本文主要是介绍django请求生命周期流程图,路由匹配,路由有名无名反向解析,路由分发,名称空间,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
django请求生命周期流程图
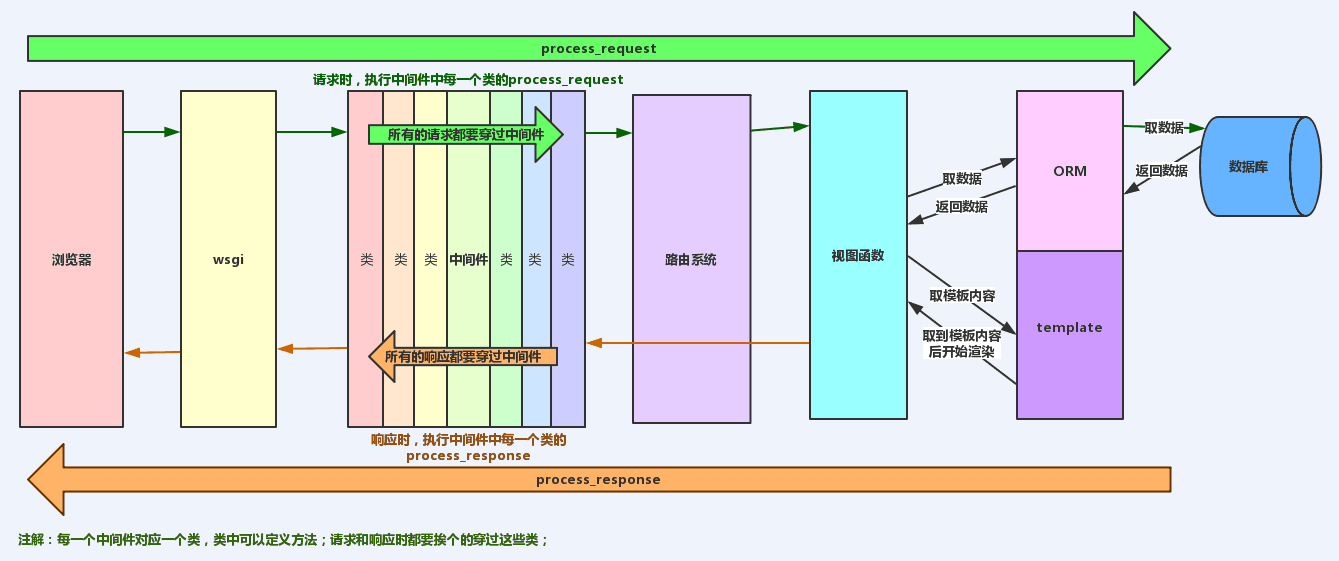
浏览器发起请求。
先经过网关接口,Django自带的是wsgiref,请求来的时候解析封装,响应走的时候打包处理,这个wsgiref模块本身能够支持的并发量很少,最多1000左右,上线之后会换成uwsgi,并且还会加nginx。
往后就到Django框架了,先经过中间件,中间件处理请求。
再到路由层做路由匹配和分发。
然后到视图层进行业务处理,ORM处理数据,从数据库取到数据返回给视图层,在模板层进行数据渲染,返回数据。
中间件处理响应。WSGI返回响应,浏览器进行渲染。
路由匹配
路由匹配就是在django项目中,建立的urls文件中的urlpatterns里面的path,我们可以称之为对应关系,每一个path都是一组对应关系,下面我们就来深入探讨路由匹配
基本格式
path('网址后缀',函数名) # 这里的函数名可以是我们在views文件中的函数名也可以是models中的类名
当网址后缀匹配成功,后面的函数名就会自动执行
路由结尾的斜杠(django二次确认机制)
eg: path('home/',views.home)
我们在html页面中访问的时候后缀一般不都是/home/嘛,那我们觉得输入/home是会报错的吧?
但是django很牛逼,它会自动给我们做一个二次处理,如果第一次没有匹配上,会让浏览器加上斜杠再次请求
你看嘛↓ 牛逼吧

django配置文件中也可以指定是否自动添加斜杠
APPEND_SLASH = False 正常人我估计是不会去用它的
path转换器
当我们网址后缀不固定的时候 可以使用转换器来匹配
语法: path('func/<int:year>/<str:info>/', views.func)
1.转换器匹配到的内容会当做视图函数的关键字参数传入
2.在这里<int:year> <str:info>他们是两个关键字参数
3.转换器有几个叫什么名字 那么视图函数的形参必须对应
def func(request,year,info):
pass
主要有以下几个转换器 常用的有 int str
'int': IntConverter(),
'path': PathConverter(),
'slug': SlugConverter(),
'str': StringConverter(),
'uuid': UUIDConverter(),re_path正则匹配
首先需要在urls中导一个模块 from django.urls import path,re_path
用法:re_path(正则表达式,函数名)
一旦网址后缀的正则能够匹配到内容就会自动执行后面的函数,并结束整个路由的匹配
eg: re_path('^index/$', views.index)
你看,你看 我这里用的是正则

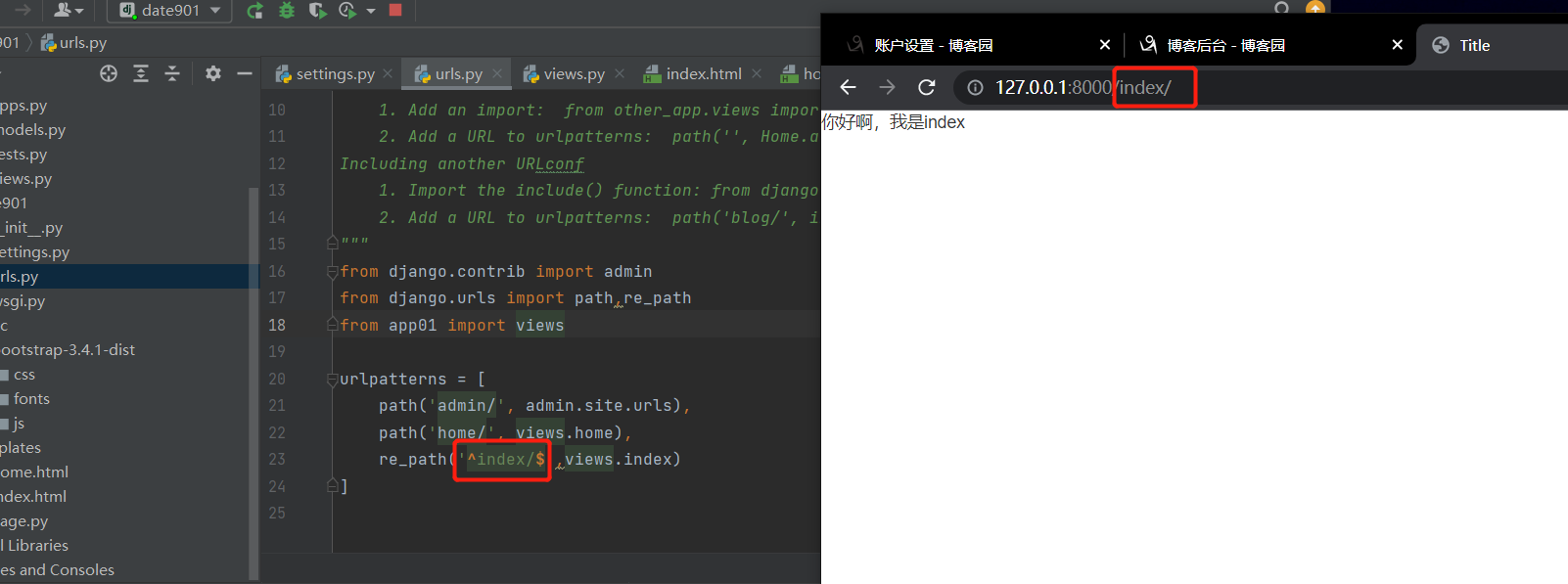
当网址后缀不固定的时候 可以使用转换器来匹配
正则匹配之无名分组
在正则表达式中我们的分组就是给正则表达式加上括号,其实在这里也一样
re_path('^index/(\d+)/', views.index) 可以设置多个分组后缀
但是,在这里分组后正则表达式匹配到的内容会当做视图函数的位置参数传递给视图函数
所以在视图函数中我们还要加上一个位置参数

正则匹配之有名分组
理论上来讲有名分组和无名分组是差不多的,区别在于有名分组要给正则表达式起别名
re_path('^index/(?P<year>\d+)/(?P<others>.*?)/', views.index)
正则表达式匹配到的内容会当做视图函数的关键字参数传递给视图函数
你来看,

django版本区别
在django1.11中 只支持正则匹配 并且方法是 url()
django2,3,4中 path() re_path() 等价于 url()
路由反向解析
我们在写路由(就是urls中的对应关系)的时候,很容易把路由写死,一旦路由发生变化会导致所有页面相关链接失效
这可咋办???
这个时候就要用到我们的反向解析
那什么是反向解析:
返回一个结果 该结果可以访问到对应的路由
语法:
1. 路由对应关系起别名 我通过这个别名就能找到对应的页面
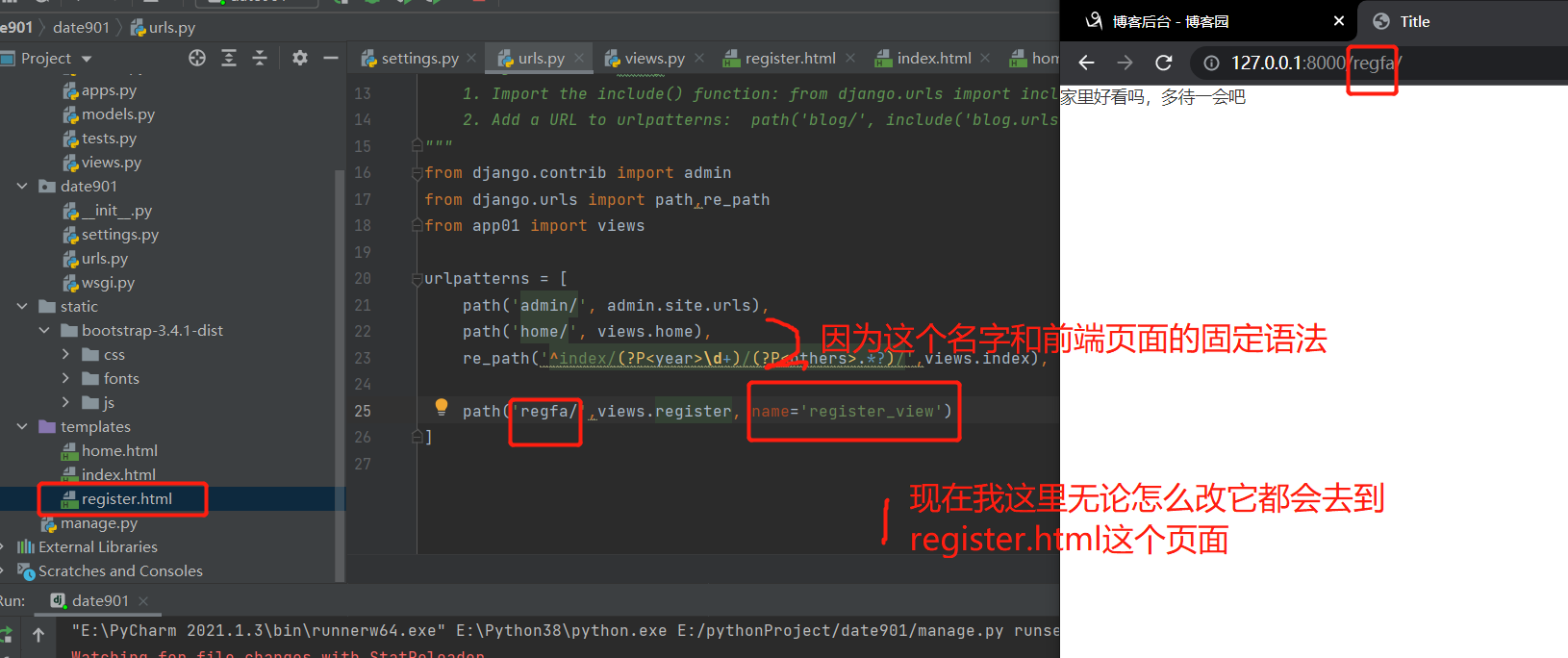
path('reg/', views.register, name='register_view')
2. 使用反向解析语法html页面
<a>{% url 'reg_view' %}</a>
ps:反向解析的操作三个方法都一样path() re_path() url()
come look 贼好用

补充一下 reverse
这个东西可以帮我们解析出当前访问的是哪个路由
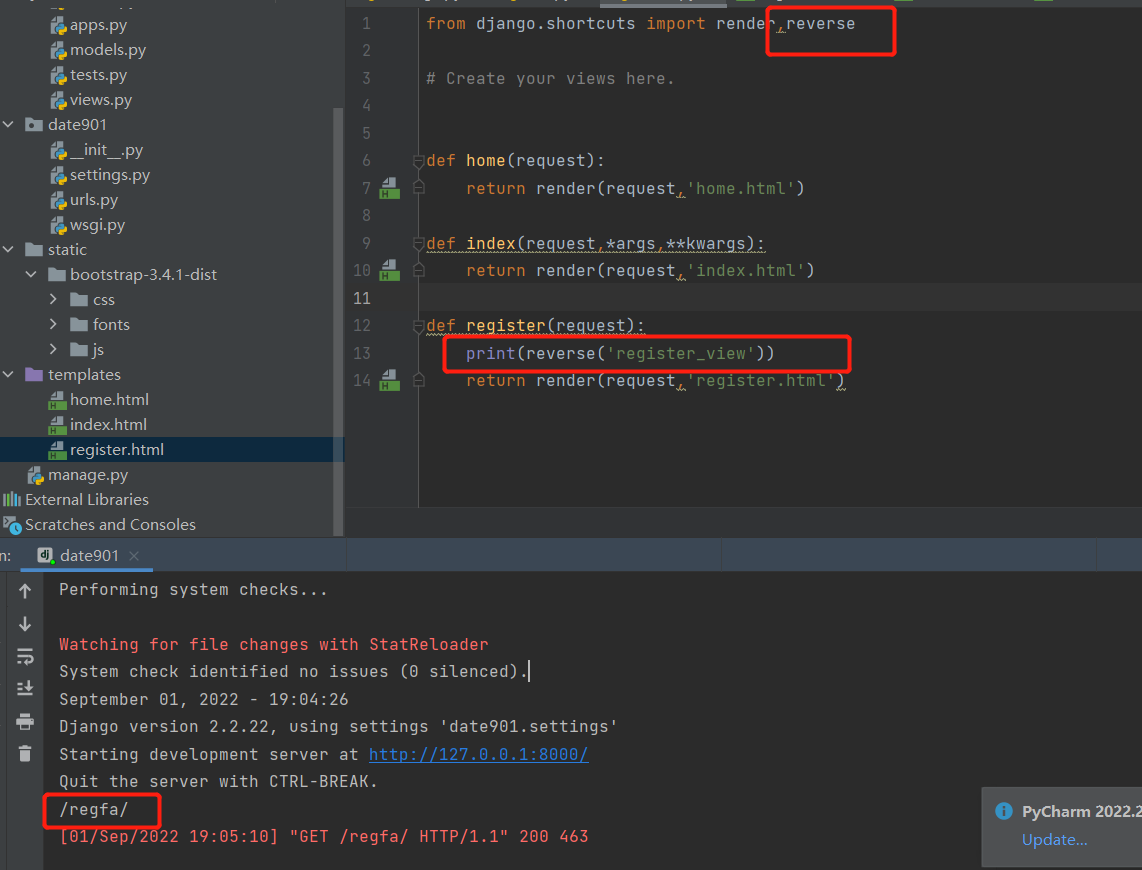
无名有名反向解析
这个时候我们再来研究一个问题
假设我们刚才的路由后缀后面还跟着一个东西<str: info>/:
path('regfa/<str:info>/',views.register, name='register_view')
我们知道<str: info>/这个东西可以接收任意的字符串,
这个时候我们再去访问home.html会报这个错误

就是说它解析不了这个路由,有点垃圾
但是,我们可以通过人为的方式进行修改,就是说路由中如果有不确定的数据,那么反向解析需要人为的方式传递数据
不想写了直接看图吧,兄弟们
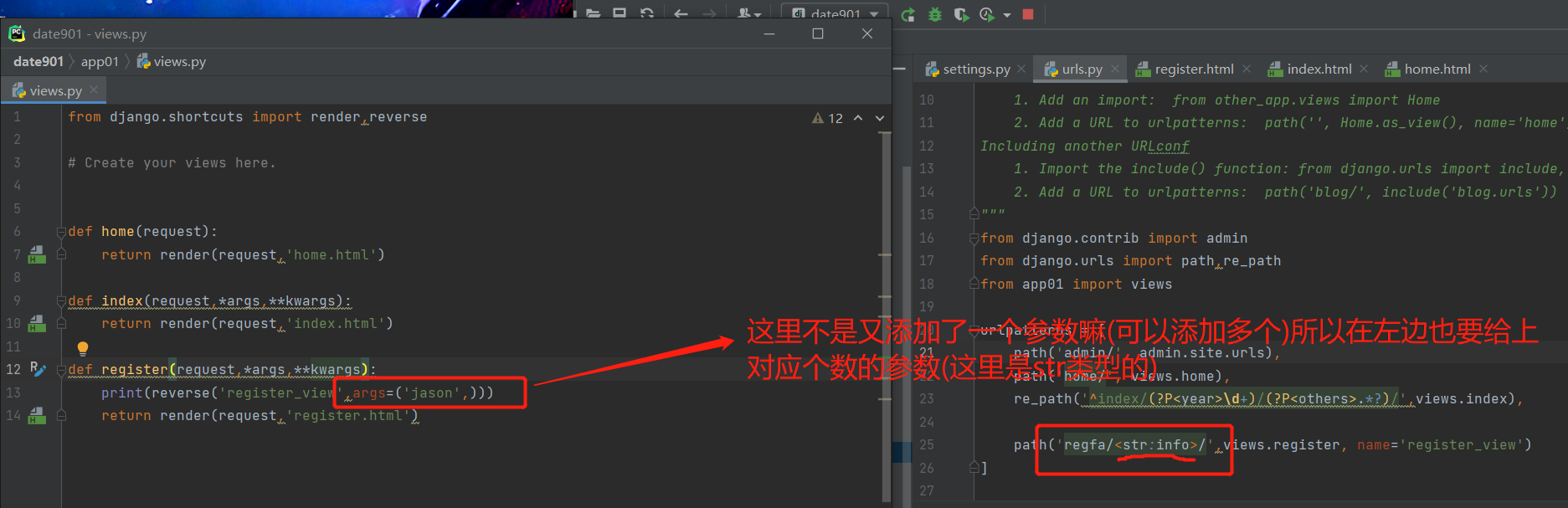
同时,在我们的前端页面也要进行修改

其实,到这里我们肯定还有疑惑,
我懂你,上面给定的字符串啦等不是随意的,是根据你将来执行什么样的业务就起什么样的参数名,没办法,只能这样了
ps:反向解析的操作三个方法都一样path() re_path() url()
路由分发
我们知道django中的应用都可以有自己独立的 我们也可以将他看作开发目录规范
eg: urls.py templates文件夹 static文件夹
能够让基于django开发的多个应用完全独立 便于小组开发
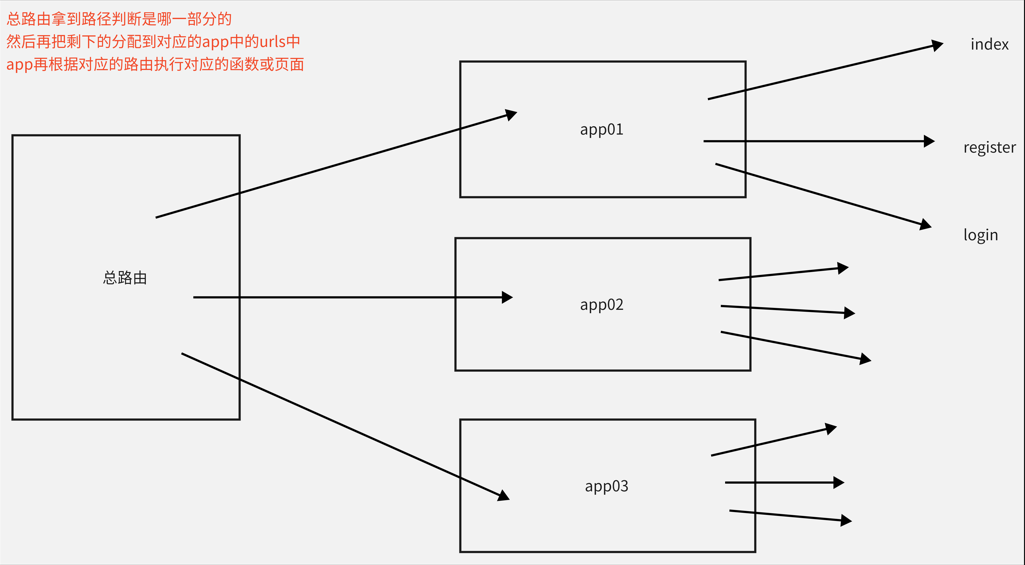
同样的我们针对路由也应该划分总路由和子路由
总路由盒子路由的功能示意图及流程
下面创建app (用到startapp app名 这个命令)
创建完app别忘了在settings中注册一下 这很重要 相信我
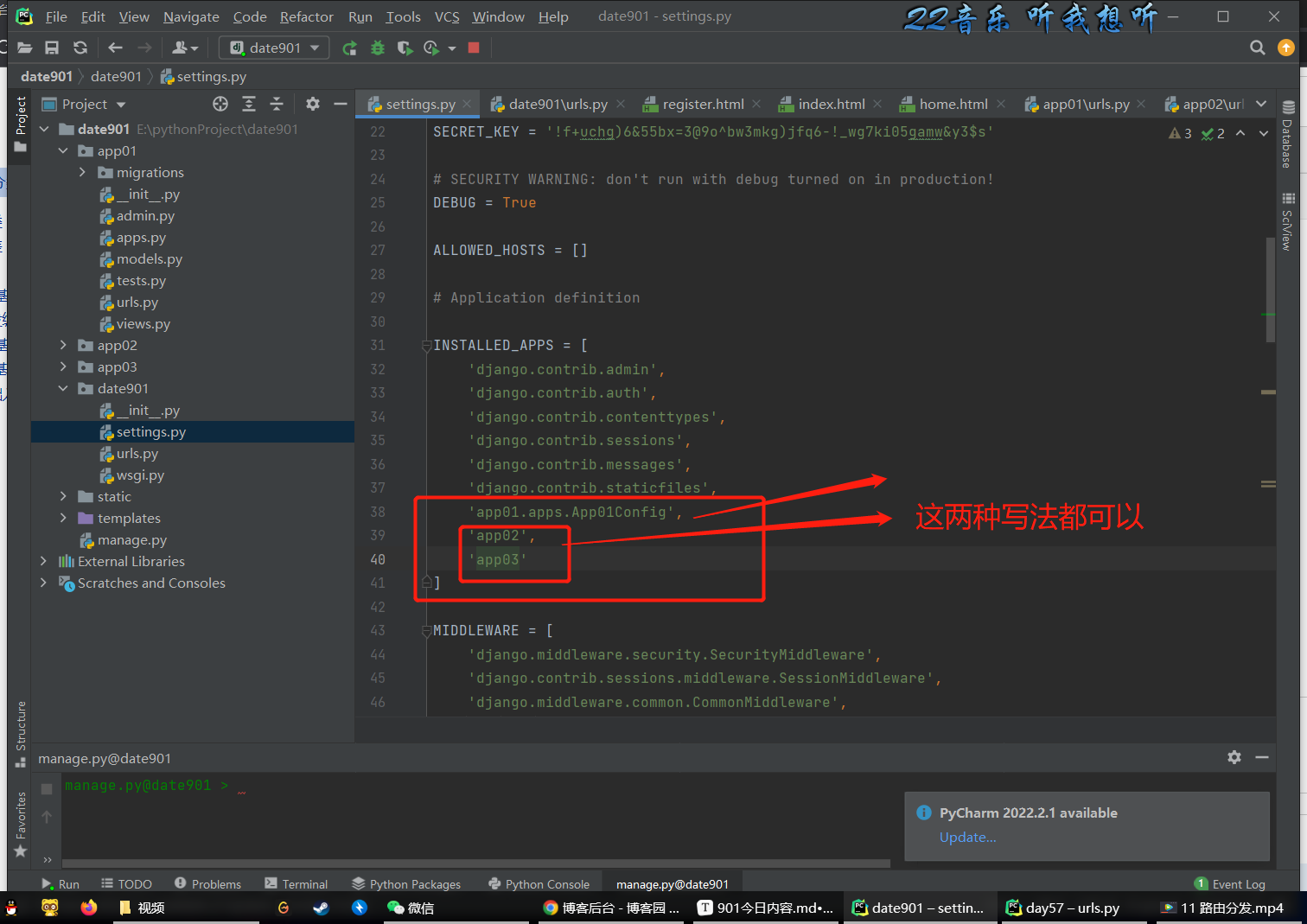
之后再在总路由的urls中分发路由的给各个app的urls并且每个app中的urls你都要写一下app中的一些路由

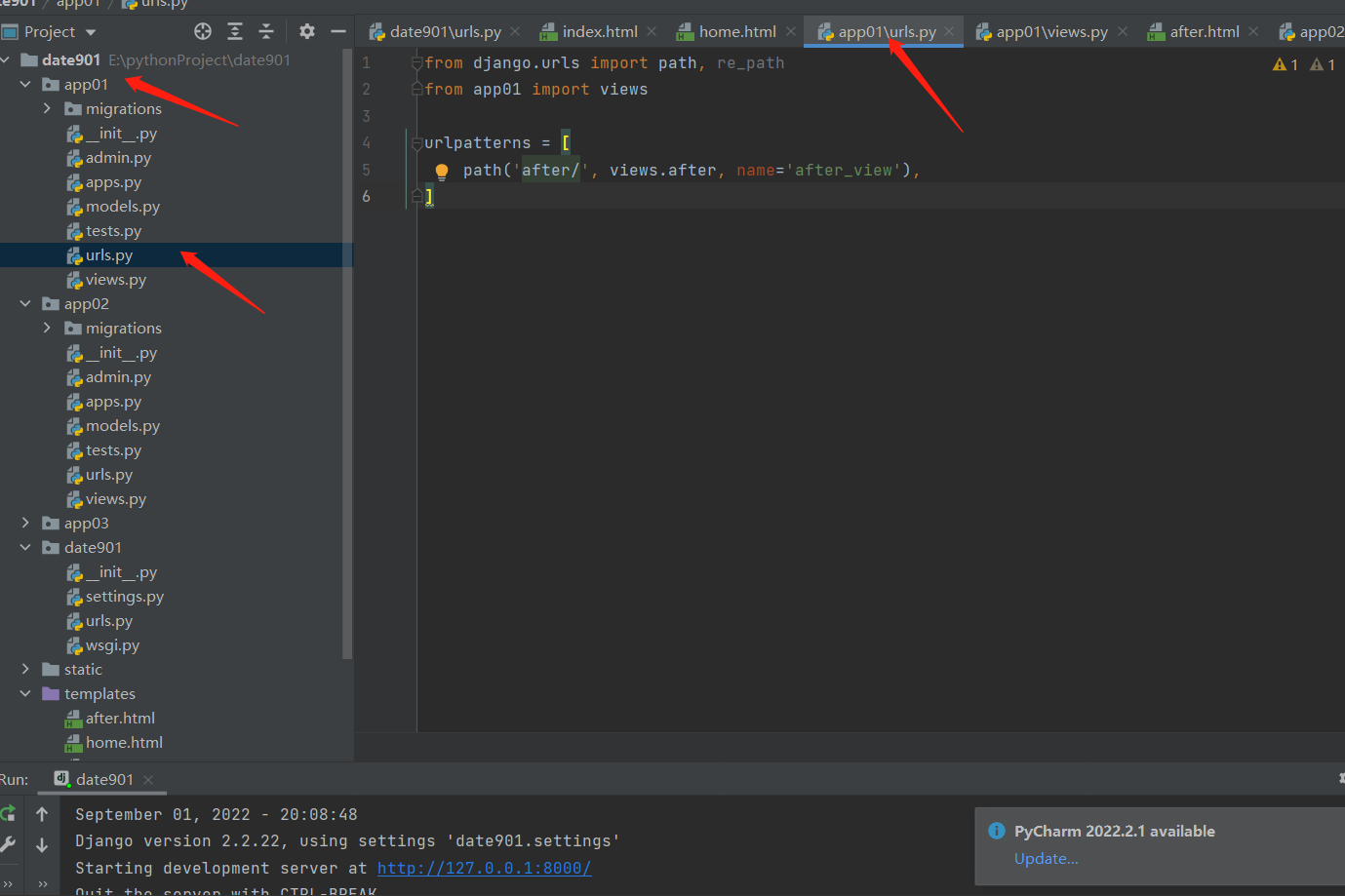
总路由path('app01/', include('app01.urls')),path('app02/', include('app02.urls')),
子路由path('after/', views.after) # app01path('after/', views.after) # app02总结include
我们把总路由中的分配路由这句话单独拿出来看
path('app01/', include('app01.urls'))
这句话的意思就是说
1.总路由先拿到访问的地址的全部的后缀名,判断第一个后缀名是不是在这个项目中,
2. 如果在那么他就会把app01/后面的后缀名传到app01的urls中
3. app01的urls拿到总路由传来的后缀名再次判断该执行那个功能
名称空间
有路由分发场景下多个应用在涉及到反向解析别名冲突的时候无法正常解析
解决方式1
namespacepath('app01/', include(('app01.urls', 'app01'), namespace='app01'))path('app01/', include(('app01.urls', 'app02'), namespace='app02'))解决方式2
别名不冲突即可(用这个用这个用这个!!!!!)
app01_你的路由
在app的urls中要写上
app: path('after/', views.after, name='app01_after_view')
这篇关于django请求生命周期流程图,路由匹配,路由有名无名反向解析,路由分发,名称空间的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






