本文主要是介绍山海鲸可视化软件:多场景下的数据呈现利器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在当今数据驱动的时代,数据可视化成为了企业和个人不可或缺的工具。作为一个老数据人,本文想借用自己常用山海鲸可视化软件,带大家了解在不同使用场景下数据可视化的应用。山海鲸可视化是一款可以免费编辑、本地化部署的产品,对数据可视化新人来说十分友好,下面介绍其典型五个应用场景。
1. 数据可视化看板
在企业管理中,数据可视化看板是展示关键业绩指标(KPI)和监控业务动态的重要工具。山海鲸可视化软件提供了丰富的图表类型和交互功能,使得企业能够轻松构建个性化的数据看板。无论是销售数据、库存情况还是用户行为分析,山海鲸都能将数据以直观、动态的方式呈现,帮助管理者快速把握业务状况。

2. 工厂
在工业生产中,实时监控和数据分析对于提高生产效率、保障安全至关重要。山海鲸可视化软件能够与工厂的各种传感器和设备连接,实时采集数据并生成可视化报告。通过直观的图表和预警功能,工厂管理者可以实时监控生产线的运行状态、能源消耗和产品质量,从而及时发现问题、优化生产流程。
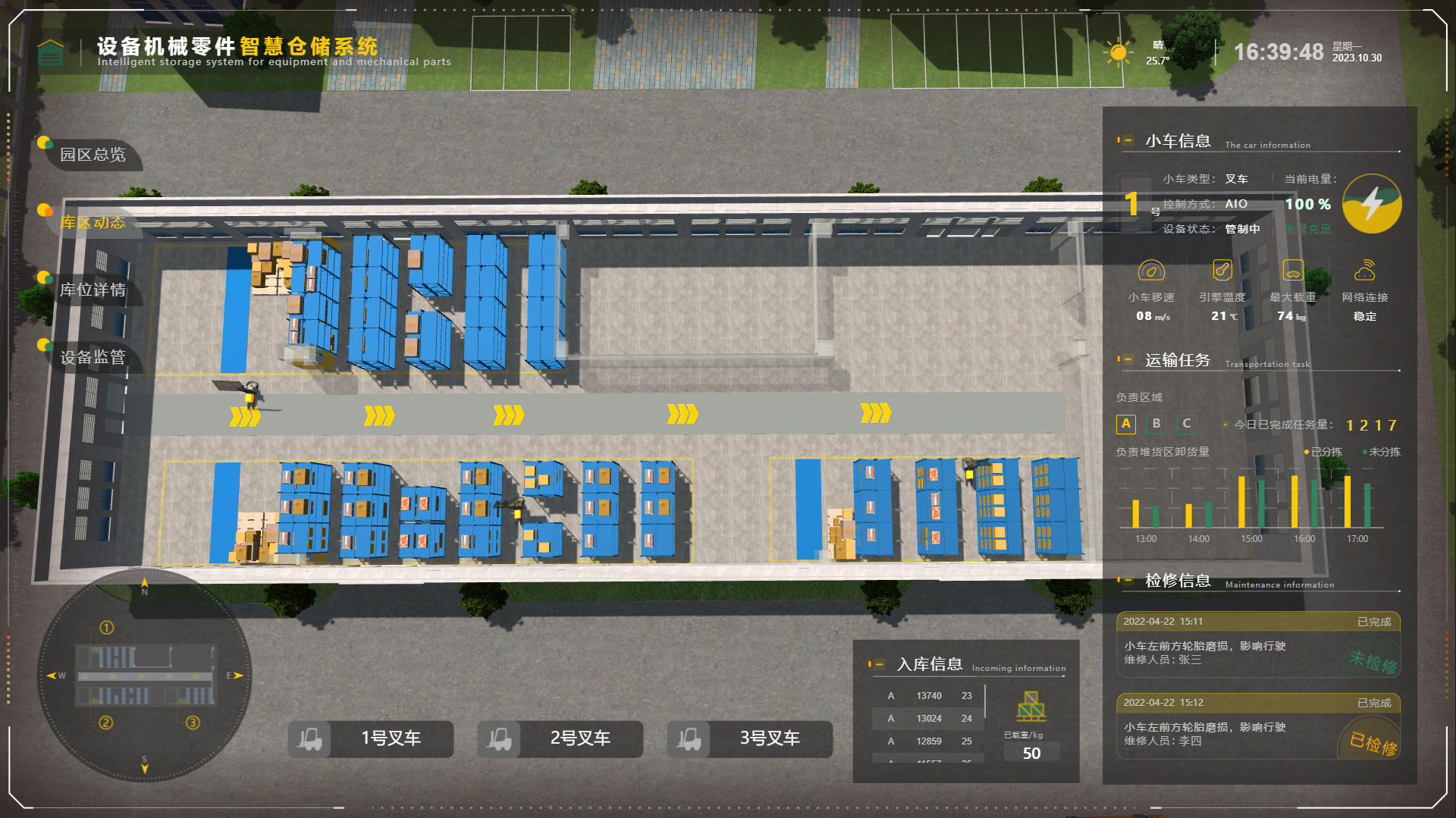
3. 教育
在教育领域,数据可视化能够帮助学生更好地理解知识、提升学习效果。山海鲸可视化软件提供了简单易用的操作界面和丰富的图表类型,使得教育者能够轻松创建教学用的数据可视化内容。无论是数学统计、物理模拟还是地理数据分析,山海鲸都能帮助教育者将复杂的数据转化为直观、有趣的形式,激发学生的学习兴趣。

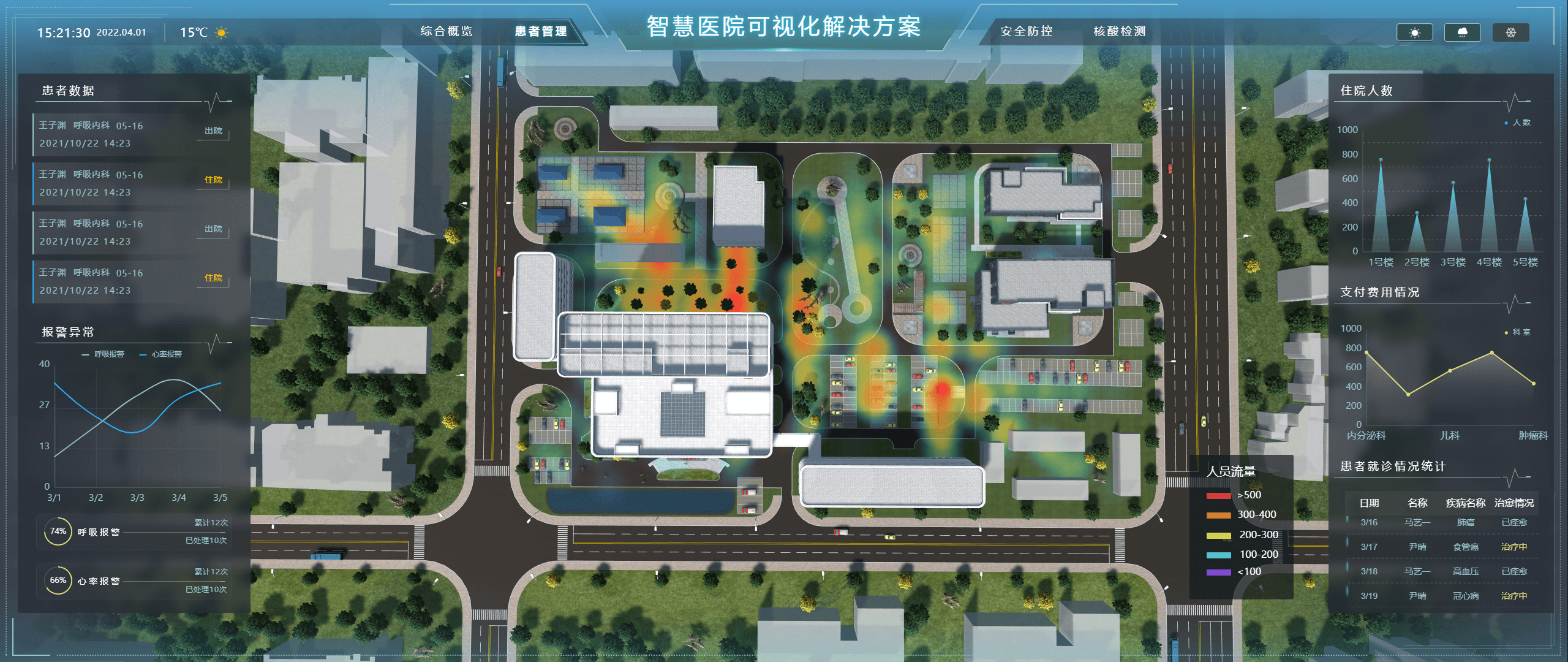
4. 医疗
在医疗领域,数据可视化对于诊断疾病、制定治疗方案具有重要意义。山海鲸可视化软件能够整合医疗机构的各类数据资源,如患者信息、医学图像和实验结果等,通过强大的可视化功能帮助医生快速获取关键信息、提高诊断准确性。同时,山海鲸还支持数据分析和挖掘功能,为医学研究提供有力支持。
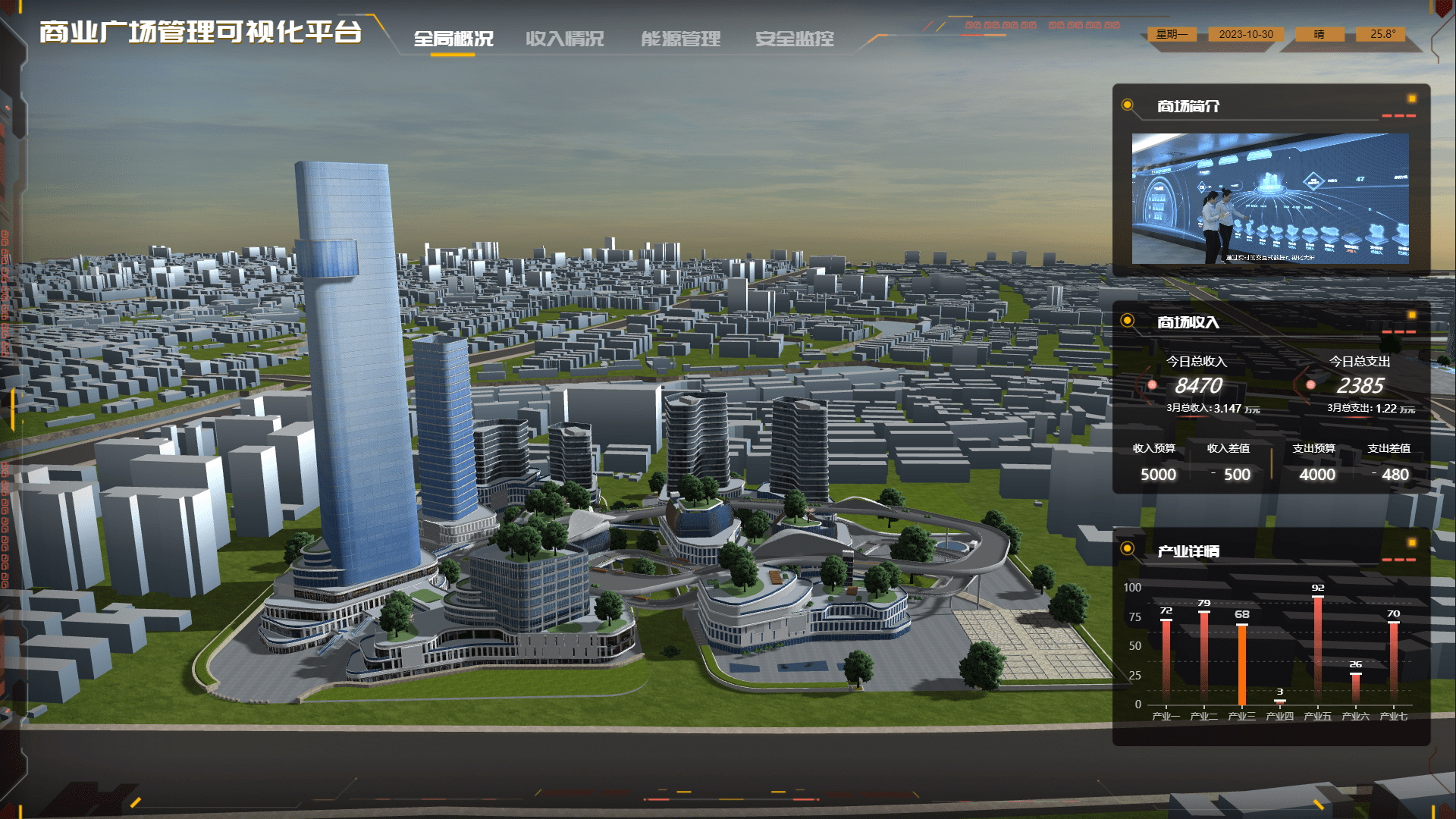
5. 园区
在智慧园区管理中,山海鲸可视化软件能够帮助管理者实时监控园区的各项运营数据,如能源消耗、安全监控和交通流量等。通过直观的图表和报告,管理者可以全面掌握园区的运行状况、发现潜在问题并及时采取措施。这有助于提高园区的运营效率、保障安全并提升服务质量。
综上所述,数据可视化在不同领域都发挥着重要作用。无论是企业管理、工业生产、教育培训、医疗诊断还是智慧园区管理,数据可视化都能为用户提供高效、直观的可视化解决方案。
这篇关于山海鲸可视化软件:多场景下的数据呈现利器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







