本文主要是介绍2020 ||门控通道注意力机制Gated Channel Transformation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Gated Channel Transformation for Visual Recognition
论文链接: https://arxiv.org/abs/1909.11519
代码地址: https://github.com/z-x-yang/GCT
CSDN(这个是详细的解说):https://blog.csdn.net/weixin_47196664/article/details/108414207?ops_request_misc=&request_id=&biz_id=102&utm_term=%E9%97%A8%E6%8E%A7%E6%B3%A8%E6%84%8F%E5%8A%9B&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-108414207.nonecase
我这篇精简了一点,附上了更详细的实现代码。
GCT更倾向于鼓励浅层次的合作,但竞争在更深层次得到增强。一般来说,浅层学习低级属性用来捕获一般特征,比如纹理。在更深的层次中,高级特征更具判别性而且与任务息息相关。我们的实验表明,GCT是一种简单有效的通道间关系建模体系结构。它显著提高了深度卷积网络在视觉识别任务和数据集上的泛化能力(亲测确实有效牛牪犇)。
论文经过研究发现,把该门控机制加在Conv层的前面,训练出来的效果最好。
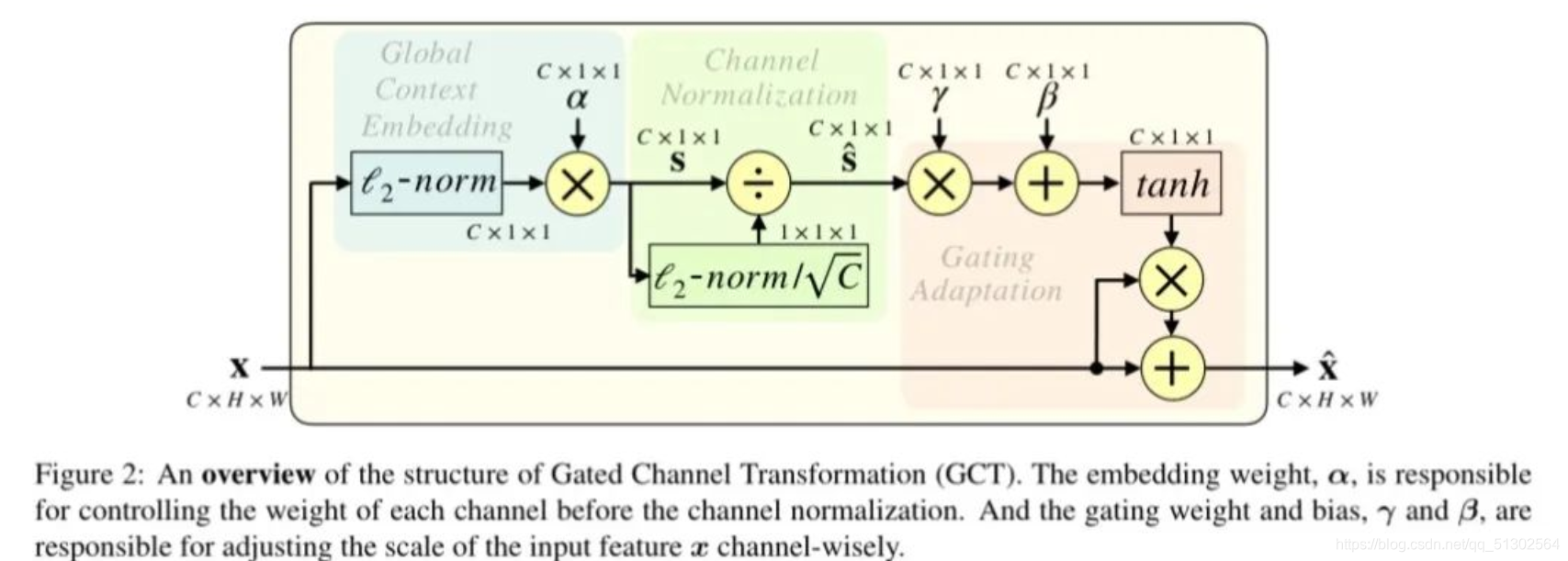
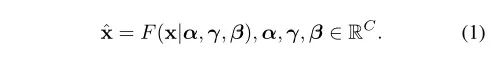
论文中引入了三个参数alpha,beita,gama来对通信道进行评价。
其中, alpha,beita,gama表示可训练参数, alpha有助于嵌入输出的自适应性, beita跟gama用于控制激活门限,它们决定了GCT在每个通道的行为表现。上面是论文的图,下面是我自己画出来的,你们可以先把论文的图看个大概,然后在看看我的/doge(虽然感觉我的画的不太好,仅供参考)。
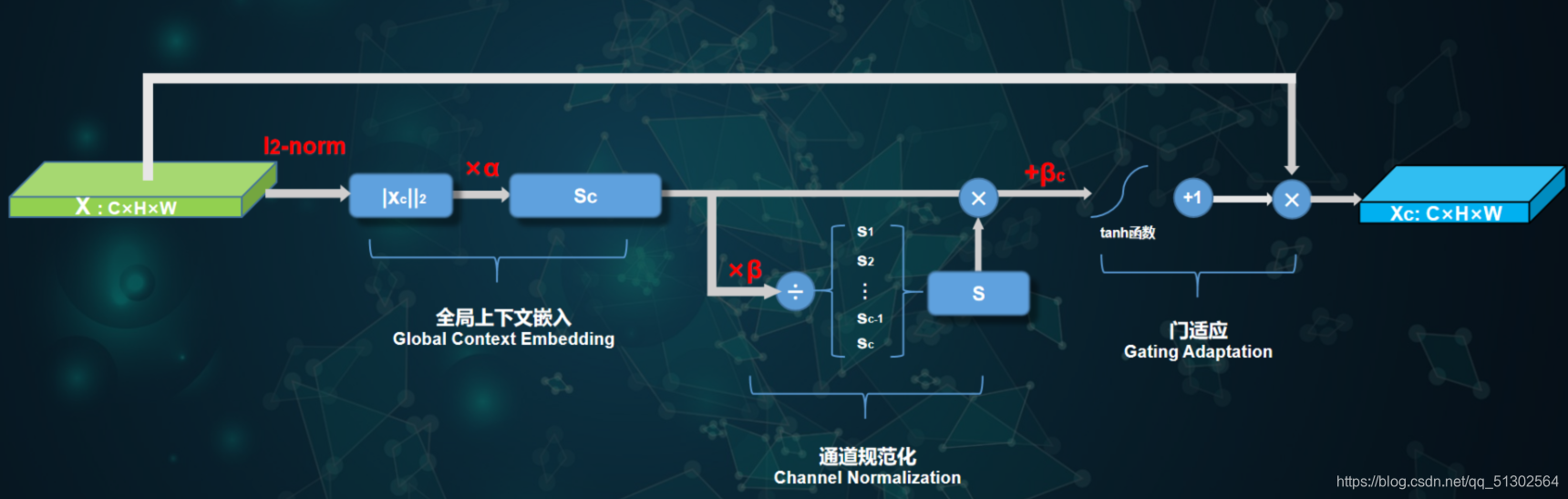
GCT:
分成三个部分
1. Global Context Embedding
大感受野有助于避免局部混淆。因此,作者首先设计了一种全局上线嵌入模块用于每个通道的全局上下文信息汇聚。
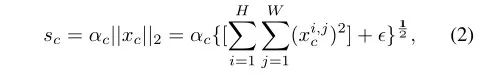
2. Channel Normalization
规范化可以通过少量计算资源构建神经元间的竞争关系,类似于LRN,作者采用 进行跨通道特征规范化,即通道规范化,此时定义如下:
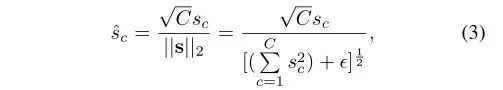

文章中提到,“根号C”,但是在代码中我并没有看到关于根号C的代码(希望有了解的童鞋可以告诉我)3. Gating Adaptation
作者在前述基础上添加了门限机制,通过引入门线机制,GCT可以有助于促进神经元的竞争or协同关系。定义如下:
3. Gating Adaptation作者在前述基础上添加了门限机制,通过引入门线机制,GCT可以有助于促进神经元的竞争or协同关系。定义如下:
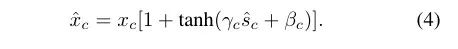
4.实现:
类似于BatchNorm,作者提出对深度网络中的所有卷积层都添加GCT。通过尝试,作者发现:将GCT置于Conv之前效果更佳。下面给出了Pytorch版的GCT实现:
class GCT(nn.Module):def __init__(self, num_channels, epsilon=1e-5, mode='l2', after_relu=False):super(GCT, self).__init__()self.alpha = nn.Parameter(torch.ones(1, num_channels, 1, 1))self.gamma = nn.Parameter(torch.zeros(1, num_channels, 1, 1))self.beta = nn.Parameter(torch.zeros(1, num_channels, 1, 1))self.epsilon = epsilonself.mode = modeself.after_relu = after_reludef forward(self, x):if self.mode == 'l2':embedding = (x.pow(2).sum((2, 3), keepdim=True) +self.epsilon).pow(0.5) * self.alphanorm = self.gamma / \(embedding.pow(2).mean(dim=1, keepdim=True) + self.epsilon).pow(0.5)elif self.mode == 'l1':if not self.after_relu:_x = torch.abs(x)else:_x = xembedding = _x.sum((2, 3), keepdim=True) * self.alphanorm = self.gamma / \(torch.abs(embedding).mean(dim=1, keepdim=True) + self.epsilon)gate = 1. + torch.tanh(embedding * norm + self.beta)return x * gate然后把GCT门控添加Conv层前(效果最好)
class REBNCONV(nn.Module):def __init__(self, in_ch=3, out_ch=3, dirate=1):super(REBNCONV, self).__init__()self.gate = GCT(in_ch)self.conv_s1 = nn.Conv2d(in_ch, out_ch, 3, padding=1 * dirate, dilation=1 * dirate)self.bn_s1 = BatchNorm2d_no_b(out_ch)self.relu_s1 = nn.ReLU(inplace=True)def forward(self, x):hx = xhx = self.gate(hx)hx = self.conv_s1(hx)hx = self.bn_s1(hx)xout = self.relu_s1(hx)return xout
这里建议先冻结原来的模型然后再训练GCT,最后解冻,再进行微调…
可以在我的博客中找到相关:https://blog.csdn.net/qq_51302564/article/details/115636452(四.小问题)
这篇关于2020 ||门控通道注意力机制Gated Channel Transformation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





