2019独角兽企业重金招聘Python工程师标准>>> 
既然MySQL 8和PostgreSQL 10已经发布了,现在是时候回顾一下这两大开源关系型数据库是如何彼此竞争的。
在这些版本之前,人们普遍认为,Postgres在功能集表现更出色,也因其“学院派”风格而备受称赞,MySQL则更善长大规模并发读/写。
但是随着它们最新版本的发布,两者之间的差距明显变小了。
特性比较
首先来看看我们都喜欢谈论的“时髦”功能。
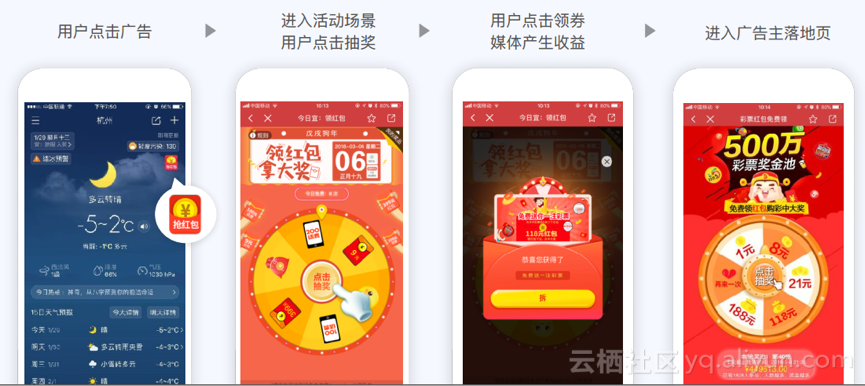
业务介绍兑吧集团包含兑吧网络和推啊网络,兑吧网络是一家致力于帮助互联网企业提升运营效率的用户运营服务平台,提供积分商城和媒体运营服务。推啊网络是一家互动式广告平台,经过多年的探索与实践,首创了全新的移动广告模式,实现了广告主、媒体、用户多方共赢。在推啊的广告场景中,广告主可获得更好的投放效果,媒体方能得到更好的流量变现效率,受众端具有更好的用户体验,目前推啊已经服务超过15000家媒体,阿里云hbase主要服务于"推啊"的广告业务。 "推啊"的整体业务流程如下图:
整体产品架构广告平台基础架构完善,能有效支持业务,其中核心数据平台为公司所有业务提供强有力的数据支撑。其中整个数据平台根据处理业务不同大致分为3个模块:
HBase在"推啊"使用场景HBase在推啊主要用于流式数据统计,存储用户画像的相关数据,属于实时统计模块中主要存储。 为什么从物理HBase迁移到阿里云HBase最开始我们是物理机房自建HBase,选择阿里云HBase主要出于以下几个考虑:
整个迁移实战过程根据我们业务的发展,从3个阶段阐述下阿里云hbase的使用情况以及遇到的问题 | MySQL 8 | PostgreSQL 10 |
| 查询 & 分析 | ||
| 公用表表达式 (CTEs) | New | |
| 窗口函数 | New | |
| 数据类型 | ||
| JSON支持 | Improved | |
| GIS / SRS | Improved | |
| 全文检索 | ||
| 可扩展性 | ||
| 逻辑复制 | New | |
| 半同步复制 | New | |
| 声明式分区 | New |
过去经常会说MySQL最适合在线事务,PostgreSQL最适合分析流程,但现在不是了。
公共表表达式(CTEs)和窗口函数是选择PostgreSQL的主要原因。但是现在,通过引用同一个表中的boss_id来递归地遍历一张雇员表,或者在一个排序的结果中找到一个中值(或50%),这在MySQL上不再是问题。
在PostgreSQL中进行复制缺乏配置灵活性,这就是Uber转向MySQL的原因。但是现在,有了逻辑复制特性,就可以通过创建一个新版本的Postgres并切换到它来实现零停机升级。在一个巨大的时间序列事件表中截断一个陈旧的分区也要容易得多。
就特性而言,这两个数据库现在都是一致的。






