以并发地在多个处理器上执行; -
runqhead、runqtail、runnext:
runqhead表示队列的开头,runqtail表示队列的末尾,runnext表示下一个需要执行的Goroutine。runqhead和runqtail模拟了一个循环队列, 将goroutine放入本地队列时,从末尾插入,头部获取; -
gFree : 表示
P(处理器)上的空闲Goroutine列表。gFree.gList是一个链表结构,用于链接所有空闲的Goroutines,当一个Goroutine执行完任务后,它可以加入到p.gFree链表中,以便稍后重用。这减少了创建和销毁Goroutines的开销,提高了程序的性能。gFree.n: 这是一个整数,表示当前P上空闲Goroutine的数量。通过n,Go调度器可以快速了解P上的可用Goroutine数量,以便在需要时将它们分配给新的任务。
-
status:表示P的状态,其被定义为五种状态://go 1.20.3 path: /src/runtime/runtime2.go const (_Pidle = iota //当前p尚未与任何m关联,处于空闲状态_Prunning //当前p已经和m关联,并且正在运行g代码_Psyscall //当前p正在执行系统调用_Pgcstop //当前p需要停止调度,一般在GC前或者刚被创建时_Pdead //当前p已死亡,不会再被调度 )同样用张流转图来表示这些状态的转变:
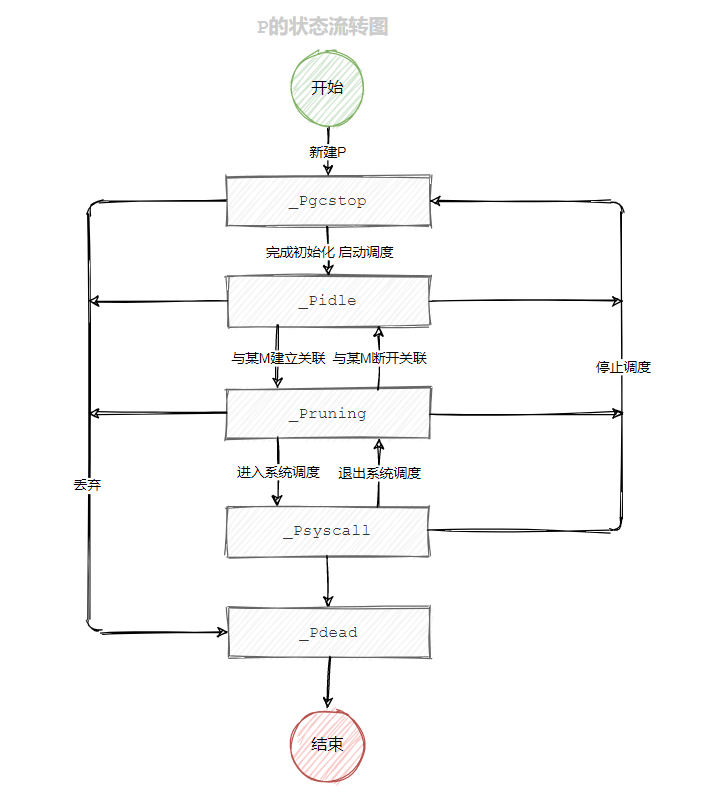
在
P创建之初,会被置为Pgcstop状态,在完成初始化之后,会马上进入Pidel状态,进入该状态后的P可被调度器调度,当P与某个M相关联时,会进入到Prunning状态,当其执行系统调用时,会进入到Psyscall状态,当P应为全局P列表的缩小而被删除时会进入Pdead状态,不会再进行状态流转和调度。当正在执行的P由于某些原因停止调度时,会统一流转成Pidle空闲状态,等待调度,避免线程饥饿。
schedt
有了G、 M 、P就可以完成用户态的协程的功能性工作了,但是要让他们完美的融合在一起工作,则需要一个调度者,我们叫它GPM调度器(schedt),它可以看做是一个全局的调度者,保存了调度器的状态信息、全局可运行G队列。
我们来看看它的结构定义:
//go 1.20.3 path: /src/runtime/runtime2.go
type schedt struct {goidgen atomic.Uint64 // 用于生成 Goroutine ID 的计数器lastpoll atomic.Int64 // 上一次轮询的时间戳pollUntil atomic.Int64 // 下一次轮询的时间戳lock mutex // 用于对 schedt 结构进行互斥访问的锁midle muintptr // 存储空闲的 M(机器)的指针nmidle int32 // 空闲 M 的数量nmidlelocked int32 // 空闲 M 中被锁定的数量mnext int64 // 下一个 M 的标识maxmcount int32 // 最大允许的 M 数量nmsys int32 // 系统级 M 的数量nmfreed int64 // 释放的 M 数量ngsys atomic.Int32 // 系统级 G 的数量pidle puintptr // 存储空闲的 P(处理器)的指针npidle atomic.Int32 // 空闲 P 的数量nmspinning atomic.Int32 // 自旋中的 M 的数量needspinning atomic.Uint32 // 需要自旋的标志runq gQueue // 运行队列,存储等待执行的 Goroutinesrunqsize int32 // 运行队列的大小disable struct {user bool // 用户级禁用标志runnable gQueue // 存储可运行 Goroutines 的队列n int32 // 可运行 Goroutines 的数量}gFree struct {lock mutex // 用于对 gFree 结构的互斥访问的锁stack gList // 存储有堆栈的空闲 GoroutinesnoStack gList // 存储没有堆栈的空闲 Goroutinesn int32 // 空闲 Goroutines 的数量}sudoglock mutex // 用于对 sudog 结构的互斥访问的锁sudogcache *sudog // sudog 缓存deferlock mutex // 用于对 defer 结构的互斥访问的锁deferpool *_defer // defer 缓存freem *m // 已经释放的 m gcwaiting atomic.Bool // 垃圾回收等待标志stopwait int32 // 停止等待标志stopnote note // 停止通知sysmonwait atomic.Bool // 系统监控等待标志sysmonnote note // 系统监控通知safePointFn func(*p) // 安全点函数safePointWait int32 // 安全点等待标志safePointNote note // 安全点通知profilehz int32 // 性能分析频率procresizetime int64 // 处理器调整时间totaltime int64 // 总执行时间sysmonlock mutex // 用于对 sysmon 操作的互斥访问的锁timeToRun timeHistogram // 时间直方图idleTime atomic.Int64 // 空闲时间totalMutexWaitTime atomic.Int64 // 总的互斥等待时间
}
下列是其中比较重要的字段:
- midle:指向空闲的
M链的指针; - nmidle:空闲的
M链的数量; - pidle:指向空闲的
P(处理器)的指针; - npidle:空闲的
P链的数量; - runq : 是一个
gQueue类型的字段,表示等待执行的Goroutines的全局运行队列,队列存储着runnable状态的G,当p的本地运行队列满了时会将G放入该队列中。gQueue用于维护一组Goroutines,它们等待被调度器分配到处理器上执行; - gFree:用于维护空闲全局的
Goroutine列表。空闲的Goroutines是已经执行完任务或者被休眠的Goroutines,它们可以被重新使用以执行新的任务,以减少 Goroutine 的创建和销毁开销。
注意: schedt.runq 与 p.runq 、schedt.gFree 与 p.gFree是不同的,p.gFree、p.runq对应的都是指向P独有的队列,而schedt.gFree、schedt.runq对应的全局队列。
schedt结构还包括以下几个重要字段,用来串行运行时任务执行前后的辅助协调,这些字段都与 Go 语言的垃圾回收(Garbage Collection)和调度有关:
| 字段名 | 数据类型 | 简述 |
|---|---|---|
| gcwaiting | uint32 | 是否有垃圾回收正在等待执行 |
| stopwait | int32 | 用于记录等待停止的 Goroutines 数量 |
| stopnote | note | 一个通知对象,用于协调 Goroutines 停止执行 |
| sysmonwait | uint32 | 是否有系统监控等待执行的标志 |
| sysmonnote | note | 一个通知对象,用于与系统监控(sysmon)相关的协调 |
这些字段后续再GC文章中细细分析,此处点到为止。
全局变量
除了GMP 和schedt这些结构体外,有一些存储g、m、p的重要全局变量,定义如下:
//go 1.20.3 path: /src/runtime/runtime2.go
var (allm *mgomaxprocs int32ncpu int32sched schedtnewprocs int32allpLock mutexallp []*p....
)//go 1.20.3 path: /src/runtime/runtime.go
var (allgs []*g....
)
- allm:全局的
M列表,指向保存了所有的M的一个单链表对象头指针; - allp: 全局的
P列表,存储着所有的P的数组; - allgs : 全局的
G列表,存储着所有的G的数组; - sched : 调度器结构体对象,记录了调度器的工作状态,对应的是上面的
schedt结构体; - ncpu:
CPU的核数,程序启动时会调用osinit获取ncpu值; - gomaxprocs:
P的允许最大数量,默认等于CPU核心数量。
下面将GMP中一些重要的队列以及数组列举下:
| 名称 | 变量 | 作用域 | 简介 |
|---|---|---|---|
| 全局M列表 | runtime.allm | 运行时系统 | 存放所有m的一个单向链表 |
| 全局P列表 | runtime.allp | 运行时系统 | 存放所有p的一个数组 |
| 全局G列表 | runtime.allgs | 运行时系统 | 存放所有g的一个数组 |
| 调度器空闲M列表 | runtime.sched.midle | 调度器 | 存放空闲M的一个单向链表 |
| 调度器空闲P列表 | runtime.sched.pidle | 调度器 | 存放空闲P的一个单向链表 |
| 调度器的可运行G队列 | runtime.sched.runqhead runtime.sched.runqtail | 调度器 | 存放可运行G的一个队列 |
| 调度器的自由G队列 | runtime.sched.gfreeStack runtime.sched.gfreeNoStack | 调度器 | 存放自由G的两个单向链表 |
| P上空闲G列表 | runtime.p.gFree | P | P上空闲的Goroutine 链表 |
| 调度器上空闲G列表 | runtime.sched.gFree | 调度器 | 调度器上空闲的Goroutine 链表 |
这些重要的队列以及数组将在后续的GMP策略以及流程中会频繁提及,这里先给出,后续使用到再进行进一步的说明。
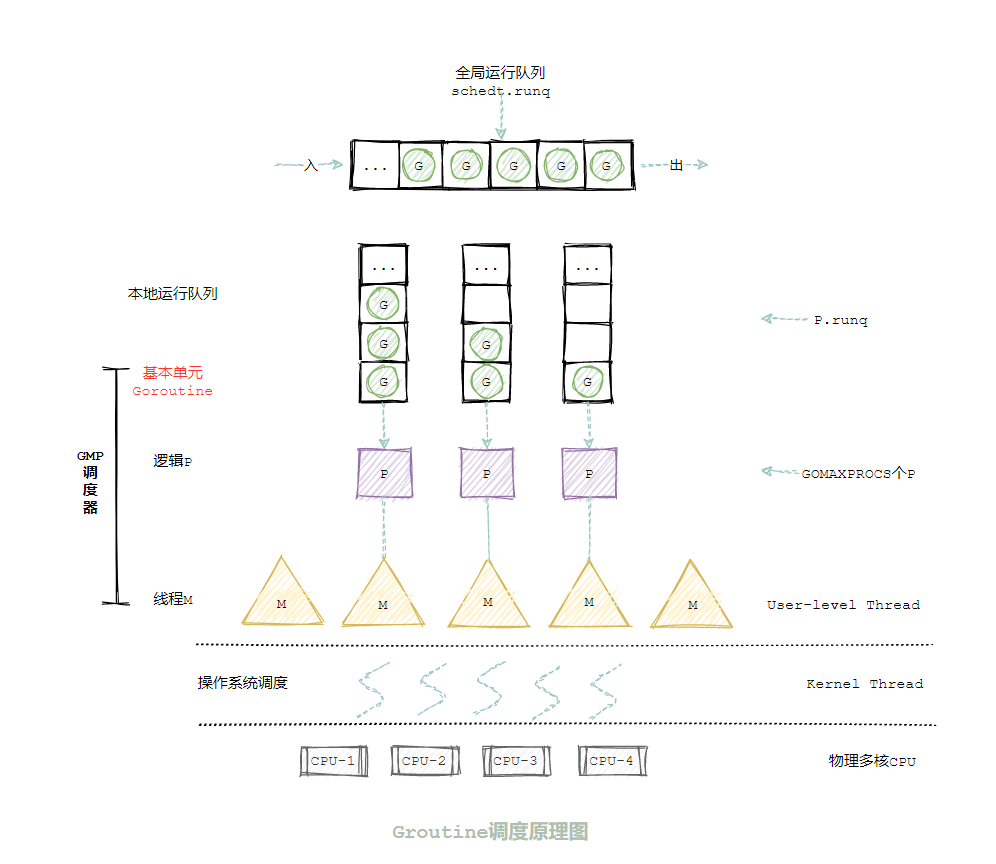
最后用一张图来总结下GMP以及全局运行队列 本地运行队列之间的关系:
程序启动流程
经过上面的介绍,我们大致知道了GMP调度中的的几个主要结构体,大致了解了这些结构体起的作用,但是它们是如何创建,如何绑定在一起的呢?
下面我们会通过这个章节从程序启动的流程开始,一起了解什么是m0、 g0以及结构体g 、m、 p 以及调度器schedt是的初始化的,以及各个结构体的关联绑定。
我们知道Go程序需要经过编译链接成可执行程序才能到指定平台上运行,经过 go build 操作会在比如在windows下生成.exe可执行程序以及在 linux 平台上生成 ELF 格式可执行文件。
在本文中我会从 ELF 可执行文件的入口讲起,讲到 GMP 调度器的初始化,到主协程的创建,到主协程进入 runtime.main 最后执行到用户定义的 main 函数。
程序入口
我们通过一个最简单的hello world例子来说明吧,代码如下:
package mainimport "fmt"func main() {fmt.Println("hello world")
}
运行起来结果如下:
# go build main.go
# ./main
hello world
程序是跑起来了,但是问题来了。传说中的协程究竟长什么样子,是何时被创建的,又是如何被加载运行并打印出 hello world 的呢?
不管是啥语言编译出来的可执行文件,都有一个执行入口点。我们使用 gdb 调试工具来查找这个入口。
执行gdb main,进入gdb程序调试交互窗口,输入 info files找到程序的入口地址=> Entry point: 0x45e4a0,在此地址上打上断点: b *0x45e4a0,最后执行r,如图:
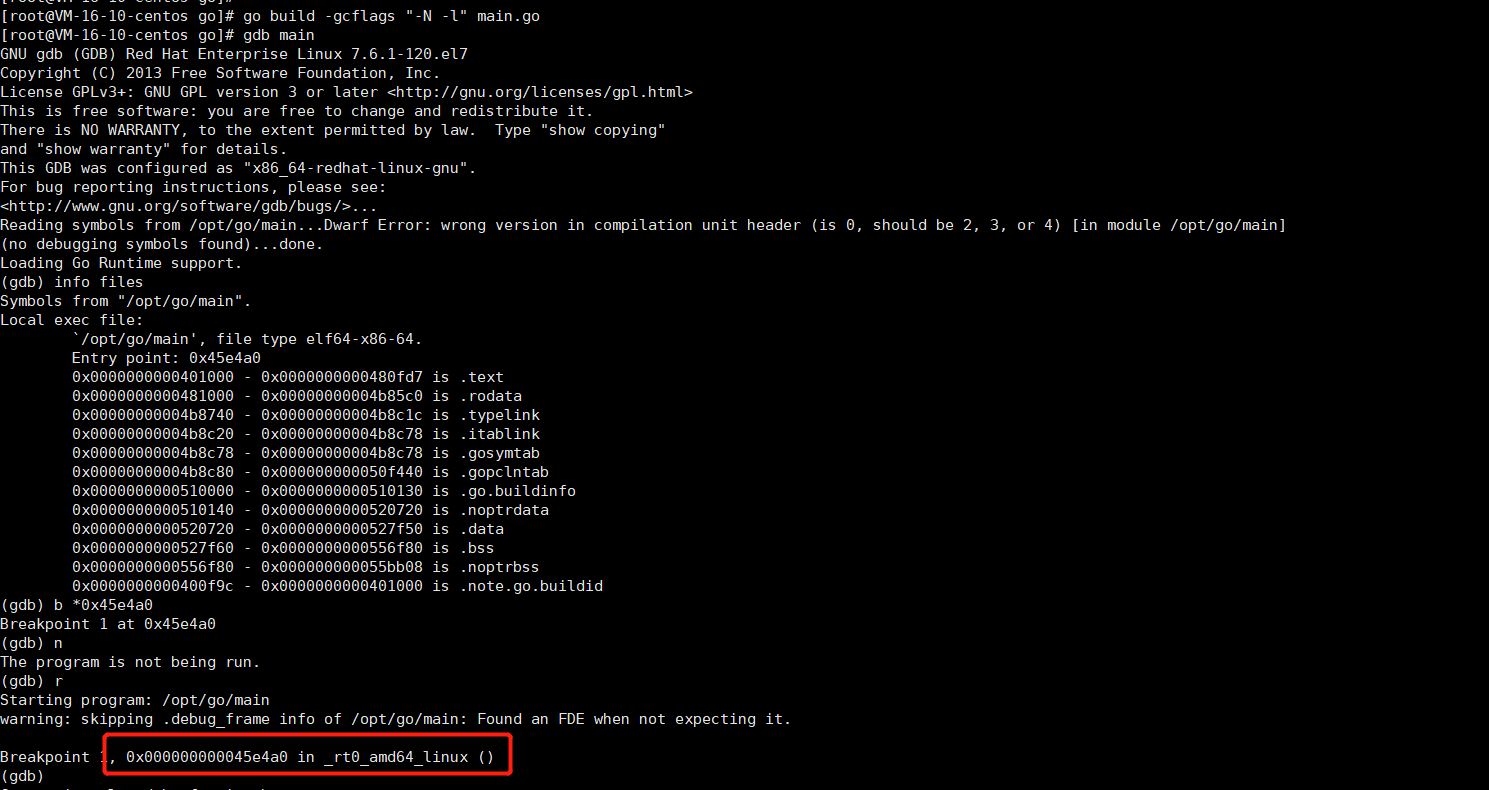
通过 Entry point 的调试定位到源代码的入口地方在_rt0_adm64_linux(), 在 go 源码目录下grep -rn "_rt0_adm64_linux" 可以定位到该函数在runtime包中rt0_linux_amd64.s中,这个文件名称非常的直观, rt0 代表 runtime0 的缩写,指代运行时的创世,超级奶爸:
如上图, Go 语言还支持更多的目标系统架构,例如:AMD64、AMR、MIPS、WASM 等,有兴趣的可以自行去src/runtime 目录下看其他架构代码,这边只按该例子结果去解析。
在 rt0_linux_amd64.s 文件中(代码是汇编语言), 可以发现 _rt0_amd64_linux 跳转到了 _rt0_amd64中:
#include "textflag.h"TEXT _rt0_amd64_linux(SB),NOSPLIT,$-8JMP _rt0_amd64(SB)TEXT _rt0_amd64_linux_lib(SB),NOSPLIT,$0JMP _rt0_amd64_lib(SB)
通过定位 _rt0_amd64又跳转到了 runtime·rt0_go(SB)方法:
TEXT _rt0_amd64(SB),NOSPLIT,$-8MOVQ 0(SP), DI // argcLEAQ 8(SP), SI // argvJMP runtime·rt0_go(SB)
通过上述代码分析,该方法将程序输入的 argc 和 argv 从内存移动到寄存器中。指针(SP)的前两个值分别是 argc 和 argv,其对应参数的数量和具体各参数的值。所以 rt0_go函数就是go程序入口。
程序启动流程
要分析程序的启动流程,就要进入入口文件,下面来看下runtime·rt0_go :
TEXT runtime·rt0_go<ABIInternal>(SB),NOSPLIT,$0//将参数复制到堆栈上MOVQ DI, AX // argcMOVQ SI, BX // argvSUBQ $(4*8+7), SP // 2args 2autoANDQ $~15, SPMOVQ AX, 16(SP)MOVQ BX, 24(SP)//设置Go语言的栈警戒区域和栈地址MOVQ $runtime·g0(SB), DILEAQ (-64*1024+104)(SP), BXMOVQ BX, g_stackguard0(DI)MOVQ BX, g_stackguard1(DI)MOVQ BX, (g_stack+stack_lo)(DI)MOVQ SP, (g_stack+stack_hi)(DI)...// 如果存在 _cgo_init,则调用它MOVQ _cgo_init(SB), AXTESTQ AX, AXJZ needtls...//设置线程局部存储(TLS)以及调用runtime·settls函数LEAQ runtime·m0+m_tls(SB), DICALL runtime·settls(SB)//存储通过TLS的值,以确保它有效get_tls(BX)MOVQ $0x123, g(BX)MOVQ runtime·m0+m_tls(SB), AXCMPQ AX, $0x123JEQ 2(PC)CALL runtime·abort(SB)
ok://保存g0地址以及绑定m0和g0get_tls(BX)LEAQ runtime·g0(SB), CXMOVQ CX, g(BX)LEAQ runtime·m0(SB), AXMOVQ CX, m_g0(AX)MOVQ AX, g_m(CX)CLDCALL runtime·check(SB)//设置参数并调用一些初始化函数,包括操作系统初始化和调度器初始化MOVL 16(SP), AX // copy argcMOVL AX, 0(SP)MOVQ 24(SP), AX // copy argvMOVQ AX, 8(SP)CALL runtime·args(SB)CALL runtime·osinit(SB)CALL runtime·schedinit(SB)//创建一个新的goroutine来启动程序MOVQ $runtime·mainPC(SB), AX // entryPUSHQ AXPUSHQ $0 // arg sizeCALL runtime·newproc(SB)POPQ AXPOPQ AX// 启动这个MCALL runtime·mstart(SB)....RET
在 runtime·rt0_go 方法中,其主要是完成各类运行时的检查,系统参数设置和获取,并进行大量的 Go 基础组件初始化。初始化完毕后进行主协程(main goroutine)的运行,并放入等待队列(GMP 模型),最后调度器开始进行循环调度。
其流程如下图:
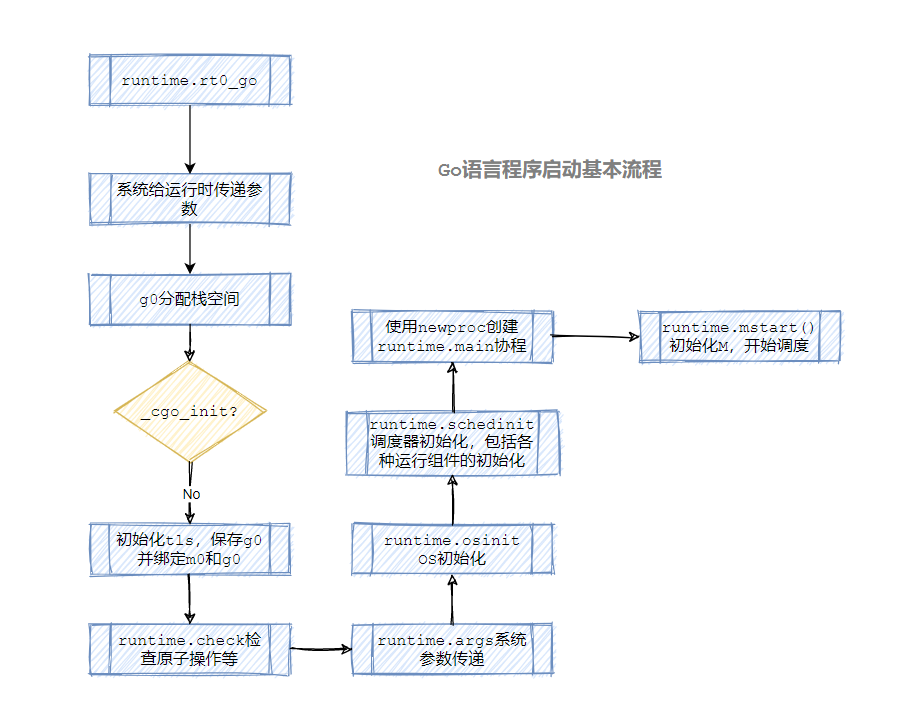
下面将根据上面的流程步骤,将一步一步分析各个流程:
1. 参数入栈
操作系统通过入口参数的约定与应用程序进行沟通,为了支持从系统给运行时传递参数,Go 程序 在进行引导时将对这部分参数进行处理。程序刚刚启动时,栈指针 SP 的前两个值分别对应 argc 和 argv,分别存储参数的数量和具体的参数的值:
TEXT runtime·rt0_go<ABIInternal>(SB),NOSPLIT,$0//将DI和SI压入AX和BX寄存器MOVQ DI, AX // argcMOVQ SI, BX // argv//栈顶向下移动39位(给函数栈腾出空间)SUBQ $(4*8+7), SP // 2args 2auto//调整栈顶寄存器SP使得它按16字节对齐//15二进制是1111,取反是0000, 相当于把低地址4位全变为0ANDQ $~15, SP// 将AX中的内容拷贝到SP+16字节处的内存中,AX中存储的是argc的值MOVQ AX, 16(SP)//将BX中的内容拷贝到SP+24字节处的内存中,BX中存储的是argv的值MOVQ BX, 24(SP)......
函数开始的工作是将寄存器DI和SI的值分别赋值给AX和BX,因为DI和SI中的值是分别是函数参数argc和argv的地址,经过赋值之后,参数的信息也就存储在了AX和BX中。然后栈顶寄存器SP向下移动39字节,并调整SP的位置使它按16字节对齐。最后将argc和argv分别放到SP+16和SP+24字节处的内存中。
其实通俗点讲就是: 将 main 参数存入栈中。
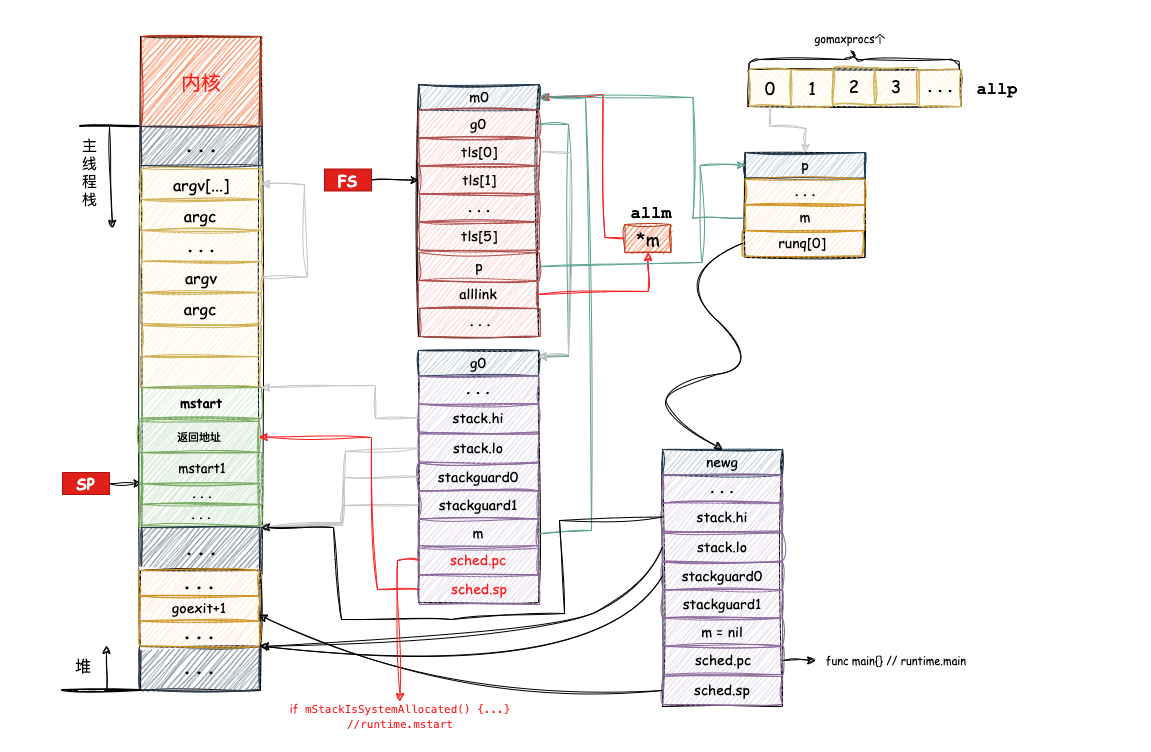
2. 初始化g0栈空间、线程存储TLS、关联m0与g0
什么是m0与g0?
首先我们要先了解g0和m0,首先要了解什么是g0和m0, 其定义为:
//go 1.20.3 path: /src/runtime/proc.go
var (m0 mg0 gmcache0 *mcacheraceprocctx0 uintptr
)
可以看出m0和g0都是全局变量,分别对应着 m结构体和 g结构体, 但是他们和普通的g 和 m还是有着区别的。
m0 :
- 启动程序后的编号为
0的主线程,如果进程中不开任何线程,可以理解为一个进程就是一个线程; - 定义在全局变量
runtime.m0中,不需要在heap(堆)上分配; - 负责执行初始化操作和启动第一个
g(g0); - 启动第一个
g之后,m0就和其他的m一样了( 负责给其他m进行抢占 )。
**g0 **:
- 每次启动一个
m,都会第一个创建的goroutine,就是g0(g0不是整个进程唯一的,而是一个线程中唯一的); g0比较特殊, 每一个m都会有且只有一个自己的g0,g0不指向任何可执行的函数;g0是一个全局的变量,定义在runtime.g0中,g0分配在系统栈中,通过汇编赋值完成,拥有着比较大的栈空间,而其他的g,则分配在用户栈中,初始化只有2K的栈空间,通过newg函数分配;g0仅用于负责调度其他的g(m可能会有很多的g,然后g0用来保持调度栈的信息),当一个m执行从g1切换到g2,首先应该切换到g0,通过g0把g1干掉,把g2加进来 , 即g0就是其他g的指挥官,起着桥梁的作用。
明了m0与g0后,继续往下看参数入栈后的后续操作。
初始化g0
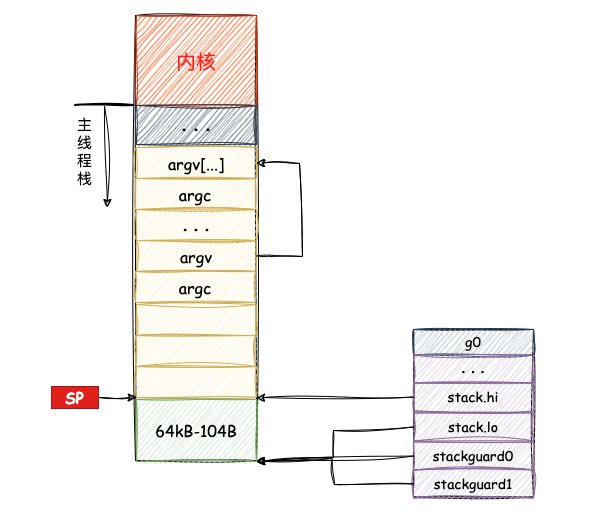
g0作用是其他 g的指挥官,所以在程序运行最初就存在了,在参数入栈后就开始了g0的栈空间构造,如下:
TEXT runtime·rt0_go(SB),NOSPLIT,$0
...
//给g0分配栈空间//将g0的地址放到DI寄存器中
MOVQ $runtime·g0(SB), DI
//将SP指向的位置向下(低地址空间)移动64*1024-104个字节,然后将该位置的地址赋值给BX
//这里是在为g0构造栈空间,g0栈的空间大小约为64KB
LEAQ (-64*1024+104)(SP), BX
// 将BX的值拷贝给g0.stackguard0,即 g0.stackguard0=*SP-64*1024+104
MOVQ BX, g_stackguard0(DI)
// g0.stackguard1=*SP-64*1024+104
MOVQ BX, g_stackguard1(DI)
// g0.stack.lo=*SP-64*1024+104
MOVQ BX, (g_stack+stack_lo)(DI)
// g0.stack.hi=SP
MOVQ SP, (g_stack+stack_hi)(DI)
...
g0 它为runtime代码的运行提供一个栈环境。程序先将 g0 的地址保存在DI寄存器中,然后栈顶寄存器SP向下移动64*1024-104个字节,即向下大约移动64KB, 构造g0的栈空间;最后给g0的stackguard0、stackguard1、stack.lo和stack.hi字段设置初始值,这几个字段与栈的位置,以及栈扩容相关。
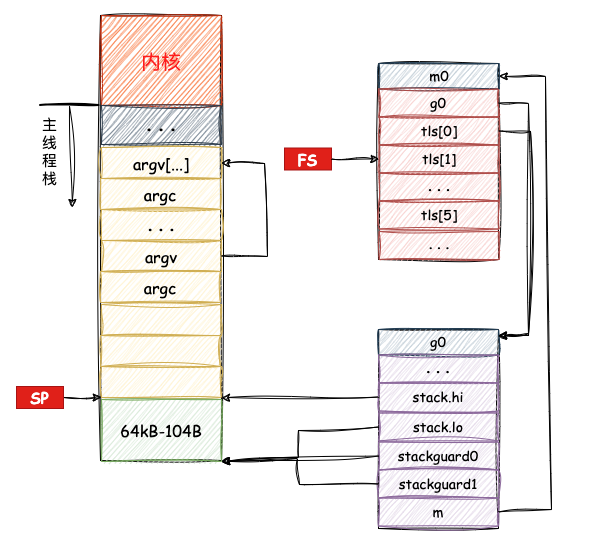
完成以上指令后,系统栈与g0的关系大致如图所示:
主线程与m0绑定
线程TLS即m.tls,定义在m的结构体中,指向的是一个6*8字节大小的指针数组:
//go 1.20.3 path: /src/runtime/runtime2.go
type m struct {...tls [6]uintptr...
}
tls被称为线程本地存储,是线程私有的全局变量而已。
有过多线程编程的编程人员一定知道,普通的全局变量在多线程中是共享的,一个线程对其进行了修改,所有线程都可以看到这个修改,而线程私有的全局变量与普通全局变量不同,线程私有全局变量是线程的私有财产,每个线程都有自己的一份副本,某个线程对其所做的修改只会修改到自己的副本,并不会修改到其它线程的副本。所以当一个线程修改线程变量的值时,不影响另外一个线程读取线程变量的值。因为线程变量在每个线程的TLS都有一份,访问时只能读取所在TLS中的线程变量值。
在g0的栈空间构造完成后,go开始对当前主线程(即m0)的tls进行绑定,其代码如下:
TEXT runtime·rt0_go(SB),NOSPLIT,$0
...//初始化m0的tls字段,即DI = &m0.tlsLEAQ runtime·m0+m_tls(SB), DI// 调用settls设置线程本地存储,settls函数的参数已在DI寄存器中CALL runtime·settls(SB)
...
通过runtime.settls利用arch_prctl系统调用把m0.tls[1]的地址设置成了FS段的段基址来实现线程本地存储。CPU中有个叫FS的段寄存器与之对应,而每个线程都有自己的一组CPU寄存器值,操作系统在把线程调离CPU运行时会帮我们把所有寄存器中的值保存在内存中,调度线程起来运行时又会从内存中把这些寄存器的值恢复到CPU,这样,在此之后,工作线程代码就可以通过Fs寄存器来找到m.tls。
FS寄存器: 一般用它来实现线程本地存储(TLS), 运行中每个M的FS寄存器都会指向它们对应的M实例的tls。
来看下runtime.settls 源码的实现:
TEXT runtime·settls(SB),NOSPLIT,$32
...
//DI寄存器中存放的是m.tls[0]的地址,m的tls成员是一个数组,读者如果忘记了可以回头看一下m结构体的定义
//下面这一句代码把DI寄存器中的地址加8,为什么要+8呢,主要跟ELF可执行文件格式中的TLS实现的机制有关
//执行下面这句指令之后DI寄存器中的存放的就是m.tls[1]的地址了
ADDQ $8, DI// ELF wants to use -8(FS)//下面通过arch_prctl系统调用设置FS段基址MOVQ DI, SI
//SI存放arch_prctl系统调用的第二个参数
MOVQ $0x1002, DI
// ARCH_SET_FS //arch_prctl的第一个参数
MOVQ $SYS_arch_prctl, AX
//系统调用
SYS CALL
CMP QAX, $0xfffffffffffff001
JLS 2(PC)
MOVL $0xf1, 0xf1 // crash
//系统调用失败直接crash
RET
从上述代码中可以看出,FS寄存器的值是 m.tls[0]+8,而要寻址 m.tls,则可以直接使用 FS 寄存器的值进行偏移量0xfffffff8(也就是-8)的偏移即可。
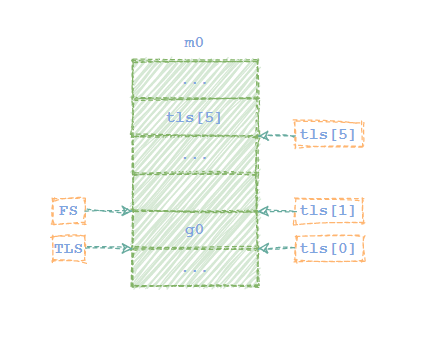
当m0.tls初始化完毕后,将刚刚构造的g0写入到m0.tls中,代码如下:
TEXT runtime·rt0_go(SB),NOSPLIT,$0
...// 验证刚才设置的本地线程存储是否可以正常工作// 获取段基地址(FS)放入BX寄存器,也就是把m0.tls[0]的地址放入到BX寄存器get_tls(BX)// 将常数0x123赋值给BX寄存器指向的内存地址MOVQ $0x123, g(BX)// 将AX设置为m0.tls[0]MOVQ runtime·m0+m_tls(SB), AX// 在将AX指向的内存中的值与0x123进行比较,通过set-get-compare的形式检查tls是否工作正常CMPQ AX, $0x123JEQ 2(PC)CALL runtime·abort(SB)
ok:get_tls(BX)//寄存器CX存储g0的地址LEAQ runtime·g0(SB), CX//将g0的地址保存到本地线程存储 m0.tls[0]中,也就是m0.tls[0]=&g0MOVQ CX, g(BX)
...
将g0写入m0.tls后,m0的内存示意图如下:
m0与g0绑定
g0构造完成后,就需要将g0与m0进行关联,直接上代码:
TEXT runtime·rt0_go(SB),NOSPLIT,$0
...//将m0的地址保存到寄存器AX中LEAQ runtime·m0(SB), AX// 将m0和g0互相绑定// m0.g0=&g0MOVQ CX, m_g0(AX)// g0.m=&m0MOVQ AX, g_m(CX)
...
这一段执行完之后,就把 m0,g0,m.tls[0] 串联起来了。通过 m.tls[0] 可以找到 g0,通过 g0 可以找到 m0(通过 g 结构体的 m 字段)。并且,通过 m 的字段 g0,m0 也可以找到 g0。
于是,主线程和 m0,g0 就关联起来了。栈帧关系图如下:
3. 运行时类型检查、系统参数处理、OS初始化
运行时类型检查
完成了主线程和 m0,g0 就关联, 接下来是对运行时类型检查,其代码如下:
TEXT runtime·rt0_go(SB),NOSPLIT,$0
...CALL runtime·check(SB)
...
可以看出,运行时类型检查由 runtime.check 来完成。
其本质上基本上属于对编译器翻译工作的一个校验,显然如果编译器的编译工作不正确,运行时的运行过程便不是一个有效的过程。这里粗略展示整个函数的内容:
//go 1.20.3 path: /src/runtime/runtime1.go
func check() {var (a int8b uint8(...))(...)// 校验 int8 类型 sizeof 是否为 1,下同if unsafe.Sizeof(a) != 1 { throw("bad a") }if unsafe.Sizeof(b) != 1 { throw("bad b") }(...)
}
系统参数处理
完成运行时类型检查,开始处理系统参数:
TEXT runtime·rt0_go(SB),NOSPLIT,$0
...// 将argc从内存搬到AX存储器中,AX = argcMOVL 16(SP), AX // copy argc// 将argc搬到 SP+0的位置,即栈顶位置MOVL AX, 0(SP)//将argv从内存搬到AX寄存器中,AX = argvMOVQ 24(SP), AX // copy argv// 将argv搬到 SP+8的位置MOVQ AX, 8(SP)//处理操作系统传递过来的参数和envCALL runtime·args(SB)
...
根据代码,可以看出:
-
将
argc和argv移动到SP+0和SP+8的位置,这样是为了将argc和argv作为runtime·args函数的参数; -
调用
runtime·args函数处理从栈中读取的参数和环境变量(env)进行相关处理,argc, argv作为来自操作系统的参数传递给runtime.args处理程序参数的相关事宜://go 1.20.3 path: /src/runtime/runtime1.go func args(c int32, v **byte) {argc = cargv = vsysargs(c, v) }runtime.args函数将参数指针保存到了argc和argv这两个全局变量中, 供其他初始化函数使用,而后调用了平台特定的runtime.sysargs处理。runtime.sysargs作用是在Go运行时初始化并设置os.Args变量的一部分,这里不展开细说了。
os初始化
完成了系统参数处理,就要调用runtime·osinit函数处理初始化cpu数量等相关操作,代码如下:
TEXT runtime·rt0_go(SB),NOSPLIT,$0
...//调用osinit函数,获取CPU的核数,存放在全局变量ncpu中,供后面的调度时使用CALL runtime·osinit(SB)
...
runtime.osinit 完成对 CPU 核心数的获取,因为这与调度器有关。 而 Darwin 上由于使用的是 mach-o 格式,在此前的 runtime.sysargs 上 还没有确定内存页的大小,因而在这个函数中,还会额外使用 runtime.sysctl 完成物理页大小的查询:
var ncpu int32// Linux
func osinit() {ncpu = getproccount()
}// Darwin
func osinit() {ncpu = getncpu()physPageSize = getPageSize() // 内部使用 runtime.sysctl 来获取物理页大小.
}
可以看出,对运行时最为重要的两个系统级参数:CPU 核心数与内存物理页大小。
4. 调度器以及相关组件初始化
接下来就进行了调度器的初始化环节,代码如下:
TEXT runtime·rt0_go(SB),NOSPLIT,$0
...
CALL runtime·schedinit(SB)
...
可以从代码中看出,代码使用了runtime·schedinit进行各种运行时组件初始化工作,这包括我们的调度器与内存分配器、回收器的初始化。
下面给出runtime·schedinit源码如下:
//go 1.20.3 path: /src/runtime/proc.gofunc schedinit() {// ...... 省略各种锁的初始化gp := getg() // 获取当前 goroutine,当前即为g0// ...... 省略race相关的代码sched.maxmcount = 10000 // 设置最大M数量worldStopped() //暂停所有 goroutine 的全局调度moduledataverify() //验证模块数据的一致性stackinit() // 初始化堆栈mallocinit() // 初始化内存分配器// 获取 Godebug 标志godebug := getGodebugEarly()initPageTrace(godebug) // 初始化页面跟踪cpuinit(godebug) // 初始化 CPUalginit() // 初始化算法fastrandinit() // 初始化快速随机数生成器// 初始化当前m,即m0mcommoninit(gp.m, -1)modulesinit() // 初始化模块typelinksinit() // 初始化类型链接itabsinit() // 初始化接口数据stkobjinit() // 初始化栈对象sigsave(&gp.m.sigmask)// 保存当前信号掩码initSigmask = gp.m.sigmaskgoargs() // 初始化命令行参数goenvs() // 初始化环境变量parsedebugvars() // 解析调试变量gcinit() // 初始化垃圾回收// 如果禁用内存分析,将内存分析率设置为 0if disableMemoryProfiling {MemProfileRate = 0}lock(&sched.lock) // 锁定调度器锁sched.lastpoll.Store(nanotime()) // 设置最后一次的调度时间// 根据 GOMAXPROCS 环境变量调整 P 的数量procs := ncpuif n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {procs = n}// 调整 P 的数量,创建并初始化所有的P,所有的P保存在全局变量allp中if procresize(procs) != nil {throw("unknown runnable goroutine during bootstrap")}unlock(&sched.lock) // 解锁调度器锁worldStarted() // 重新启动所有 goroutine 的全局调度// .......省略 cgo check相关以及设置版本信息内容
}从代码中可以看出,该函数调用了一堆 init 函数,初始化各种配置和锁,现在不去深究,重点关注分析下面关键的两点:
runtime·schedinit调用了runtime.mcommoninit函数初始化m,如果当前m为进程的第一个m,则该m为m0;runtime·schedinit调用了runtime.procresize函数根据GOMAXPROCS值创建并初始化了等量的p存入初始化全局变量allp,并将m0和allp[0]绑定到一起,即p的初始化以及绑定。
m的初始化 — runtime.mcommoninit
m的初始化主要是调用 runtime.mcommoninit函数实现的, 相关源码如下:
//go 1.20.3 path: /src/runtime/proc.gofunc mcommoninit(mp *m, id int64) {gp := getg() // 获取当前 goroutine// 如果当前 goroutine不是 g0,获取当前函数的调用栈if gp != gp.m.g0 {callers(1, mp.createstack[:])}lock(&sched.lock) // 锁定调度器锁// 根据传入的 id 初始化 M(调度器线程)的 idif id >= 0 {mp.id = id} else {mp.id = mReserveID()}// 生成 fastrand 种子值lo := uint32(int64Hash(uint64(mp.id), fastrandseed))hi := uint32(int64Hash(uint64(cputicks()), ^fastrandseed))if lo|hi == 0 {hi = 1}// 根据系统字节序设置 fastrand 值if goarch.BigEndian {mp.fastrand = uint64(lo)<<32 | uint64(hi)} else {mp.fastrand = uint64(hi)<<32 | uint64(lo)}mpreinit(mp) // 初始化 M(调度器线程)// 如果 M(调度器线程)有关联的信号 goroutine,则设置栈警戒区域if mp.gsignal != nil {mp.gsignal.stackguard1 = mp.gsignal.stack.lo + _StackGuard}// 将 M(调度器线程)添加到全局 M 链表中mp.alllink = allmatomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))unlock(&sched.lock) // 解锁调度器锁// 如果是 Cgo 环境,Solaris,Illumos 或 Windows,初始化 Cgo 调用的相关信息if iscgo || GOOS == "solaris" || GOOS == "illumos" || GOOS == "windows" {mp.cgoCallers = new(cgoCallers)}
}该函数主要流程可以概括为以下几个步骤:
-
调用
getg()函数获取当前的g, 如果当前g不是g0,则获取当前函数的调用栈的信息并将这些信息存储在mp.createstack数组中; -
设置当前
M的id以及fastrand值; -
调用
mpreinit函数配并初始化M的信号处理Goroutine,并将M与信号处理Goroutine关联起来,以便M能够控制和管理这个Goroutine。mpreinit函数源码为://go 1.20.3 path: /src/runtime/os_darwin.go func mpreinit(mp *m) {// 分配信号处理 Goroutine,设置栈大小为 32 * 1024 字节mp.gsignal = malg(32 * 1024)// 将 M(调度器线程)关联到信号处理 Goroutinemp.gsignal.m = mp// 如果运行在 darwin/arm64 平台,执行以下操作if GOOS == "darwin" && GOARCH == "arm64" {// 锁定信号 Goroutine 的栈,以避免内存分页失效mlock(unsafe.Pointer(mp.gsignal.stack.hi-physPageSize), physPageSize)} }从上述代码可以看出,该信号
Goroutine是一个栈空间大小为32KB的的g,这个Goroutine用于处理异步信号,如垃圾回收和其他系统级操作。该Goroutine创建完毕后,赋值给mp.gsignal,并将该g的m设置为当前m对象:mp.gsignal.m = mp。 -
初始化
m的信号g后,然后将当前m对象mp挂入全局链表allm之中,更新allm的头节点为当前m对象mp,下图为allm链表插入前和插入后示意图: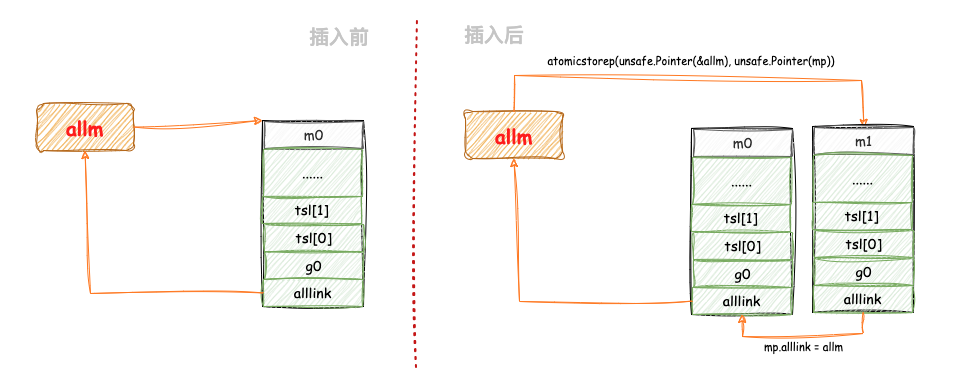
完成这些操作后,大功告成!解锁。
p的初始化以及关联 — runtime.procresize
完成了m的初始化,在进行p的初始化前先要根据GOMAXPROCS调整p的数量,如下:
//go 1.20.3 path: /src/runtime/proc.gofunc schedinit() {// ...... // 根据 GOMAXPROCS 环境变量调整 P 的数量procs := ncpuif n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {procs = n}// .......
}
调整好P的数量procs后,调用 runtime.procresize函数进行对p的初始化以及相关关联。
runtime.procresize函数代码比较长,我们将该函数分步解析,按着功能和流程拆分函数:
-
根据
nprocs数量(即GOMAXPROCS值,CPU逻辑核心数) 生成 该值量大小的全局变量切片allp(该切片是用于存放p)以及idlepMask和timerpMask掩码数组;相关代码如下://go 1.20.3 path: /src/runtime/proc.gofunc procresize(nprocs int32) *p {assertLockHeld(&sched.lock) // 确保调度器锁已被持有assertWorldStopped() // 确保全局调度已停止old := gomaxprocs // 保存旧的M最大数量// 检查传入的 nprocs 是否合法,如果小于等于零,则抛出错误if old < 0 || nprocs <= 0 {throw("procresize: invalid arg")}// ...... now := nanotime() // 获取当前时间if sched.procresizetime != 0 {sched.totaltime += int64(old) * (now - sched.procresizetime) //累加CPU时间总和}sched.procresizetime = now //将 sched.procresizetime更新为当前时间now,以便在下次 M 调整时再次计算时间间隔。maskWords := (nprocs + 31) / 32 // 计算用于存储处理器状态的位掩码大小// 如果新的 M 最大数量大于当前 allp 数组的长度,进行动态数组扩展if nprocs > int32(len(allp)) {lock(&allpLock)if nprocs <= int32(cap(allp)) {allp = allp[:nprocs]} else {nallp := make([]*p, nprocs)copy(nallp, allp[:cap(allp)])allp = nallp}// 根据位掩码大小动态调整 idlepMask 和 timerpMask 数组if maskWords <= int32(cap(idlepMask)) {idlepMask = idlepMask[:maskWords]timerpMask = timerpMask[:maskWords]} else {nidlepMask := make([]uint32, maskWords)copy(nidlepMask, idlepMask)idlepMask = nidlepMaskntimerpMask := make([]uint32, maskWords)copy(ntimerpMask, timerpMask)timerpMask = ntimerpMask}unlock(&allpLock)}// ...... }该段代码没什么复杂的逻辑需要解释,这里稍微介绍下
idlepMask和timerpMask:idlepMask(空闲P掩码):这个位掩码数组用于跟踪哪些处理器处于空闲状态。每个位表示一个处理器(P),如果该位为1,则表示相应的处理器是空闲的,可以用于运行新的Goroutine。这个位掩码在调度器中用于选择合适的处理器来运行Goroutine,以提高并发性能;timerpMask(定时器P掩码):这个位掩码数组用于标记具有定时器任务的处理器。在Go运行时中,有些P负责处理定时器事件,比如定时的垃圾回收。这个位掩码用于标记哪些P具有定时器任务,以便在需要时选择这些P来执行定时任务。
-
根据
nprocs数量循环创建和初始化P结构体对象并依次存入全局变量allp中;相关代码如下://go 1.20.3 path: /src/runtime/proc.gofunc procresize(nprocs int32) *p {// ......// 创建新的 P(处理器)并初始化for i := old; i < nprocs; i++ {pp := allp[i]if pp == nil {pp = new(p)}pp.init(i)atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))}// ...... }这段代码逻辑也非常简单,大致流程是根据新的
M最大数量nprocs动态创建和初始化处理器P。如果旧的处理器P数量小于新的M最大数量,它会创建新的处理器P并将它们初始化,以便在调度器中使用。这是为了确保Go程序可以更好地适应不同并发需求,并更好地管理系统资源。我们继续来刨根问底,看看调用的
pp.init(i)这个初始化函数做了一些什么工作://go 1.20.3 path: /src/runtime/proc.gofunc (pp *p) init(id int32) {pp.id = id // 设置处理器 P 的 IDpp.status = _Pgcstop //设置处理器 P 的状态为_Pgcstop,该状态一般在GC前或者刚被创建时// 初始化 sudogcache 切片,用于缓存等待锁的 Goroutinepp.sudogcache = pp.sudogbuf[:0]// 初始化 deferpool 切片,用于缓存延迟执行的函数调用pp.deferpool = pp.deferpoolbuf[:0]pp.wbBuf.reset() // 重置写屏障缓冲区//如果pp.mcache为空,则为处理器P分配一个本地的内存分配缓存(mcache)if pp.mcache == nil {if id == 0 {if mcache0 == nil {throw("missing mcache?")}pp.mcache = mcache0} else {pp.mcache = allocmcache()}}//为处理器 P 初始化竞态检测上下文,确保在使用竞态检测工具时,每个处理器都有自己的独立竞态检测上下文,以避免竞态条件和混淆竞态检测的结果if raceenabled && pp.raceprocctx == 0 {if id == 0 {pp.raceprocctx = raceprocctx0raceprocctx0 = 0 // 初始化竞态检测的上下文} else {pp.raceprocctx = raceproccreate()}}lockInit(&pp.timersLock, lockRankTimers) // 初始化定时器锁timerpMask.set(id) // 设置定时器 P 掩码中对应位为 1,表示处理器P具有定时器任务idlepMask.clear(id) // 清除空闲 P 掩码中对应位的标志,表示处理器P不是空闲状态 }init函数主要是设置处理器P的各个字段和状态。其中包括了设置ID、状态、缓存等待锁的切片、缓存延迟函数调用的切片、写屏障缓冲区的重置,以及初始化竞态检测的上下文、定时器锁等操作。这些操作都是为了确保处理器P可以正确地执行任务和协调其他组件。 -
根据当前
Goroutine状态和与处理器P的关联情况进行绑定关系有效的处理。 处理分两种情况:- 如果当前
Goroutine已经绑定了P且该P.id在正常范围,则不需要改变关联。则将该处理器P的状态设置为_Prunning,表示它正在运行;然后准备处理器 P 的本地内存分配缓存以进行垃圾回收; - 否则表示当前
Goroutine不与有效的处理器P相关联或者需要重新关联。需要取消当前Goroutine的相关P和M的关联,然后获取第一个处理器P(即allp[0])与当前Goroutine进行关联,更改相关P、M的一些关联以及状态。
//go 1.20.3 path: /src/runtime/proc.gofunc procresize(nprocs int32) *p {// ......gp := getg() // 获取当前 Goroutineif gp.m.p != 0 && gp.m.p.ptr().id < nprocs { // 如果当前 Goroutine已经与某个处理器 P 相关联(gp.m.p 不为0),// 并且该处理器 P 的 ID 小于新的 M 最大数量 nprocsgp.m.p.ptr().status = _Prunning //设置关联的处理器 P 的状态为 _Prunning,表示正在运行gp.m.p.ptr().mcache.prepareForSweep() // 准备处理器 P 的本地内存分配缓存以进行垃圾回收} else {// 如果当前 Goroutine已经与某个处理器 P 相关联(gp.m.p 不为0)if gp.m.p != 0 {// ......gp.m.p.ptr().m = 0 // 取消当前 Goroutine 与处理器 P 的关联,将 m 字段置为0}gp.m.p = 0 // 取消当前 Goroutine 与处理器 P 的关联,将当前 Goroutine 的关联处理器 P 字段置为0pp := allp[0] // 获取第一个处理器 Ppp.m = 0 // 取消第一个处理器 P 与当前 Goroutine 的关联,将 m 字段置为0pp.status = _Pidle // 设置第一个处理器 P 的状态为 _Pidle,表示空闲状态// 获取一个空闲的处理器 P 并将当前 Goroutine 与其关联acquirep(pp)// ......}// ...... }代码已经做了详细的注释,不再啰嗦了,这边我们看看有个
runtime.acquirep的函数调用,runtime.acquirep中的主要逻辑就是调用了runtime.wirep, 作用是将allp[0]与m(如果是第一个线程,则是m0)互相绑定,并将p的状态修改为_Prunning, 我们看下源码://go 1.20.3 path: /src/runtime/proc.gofunc acquirep(pp *p) {wirep(pp) // 与处理器 P 关联pp.mcache.prepareForSweep() // 准备处理器 P 的本地内存分配缓存以进行垃圾回收// ...... }func wirep(pp *p) {gp := getg() // 获取当前 Goroutine的 G 对象if gp.m.p != 0 {throw("wirep: already in go") // 如果当前 Goroutine已经关联了处理器 P,抛出异常}//处理器 P的状态不合法,抛出异常if pp.m != 0 || pp.status != _Pidle {id := int64(0)if pp.m != 0 {id = pp.m.ptr().id // 获取处理器 P 的 ID}// 打印错误信息,包括处理器 P 的 m 和状态print("wirep: p->m=", pp.m, "(", id, ") p->status=", pp.status, "\n")throw("wirep: invalid p state") // 如果处理器 P的状态不合法,抛出异常}gp.m.p.set(pp) // 将当前 Goroutine关联到指定的处理器 Ppp.m.set(gp.m) // 将指定的处理器 P关联到当前 Goroutine的 Mpp.status = _Prunning // 设置处理器 P的状态为 _Prunning,表示正在运行 }wirep函数的作用是将Goroutine与处理器P关联,以确保Goroutine可以在指定的处理器P上执行,同时进行状态检查以避免不合法的关联。 - 如果当前
-
根据新的
M最大数量nprocs进行处理器P的调整和管理,主要的工作就是销毁多余的P以及当P数量大于最大数量nprocs时进行allp数组的调整缩减;//go 1.20.3 path: /src/runtime/proc.gofunc procresize(nprocs int32) *p {// ......mcache0 = nil // 将 mcache0 置为 nil,释放不再使用的全局内存分配缓存//销毁不再需要的处理器 Pfor i := nprocs; i < old; i++ {pp := allp[i]pp.destroy() // 销毁不再需要的处理器 P}// 如果 allp 数组的长度不等于新的 M 最大数量,进行数组缩减if int32(len(allp)) != nprocs {lock(&allpLock) // 锁定 allpLock 以确保线程安全allp = allp[:nprocs] // 缩减 allp 数组的长度至新的 M 最大数量idlepMask = idlepMask[:maskWords] // 重新分配 idlepMask 切片以匹配新的长度timerpMask = timerpMask[:maskWords] // 重新分配 timerpMask 切片以匹配新的长度unlock(&allpLock) // 解锁 allpLock}// ...... }这段代码用于动态管理和调整处理器
P的数量以适应并发需求,同时释放不再使用的资源。不再过多解析了。 -
调整处理器
P的数量后,将所有空闲的P放入到调度器的全局空闲队列;对于非空闲的P(本地队列里有G待执行),则是生成一个P链表,返回给procresize函数的调用者。//go 1.20.3 path: /src/runtime/proc.gofunc procresize(nprocs int32) *p {// ......// 初始化可运行的 P 链表var runnablePs *p //声明一个变量 runnablePs,用于存储可能用于运行的处理器 P//遍历处理器 P 数组for i := nprocs - 1; i >= 0; i-- {pp := allp[i] //获取当前索引i存储的处理器P//检查当前 Goroutine是否与当前处理器 P关联。如果已经关联,就跳过。if gp.m.p.ptr() == pp {continue}pp.status = _Pidle //将处理器P的状态设置为 _Pidle,表示它处于空闲状态if runqempty(pp) {//如果处理器P的运行队列为空,将处理器P放入空闲队列,并设置相应的空闲时间pidleput(pp, now)} else {//否则,如果运行队列不为空,则pp.m.set(mget()) //为处理器 P分配一个 Mpp.link.set(runnablePs) //将处理器 P链接到 runnablePs 列表,以便稍后执行runnablePs = pp}}// 重置 goroutine 抢占顺序stealOrder.reset(uint32(nprocs))var int32p *int32 = &gomaxprocsatomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs)) // 更新 GOMAXPROCS// 如果旧的 M 最大数量与新的 M 最大数量不一致,重置 GC 限制if old != nprocs {gcCPULimiter.resetCapacity(now, nprocs)}// 返回可能用于运行的处理器 Preturn runnablePs }
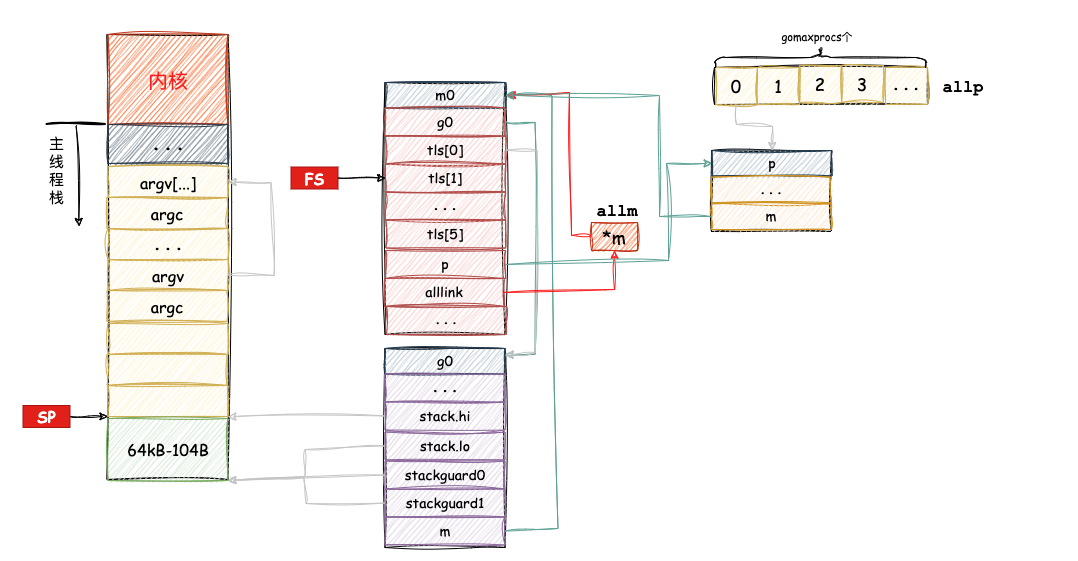
这样,整个 procresize 函数就讲完了,这也意味着,调度器的初始化工作已经完成了。得到如下关系结构图:
5. main Goroutine的创建
经过前面一系列流程,调度器的初始化工作已经完成,接下来的流程是:
TEXT runtime·rt0_go<ABIInternal>(SB),NOSPLIT,$0......//创建一个新的goroutine来启动程序MOVQ $runtime·mainPC(SB), AX // mainPC是runtime.mainPUSHQ AX // 将runtime.main函数地址入栈,作为参数PUSHQ $0 // arg sizeCALL runtime·newproc(SB) // 创建main goroutine,入参就是runtime.mainPOPQ AXPOPQ AX
....
这段代码的主要目的是启动 Go 程序的执行,它调用 runtime·newproc 函数来创建一个新的 Goroutine,并将 runtime.main 函数的地址和参数传递给它,从而开始执行 Go 主程序。而这个Goroutine我们称为 main goroutine ,这是系统创建的真正意义上的第一个goroutine 了(之前的g0和m.gsignal是特殊功能上的g)。
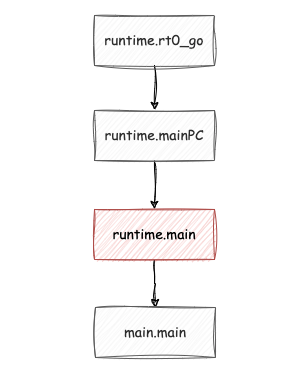
main goroutine 并非字面上理解为执行我们自己写的main包中的main函数的, 其实它是用来执行runtime.mainPC 所对应的runtime.main函数。
runtime.main函数属于runtime包中的内容,该函数主要功能是创建监控线程执行sysmon函数、启动gc清扫的goroutine、执行runtime包的初始化,main包以及main包import的所有包的初始化等相关工作,完成这些工作后main goroutine 函数又会调用我们用户编写的package main包中main函数,这样我们的用户代码就可以被执行到了。如下图(红色部分为我们这边所说的 main goroutine ):
阅代码所知,系统是调用 runtime·newproc 函数来创建goroutine的。其实不仅仅系统调用它生成goroutine,最终我们自己写的goroutine的(即 go func()模式)也都是调用了 runtime.newproc函数进行协程的创建,所以, runtime.newproc函数就是协程创建的钥匙。
总结起来一句话:不管是普通的Goroutine 还是 main Goroutine,都是调用 runtime.newproc 完成的。
那runtime.newproc到底做了什么?我们直接来看 runtime.newproc的源码:
//go 1.20.3 path: /src/runtime/proc.gofunc newproc(fn *funcval) {// 获取当前 Goroutinegp := getg()// 获取调用者的 PC 寄存器值pc := getcallerpc()// 在系统堆栈上运行下面的代码块systemstack(func() {// 调用 newproc1 函数创建一个新的 Goroutinenewg := newproc1(fn, gp, pc)// 获取当前 Goroutine所在处理器 Ppp := getg().m.p.ptr()// 将新的 Goroutine 添加到当前处理器 P的运行队列runqput(pp, newg, true)// 如果主程序已经启动,唤醒一个空闲的处理器 Pif mainStarted {wakep()}})
}
该函数代码看上去寥寥几行,但其实大部分逻辑都封装进了调用的函数中去了,现在大致总结下该函数的流程:
- 获取当前的
Goroutine以及调用者的PC寄存器值,连同传递函数值fn一起作为参数传递给runtime.newproc1函数,调用systemstack切换到g0栈执行runtime.newproc1函数创建出一个Goroutine,为其分配栈空间、设置初始状态,初始化调用信息,更新相关计数器,以及进行跟踪和race检测相关的设置; - 通过调用
runtime.runqput函数将新获取的Goroutine加入到运行队列中去,该队列既可能是全局的运行队列,也可能是p本地的运行队列; - 在满足条件时调用
runtime.wakep唤醒一个空闲的的P,以确保新创建的Goroutine能够被执行。
总起起来,runtime·newproc 是负责获取当前 Goroutine、调用者的 PC 寄存器值,并在系统堆栈上运行代码块,以确保新 Goroutine 的创建不会导致栈问题,然后会调用runtime.newproc1函数创建一个新 Goroutine 并将其添加到当前处理器 P 的运行队列,以便后续被调度执行。
5.1 Goroutine的创建 – runtime.newproc1
从runtime·newproc 源码中,我们可以看出创建一个Goroutine操作主要封装在 runtime.newproc1函数中,所以 runtime.newproc1函数才是那个创建一个新的 Goroutine(Go 协程),为其分配栈空间、设置初始状态,初始化调用信息,更新相关计数器,以及进行跟踪和 race 检测相关的设置的核心函数。
runtime.newproc1函数其源码如下:
//go 1.20.3 path: /src/runtime/proc.gofunc newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {// 检查传入的函数值是否为 nilif fn == nil {fatal("go of nil func value")}// 获取当前 M 和处理器 Pmp := acquirem()pp := mp.p.ptr()// 尝试从 P 的可用 Goroutine 缓存中获取一个新的 Goroutinenewg := gfget(pp)if newg == nil {// 如果缓存中没有可用的 Goroutine,则创建一个新的 Goroutinenewg = malg(_StackMin)casgstatus(newg, _Gidle, _Gdead) // 设置 Goroutine 状态为 _Gdeadallgadd(newg) // 添加到所有 Goroutine 列表中}// 检查新 Goroutine 的栈是否存在if newg.stack.hi == 0 {throw("newproc1: newg missing stack")}// 检查新 Goroutine 的状态是否为 _Gdeadif readgstatus(newg) != _Gdead {throw("newproc1: new g is not Gdead")}// 计算新 Goroutine 的栈空间大小totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize)totalSize = alignUp(totalSize, sys.StackAlign)// 计算新 Goroutine 的栈指针位置sp := newg.stack.hi - totalSizespArg := sp// 如果使用了 Link Register (LR),进行相应的设置if usesLR {*((*uintptr)(unsafe.Pointer(sp)) = 0prepGoExitFrame(sp)spArg += sys.MinFrameSize}// 清除 Goroutine 结构中的部分字段memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))// 设置 Goroutine 的堆栈指针等信息newg.sched.sp = spnewg.stktopsp = spnewg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantumnewg.sched.g = guintptr(unsafe.Pointer(newg))// 初始化调用函数的 Goroutine 调度信息gostartcallfn(&newg.sched, fn)// 设置 Goroutine 的 gopc、ancestors 和 startpc 字段newg.gopc = callerpcnewg.ancestors = saveAncestors(callergp)newg.startpc = fn.fn// 根据是否为系统 Goroutine 进行不同的设置if isSystemGoroutine(newg, false) {sched.ngsys.Add(1)} else {if mp.curg != nil {newg.labels = mp.curg.labels}if goroutineProfile.active {newg.goroutineProfiled.Store(goroutineProfileSatisfied)}}// 生成 Goroutine 的跟踪序列newg.trackingSeq = uint8(fastrand())if newg.trackingSeq%gTrackingPeriod == 0 {newg.tracking = true}// 设置 Goroutine 状态为 _Grunnable,准备执行casgstatus(newg, _Gdead, _Grunnable)// 添加新 Goroutine 的栈到 GC 控制器的扫描栈列表gcController.addScannableStack(pp, int64(newg.stack.hi-newg.stack.lo))// 更新处理器 P 的 Goroutine ID 缓存if pp.goidcache == pp.goidcacheend {pp.goidcache = sched.goidgen.Add(_GoidCacheBatch)pp.goidcache -= _GoidCacheBatch - 1pp.goidcacheend = pp.goidcache + _GoidCacheBatch}newg.goid = pp.goidcachepp.goidcache++// ......省略 race 追踪和检测相关代码// 释放 Mreleasem(mp)// 返回创建的新 Goroutinereturn newg
}
总结起来,流程如下:
- 检查传递的函数值是否为
nil, 并获取当前M和P; - 获取或创建新的
Goroutine; - 初始化新
Goroutine,包括状态、堆栈指针、PC寄存器等; - 设置执行函数,为新
Goroutine分配要执行的函数,标记Goroutine为可运行状态,分配唯一的Goroutine ID,处理竞争检测和跟踪信息; - 返回新
Goroutine,使其可以被添加到运行队列并调度执行。
这边从简分析,主要分析这些流程中最重要的两大块: 获取或者创建新的Goroutine 和 Goroutine的属性金额关联设置。
获取/创建 Goroutine
先来看看 runtime.newproc1 中关于 Goroutine 结构体获取或者新创建的代码:
//go 1.20.3 path: /src/runtime/proc.gofunc newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {// ......// 尝试从 P 的可用 Goroutine 缓存中获取一个新的 Goroutinenewg := gfget(pp)if newg == nil {// 如果缓存中没有可用的 Goroutine,则创建一个新的 Goroutinenewg = malg(_StackMin)casgstatus(newg, _Gidle, _Gdead) // 设置 Goroutine 状态为 _Gdeadallgadd(newg) // 添加到所有 Goroutine 列表中}// ......
}
从上述代码看到逻辑很简单:
- 首先会通过
runtime.gfget从p.gFree或者sched.gFree列表中查找空闲的Goroutine; - 如果不存在空闲的
Goroutine,则调用runtime.malg创建一个栈大小足够的新结构体并加入全局Goroutine列表runtime.allgs中;
这里面涉及到几个函数 :runtime.gfget 、runtime.malg、allgadd 函数,我们一探究竟,追踪下这些函数的逻辑以及功能。
获取空闲G — runtime.gfget
runtime.gfget函数的主要作用和功能是:
- 从
P(Processor) 的空闲Goroutine列表(p.gFree)中获取一个空闲的Goroutine; - 如果当前
P没有可用的空闲Goroutine,它会尝试从全局Goroutine列表(sched.gFree)中获取Goroutines, 最后,函数返回获取到的Goroutine。
runtime.gfget 源码如下:
//go 1.20.3 path: /src/runtime/proc.gofunc gfget(pp *p) *g {
retry:// 检查当前处理器的 Goroutine 自由列表是否为空,以及全局 Goroutine 自由列表中是否有可用的 Goroutine。if pp.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) {// 获取全局 Goroutine自由列表的锁,确保多个线程不会同时修改。lock(&sched.gFree.lock)// 从全局 Goroutine自由列表中获取 Goroutine,填充到P的自由列表中,直到处理器的自由列表至少有 32 个 Goroutine。for pp.gFree.n < 32 {gp := sched.gFree.stack.pop()if gp == nil {gp = sched.gFree.noStack.pop()if gp == nil {break}}// 更新 Goroutine计数。sched.gFree.n--pp.gFree.push(gp)pp.gFree.n++}// 释放全局 Goroutine自由列表的锁。unlock(&sched.gFree.lock)// 再次尝试获取 Goroutine。goto retry}// 从处理器的自由列表中获取一个 Goroutine。gp := pp.gFree.pop()if gp == nil {return nil}pp.gFree.n--// 如果 Goroutine的堆栈不为空且大小不等于 startingStackSize,则释放其堆栈。if gp.stack.lo != 0 && gp.stack.hi-gp.stack.lo != uintptr(startingStackSize) {systemstack(func() {stackfree(gp.stack)gp.stack.lo = 0gp.stack.hi = 0gp.stackguard0 = 0})}// 如果 Goroutine的堆栈为空,则分配新的堆栈。if gp.stack.lo == 0 {systemstack(func() {gp.stack = stackalloc(startingStackSize)})gp.stackguard0 = gp.stack.lo + _StackGuard} else {// 其他处理,此处省略不详细解释。}return gp
}
代码就不再解释了,注释和上面的流程都写很明白了,这边需要注意的是:我们获取的G都会给其提供一个栈帧空间,是调用了 runtime.stackalloc在堆上给其分配一个 2K 的栈空间。
但如果 runtime.gfget无法从 相关 gFree 列表中获取到一个空闲的 Goroutine怎么办呢?
那就需要 runtime.malg出马了。
创建G结构 — runtime.malg
当 runtime.gfget 无法获取到一个空闲的 goroutine,则调用 runtime.malg初始化新的 runtime.g 结构,如果申请的堆栈大小大于 0,这里会通过 runtime.stackalloc分配 2KB 的栈空间:
//go 1.20.3 path: /src/runtime/proc.gofunc malg(stacksize int32) *g {newg := new(g) // 创建一个新的 g 结构体,赋值给 newgif stacksize >= 0 {stacksize = round2(_StackSystem + stacksize) // 将 stacksize 调整为大于等于 _StackSystem + stacksize 的最小的 2 的幂次方systemstack(func() { // 进入系统栈,确保下面的代码在系统栈上执行newg.stack = stackalloc(uint32(stacksize)) // 为 newg 的 stack 字段分配内存,内存大小为 stacksize 字节})newg.stackguard0 = newg.stack.lo + _StackGuard // 设置 stackguard0 字段,用于栈溢出检测newg.stackguard1 = ^uintptr(0) // 设置 stackguard1 字段,用于栈溢出检测*(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0 // 将 newg.stack.lo 的值设置为 0,标记此位置为空闲栈帧的起始位置}return newg
}
代码的功能是根据给定的 stacksize 创建一个新的 g 结构体。当 stacksize 大于等于 0 时,会为 g 结构体的 stack 字段分配 stacksize 大小的内存,并设置 stackguard0 和 stackguard1 字段用于栈溢出检测。
注意代码中的 systemstack 函数会将代码切换到系统栈上执行,这是为了确保在 g 结构体的 stack 字段分配内存时不会出现栈溢出的情况。最后将创建的新的 g 结构体返回。
至此,根据runtime.gfget与runtime.malg代码可以得出如下图的获取G的流程:
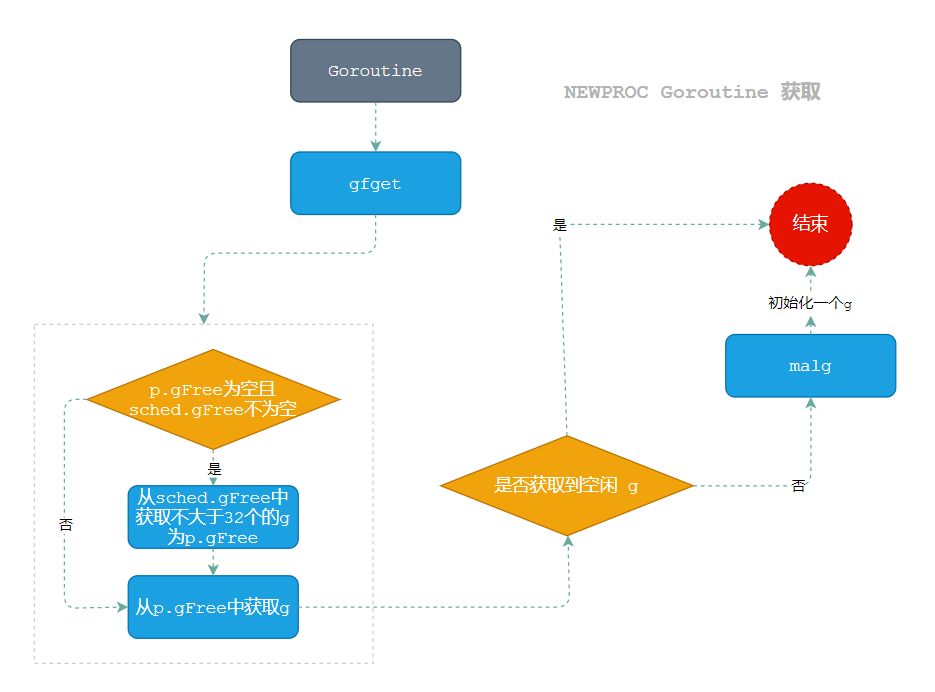
设置Goroutine属性以及调度信息
当我们获取通过runtime.gfget与runtime.malg获取到一个 goroutine,这个 goroutine只是一个简单的g结构体和栈帧结构,里面很多属性以及相关的调度信息都是没有设置的,并不具备调度和执行的条件,所以runtime.newproc1 函数后半段的工作就是完善这些信息,完整的后半段源码就不贴了,相关源码和注释前面都有给出。在这边,我们只挑些重点代码进行解析。
看代码前,我们需要知道的是goroutine 调度本质,其本质是:一组CPU寄存器和执行流的切换,当前我们执行某个g的时候,将BP,SP等寄存器设置为合适的值,将程序计数器pc指向g中的函数地址,这样g就被调度运行起来了,当要切换出当前g换其他g运行的时候,需要将当前g的CPU寄存器等信息保存到内存中,以供下次运行该g的时候,直接将保存到内存中的信息恢复到寄存器中又可以运行了。
知道明白了这个概念,再来让我们看看下面一段代码:
//go 1.20.3 path: /src/runtime/proc.gofunc newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {// ......// 清除 Goroutine 结构中的部分字段memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))// 设置 Goroutine 的堆栈指针等信息newg.sched.sp = spnewg.stktopsp = spnewg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantumnewg.sched.g = guintptr(unsafe.Pointer(newg))// ......// 初始化调用函数的 Goroutine 调度信息gostartcallfn(&newg.sched, fn)// ......// 设置 Goroutine 状态为 _Grunnable,准备执行casgstatus(newg, _Gdead, _Grunnable)newg.goid = pp.goidcache// ......
}
-
首先,调用
memclrNoHeapPointers将newg.sched的内存全部清零; -
接着,设置
newg.sched的sp字段,当goroutine被调度到m上运行时,需要通过sp字段来指示栈顶的位置,这里设置的就是新栈的栈顶位置; -
然后设置
newg.sched的pc字段,这是最关键的一句,我们看看代码:newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum,该代码设置pc字段为函数goexit的地址加1,也说是goexit函数的第二条指令,goexit函数是goroutine退出后的一些清理工作。为什么要这么设置呢?带着疑问继续往下看; -
继续执行
newg.sched.g = guintptr(unsafe.Pointer(newg))。这代码主要是设置g字段为newg的地址。插一句,sched是g结构体的一个字段,它本身也是一个结构体,保存调度信息。复习一下:type g struct {...sched gobuf // 存储 Goroutine的调度相关的数据(协程执行的上下文信息)... }// gobuf 描述了 Goroutine 的执行现场 type gobuf struct {sp uintptr // 栈指针,保存rsp寄存器的值pc uintptr // 程序计数器,保存rip寄存器的值g guintptr // 与gobuf关联的goroutine地址ctxt unsafe.Pointerret sys.Uintreg // 系统调用的返回值lr uintptrbp uintptr } -
经过上面流程的得到的
newg.sched还不完全是初始化后的Goroutine的最终结果,它还需要调用runtime.gostartcallfn来调整newg.sched成员和newg的栈,来看下runtime.gostartcallfn源码://go 1.20.3 path: /src/runtime/stack.gofunc gostartcallfn(gobuf *gobuf, fv *funcval) {var fn unsafe.Pointer // fn: gorotine 的入口地址,初始化时对应的是 runtime.mainif fv != nil {fn = unsafe.Pointer(fv.fn)} else {fn = unsafe.Pointer(abi.FuncPCABIInternal(nilfunc))}gostartcall(gobuf, fn, unsafe.Pointer(fv)) }func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {sp := buf.sp // newg 的栈顶,目前 newg 栈上只有 fn 函数的参数,sp 指向的是 fn 的第一参数sp -= goarch.PtrSize // 为返回地址预留空间// 这里填的是 newproc1 函数里设置的 goexit 函数的第二条指令// 伪装 fn 是被 goexit 函数调用的,使得 fn 执行完后返回到 goexit 继续执行,从而完成清理工作*(*uintptr)(unsafe.Pointer(sp)) = buf.pc// 重新设置 buf.spbuf.sp = sp// 当 goroutine 被调度起来执行时,会从这里的 pc 值开始执行,初始化时就是 runtime.mainbuf.pc = uintptr(fn)buf.ctxt = ctxt }函数
gostartcallfn只是拆解出了包含在funcval结构体里的函数指针,转过头就调用gostartcall。runtime.gostartcall函数将栈顶寄存器SP向下移动一个指针的位置,这是给返回地址留空间。接着就把
buf.pc填入了栈顶的位置,让我们回忆下,在前面buf.pc值被设置为:newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum,即goexit的第二条指令。然后又将buf.pc即newg.sched.pc重新设为fn函数入口,(初始化即为runtime.main函数入口)。相当于将goexit放到newg的栈顶,伪造成newg是被goeixt函数调用的,当newg中的fn函数执行完成之后,返回到goexit继续执行,做一些清理的操作。 -
之后,将
newg的状态改为runnable,设置goroutine的id。每个P每次会批量(16个)申请id,每次调用newproc函数,新创建一个goroutine,id加1。因此g0的id是0,而main goroutine的id就是1。
完成上述流程后,newg 的状态变成可执行后(Runnable),就可以将它加入到 P 的本地运行队列里,等待调度。goroutine 何时被执行,用户代码决定不了。
这时候的栈帧关系如下:
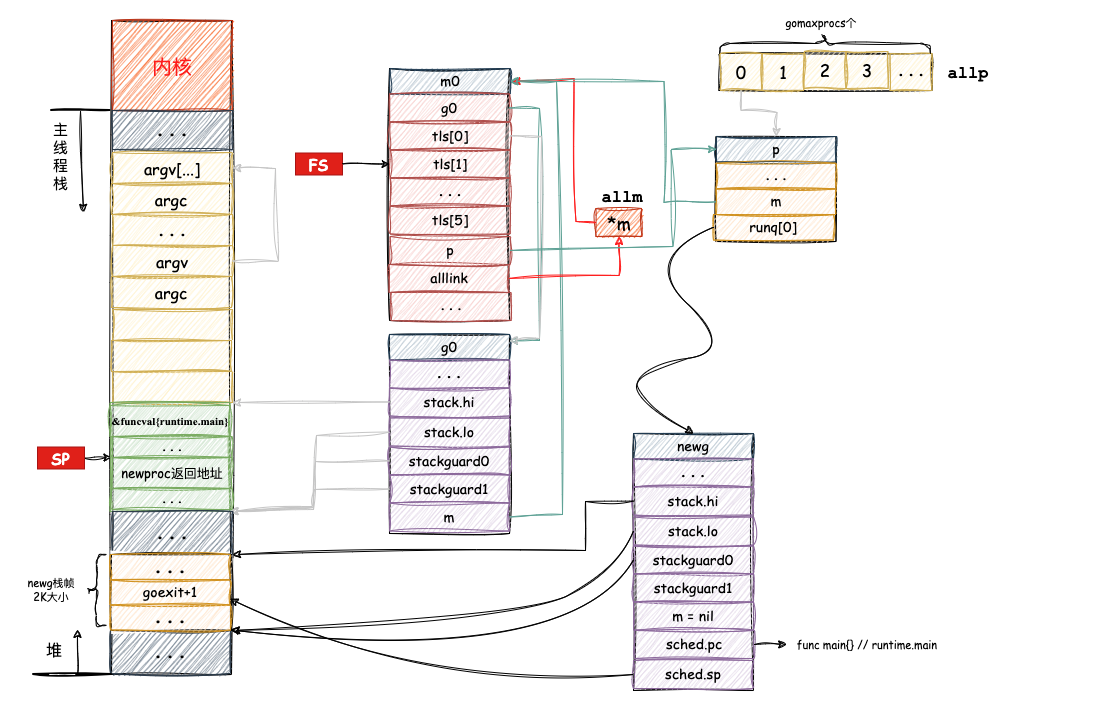
5.2 加入运行队列 — runtime.rungput
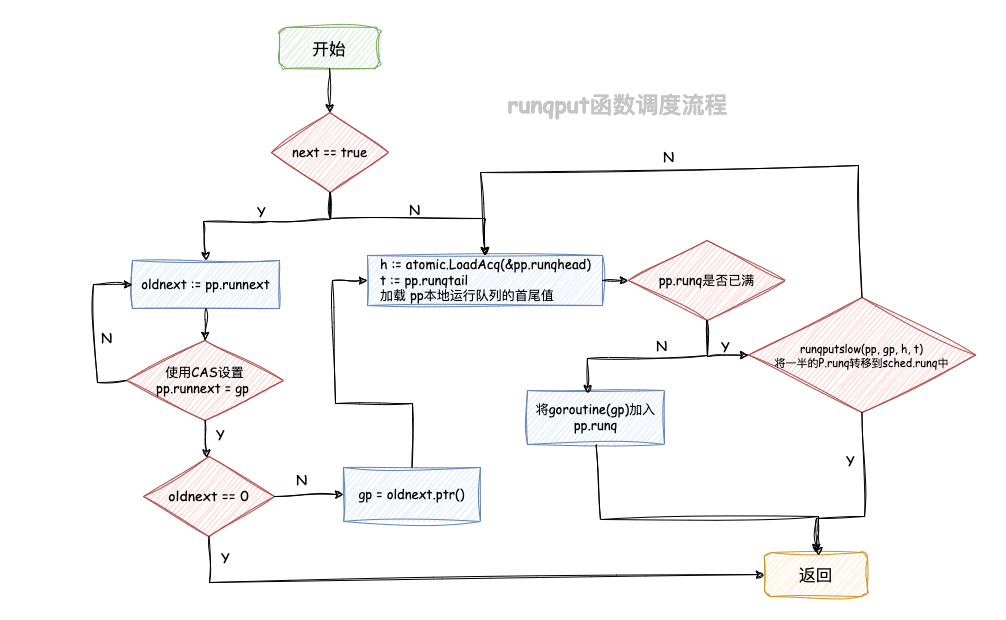
新创建 goroutine 的状态变成可执行后(Runnable),就可以将它加入到运行队列里,不管是P的本地队列p.runq还是调度器的全局队列sched.runq,然后等待调度。
将G加入队列,则是调用了函数runtime.runqput,其源码如下:
//go 1.20.3 path: /src/runtime/proc.go// 在调度器运行队列中插入一个 goroutine
func runqput(pp *p, gp *g, next bool) {// 如果启用随机调度并且 next为true 且随机数为偶数,则禁用 nextif randomizeScheduler && next && fastrandn(2) == 0 {next = false}// 如果 next 为 true,则尝试将当前 goroutine 放置在运行队列的 runnext 字段中if next {retryNext:oldnext := pp.runnext// 使用 Compare-and-Swap 操作将当前 goroutine 放置在 runnext 字段中if !pp.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {goto retryNext}// 如果 oldnext 为 0,则成功插入,否则更新 gp 为 oldnextif oldnext == 0 {return}gp = oldnext.ptr()}retry:// 从 pp 的运行队列头部加载值h := atomic.LoadAcq(&pp.runqhead)// 加载 pp 的运行队列尾部值t := pp.runqtail// 如果运行队列未满,则将当前 goroutine 放置在队列中if t-h < uint32(len(pp.runq)) {pp.runq[t%uint32(len(pp.runq))].set(gp)// 原子地更新 pp 的运行队列尾部值atomic.StoreRel(&pp.runqtail, t+1)return}// 如果运行队列已满,则调用 runqputslow 进行慢路径处理if runqputslow(pp, gp, h, t) {return}// 重试插入goto retry
}
来总结下该函数的主要流程:
-
如果启用了随机化调度(
randomizeScheduler为真),并且next为真且随机数生成的偶数为0,则禁用next; -
如果
next为真,则尝试将当前goroutine放置在运行队列的runnext字段中,作为下一个处理器执行的任务;更新runnext字段则使用cas操作(Compare-and-Swap)来原子操作,如果更新成功,说明成功插入,返回。 -
如果
P本地运行队列(pp.runq)未满,则将当前goroutine放置在运行队列中,更新队列尾部值后返回;如果P本地运行队列已满(P的本地可运行队列的长度为256,它是一个循环队列,因此最多只能放下256个goroutine),则调用runqputslow进行处理; -
如果
runqputslow处理失败,则说明本地队列在此过程中发生了变化,又有了位置可以添加goroutine,因此重试retry代码段。
而runtime.runqputslow函数主要是处理当本地运行队列(pp.runq)已经满了无法存放下新的 goroutine 的情况,其思路就是将部分 goroutine添加到调度器持有的全局运行队列sched.runq上去。直接来看runtime.runqputslow源码:
//go 1.20.3 path: /src/runtime/proc.go// 慢路径处理,用于将 goroutine 插入到全局运行队列中
func runqputslow(pp *p, gp *g, h, t uint32) bool {// 创建一个 goroutine 数组,大小为P本地运行队列的一半加一var batch [len(pp.runq)/2 + 1]*g// 计算运行队列中的 goroutine 数量n := t - hn = n / 2// 如果数量不等于运行队列的一半,抛出异常if n != uint32(len(pp.runq)/2) {throw("runqputslow: queue is not full")}// 将P本地运行队列中的 goroutine 拷贝到 batch 数组中for i := uint32(0); i < n; i++ {batch[i] = pp.runq[(h+i)%uint32(len(pp.runq))].ptr()}// 使用原子操作更新运行队列头部值if !atomic.CasRel(&pp.runqhead, h, h+n) {return false}// 将当前 goroutine 放置在 batch 数组的末尾batch[n] = gp// 如果启用随机化调度,则随机打乱 batch 数组中 goroutine 的顺序if randomizeScheduler {for i := uint32(1); i <= n; i++ {j := fastrandn(i + 1)batch[i], batch[j] = batch[j], batch[i]}}// 将 batch 数组中的 goroutine 串联起来for i := uint32(0); i < n; i++ {batch[i].schedlink.set(batch[i+1])}// 创建一个 gQueue 结构体,将 batch 数组的头尾连接起来var q gQueueq.head.set(batch[0])q.tail.set(batch[n])// 获取全局运行队列锁,将 batch 中的 goroutine 放入全局运行队列lock(&sched.lock)globrunqputbatch(&q, int32(n+1))unlock(&sched.lock)return true
}func globrunqputbatch(batch *gQueue, n int32) {assertLockHeld(&sched.lock)sched.runq.pushBackAll(*batch)sched.runqsize += n*batch = gQueue{}
}// 将 gQueue q2 中的所有元素推入到当前 gQueue q 的末尾
func (q *gQueue) pushBackAll(q2 gQueue) {// 如果 q2 的尾部为空,则不执行任何操作if q2.tail == 0 {return}// 将 q2 的尾部 goroutine 的 schedlink 设置为 0,表示链表结束q2.tail.ptr().schedlink = 0// 如果当前队列 q 的尾部不为空,将其尾部 goroutine 的 schedlink 设置为 q2 的头部if q.tail != 0 {q.tail.ptr().schedlink = q2.head} else {// 如果当前队列 q 的尾部为空,将其头部设置为 q2 的头部q.head = q2.head}// 更新当前队列 q 的尾部为 q2 的尾部q.tail = q2.tail
}这个函数是 runqput 的慢路径处理部分。它负责将部分 goroutine 插入到全局运行队列(sched.runq)中,主要包括以下步骤:
-
准备一个大小为
P本地运行队列(pp.runq)的一半加一的goroutine数组batch,并将P本地运行队列中的一半goroutine拷贝到batch数组中,随后更新P本地运行队列头部值pp.runqhead = pp.runqhead + len(pp.runq)/2; -
将当前
goroutine加入到在batch数组的末尾,然后将batch数组中的goroutine通过g.schedlink字段串联起(注意:如果开启随机调度,则要提前打乱batch数组顺序);goroutine串联成链表示意图: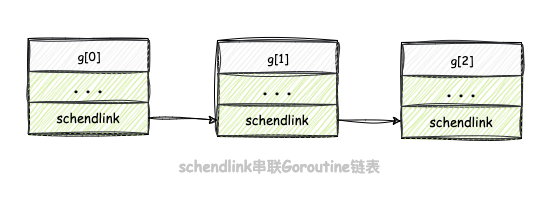
-
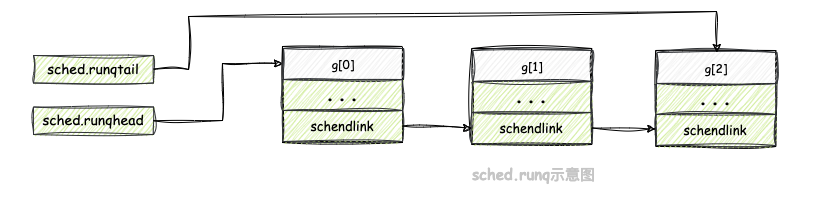
创建一个
gQueue结构体,将batch数组的头尾连接起来;获取全局运行队列锁,然后通过调用globrunqputbatch函数将gQueue中的goroutine放入全局运行队列(sched.runq)中;释放全局运行队列锁。gQueue设置完成示意图:
runtime.runqput基本内容就这些,用一张图总结下:
5.3 唤醒P对象 — runtime.wakep
新创建的goroutine放入运行队列中去等待调度后,再根据相关条件是否满足来决定是否执行 runtime.wakep操作:
//go 1.20.3 path: /src/runtime/proc.gofunc newproc(siz int32, fn *funcval) {...if mainStarted {//唤醒处理执行 Goroutinewakep()}...
}func main() {...mainStarted = true...
}
从代码可以看出,全局变量mainStarted会在runtime.main 被调用后被设置为true,之后普通协程的创建,则会调用runtime.wakep函数尝试唤醒空闲的P。
再来看看 runtime.wakep 函数:
//go 1.20.3 path: /src/runtime/proc.go// 唤醒一个休眠中的 P(Processor)
func wakep() {// 如果当前有M在自旋(spinning),或者自旋计数不为0,则直接返回if sched.nmspinning.Load() != 0 || !sched.nmspinning.CompareAndSwap(0, 1) {return}// 获取当前 M(执行上下文)mp := acquirem()var pp *p// 获取全局调度器锁lock(&sched.lock)// 尝试获取一个正在自旋的空闲 Ppp, _ = pidlegetSpinning(0)// 如果没有可用的 Pif pp == nil {// 减少自旋计数if sched.nmspinning.Add(-1) < 0 {throw("wakep: negative nmspinning")}// 释放全局调度器锁unlock(&sched.lock)// 释放当前 Mreleasem(mp)return}// 释放全局调度器锁unlock(&sched.lock)// 启动 M,开始执行startm(pp, true)// 释放当前 Mreleasem(mp)
}
wakep 的作用是唤醒一个休眠中的 P,使其能够开始执行 Go 协程,其主要流程为:
- 如果当前有
M在自旋(spinning),或者自旋计数不为0,则直接返回,避免重复唤醒和竞争条件,以确保在多线程环境中正确地处理自旋的M; - 使用
acquirem获取当前M,获取全局调度器锁,调用pidlegetSpinning函数尝试获取一个正在自旋的空闲P;如果空闲P获取失败,则则减少自旋计数,并释放锁,然后释放当前M; - 如果成功获取到一个正在自旋的空闲
P,则释放全局调度器锁,并调用startm启动一个M来执行相应的Go协程,然后释放当前M;
流程大致就是这么一个流程,下面将对该流程下出现的一些关联函数进行具体分析梳理:
M的启用 — runtime.startm
runtime.startm函数的主要功能是启动一个新的 M,使其执行 Go 协程。函数会负责获取或分配一个 P,然后创建一个新的 M 或者从 M 列表中获取一个空闲的 M。在创建新 M 之后,函数会检查新 M 的状态,并根据需要设置自旋状态、关联的 P,并唤醒可能在等待的 M。
源码如下:
//go 1.20.3 path: /src/runtime/proc.go// 启动一个 M,使其执行 Go 协程
func startm(pp *p, spinning bool) {// 获取当前 M(执行上下文)mp := acquirem()// 获取全局调度器锁lock(&sched.lock)// 如果没有给定 P,则从空闲P中获取一个if pp == nil {// 如果是自旋状态,抛出异常(自旋需要一个明确的 P)if spinning {throw("startm: P required for spinning=true")}// 从空闲 P 中获取一个pp, _ = pidleget(0)// 如果没有可用的 P,释放锁并返回if pp == nil {unlock(&sched.lock)releasem(mp)return}}// 获取一个新的 M 或者从 M 列表中获取一个空闲的 Mnmp := mget()if nmp == nil {// 如果没有可用的 M,为新 M 预留一个 ID,并释放锁id := mReserveID()unlock(&sched.lock)// 根据自旋状态创建一个新 M,并绑定到给定的 P 上var fn func()if spinning {fn = mspinning}newm(fn, pp, id)releasem(mp)return}// 如果新 M 正在自旋,抛出异常if nmp.spinning {throw("startm: m is spinning")}// 如果新 M 已经关联了 P,抛出异常if nmp.nextp != 0 {throw("startm: m has p")}// 如果是自旋状态且关联的 P 有可运行的 goroutine,抛出异常if spinning && !runqempty(pp) {throw("startm: p has runnable gs")}// 设置新 M 的自旋状态和关联的 P,唤醒可能在等待的 Mnmp.spinning = spinningnmp.nextp.set(pp)notewakeup(&nmp.park)// 释放全局调度器锁和当前 Munlock(&sched.lock)releasem(mp)
}获取空闲P — runtime.pidleget
runtime.pidleget函数的主要功能是从全局调度器的空闲 P 列表(sched.pidle)中获取一个可用的 P。如果存在可用的 P,函数会进行相应的操作,包括更新列表、减少数量、停止限速器事件等,并最终返回获取到的 P 和当前时间。这样,获取到的 P 就可以用于执行新的 goroutine。该函数源码:
//go 1.20.3 path: /src/runtime/proc.go// 从空闲 P 中获取一个 P
func pidleget(now int64) (*p, int64) {// 确保全局调度器锁已经被获取assertLockHeld(&sched.lock)// 获取当前空闲 P 的头部 Ppp := sched.pidle.ptr()if pp != nil {// 如果当前时间为0,则获取当前时间if now == 0 {now = nanotime()}// 设置当前 P 的定时器标志timerpMask.set(pp.id)// 清除当前 P 的空闲标志idlepMask.clear(pp.id)// 更新全局调度器的空闲 P 列表sched.pidle = pp.link// 减少全局调度器的空闲 P 数量sched.npidle.Add(-1)// 停止当前 P 的限速器事件pp.limiterEvent.stop(limiterEventIdle, now)}// 返回获取到的 P 和当前时间return pp, now
}获取空闲M — runtime.mget
runtime.mget函数的主要功能是从全局调度器的空闲 M 列表(sched.midle)中获取一个可用的 M。如果存在可用的 M,函数会进行相应的操作,包括更新列表、减少数量等,并最终返回获取到的 M。源码如下:
//go 1.20.3 path: /src/runtime/proc.go// 从空闲 M 中获取一个 M
func mget() *m {// 确保全局调度器锁已经被获取assertLockHeld(&sched.lock)// 获取当前空闲 M 的头部 Mmp := sched.midle.ptr()if mp != nil {// 更新全局调度器的空闲 M 列表sched.midle = mp.schedlink// 减少全局调度器的空闲 M 数量sched.nmidle--}// 返回获取到的 Mreturn mp
}与runtime.mget函数相关的函数还有runtime.mput,该函数的作用是将一个空闲的M存放进空闲 M 列表中(sched.midle):
//go 1.20.3 path: /src/runtime/proc.go
func mput(mp *m) {assertLockHeld(&sched.lock)mp.schedlink = sched.midlesched.midle.set(mp)sched.nmidle++checkdead()
}
M的创建 — runtime.newm
runtime.newm函数的主要功能是创建一个新的 M(执行上下文)。函数负责分配新 M 的资源、初始化字段,并根据调用的上下文(是否在锁定的线程上调用)来进行适当的处理。如果在锁定的线程上调用,将新 M 添加到线程模板的队列中。如果不在锁定的线程上调用,调用 newm1 函数继续处理新 M 的启动。
函数源码如下:
//go 1.20.3 path: /src/runtime/proc.go// 创建一个新的 M(执行上下文)
func newm(fn func(), pp *p, id int64) {// 获取当前 M(执行上下文)acquirem()// 分配一个新的 M,并初始化一些字段mp := allocm(pp, fn, id)mp.nextp.set(pp)mp.sigmask = initSigmask// 检查是否在锁定的线程上调用,并处理线程模板if gp := getg(); gp != nil && gp.m != nil && (gp.m.lockedExt != 0 || gp.m.incgo) && GOOS != "plan9" {// 如果在锁定的线程上调用,将新 M 添加到线程模板的队列中lock(&newmHandoff.lock)if newmHandoff.haveTemplateThread == 0 {throw("on a locked thread with no template thread")}mp.schedlink = newmHandoff.newmnewmHandoff.newm.set(mp)if newmHandoff.waiting {newmHandoff.waiting = falsenotewakeup(&newmHandoff.wake)}unlock(&newmHandoff.lock)releasem(getg().m)return}// 不在锁定的线程上调用,调用 newm1 函数处理新 M 的启动newm1(mp)releasem(getg().m)
}
分析代码改函数的主要流程为:
- 获得当前
M的资源信息并调用runtime.allocm分配一个新的M并初始化一些字段(nextp、sigmask); - 获得当前
G,如果满足 当前G已经被对应的M绑定且当前M被外部代码锁定或由CGO调用且操作系统不是Plan 9则执行使用newmHandoff来协调创建新的M,创建完成后释放当前线程的M资源并返回; - 如果不满足2条件,则调用
runtime.newm1函数在新的操作系统线程上启动一个新的M。它设置线程属性、信号屏蔽集,创建新线程,并将执行的起点设置为mstart_stub函数,最终启动了一个新的M。
这里涉及到了两个函数: runtime.allocm 和 runtime.newm1,我们下面进行分析下。
runtime.allocm
runtime.allocm函数的主要功能是分配一个新的 M(执行上下文)。函数会尝试整理释放掉sched.freem列表,然后会向操作系统请求新的内存块。最后,函数会创建一个新的 M,并初始化相应的字段。函数源码如下:
//go 1.20.3 path: /src/runtime/proc.go// 分配一个新的 M(执行上下文)
func allocm(pp *p, fn func(), id int64) *m {// 读取分配 M 的锁allocmLock.rlock()// 获取当前 M(执行上下文)acquirem()// 获取当前 G(goroutine)gp := getg()// 如果当前 G 所属的 M 的 P 为0,说明当前G不在P 上执行if gp.m.p == 0 {// 如果不在 P 上执行,尝试获取指定的 Pacquirep(pp)}// 尝试整理释放掉sched.freem列表if sched.freem != nil {lock(&sched.lock)var newList *m// 遍历调度器中的freem链表 for freem := sched.freem; freem != nil; {//获取freem节点的等待状态wait,可能为freeMWait或者freeMStackwait := freem.freeWait.Load()/**freeMWait表示释放的M处于等待状态, 当一个M被释放后,如果有其他M正在使用它,该M会被放入 sched.freem 链表,并设置 sched.freem.freeWait 为 freeMWait;当一个M被释放后,如果有其他M正在使用它,该M会被放入 sched.freem 链表,并设置 sched.freem.freeWait 为 freeMWait;freeMStack表示释放的M的堆栈内存也需要被释放,当一个M被释放后,如果其堆栈内存也需要被释放(例如,该M的堆栈内存是由系统分配的),则设置 sched.freem.freeWait 为 freeMStack;在释放M的时候,会检查 sched.freem.freeWait 的状态,如果为 freeMStack,则会调用 stackfree 函数释放M的堆栈内存*/// 如果等待状态为freeMWait,进行清理freem列表if wait == freeMWait {next := freem.freelinkfreem.freelink = newListnewList = freemfreem = nextcontinue}// 如果等待状态为freeMStack,进行freem节点的堆栈清理if wait == freeMStack {// 处理释放 M 时关联的堆栈内存systemstack(func() {stackfree(freem.g0.stack)})}freem = freem.freelink}sched.freem = newListunlock(&sched.lock)}// 创建一个新的 M,并初始化一些字段mp := new(m)mp.mstartfn = fnmcommoninit(mp, id)// 如果是 cgo 或者 M 的堆栈由系统分配,则使用 malg(-1) 分配 G 的内存// 否则,使用 malg 分配指定大小的 G 的内存if iscgo || mStackIsSystemAllocated() {mp.g0 = malg(-1)} else {mp.g0 = malg(8192 * sys.StackGuardMultiplier)}mp.g0.m = mp// 如果指定了 P,并且当前 G 所属的 M 的 P 等于指定的 P,则释放指定的 Pif pp == gp.m.p.ptr() {releasep()}// 释放当前 Mreleasem(gp.m)// 释放分配 M 的锁allocmLock.runlock()// 返回分配的 Mreturn mp
}
runtime.newm1
runtime.newm1函数的主要功能是启动一个新的 M(执行上下文)。在 cgo 环境下,它通过 _cgo_thread_start 函数在新的线程上执行 mstart 函数。在非 cgo 环境下,它直接调用 newosproc 函数,在新的操作系统线程上启动一个新的 M。函数源码如下:
//go 1.20.3 path: /src/runtime/proc.go// 启动一个新的 M(执行上下文)
func newm1(mp *m) {// 如果是 cgo 环境if iscgo {// ... 省略cgo环境处理代码return}// 不是 cgo 环境,直接调用 newosproc 函数execLock.rlock()newosproc(mp)execLock.runlock()
}
在非cgo 环境下,runtime.newosproc是整个runtime.newm1函数核心,基本的逻辑代码在该函数中,源码如下:
//go 1.20.3 path: /src/runtime/proc.go// 在新的操作系统线程上启动一个新的 M(执行上下文)
func newosproc(mp *m) {//获得当前 M(操作系统线程)关联的 G0(系统线程使用的 goroutine)的栈顶地址stk := unsafe.Pointer(mp.g0.stack.hi)// ...// 初始化 pthreadattr 结构体,pthread_attr结构体通常用于设置新创建线程的一些属性,例如:Stack Size(栈大小)和Detached State(分离状态)var attr pthreadattrvar err int32err = pthread_attr_init(&attr)if err != 0 {writeErrStr(failthreadcreate)exit(1)}// 获取线程栈大小,通过 pthread_attr_setstacksize 可以设置新线程的栈大小。var stacksize uintptrif pthread_attr_getstacksize(&attr, &stacksize) != 0 {writeErrStr(failthreadcreate)exit(1)}mp.g0.stack.hi = stacksize // 设置 M 的栈顶地址,用于 mstart// 设置线程属性为分离状态,通过 pthread_attr_setdetachstate 可以设置线程的分离状态if pthread_attr_setdetachstate(&attr, _PTHREAD_CREATE_DETACHED) != 0 {writeErrStr(failthreadcreate)exit(1)}// 保存当前信号屏蔽集,然后设置全局信号屏蔽集var oset sigsetsigprocmask(_SIG_SETMASK, &sigset_all, &oset)// 创建新的线程,调用 mstart_stub 函数err = retryOnEAGAIN(func() int32 {return pthread_create(&attr, abi.FuncPCABI0(mstart_stub), unsafe.Pointer(mp))})// 恢复之前保存的信号屏蔽集sigprocmask(_SIG_SETMASK, &oset, nil)// 处理创建线程失败的情况if err != 0 {writeErrStr(failthreadcreate)exit(1)}
M的唤醒 — notewakeup
//go 1.20.3 path: /src/runtime/lock_sema.gofunc notewakeup(n *note) {var v uintptr// 循环直到成功获取 note 锁for {v = atomic.Loaduintptr(&n.key) // 获取 note 的当前 key 值if atomic.Casuintptr(&n.key, v, locked) { // 尝试使用 CAS 获取锁break}}// 根据 note 的 key 值进行判断和处理switch {case v == 0:// 没有 goroutine 在等待,什么也不做case v == locked:// note 已经处于锁定状态,表示重复唤醒throw("notewakeup - double wakeup")default:// 通过将 uintptr 转换回 M 类型,唤醒等待的 goroutinesemawakeup((*m)(unsafe.Pointer(v)))}
}func semawakeup(mp *m) {pthread_mutex_lock(&mp.mutex) // 获取 m 的互斥锁mp.count++ // 增加 m 的计数器if mp.count > 0 {pthread_cond_signal(&mp.cond) // 如果计数器大于 0,通过条件变量唤醒等待的线程}pthread_mutex_unlock(&mp.mutex) // 释放 m 的互斥
}
至此的话,创建完任务G后,将G放入了P的LOCAL队列或者是全局队列,然后开始获取了一个空闲的M或者新建一个M来执行G,M, P, G 都已经准备完成了,下面就是开始调度,来运行任务G了。
6. 启动调度器
runtime·rt0_go中在调用完runtime.newproc后,继续后面的流程,代码如下:
TEXT runtime·rt0_go<ABIInternal>(SB),NOSPLIT,$0...CALL runtime·mstart(SB)CALL runtime·abort(SB)RET
runtime.mstart 函数是 Go 运行时系统中的一个关键函数,用于启动 M(操作系统线程),是 Go 运行时系统中 M 的入口点。
M执行G有两个起点,一个是线程启动函数 mstart, 另一个则是休眠被唤醒后的调度schedule了,我们从头开始,也就是mstart, mstart 走到最后也是 schedule 调度。
而runtime.mstart 函数最终调用的是runtime.mstart0:
TEXT runtime·mstart(SB),NOSPLIT|TOPFRAME,$0CALL runtime·mstart0(SB)RET // not reached
来看runtime.mstart0的源码:
//go 1.20.3 path: /src/runtime/proc.gofunc mstart0() {gp := getg() // 获取当前 goroutine 的 G 对象osStack := gp.stack.lo == 0 // 检查是否为操作系统分配的栈if osStack {size := gp.stack.hiif size == 0 {size = 8192 * sys.StackGuardMultiplier}// 设置 goroutine 的栈范围gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))gp.stack.lo = gp.stack.hi - size + 1024}gp.stackguard0 = gp.stack.lo + _StackGuard // 设置栈的 guard 区域,用于检测栈溢出gp.stackguard1 = gp.stackguard0mstart1() // 进入 M 的主要执行函数 mstart1()// 如果栈是由操作系统分配的,则标记为操作系统栈if mStackIsSystemAllocated() {osStack = true}// 退出 M,参数表示是否为操作系统分配的栈mexit(osStack)
}该函数主要流程是:
- 如果当前的栈是由操作系统分配的(
osStack := gp.stack.lo == 0),则设置goroutine的栈范围,这确保goroutine拥有足够的栈空间供其执行; - 设置栈的
guard区域,用于检测栈溢出。gp.stackguard0和gp.stackguard1分别表示栈的两个guard区域; - 调用
mstart1函数: 进入M的主要执行函数runtime.mstart1,在这个函数中M会执行调度循环,不断从全局运行队列中获取G(goroutine)并执行; - 如果栈是由操作系统分配的,则标记为操作系统栈,调用
mexit函数,表示M的任务执行结束。
其中第3步骤的runtime.mstart1较为重要,源码如下:
//go 1.20.3 path: /src/runtime/proc.gofunc mstart1() {gp := getg() // 获取当前 goroutine 的 G 对象if gp != gp.m.g0 {throw("bad runtime·mstart") // 检查是否是正确的 runtime·mstart 函数调用}gp.sched.g = guintptr(unsafe.Pointer(gp)) // 设置当前 G 的 sched.g 字段为 G 的地址gp.sched.pc = getcallerpc() // 设置当前 G 的 sched.pc 字段为调用者的 PCgp.sched.sp = getcallersp() // 设置当前 G 的 sched.sp 字段为调用者的 SPasminit() // 初始化汇编相关的内容minit() // 初始化 M 相关的内容if gp.m == &m0 {mstartm0() // 如果是初始 M,则调用 mstartm0 函数}if fn := gp.m.mstartfn; fn != nil {fn() // 调用注册的 mstart 函数}if gp.m != &m0 {acquirep(gp.m.nextp.ptr()) // 获取下一个 Pgp.m.nextp = 0 // 清空当前 G 的 nextp 字段}schedule() // 进入调度循环
}
该函数主要流程如下:
-
获取当前
goroutine的G对象,检查是否是正确的runtime·mstart函数调用,确保当前G属于M0; -
设置当前
G的sched.g字段为G的地址,设置当前G的sched.pc字段为调用者的PC,设置当前G的sched.sp字段为调用者的SP; -
调用
asminit函数初始化汇编相关的内容,调用minit函数初始化M相关的内容;minit函数主要用于初始化M(操作系统线程)的一些属性,包括备用信号栈、信号屏蔽和线程ID://go 1.20.3 path: /src/runtime/os_darwin.go func minit() {// iOS 不支持备用信号栈。// 信号处理程序直接处理它。if !(GOOS == "ios" && GOARCH == "arm64") {minitSignalStack() // 初始化备用信号栈}minitSignalMask() // 初始化信号屏蔽getg().m.procid = uint64(pthread_self()) // 获取当前线程的 ID,并赋值给当前 M 的 procid 字段 } -
如果当前
M是初始M0,则调用mstartm0函数;如果fn是gp.m.mstartfn,则调用注册的mstart函数;mstartm0函数主要用于在启动M的初始线程(M0)时执行一些初始化工作。代码如下://go 1.20.3 path: /src/runtime/proc.go func mstartm0() {// 如果是 cgo 或者是 Windows,且尚未为 cgo 创建额外的 M(操作系统线程)if (iscgo || GOOS == "windows") && !cgoHasExtraM {cgoHasExtraM = true // 标记已经创建了额外的 Mnewextram() // 为 cgo 创建额外的 M}initsig(false) // 初始化信号处理,参数表示是否需要启动分配额外的信号栈 } -
如果当前
M不是初始M0,则获取下一个P并清空当前G的nextp字段; -
调用
schedule函数, 进入调度循环,从全局运行队列中获取G并执行。
可以看到mstart1函数保存额调度相关的信息,特别是保存了正在运行的g0的下一条指令和栈顶地址, 这些调度信息对于goroutine而言是很重要的。
至此,程序启动的几个流程都讲完了,过程中也将GMP等各个结构体初始化、G的生成、P的生成、M的生成等的相关内容也进行了一一分析。接下来就是golang调度系统的核心函数runtime.schedule了, 这块内容讲放到循环调度一起讲。
参考资料:
刘丹冰Aceld https://www.bilibili.com/video/BV19r4y1w7Nx
幼麟实验室 https://space.bilibili.com/567195437
draveness https://draveness.me/golang/docs
changkun https://golang.design/under-the-hood/zh-cn
CSDN https://baijiahao.baidu.com/s?id=1687308494061329777&wfr=spider&for=pc
https://segmentfault.com/a/1190000039378412?utm_source=tag-newest
https://thinkwon.blog.csdn.net/article/details/102021274?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-102021274-blog-124747195.pc_relevant_multi_platform_whitelistv4&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-102021274-blog-124747195.pc_relevant_multi_platform_whitelistv4&utm_relevant_index=2
[数据小冰] https://mp.weixin.qq.com/s?__biz=MzA3MzIxMjY1NA==&mid=2648488025&idx=1&sn=b9c636ecfd29bf59a6ba8a7b02c148bd&chksm=873a6fd8b04de6ceb0dbee26287edb0c441b1650f9d256f99f46d84dc2a6ae176999d61fa408&scene=178&cur_album_id=1868300478069948416#rd
这篇关于GO调度模型-GMP(上)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


