本文主要是介绍【TT100K中对test结果按照目标大小进行分类评估 anno_func.py】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
caffe 官方例程之R-CNN
def eval_annos(annos_gd, annos_rt, iou=0.75, imgids=None, check_type=True, types=None, minscore=40, minboxsize=0, maxboxsize=400, match_same=True):ac_n, ac_c = 0,0 #accuracyrc_n, rc_c = 0,0 #recallif imgids==None:imgids = annos_rt['imgs'].keys() #字典 dishes = {'eggs': 2, 'sausage': 1, 'bacon': 1, 'spam': 500}if types!=None: #key:valuetypes = { t:0 for t in types } #类似{1: 0, 2: 0, 3: 0, 4: 0, 5: 0}miss = {"imgs":{}} #字典的嵌套?wrong = {"imgs":{}}right = {"imgs":{}}for imgid in imgids: #对于某一张图片v = annos_rt['imgs'][imgid] #预测的图片vg = annos_gd['imgs'][imgid] #实际的convert = lambda objs: [ [ obj['bbox'][key] for key in ['xmin','ymin','xmax','ymax']] for obj in objs]#不是常规的双层循环,按照括号来说,后面是外层循环#lambda x, y: x*y#函数输入是x和y,输出是它们的积x*yobjs_g = vg["objects"] #实际的目标objs_r = v["objects"] #预测的目标bg = convert(objs_g) #实际的边框br = convert(objs_r) #预测的边框match_g = [-1]*len(bg) #边框是否匹配?一开始都是-1?列表的乘法即为重复match_r = [-1]*len(br) #列表的加法为拼接if types!=None:for i in range(len(match_g)):if not types.has_key(objs_g[i][ 'category']):#如果键在字典里返回true,否则返回false。match_g[i] = -2 #真实框的类别没有检测出来?真实框的类别不在设定的检测范围内?所以是没用的?for i in range(len(match_r)):if not types.has_key(objs_r[i]['category']):match_r[i] = -2 #预测框的类别没有检测出来?所以也是没用的?for i in range(len(match_r)):if objs_r[i].has_key('score') and objs_r[i]['score']<minscore:#我一直没找到这个score的定义,不知道这是个什么分数match_r[i] = -2 #分数太低就淘汰?就没用了?matches = [] #空的列表for i,boxg in enumerate(bg): #枚举 enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)#组合为一个索引序列,同时列出下标和数据for j,boxr in enumerate(br):if match_g[i] == -2 or match_r[j] == -2:continue #if continue的用法(跳过本次循环,执行下一个循环)if match_same and objs_g[i]['category'] != objs_r[j]['category']: continue #分类不一样就淘汰?#match_same是传进来的参数tiou = calc_iou(boxg, boxr) #如果分类一致就计算iou(不一定是同一个目标)if tiou>iou: #大于输入的阈值,有可能是同一目标?matches.append((tiou, i, j))#列表中添加元组?matches = sorted(matches, key=lambda x:-x[0]) #按第一个元素(tiou)反向(由大到小)排列#lambda函数示例:#lambda x, y: x*y#函数输入是x和y,输出是它们的积x*yfor tiou, i, j in matches:if match_g[i] == -1 and match_r[j] == -1: #不是-2就证明起码不是没用的?match_g[i] = jmatch_r[j] = i #记录对应关系?for i in range(len(match_g)):boxsize = box_long_size(objs_g[i]['bbox'])erase = Falseif not (boxsize>=minboxsize and boxsize<maxboxsize):erase = True #大小不符合就擦除?#if types!=None and not types.has_key(objs_g[i]['category']):# erase = Trueif erase:if match_g[i] >= 0:match_r[match_g[i]] = -2 #match_g[i] = jmatch_g[i] = -2for i in range(len(match_r)):boxsize = box_long_size(objs_r[i]['bbox'])if match_r[i] != -1: continueif not (boxsize>=minboxsize and boxsize<maxboxsize):match_r[i] = -2 #??????预测框大小不符合也删掉?miss["imgs"][imgid] = {"objects":[]}wrong["imgs"][imgid] = {"objects":[]}right["imgs"][imgid] = {"objects":[]}miss_objs = miss["imgs"][imgid]["objects"]wrong_objs = wrong["imgs"][imgid]["objects"]right_objs = right["imgs"][imgid]["objects"]tt = 0for i in range(len(match_g)):if match_g[i] == -1: #类别存在但没找到匹配对象miss_objs.append(objs_g[i])for i in range(len(match_r)):if match_r[i] == -1: #类别存在但没找到匹配对象obj = copy.deepcopy(objs_r[i])obj['correct_catelog'] = 'none'wrong_objs.append(obj)elif match_r[i] != -2: #类别存在且找到匹配对象j = match_r[i] obj = copy.deepcopy(objs_r[i])if not check_type or objs_g[j]['category'] == objs_r[i]['category']: #优先级&&如果分类一致right_objs.append(objs_r[i])tt+=1 #分类正确的计数else: #分类不正确?obj['correct_catelog'] = objs_g[j]['category']wrong_objs.append(obj)rc_n += len(objs_g) - match_g.count(-2) #计数 全部的真实框-没用的ac_n += len(objs_r) - match_r.count(-2) #计数 全部的预测框-没用的ac_c += tt #分类正确的计数rc_c += tt #分类正确的计数if types==None: #types是传进来的参数styps = "all"elif len(types)==1:styps = types.keys()[0]elif not check_type or len(types)==0:styps = "none"else:styps = "[%s, ...total %s...]"%(types.keys()[0], len(types))report = "iou:%s, size:[%s,%s), types:%s, accuracy:%s, recall:%s"% (iou, minboxsize, maxboxsize, styps, 1 if ac_n==0 else ac_c*1.0/ac_n, 1 if rc_n==0 else rc_c*1.0/rc_n)summury = {"iou":iou,"accuracy":1 if ac_n==0 else ac_c*1.0/ac_n,"recall":1 if rc_n==0 else rc_c*1.0/rc_n,"miss":miss,"wrong":wrong,"right":right,"report":report}return summury




25


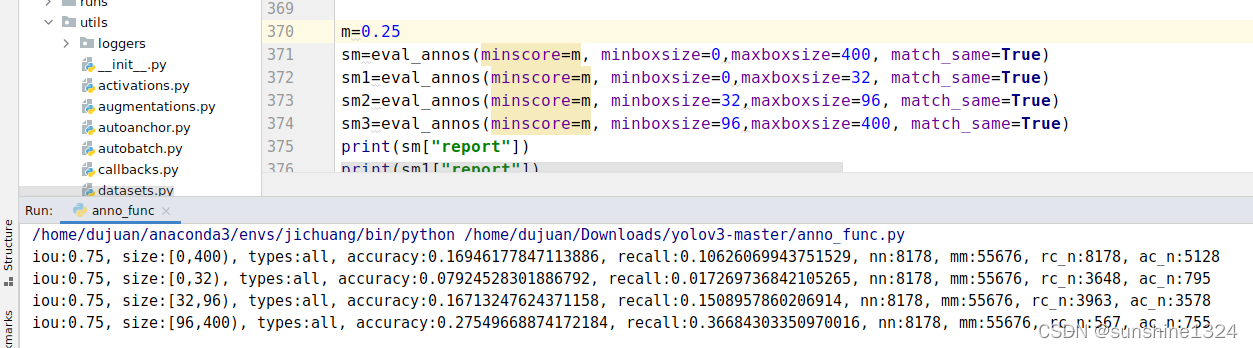

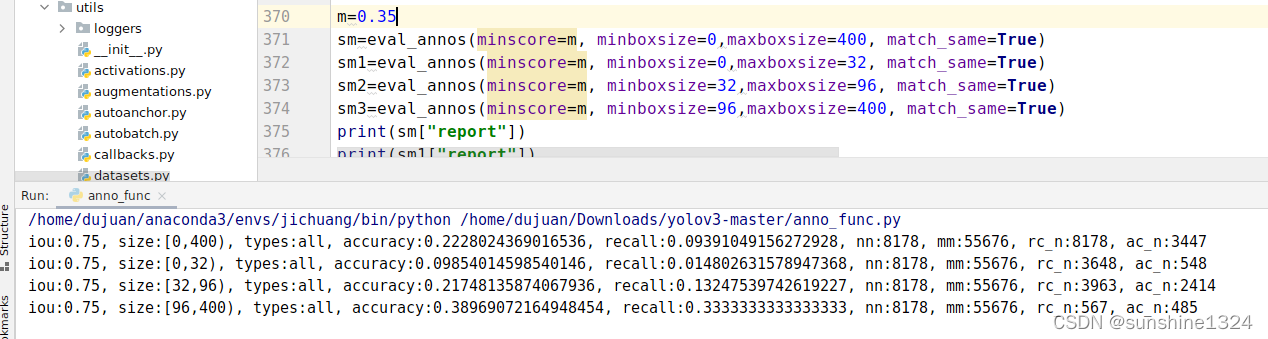

这篇关于【TT100K中对test结果按照目标大小进行分类评估 anno_func.py】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




