本文主要是介绍重磅好文透彻理解,异构图上 Node 分类理论与DGL源码实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
重磅好文透彻理解,异构图上 Node 分类理论与DGL源码实战
文章源码下载地址:点我下载http://inf.zhihang.info/resources/pay/7692.html
书接上文,关注过作者历史文章的读者都知道,图上机器学习/深度学习系列文章 从 一文揭开图机器学习的面纱,你确定不来看看吗 开始,已经陆续和大家一起了解了 同构图上的链接预测、节点分类与回归、边分类与回归 等机器学习任务,不熟悉的同学可以去作者的历史文章里查找哦。
如上所说,以前介绍 图上机器学习任务 的文章, 均是在 同构图 上进行的,忽略了图上不同节点以及不同边的独特性质,而是把所有节点当作一种节点来看待的。这个虽然可以解决一部分问题,但是该关系建模能力也不足以覆盖现实世界 中复杂多变的多种关系,所以就轮到我们的 异构图关系建模 文章出马了。
针对 异构图 上关系的建模,因为其 工程实现的复杂性 ,目前的学术界和工业界均存在一定的 实现难度 。我知道的甚至很多图深度学习框架在最新的版本里还 不支持 对异构图的建模。好在亚马逊的DGL框架在最新的几个版本中,已经更新了对异构图的工程实现,下面就让我们结合DGL的实现源码来一起了解下 异构图上节点分类/回归任务 吧 ~ go go go !!!
注意:我们的文章里,把分类回归任务一起囊括了因为这来那个任务除了 输入和损失不同 以外,网络结构并没有别的不同,分类回归任务彼此修改互用也比较容易,这里就不再进行区分了。本文说是节点分类任务,但是其实回归任务也差不太多。
(1) 异构图节点分类任务理论基础
按照惯例,我们还是先从基础定义引出下文的话题。
在以前的文章 一文揭开图机器学习的面纱,你确定不来看看吗 中,我们说图的分类的时候说到了异构图,文中说:图中节点类型和边类型超过两种的图称为异构图。这意思就是说异构图中的节点和同2个节点的边可能有多种,例如:图中包括用户,商品,IP三种类型的节点,其中用户和商品之间又有加购物车与购买这两种关系的边。本文所说的图就是这种类型的 比较复杂 的图。
从 同构图推广 来看,既然在异构图中区分了 节点和边 的不同类型,那我们在处理根据 异构图的局部与全局结构特性 对某个节点进行 定性分析 或则 进行两个节点之间 关系预测 的时候,就需要从 更细粒度 上去对不同的节点和边的关系进行 区分 。既然2个节点的某一种关系决定了一种类型的边,一种比较好的方式是: 根据关系(边)类型去组织不同类型的节点 ,然后进行异构图卷积操作,得到对各个类型的节点的 Embeding,在基于此最终完成 异构图上的机器学习任务 ,就像DGL官方源码实现的那样。
所谓 异构图卷积,顾名思义: 就是对 各种边的关系各自分别进行卷积 ,然后将这些关系对应的各种类型的同类型节点进行融合,默认是Sum , 得到各种同类型节点的Embeding, 注意这里每种类型节点只有一个Embeding。 对于 节点分类 任务,最后在异构图卷积层结束的时候,可以直接接激活函数,然后分别对每种类型的节点计算出一个Logit, 和有监督的某种类型的 label 计算损失进行回传即可。感兴趣的同学,可以看 DGL实现的RGCB节点分类任务的源码验证明晰 以上所说的逻辑。
这里需要特别强调注意 的是: 在异构图RGCN采样的时候,采样了几层邻居节点,异构图卷积层就有几层异构卷积layer, 分别有每个异构卷积layer去处理每一层的邻居节点。
因为采样是由内向外采样的,而聚合是由外向内聚合的。这里要引入DGL实现采样得到的Block的概念,通俗理解 Block其实就是采样得到的子图,而这些子图里的边也有对应这开始节点和结束节点以及边类型等和 全Graph同等 的一些属性 。
我们可以这样理解 :DGL实现的Block可以把看作一个数组,数组里的每一个元素是图上一层邻居的采样,Block内部节点是 从远到近的顺序排列内部的Block的,Block数组的下标从小到大对应着采样范围由外到内、覆盖范围由远及近,并且 blocks[i+1]的 source node 和 blocks[i]的target node是可以对应上的。我们知道邻居节点采样其实是按照边的关系去采来确认邻居的,所以在DGL的采样过程中,让 blocks[0]的 src node 包含了 blocks[0]的所有dst node,并且dst 节点出现在src 节点序列的前面若干位置 。
所以我们在代码实现的时候,将 外层对应节点的Embeding作为内层节点的输入,构成两个互相挨着的卷积层 ,这里采样与工程实现是 完美互相契合 的。有疑问的同学,可以去看源码验证哦 ~
好吧,整体对异构图的节点分类任务 抽象 一下: 既然我们要对异构图上某节点进行分类,那我们就需要综合异构图上该节点邻居节点的信息,得出所求节点的Embeding 信息。 而该节点周围有多种类别关系的节点,则我们就对各个关系分别进行卷积,求得各个关系里面各个节点的Embeding, 然后将多种关系涵盖的多类同类节点 Embeding进行聚合,后面可以接全链接层,也可以不接全链接层直接接激活函数,得到各个节点类型的结果作为输出。对于异构图,最终 节点分类任务的 Logit 也是 按照节点类别的个数有多个 。
当然针对异构图,我们可以采用 GraphSage还是HAN ?吐血力作综述Graph Embeding 经典好文 文章后半部分里介绍的,使用 MetaPath 结合 Attention 进行 Node 节点级别 与 path语义级别的融合,类似于 HAN 的处理方式。但是 万丈高楼平地起 ,写代码和写文章,也得慢慢来一点一点儿实现不是~
异构图RGCN节点分类任务 整体的流程解析就到这里吧,感觉这个地方,还是得看源码才能说清楚。因为整个源码流程比较长,也为了让最后整个代码demo能够完美的运行起来,本篇文章的代码将从 讲述一个工程的实现 开始。
所以,本文 就让我们一起实现 基于DGL和异构图的RGCN来进行节点分类回归任务 。下面就让我们开始 coding 吧 ~
(2) 代码时光
开篇先吼一嗓子 , talk is cheap , show me the code !!!
本文的代码讲的是 基于DGL和RGCN实现的异构图上节点分类任务,整个源码流程是一个 小型的工业可用的工程,基于dgl实现,觉得有用赶紧收藏转发吧~
life is short , i use python !!!
(2.1) 数据准备
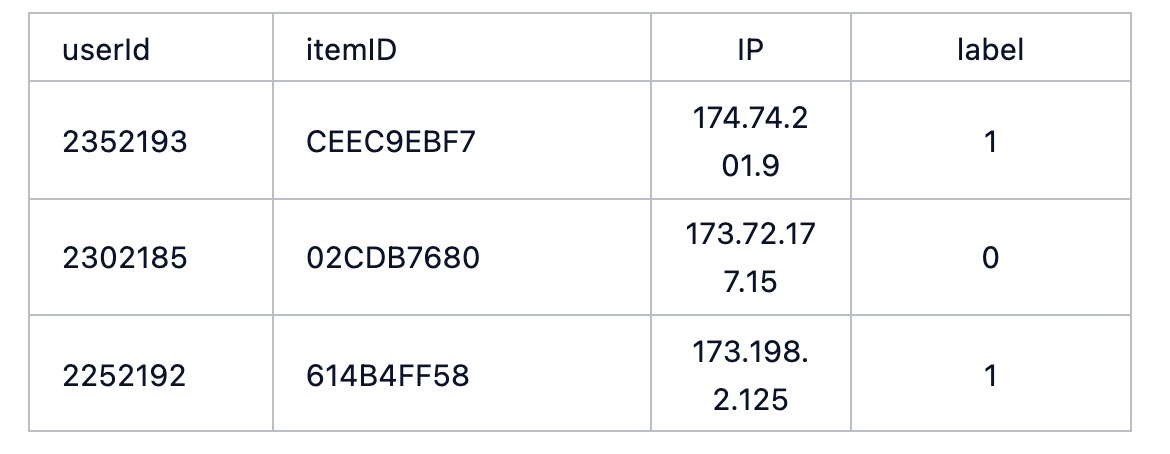
我们假设可以输入类似于这样的数据, 其中每2列对应这一种关系,例如 用户2352193 购买了商品CEEC9EBF7,用户用了IP 174.74.201.9登录了账号,用户用IP 174.74.201.9 购买了商品 CEEC9EBF7, label 表示着该用户真的购买商品,最终的节点分类任务是预测用户的购买意愿,是否是我们的高意图潜在用户,二分类。
我们可以把这样一份数据存入 source_data.csv 文件中,用 pandas 接口把数据读入:
raw_pdf = pd.read_csv('./source_data.csv')
因为对于 异构图 模型,节点和边的类型均有多种,为了处理方便,我们可以把各种类型的节点进行编码,再到后期对其进行解码,对 pandas 的 dataframe 数据结构的编解码,我们可以使用下面的代码:
@ 欢迎关注微信公众号:算法全栈之路#编码方法
def encode_map(input_array):p_map={}length=len(input_array)for index, ele in zip(range(length),input_array):# print(ele,index)p_map[str(ele)] = indexreturn p_map#解码方法
def decode_map(encode_map):de_map={}for k,v in encode_map.items():# index,ele de_map[v]=kreturn de_map
然后用其中的各列node 进行 编码
@ 欢迎关注微信公众号:算法全栈之路userid_encode_map=encode_map(set(graph_features_pdf['user_id'].values))
# 解码map
userid_decode_map=decode_map(userid_encode_map)
graph_features_pdf['user_id_encoded'] = graph_features_pdf['user_id'].apply(lambda e: userid_encode_map.get(str(e),-1))
# print unique值的个数
userid_count=len(set(graph_features_pdf['user_id_encoded'].values))
print(userid_count)这里仅仅以 用户节点编码 为例,itemId和 IP同理编解码即可。
最后我们可以把图数据保存,供以后的异构图代码 demo使用。
@ 欢迎关注微信公众号:算法全栈之路final_graph_pdf=graph_features_pdf[['user_id_encoded','ip_encoded','item_id_encoded','label']].sort_values(by='user_id_encoded', ascending=True)
final_graph_pdf.to_csv('result_label.csv',index=False)
基于此,异构图的基础准备数据就结束了,下面开始正式的coding了。
(2.2) 导包
老规矩,先导包,基于DGL和RGCN实现的异构图上节点分类任务只需要这些包就可以了。
@ 欢迎关注微信公众号:算法全栈之路import argparse
import torch
import torch.nn as nn
import dgl
import torch.optim as optim
from dgl.dataloading import MultiLayerFullNeighborSampler, EdgeDataLoader
from dgl.dataloading.negative_sampler import Uniform
import numpy as np
import pandas as pd
import itertools
import os
import tqdm
from dgl import save_graphs, load_graphs
import dgl.function as fn
import torch
import dgl
import torch.nn.functional as F
from dgl.nn.pytorch import GraphConv, SAGEConv, HeteroGraphConv
from dgl.utils import expand_as_pair
import tqdm
from collections import defaultdict
import torch as th
import dgl.nn as dglnn
from dgl.data.utils import makedirs, save_info, load_info
from sklearn.metrics import roc_auc_score
import gc
gc.collect()推荐一个工具,tqdm 很好用 哦,结合 dataloading接口 , 可以看到模型训练以及数据处理执行的进度,赶紧用起来吧~
这里的 sklearn 工具 的导入,仅仅是为了调用他来进行分类模型的离线指标评估,得到AUC等指标而已。
各种模型工具无所谓分类,能解决问题的就是好工具,混用又有何不可呢? 实用就行!
(2.3) 构图
数据有了,接下来就是构图了,我们构建的是包含 三种节点的异构图 。
@ 欢迎关注微信公众号:算法全栈之路# user 登录 ip
u_e_ip_src = final_graph_pdf['user_id_encoded'].values
u_e_ip_dst = final_graph_pdf['ip_encoded'].values
# user 购买 item
u_e_item_src = final_graph_pdf['user_id_encoded'].values
u_e_item_dst = final_graph_pdf['item_id_encoded'].values
# item和ip 共同出现
ip_e_item_src = final_graph_pdf['ip_encoded'].values
ip_e_item_dst = final_graph_pdf['item_id_encoded'].values
# user 购买 label
user_node_buy_label = final_graph_pdf['label'].valueshetero_graph = dgl.heterograph({('user', 'u_e_ip', 'ip'): (u_e_ip_src, u_e_ip_dst),('ip', 'u_eby_ip', 'user'): (u_e_ip_dst, u_e_ip_src),('user', 'u_e_item', 'item'): (u_e_item_src, u_e_item_dst),('item', 'u_eby_item', 'user'): (u_e_item_dst, u_e_item_src),('ip', 'ip_e_item', 'item'): (ip_e_item_src, ip_e_item_dst),('item', 'item_eby_ip', 'ip'): (ip_e_item_dst, ip_e_item_src)
})# 给 user node 添加标签
hetero_graph.nodes['user'].data['label'] = torch.tensor(user_node_buy_label)
print(hetero_graph)
这里的 异构图是 无向图 ,因为无向,所以双向。 构图的时候就需要构建 双向的边。 代码很好理解,就不再赘述了哈。
(2.4) 模型的自定义函数
这里定义了 异构图上RGCN 会用到的模型的一系列自定义函数,综合看代码注释,结合上文第一小节的抽象理解,希望能理解的更加深入哦。
@ 欢迎关注微信公众号:算法全栈之路class RelGraphConvLayer(nn.Module):def __init__(self,in_feat,out_feat,rel_names,num_bases,*,weight=True,bias=True,activation=None,self_loop=False,dropout=0.0):super(RelGraphConvLayer, self).__init__()self.in_feat = in_featself.out_feat = out_featself.rel_names = rel_namesself.num_bases = num_basesself.bias = biasself.activation = activationself.self_loop = self_loop# 这个地方只是起到计算的作用, 不保存数据self.conv = HeteroGraphConv({# graph conv 里面有模型参数weight,如果外边不传进去的话,里面新建# 相当于模型加了一层全链接, 对每一种类型的边计算卷积rel: GraphConv(in_feat, out_feat, norm='right', weight=False, bias=False)for rel in rel_names})self.use_weight = weightself.use_basis = num_bases < len(self.rel_names) and weightif self.use_weight:if self.use_basis:self.basis = dglnn.WeightBasis((in_feat, out_feat), num_bases, len(self.rel_names))else:# 每个关系,又一个weight,全连接层self.weight = nn.Parameter(th.Tensor(len(self.rel_names), in_feat, out_feat))nn.init.xavier_uniform_(self.weight, gain=nn.init.calculate_gain('relu'))# biasif bias:self.h_bias = nn.Parameter(th.Tensor(out_feat))nn.init.zeros_(self.h_bias)# weight for self loopif self.self_loop:self.loop_weight = nn.Parameter(th.Tensor(in_feat, out_feat))nn.init.xavier_uniform_(self.loop_weight,gain=nn.init.calculate_gain('relu'))self.dropout = nn.Dropout(dropout)def forward(self, g, inputs):g = g.local_var()if self.use_weight:weight = self.basis() if self.use_basis else self.weight# 这每个关系对应一个权重矩阵对应输入维度和输出维度wdict = {self.rel_names[i]: {'weight': w.squeeze(0)}for i, w in enumerate(th.split(weight, 1, dim=0))}else:wdict = {}if g.is_block:inputs_src = inputsinputs_dst = {k: v[:g.number_of_dst_nodes(k)] for k, v in inputs.items()}else:inputs_src = inputs_dst = inputs# 多类型的边结点卷积完成后的输出# 输入的是blocks 和 embedinghs = self.conv(g, inputs, mod_kwargs=wdict)def _apply(ntype, h):if self.self_loop:h = h + th.matmul(inputs_dst[ntype], self.loop_weight)if self.bias:h = h + self.h_biasif self.activation:h = self.activation(h)return self.dropout(h)#return {ntype: _apply(ntype, h) for ntype, h in hs.items()}class RelGraphEmbed(nn.Module):r"""Embedding layer for featureless heterograph."""def __init__(self,g,embed_size,embed_name='embed',activation=None,dropout=0.0):super(RelGraphEmbed, self).__init__()self.g = gself.embed_size = embed_sizeself.embed_name = embed_nameself.activation = activationself.dropout = nn.Dropout(dropout)# create weight embeddings for each node for each relationself.embeds = nn.ParameterDict()for ntype in g.ntypes:embed = nn.Parameter(torch.Tensor(g.number_of_nodes(ntype), self.embed_size))nn.init.xavier_uniform_(embed, gain=nn.init.calculate_gain('relu'))self.embeds[ntype] = embeddef forward(self, block=None):return self.embedsclass EntityClassify(nn.Module):def __init__(self,g,h_dim, out_dim,num_bases=-1,num_hidden_layers=1,dropout=0,use_self_loop=False):super(EntityClassify, self).__init__()self.g = gself.h_dim = h_dimself.out_dim = out_dimself.rel_names = list(set(g.etypes))self.rel_names.sort()if num_bases < 0 or num_bases > len(self.rel_names):self.num_bases = len(self.rel_names)else:self.num_bases = num_basesself.num_hidden_layers = num_hidden_layersself.dropout = dropoutself.use_self_loop = use_self_loopself.embed_layer = RelGraphEmbed(g, self.h_dim)self.layers = nn.ModuleList()# i2hself.layers.append(RelGraphConvLayer(self.h_dim, self.h_dim, self.rel_names,self.num_bases, activation=F.relu, self_loop=self.use_self_loop,dropout=self.dropout, weight=False))# h2h , 这里不添加隐层,只用2层卷积# for i in range(self.num_hidden_layers):# self.layers.append(RelGraphConvLayer(# self.h_dim, self.h_dim, self.rel_names,# self.num_bases, activation=F.relu, self_loop=self.use_self_loop,# dropout=self.dropout))# h2oself.layers.append(RelGraphConvLayer(self.h_dim, self.out_dim, self.rel_names,self.num_bases, activation=None,self_loop=self.use_self_loop))# 输入 blocks,embedingdef forward(self, h=None, blocks=None):if h is None:# full graph trainingh = self.embed_layer()if blocks is None:# full graph trainingfor layer in self.layers:h = layer(self.g, h)else:# minibatch training# 输入 blocks,embedingfor layer, block in zip(self.layers, blocks):h = layer(block, h)return hdef inference(self, g, batch_size, device="cpu", num_workers=0, x=None):if x is None:x = self.embed_layer()for l, layer in enumerate(self.layers):y = {k: th.zeros(g.number_of_nodes(k),self.h_dim if l != len(self.layers) - 1 else self.out_dim)for k in g.ntypes}sampler = dgl.dataloading.MultiLayerFullNeighborSampler(1)dataloader = dgl.dataloading.NodeDataLoader(g,{k: th.arange(g.number_of_nodes(k)) for k in g.ntypes},sampler,batch_size=batch_size,shuffle=True,drop_last=False,num_workers=num_workers)for input_nodes, output_nodes, blocks in tqdm.tqdm(dataloader):# print(input_nodes)block = blocks[0].to(device)h = {k: x[k][input_nodes[k]].to(device) for k in input_nodes.keys()}h = layer(block, h)for k in h.keys():y[k][output_nodes[k]] = h[k].cpu()x = yreturn y上面的代码主要分为三大块:分别是 RelGraphConvLayer、 RelGraphEmbed 以及 EntityClassify 。
首先就是:RelGraphConvLayer 。我们可以看到 RelGraphConvLayer 就是我们的 异构图卷积层layer , 其主要是调用了DGL实现的 HeteroGraphConv算子,从上面第一小节我们也详细阐述了异构图卷积算子其实就是: 对各种关系分别进行卷积然后进行同类型的节点的融合。
这里我们需要重点关注的是:RelGraphConvLayer层的返回,从代码中,我们可以看到,对于每种节点类型是返回了一个Embeding, 维度是 out_feat。如果是带了激活函数的,则是返回激活后的一定维度的一个tensor。
过来是 RelGraphEmbed。 从代码中可以看到: 这个python类仅仅返回了一个字典,但是这个字典里却包括了 多个 Embeding Variable, 注意这里的 Variable 均是可以 随着网络训练变化更新 的。我们可以根据节点类型,节点ID取得对应元素的 Embeding 。 这种实现方法是不是解决了 前文 GraphSage与DGL实现同构图 Link 预测,通俗易懂好文强推 和 基于GCN和DGL实现的图上 node 分类, 值得一看!!! 所提到的 动态更新的Embeding 的问题呢。
最后就是 EntityClassify类 了,我们可以看到 这个就是最终的 模型RGCN结构 了,包括了 模型训练的 forward 和用于推断的inference方法
。这里的 inference 可以用于 各个节点的embedding的导出, 我们在后文有实例代码,接着看下去吧~
注意看 forword 方法里 的 for layer, block in zip(self.layers, blocks) 这个位置, 这里就是我们前一小节所说的 采样层数和模型的卷积层数目是相同的说法的由来,可以结合上文说明理解源码哦。
(2.5) 模型采样超参与节点采样介绍
先上代码。
@ 欢迎关注微信公众号:算法全栈之路# 根据节点类型和节点ID抽取embeding 参与模型训练更新
def extract_embed(node_embed, input_nodes):emb = {}for ntype, nid in input_nodes.items():nid = input_nodes[ntype]emb[ntype] = node_embed[ntype][nid]return emb# 采样定义,有监督采样和无监督采样不一样
batch_size = 20480
neg_sample_count = 1
# 采样2层全部节点
sampler = MultiLayerFullNeighborSampler(2)# 用户节点采样,这里是对用户的所有邻居采样了2层节点
hetero_graph.nodes['user'].data['train_mask'] = torch.zeros(unique_userid_count, dtype=torch.bool).bernoulli(1.0)
all_userid_idx = torch.nonzero(hetero_graph.nodes['user'].data['train_mask'], as_tuple=False).squeeze()
user_loader = dgl.dataloading.NodeDataLoader(hetero_graph, {"user": train_userid_nodeids}, sampler,batch_size=batch_size, shuffle=True, num_workers=0)# 训练集和测试集split
train_count=(int)(len(all_userid_idx) * 0.9)
print(train_count)
train_userid_nodeids = all_userid_idx[:train_count]
test_userid_nodeids = all_userid_idx[train_count:]# IP节点的邻居采样
hetero_graph.nodes['ip'].data['train_mask'] = torch.zeros(unique_ip_count, dtype=torch.bool).bernoulli(1.0)
train_ip_nodeids = hetero_graph.nodes['ip'].data['train_mask'].nonzero(as_tuple=True)[0]
ip_loader = dgl.dataloading.NodeDataLoader(hetero_graph, {"ip": train_ip_nodeids}, sampler,batch_size=batch_size, shuffle=True, num_workers=0)
# item 邻居节点采样
hetero_graph.nodes['item'].data['train_mask'] = torch.zeros(unique_ip_prefix_count, dtype=torch.bool).bernoulli(1.0)
train_ipprefix_nodeids = hetero_graph.nodes['item'].data['train_mask'].nonzero(as_tuple=True)[0]
ipprefix_loader = dgl.dataloading.NodeDataLoader(hetero_graph, {"item": train_ipprefix_nodeids}, sampler,batch_size=batch_size, shuffle=True, num_workers=0)
这里的代码作者花了大量时间进行优化,注释和组织形式 尽量写的非常清晰,非常容易理解。
我们这里选择了 NodeDataLoader 来进行训练数据的读入,这其实是一种 分batch训练 的方法,而 不是一次性把图全读入内存 进行训练,而是每次选择 batch的种子节点以及他们采样的邻居节点 读入内存参与训练,这也让大的图神经网络训练成为了可能,是 DGL图深度框架 非常优秀 的实现 !!! 大赞 !
需要 注意的是 : extract_embed 这个方法可以抽取出对应类别对应节点的 Embeding。 我们这里用了 MultiLayerFullNeighborSampler 这个接口,对每个种子节点采样了2层的全部邻居参与训练,中间因为是节点分类任务,这里需要将该邻居采样算子 和 dgl.dataloading.NodeDataLoader 结合使用。
而 NodeDataLoader 的第二个参数属于一个字典,其中可以放多个 节点类型以及对应的种子nids , 这里为了方便理解,把拆解成了多个 data_loader,来分别对多个类型的节点在图上进行全部邻居的采样,这里的 实现是等价 的。
作者亲测,图训练的 batch_size 能选择大尽可能大一些 吧,不然训练模型会非常慢的~
(2.6) 模型训练超参与单epoch训练
@ 欢迎关注微信公众号:算法全栈之路# 模型定义
num_class = 2
n_hetero_features = 16
labels = hetero_graph.nodes['user'].data['label']hidden_feat_dim = n_hetero_featuresembed_layer = RelGraphEmbed(hetero_graph, hidden_feat_dim)
all_node_embed = embed_layer()model = EntityClassify(hetero_graph, hidden_feat_dim, num_class)
# 优化模型所有参数,主要是weight以及输入的embeding参数
all_params = itertools.chain(model.parameters(), embed_layer.parameters())
optimizer = torch.optim.Adam(all_params, lr=0.01, weight_decay=0)def train_nodetype_one_epoch(ntype, spec_dataloader):losses = []# input_nodes 代表计算 output_nodes 的表示所需的节点,input_nodes包含了output_nodes。# 块 包含了每个GNN层要计算哪些节点表示作为输出,要将哪些节点表示作为输入,以及来自输入节点的表示如何传播到输出节点。for input_nodes, output_nodes, blocks in tqdm.tqdm(spec_dataloader):emb = extract_embed(all_node_embed, input_nodes)batch_tic = time.time()seeds = output_nodes[ntype]lbl = labels[seeds] # 只取output_nodes部分结点参与训练logits = model(emb, blocks)[ntype]loss = F.cross_entropy(logits, lbl)loss.backward()optimizer.step()train_acc = torch.sum(logits.argmax(dim=1) == lbl).item() / len(seeds)print('AUC', roc_auc_score(lbl, logits.argmax(dim=1) ))print("Epoch {:05d} | Train Acc: {:.4f} | Train Loss: {:.4f} | Time: {:.4f}".format(epoch, train_acc, loss.item(), time.time() - batch_tic))从上面的代码我们可以看到: 最终我们是进行了 2分类 ,中间的调用了上面模型定义类 EntityClassify 来定义 异构图上RGCN的模型 结构,因为是分类问题,损失函数选择了 交叉熵损失 。
需要注意的是: all_params = itertools.chain(model.parameters(), embed_layer.parameters()) 这一行代码,我们定义优化器的参数时,将我们自定义的 可随网络更新的 Variable 加入了 itertools.chain 参与模型的训练。
另一个需要注意的点是: spec_dataloader 这个地方,它的返回是 input_nodes, output_nodes和 blocks 这三个元素的tuple 。 其中,input_nodes 代表计算 output_nodes 的表示所需的节点,input_nodes包含了output_nodes。块 包含了每个GNN层要计算哪些节点表示作为输出,要将哪些节点表示作为输入,以及来自输入节点的表示如何传播到输出节点。
这就有了我们进行模型训练所需要的图上结构的全部信息了。
(2.6) 模型多种节点训练
@ 欢迎关注微信公众号:算法全栈之路# 开始train 模型
for epoch in range(20):print("start epoch:", epoch)model.train()train_nodetype_one_epoch('user', user_loader)train_nodetype_one_epoch('user', user_loader)train_nodetype_one_epoch('user', user_loader)从代码中我们可以知道: 对于异构图,其实我们也是以 各种类型的节点作为种子节点, 然后进行图上的邻居采样,分别进行训练然后更新整个模型结构 的。
(2.7) 模型保存与节点Embeding导出
@ 欢迎关注微信公众号:算法全栈之路# 图数据和模型保存
save_graphs("graph.bin", [hetero_graph])
torch.save(model.state_dict(), "model.bin")# 每个结点的embeding,自己初始化,因为参与了训练,这个就是最后每个结点输出的embeding
print("node_embed:", all_node_embed['user'][0])# 模型预估的结果,最后应该使用 inference,这里得到的是logit
# 注意,这里传入 all_node_embed,选择0,选1可能会死锁,最终程序不执行
inference_out = model.inference(hetero_graph, batch_size, 'cpu', num_workers=0, all_node_embed)
print(inference_out["user"].shape)
print(inference_out['user'][0])
这里我们可以看到, 我们使用了 model.inference 接口进行模型的节点 Embeding导出。
这里需要注意的是: 这个地方 num_workers应该设置0 ,即为不用多线程, 不然会互锁,导致预估任务不执行。这里是 深坑 啊,反正经过很长时间的纠结和查找,最终发现是这个原因,希望读者可以避免遇到相似的问题 ~
其实对于异构图,要写出对它的一些应用的理解,我也是怯生生的。但是,凡事必先骑上虎背 。管它呢,上吧,能写到哪一步是哪一步吧! 欢迎关注作者并留言和我一起讨论,彼此一起学习交流 ~
到这里,重磅好文透彻理解, 异构图上 Node 分类理论与DGL源码实战 的全文就写完了。上面的代码demo 在环境没问题的情况下,全部复制到一个python文件里,就可以完美运行起来。本文的 代码是一个小型的商业可以用的工程项目,希望可以对你有参考作用 ~
码字不易,觉得有收获就动动小手转载一下吧,你的支持是我写下去的最大动力 ~
更多更全更新内容 : 算法全栈之路
这篇关于重磅好文透彻理解,异构图上 Node 分类理论与DGL源码实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







