本文主要是介绍GeoServer发布ImageMasic(影像镶嵌数据集),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:如果你有很多井影像,拼接起来的影像很大,而你又不想拼接的时候,你就可以使用GeoServer发布ImageMosaic,即影像的镶嵌数据集。当然ImageMosaic的另一个妙用是,可以对单幅非tif影像去黑边,如单幅img影像。 
注意:如果你的GeoServer没有安装GDAL的拓展,那么你的ImageMosaic支持的格式就很少,比如tif可以,img就不行。如果你还不知道如何安装GDAL的拓展,请移步这篇博文: GeoServer安装GDAL拓展。
一、声明
之所以要提前说明,是因为GeoServer发布ImageMosaic是有一些坑的,不过看到这篇文章的你很幸运,你会完美的避过这些坑,因为我已经踩过了,而我又将这些坑分享了出来。
坑1:GeoServer发布ImageMosaic,不需要你手动在arcgis里生成镶嵌数据集的footprint(轮廓),注意是footprint,不是boundary(边界), 你只需要将所有要拼接的影像放在一个文件夹里,GeoServer会自动帮你生成这个footprint的shp,而这个shp里就是几个相互重叠的面数据,分别表示每个影像所处的位置。
这里要吐槽一下百度能搜到的GeoServer发布ImageMosaic的教程,几乎都是在arcgis手动生成footprint的shp,并且这个shp,GeoServer根本不认,真是害人不浅啊。
坑2:前面我们已经说过了,GeoServer会自己帮你生成一个footprint(轮廓)的shp,而这个shp的名称是GeoServer根据你放置影像的文件夹命名的,所以这个文件夹命名如果是中文的,那么生成这个shp的时候就会报错,所以你最好放置影像的文件夹命名不要出现中文。
坑3:还是跟这个生成的shp有关,我们在坑1里说过了,这个shp里是几个相互重叠的面数据,而这些面数据表示的是影像的位置。shp中有个字段叫做location,存的是影像的名称,所以如果你的影像命名是中文的,那么GeoServer也是不识别的,但是他这个在你新建数据存储和发布图层的时候都不会报错,但是当你图层预览的时候,他就会报错:cannot create mosaic。
坑4:使用arcgis做影像导出和格式转换的时候,千万不要提升像素深度,一旦提升了像素深度,GeoServer发布的时候,就是一片黑,识别不出来了,这是一个非常非常隐蔽的坑,切记!切记!
二、再次声明
再次强调,一定一定要仔细阅读上面四个坑的说明,这样发布Image Mosaic的时候才不会出现一些莫名其妙的错误,比如:
1、可以发布tif镶嵌数据集,但是影像和影像之间的有黑色背景
2、可以发布img镶嵌数据集,影像和影像之间也去掉了黑色背景,但是影像的整体的黑色背景去不掉
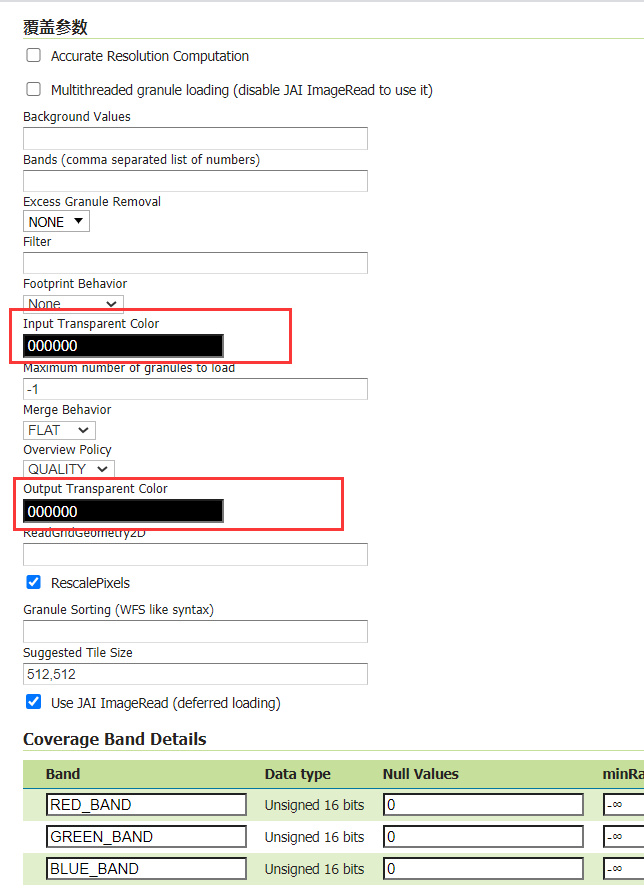
3、不能设置InputTransparentColor,一旦设置了,图层预览就会报错。根据GeoServer官方文档,这个参数是用来控制影像重叠区域的黑色背景的。
4、不能设置OupPutTransparentColor,一旦设置了,也就无法预览了,而这个参数,是用来控制整个拼接好的影像的黑色背景的。
三、正式开始发布
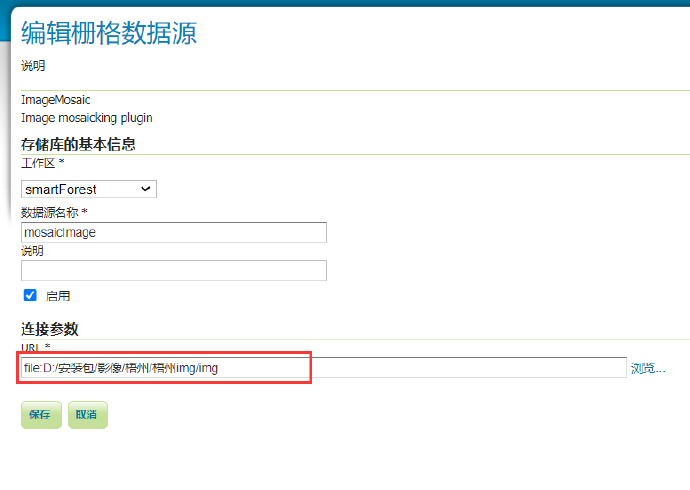
1、新建数据存储,选择ImageMosaic
2、路径选择我们存放影像的 文件夹
注意:文件夹名称必须是英文,里面的影像也必须是英文
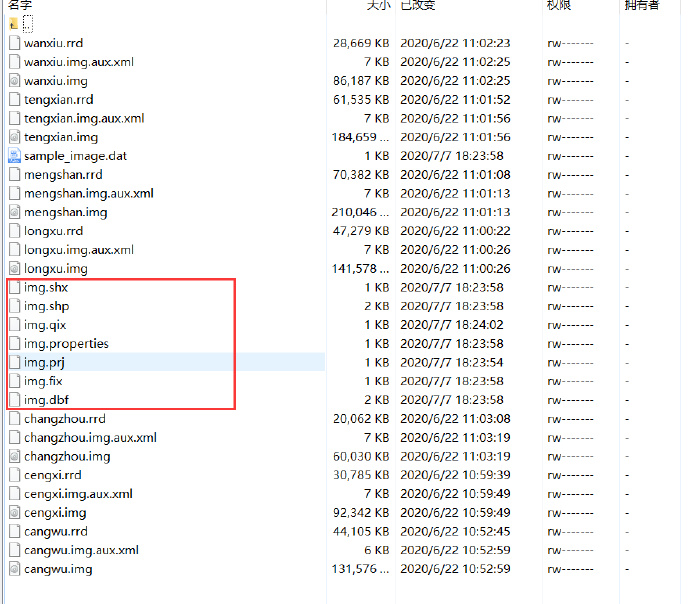
3、点击保存,查看是否生成了对应的shp文件和properties文件
可以看到,已经自动生成了shp文件和properties文件,这个shp文件比我们在arcgis生成的shp文件多了 .fix 和 .qix文件,这就完美解释了为什么我们在arcgis里生成的轮廓文件,在GeoServer里不识别。
4.图层发布
拉到图层设置的最底部,将InputTransparentColor设置为000000,将OutPutTransparentColor也设置为000000,当然,这两个参数设置为FFFFFF或者nodata,GeoServer也是识别的。
5、图层预览
设置前:
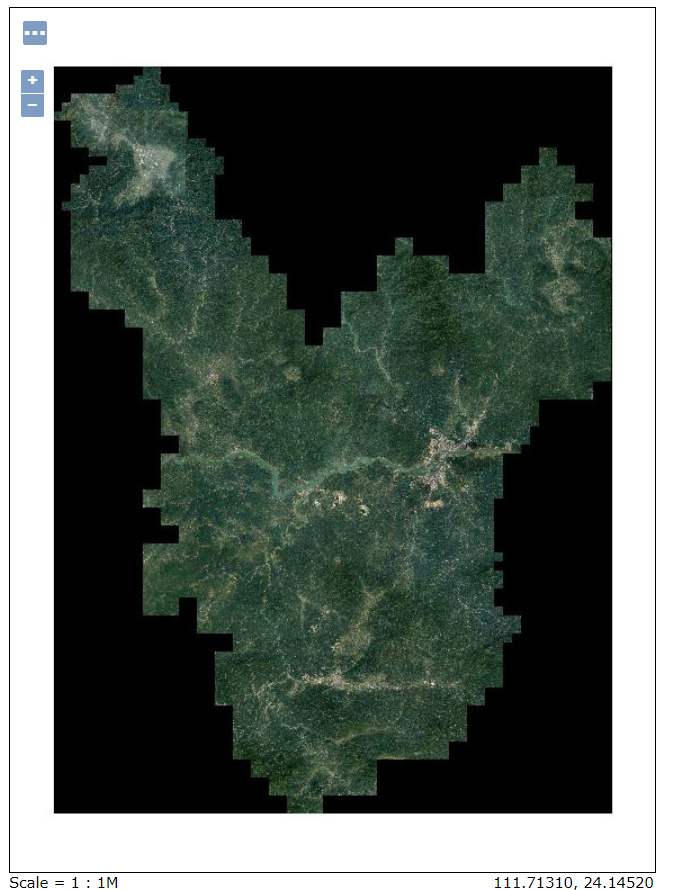
设置后:
6、疑难解答
如果你在图层预览的时候报错了,那么你要仔仔细细检查一下,我们在上面说过四个坑。
那么,本次教程我们就分享到这里,关于GeoServer发布影像的教程,我们连着出了三篇博客,应该涉及到了影像的方方面面,后面我会考虑出一版GeoServer版本迁移教程和影像的时间序列发布教程,敬请期待~
这篇关于GeoServer发布ImageMasic(影像镶嵌数据集)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






