本文主要是介绍Sora背后的论文(1):使用 lstms 对视频展现进行无监督学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

之前那篇《Sora背后的32篇论文》发出后,大家都觉得不错,有很多小伙伴都开始啃论文了。
那么我就趁热打铁,把这32篇论文的通俗解读版贴一下。
从去年开始,我基本上形成了一个思维方式,任何事情做之前先看看
有没有好的AI工具帮助自己提高效率。
我本身不是算法出身,也是散装英语的水平,
所以这个过程是借助了一些AI工具完成,后面会专门写一篇介绍详细的说明。

Sora官网技术文章出处:
Video generation models as world simulators


本篇论文:
Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhudinov. "Unsupervised learning of video representations using lstms." International conference on machine learning. PMLR, 2015.↩︎
斯里瓦斯塔瓦、尼蒂什、埃尔曼·曼西莫夫和鲁斯兰·萨拉胡迪诺夫。
“使用 lstms 对视频表示进行无监督学习。”机器学习国际会议。PMLR,2015 年。
论文链接:
- AMinerAMiner利用数据挖掘和社会网络分析与挖掘技术,提供研究者语义信息抽取、面向话题的专家搜索、权威机构搜索、话题发现和趋势分析、基于话题的社会影响力分析、研究者社会网络关系识别等众多功能。![]() https://www.aminer.cn/pub/573696ce6e3b12023e5cec74/unsupervised-learning-of-video-representations-using-lstms
https://www.aminer.cn/pub/573696ce6e3b12023e5cec74/unsupervised-learning-of-video-representations-using-lstms

论文结构
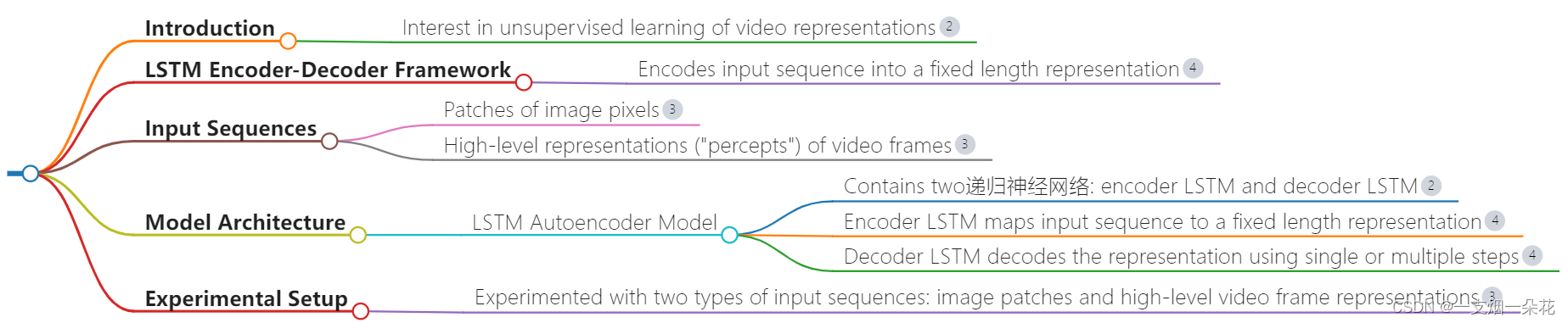
使用LSTM(长短时记忆)模型进行无监督学习的视频表示,主要是通过编码器-解码器框架实现的。
这种方法涉及到两个递归神经网络:编码器LSTM和解码器。
此外,该模型还被用于实验不同类型的输入序列,
包括图像像素块和视频帧的高层表示("percepts")[[3]]。
这表明,尽管具体的输入序列可能有所不同,但基本原理是一致的,即利用LSTM网络学习视频序列的表征。

如何优化LSTM模型以提高视频表示的准确性和效率?
1. 调整LSTM模型的超参数:
首先,需要对LSTM模型进行详细的调参。
这包括但不限于调整神经元个数、隐藏层个数、权重初始策略、激活函数以及优化器等超参数。
通过可视化loss和ACC曲线,判断是否存在过拟合现象,并逐个讲解这些参数的选择。
此外,通过逐渐减小学习率,使模型在训练过程中更加稳定地收敛,从而提高模型的性能。
2. 选择合适的优化算法:
尝试使用不同的优化算法,找到最适合LSTM模型训练的算法。
不同的优化算法可能会对模型的收敛速度和性能产生影响。
例如,PyTorch框架下的LSTM模型优化是一个重要的研究方向,需要精心的优化。
3. 改进视频质量评估方法:
在视频处理过程中,准确性是衡量模型输出结果与真实结果之间接近程度的关键指标。
通常使用分类准确率、回归误差等指标来评估系统或算法的表现。
因此,通过改进视频质量评估方法,可以进一步提升编码效率。
4. 利用深度学习技术:
深度学习技术,如LSTM,被广泛应用于提升视频转码效率与视觉质量。
通过精准定位人眼喜好,可以实现缩小视频文件体积的同时提升画面主观视觉质量。
这表明,结合深度学习的优化技巧和应用,可以有效提高视频表示的准确性。
优化LSTM模型以提高视频表示的准确性和效率,需要综合考虑超参数的调整、
优化算法的选择、视频质量评估方法的改进以及深度学习技术的应用。
通过这些方法的综合运用,可以显著提升LSTM模型的性能。

LSTM模型在视频表示中的应用有哪些具体案例?
LSTM模型在视频表示中的应用主要体现在以下几个方面:
1. 视频动作分类:
通过结合2D卷积神经网络和LSTM模型,可以实现视频动作的分类。
这种方法利用了视频中的特征,包括动作的时间、空间位置等信息,来训练模型,
并最终实现对视频中特定动作的识别[[16]]。
2. 视频检测或识别:
LSTM在视频任务中扮演着时间序列预测的作用。
它与CNN或RNN结合使用,用于视频帧的特征提取,从而输出离散的特征表示。
这些特征可以被用来表示视频内容,进而进行视频检测或识别任务[[17]]。
3. 不稳定降雨量时间序列预测:
使用LSTM神经网络对不稳定降雨量时间序列进行预测。
这表明LSTM不仅可以处理连续的数据序列,也能有效地处理离散化的数据,如视频帧或图像帧[[18]]。
4. 视频分类:
通过训练深层神经网络(如卷积神经网络)和视频帧的表示,可以直接从原始的GelSight视频回归硬度。
这种方法展示了LSTM模型如何用于视频的深层学习,以实现视频分类的目的[[20]]。
5. 视频预测:
基于空间自适应卷积LSTM的视频预测是另一个例子,展示了LSTM在视频分析中的潜力。
这种方法可能涉及到对未来事件的预测,如交通流量、天气变化等[[23]]。
LSTM模型在视频表示中的应用案例包括但不限于视频动作分类、视频检测或识别、不稳定降雨量时间序列预测、视频分类以及视频预测等。
这些应用展示了LSTM在处理视频数据时的灵活性和强大功能。

在视频表示中,LSTM模型与传统方法(如CNN)相比有何优势和局限性?
优势方面:
1. 处理长期依赖性:
LSTM模型能够有效地捕捉和处理长期时间序列中的依赖关系,这是传统RNN难以处理的问题[[32]]。
2. 防止梯度消失问题:
LSTM能够解决传统的RNN模型在处理长序列时容易出现梯度消失的问题,导致难以训练的问题[[34]]。
3. 良好的学习能力:
LSTM具有良好的学习能力,这使得它在面对复杂的时间序列问题时表现出较好的性能[[26]]。
局限性方面:
1. 训练时间较长:
LSTM模型的训练过程相对较长,这可能会影响到实时应用的需求[[26]]。
2. 参数多且容易过拟合:
LSTM的参数众多,这可能导致模型过拟合,从而影响模型的泛化能力和准确性[[26]]。
3. 计算资源消耗大:
LSTM需要大量的计算资源来进行训练和推理,这对于一些资源受限的应用场景来说是一个挑战[[26]]。
LSTM模型在视频表示中相比传统方法如CNN,主要优势在于
其能有效处理长期依赖性问题,防止梯度消失,以及具有良好的学习能力。
然而,其训练时间长、参数众多且容易过拟合,以及对计算资源的高需求也是其局限性所在。
因此,在选择使用LSTM还是CNN时,需要根据具体的视频表示任务和可用资源做出合理的决策。

如何处理和分析LSTM模型输出的视频序列表征以提取有用信息?
处理和分析LSTM模型输出的视频序列表征以提取有用信息,
首先需要理解LSTM模型的基本原理和应用场景。
LSTM(长短期记忆网络)是一种基于门控机制的深度学习模型,
能够处理序列数据中的长期依赖关系[[42]]。
在视频序列分析中,LSTM模型可以用于捕捉视频中的动作、行为等时间依赖特征[[40]]。
处理和分析视频序列表征的方法包括:
1. 截帧与深度学习表达:
将视频截帧,然后通过深度学习模型对每一帧进行特征提取,以获得视频的特征表示[[37]]。
这种方法适用于需要从单个帧中提取特定特征的情况。
2. 时域特征提取:
利用LSTM模型捕捉视频序列中的时域特征,如动作的持续时间、速度等[[41]]。
这可以通过优化模型参数或采用时域自适应正则化方法来实现[[41]]。
3. 序列变换特征提取:
除了时域特征外,还可以通过序列变换来提取视频序列中的序列变换特征,
如动作的顺序变化等[[40]]。
4. 注意力机制:
在视频序列表情识别等任务中,
通过注意力机制关注局部区域的关键信息,可以有效提高识别准确率[[44]]。
5. 并行处理与端到端学习:
利用视频序列批处理输入和并行处理,实现高效的端到端学习,
对视觉模型参数和序列化模型参数的快速计算[[45]]。
处理和分析LSTM模型输出的视频序列表征时,应综合考虑时域和序列化的特征,
采用适当的算法和技术手段,如截帧、深度学习编码、时域特征提取、
序列化变换、注意力机制等,以提取出有用的视频特征。
同时,也可以结合并行处理和端到端学习等技术,以提高模型的效率和准确性。

LSTM模型在视频表示中的最新研究进展是什么?
1. 视频预测与表征学习:
Srivastava等人提出了一种使用LSTM架构的无监督视频表征学习模型,
该模型能够将图像经过编码器编码后送入LSTM网络,
通过解码器重建原视频或预测未来视频[[47]]。
这表明LSTM模型不仅用于视频的重建,还能用于视频的预测和学习。
2. 深度特征提取:
Ng等人使用5层隐层结点数512的LSTM来提取深度特征,每个时刻都进行输出[[48]]。这种方法有助于在视频理解中提取深度特征,提高视频理解的准确性。
3. 动作识别:
在动作识别任务上,研究人员采用了更多帧(如64帧)的视频信息作为输入信号,并实现了对远程动作的识别[[49]]。
这说明LSTM模型在处理多帧视频信息时具有较好的性能,尤其是在需要长距离依赖关系的任务中。
4. 换脸视频检测:
基于卷积LSTM网络的模型被应用于换脸视频检测中,有效提取输入帧的面部变化特征,
进而提高检测器的性能[[51]]。
这一应用展示了LSTM模型在特定视频检测任务上的有效性。
5. 实时移动带宽预测:
使用LSTM神经网络和贝叶斯融合的方法进行实时移动带宽预测,
极大地提高了最新的预测算法的预测精度[[52]]。
这表明LSTM在时间序列预测方面也展现出了强大的能力。
LSTM模型在视频表示中的最新研究进展包括其在视频预测、深度特征提取、
动作识别以及实时移动带宽预测等多个领域的应用,
显示了LSTM模型作为一种有效的视频表示工具的潜力和优势。

参考文章:
2. 【论文笔记】Unsupervised Learning of Video ... - CSDN博客 [2017-03-26]
3. Unsupervised learning of video representations using LSTMs [2015-07-06]
4. Unsupervised Learning of Video Representations using LSTMs [2021-11-23]
5. 【论文笔记】Unsupervised Learning of Video ... - CSDN博客 [2022-02-25]
6. LSTM 08:超详细LSTM调参指南原创 - CSDN博客 [2020-03-21]
7. 如何利用深度学习提升视频转码效率与视觉质量? 原创 - CSDN博客 [2019-04-08]
8. LSTM的优化技巧:提高自然语言处理任务的性能 - 稀土掘金 [2024-01-08]
9. LSTM 08:超详细LSTM调参指南 - 腾讯云
10. LSTM调参经验- kamekin - 博客园 [2018-12-23]
11. 自然语言处理:LSTM模型的应用与优化 - 百度开发者中心 [2024-02-06]
12. 深度学习LSTM算法超参数调优—可视化loss和acc曲线、判断过拟合 [2020-03-13]
13. 通过改进视频质量评估提升编码效率 - 阿里云开发者社区 [2021-03-17]
14. PyTorch:深度学习框架的优化技巧 - 百度开发者中心 [2024-02-17]
15. 如何使用学习曲线来诊断你的LSTM模型的行为?(附代码) | 机器之心 [2019-03-11]
16. 2D卷积神经网络+LSTM实现视频动作分类原创 - CSDN博客 [2020-02-19]
17. 关于LSTM Layer在视频检测或识别任务中的作用的简单理解 [2018-07-23]
18. 【视频】Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列 ...
19. 长短期记忆神经网络(LSTM)介绍以及简单应用分析「建议收藏」 [2022-09-16]
20. LSTM视频分类的深度学习——思路参考 - 阿里云开发者社区 [2022-06-08]
21. 【视频】LSTM神经网络架构和原理及其在Python中的预测应用 [2022-02-25]
22. 莫烦Python- LSTM (分类例子)-程序和视频讲解转载 - CSDN博客 [2018-01-31]
23. [PDF] 基于空间自适应卷积LSTM 的视频预测 - 计算机应用与软件
24. 手把手教你开发CNN LSTM模型,并应用在Keras中(附代码) [2019-02-11]
25. 如何使用长短时记忆网络(LSTM) - PingCode
26. LSTM的优点和缺点 - PingCode
27. CNN,RNN,LSTM区别原创 - CSDN博客 [2018-07-24]
28. LSTM网络模型的原理和优缺点 - 知乎专栏
29. CNN,RNN,LSTM都是什么?-腾讯云开发者社区
30. 【个人整理】长短是记忆网络LSTM的原理以及缺点原创 - CSDN博客 [2019-04-04]
31. 直观比较四种NLP模型- 神经网络,RNN,CNN,LSTM - 稀土掘金 [2021-06-02]
32. LSTM 模型有哪些优点和局限性? [2023-08-24]
33. 神经网络:CNN与LSTM的比较与应用 - 百度开发者中心 [2024-02-08]
34. 长短时记忆网络(LSTM)在序列数据处理中的优缺点分析 - 腾讯云 [2023-07-04]
35. 请你说说CNN,RNN,LSTM,Transformer之间的优缺点转载 [2023-01-11]
36. 基于Python的LSTM视频分类实现
37. Video Feature extracting_视频特征提取 - CSDN博客 [2022-01-06]
38. 【视频】Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列 ... [2022-12-19]
39. 如何提取视频特征?如何综合判断一个模型的效果? - 知乎专栏 [2018-06-12]
40. 从时间序列中提取特征的几种方法原创 - CSDN博客 [2021-03-16]
41. 视频行为分析 - 东南大学大数据计算中心
42. 时间序列分析(4) RNN/LSTM - 知乎专栏
43. 10. 时间序列的深度学习模型(RNN和LSTM)(上) - 网易公开课
44. 采用Transformer网络的视频序列表情识别 - 中国图象图形学报 [2022-10-16]
45. 论文笔记——基于深度学习的视频行为识别/动作识别(二) - 知乎专栏 [2018-08-20]
46. 视频预测领域有哪些最新研究进展?不妨看看这几篇顶会论文 - 领研网 [2020-03-03]
47. 基于深度学习的视频预测研究综述
48. 视频理解近期研究进展 - 知乎专栏
49. FCS | ResLNet:动作识别任务上的可接受更长输入的深度残差LSTM ... [2022-10-12]
50. 【视频】Python用LSTM长短期记忆神经网络对不稳定降雨 ... - 稀土掘金 [2022-12-19]
51. [PDF] 基于卷积长短期记忆网络的换脸视频检测 [2020-12-24]
52. 使用LSTM神经网络和贝叶斯融合进行实时移动带宽预测,Computer ...
53. 基于深度学习的时间序列分类研究综述 - 电子与信息学报
这篇关于Sora背后的论文(1):使用 lstms 对视频展现进行无监督学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






