本文主要是介绍AI嵌入式K210项目(29)-模型加载,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、下载部署包
- 二、C++部署
- 三、搭建文件传输环境
- 四、文件传输
- 五、调试
- 六、MicroPython部署
- 总结
前言
上一章节介绍了如何进行在线模型训练,生成部署包后,本章介绍加载模型;
一、下载部署包
训练结束后,在训练任务条目中选择下载按钮;
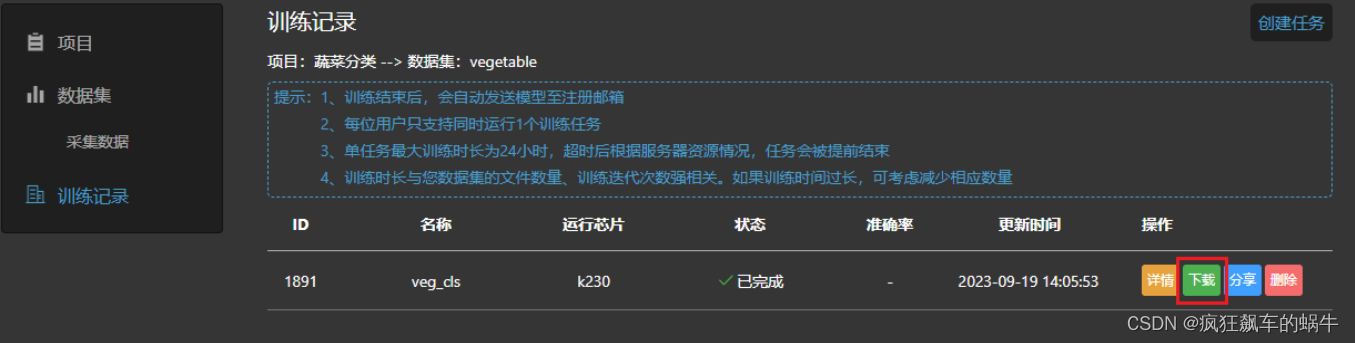
下载得到部署资源包。
部署资源包内包含:测试结果图片、生成的kmodel、部署配置文件deploy_config.json、部署资源压缩包。
部署资源压缩包解压后,参照README.md可以实现上板部署过程;

C++部署资源压缩包deployment_source.zip解压后结构如下:

MicroPython部署资源压缩包mp_deployment_source.zip解压后结构如下:

二、C++部署
若使用MicroPython的部署包请参见下一章节。
注意:训练环境中nncase和nncase-kpu的版本和SDK的版本要对应, nncase和nncase-kpu版本为2.4.0, SDK版本为1.1。
上板部署过程分为以下几个步骤:
K230 SDK需要在Linux环境下编译,推荐使用Ubuntu Liunx 20.04。 使用docker编译环境,下载k230_sdk
# 下载docker编译镜像
docker pull ghcr.io/kendryte/k230_sdk
# 可以使用以下命令确认docker镜像拉取成功
docker images | grep k230_sdk
# 下载sdk
git clone -b v1.1 --single-branch https://github.com/kendryte/k230_sdk.git
cd k230_sdk
# 下载工具链, make prepare_sourcecode 会自动下载Linux和RT-Smart toolchain,
buildroot package, AI package等. 请确保该命令执行成功并没有Error产生, 下载时间和速度
以实际网速为准。
make prepare_sourcecode
# 创建docker容器, $(pwd):$(pwd)表示系统当前目录映射到docker容器内部的相同目录下, 将系
统下的工具链目录映射到docker容器内部的/opt/toolchain目录下
docker run -u root -it -v $(pwd):$(pwd) -v $(pwd)/toolchain:/opt/toolchain -
w $(pwd) ghcr.io/kendryte/k230_sdk /bin/bash
这里使用的CANMV-K230开发板,还有一种K230-EVB开发板
# 在docker中编译镜像, 请耐心等待完成, 不同类型开发板编译命令不同
# 如果是CANMV-K230开发板
make CONF=k230_canmv_defconfig
# 如果是K230-EVB开发板
make CONF=k230_evb_defconfig
SD卡镜像也可在嘉楠开发者社区资料下载板块找到。
CANMV-K230开发板,编译结束后在output/k230_canmv_defconfig/images目录下可以找到编译好的镜像文件:
k230_canmv_defconfig/images
├── big-core
├── little-core
├── sysimage-sdcard.img # SD卡镜像
└──
sysimage-sdcard.img.gz # SD卡镜像压缩包
CANMV-K230开发板支持SD卡镜像启动
烧录TF卡
详细烧录步骤参考K230_SDK_使用说明。
Linux: 如使用Linux烧录TF卡,需要先确认SD卡在系统中的名称/dev/sdx, 并替换如下命令中的/dev/sdx
sudo dd if=sysimage-sdcard.img of=/dev/sdx bs=1M oflag=sync
Windows: 如使用Windows烧录, 建议使用the balena Etcher工具。将生成的sysimage-sdcard.img下载到本地,使用烧录工具the balena Etcher进行烧录。

其它更详细的烧录方法,请参考K230_SDK_使用说明。
确认启动开关选择在SD卡启动模式下,将烧录完成的TF卡插入进开板板卡槽中,然后将电源开关K1拔到ON位置,系统可上电。如果您有接好串口,可在串口中看到启动日志输出。 系统上电后,默认会有二个串口设备,可分别访问小核Linux和大核RTSmart 大核RTSmart系统中会开机会自动启动一个应用程序,可按q键退出至命令提示符终端;
三、搭建文件传输环境
windows系统
(1) Tftpd64安装,在https://bitbucket.org/phjounin/tftpd64/downloads/下载。
(2) MobaXterm安装:在https://mobaxterm.mobatek.net/download.html下载安装。
(2)配置PC网络:


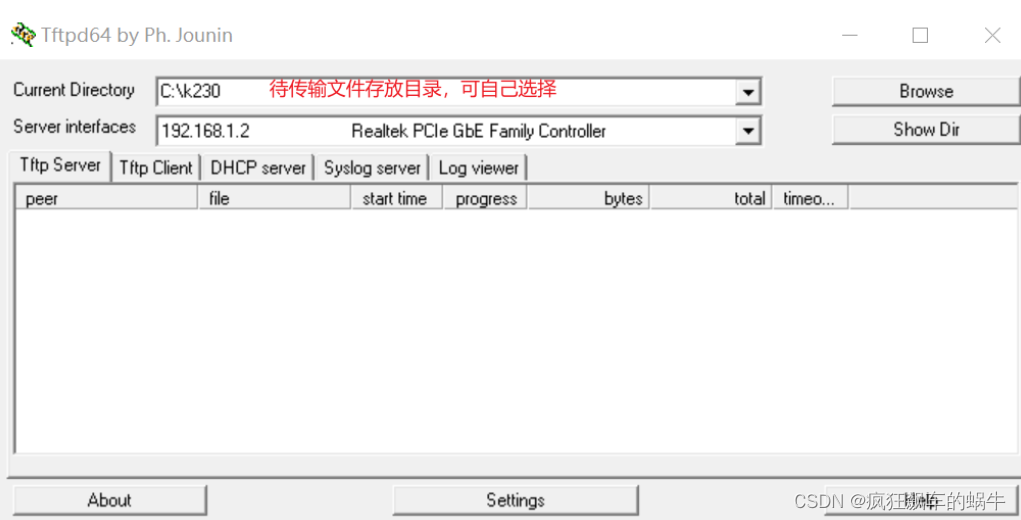
开发板网络配置:
开发板上电,电源线、网线、 COM口连接线配置见文档: K230_SDK_使用说明。打开MobaXterm,通过两路COM串口连接开发板, COM编号不固定,较小为小核串口,较大为大核串口。

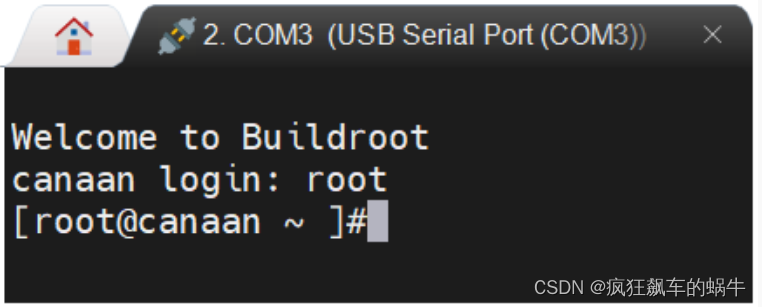
小核进入后回车,进入如下界面,使用root登录:
大核进入后回车,进入如下界面

在小核配置网络

大小核共享存储区域: /sharefs
当要从Tftpd64配置的文件中拷贝数据时,在小核界面使用如下命令:
#192.168.1.2 为PC的局域网IP
# 192.168.1.2 为PC的局域网IP
tftp -g -r your_file_name 192.168.1.2
当将开发板文件拷贝到PC端Tftpd64配置的文件夹下时,在小核使用如下命令:
# 192.168.1.2 为PC的局域网IP
tftp -p -r your_file_name 192.168.1.2
在Linux系统中, PC正常连接网络,开发板可以通过网线连接PC所在网关下其他网口,通过scp命令实现文件传输。
开发板上电,进入大小核COM界面,在小核执行scp传输命令:
# 从PC拷贝文件至开发板
scp 用户名@域名或IP:文件所在目录 开发板目的目录
# 从开发板拷贝文件至PC
scp 开发板待拷贝目录 用户名@域名或IP:PC目的目录
将部署资源压缩包deployment_source.zip解压,阅读README.md,将子文件夹example_code_k230拷贝到SDK文件目录下的src/big/nncase子目录下,授予权限,编译elf可执行文件。编译K230-EVB开发板的可执行文件
chmod +x build_app.sh
./build_app.sh evb
编译结束后在example_code_k230文件夹下的k230_bin中可以获得编译完成的main.elf文件。
编译CANMV-K230开发板的可执行文件:
chmod +x build_app.sh
./build_app.sh
四、文件传输
在小核/sharefs下新建一子目录test_deploy
cd /sharefs
mkdir test_deploy
cd test_deploy
通过tftp将部署资源包中的kmodel文件、 deploy_config.json文件、 main.elf文件和待测试图片文件拷贝到小核/sharefs/test_deploy目录下
五、调试
上板调试命令
# 进入大核对应目录下, 执行main.elf deploy_config.json 图片/None debug_mode
# deploy_config.json是部署配置文件
# 图片/None 如果是图片路径, 则执行静态图推理, 如果调用摄像头进行视频流推理, 此参数为None
# debug_mode: 调试模式, 有0、 1、 2三个选项; 分别对应不调试、 简单调试、 详细调试
在大核中进入/sharefs/test_deploy目录下,执行main.elf可执行文件。
# 静态图推理调试
main.elf deploy_config.json test.jpg 1
# 视频流推理调试
main.elf deploy_config.json None 1
六、MicroPython部署
注意:训练环境中nncase和nncase-kpu的版本和SDK的版本要对应, nncase和nncase-kpu版本为2.4.0, SDK版本为1.1。
上板部署过程分为以下几个步骤:
CanMV 的目的是让 AIOT 编程更简单, 基于 Micropython 语法, 运行在Canaan强大的嵌入式AI SOC系
列上。目前它在K230上运行。使用docker编译环境,下载k230_CanMV。
git clone https://github.com/kendryte/k230_canmv.git
cd k230_canmv
make prepare_sourcecode
# 生成docker镜像(第一次编译需要, 已经生成docker镜像后跳过此步骤, 可选)
docker build -f k230_sdk/tools/docker/Dockerfile -t k230_docker
k230_sdk/tools/docker
# 启动docker环境(可选)
docker run -u root -it -v $(pwd):$(pwd) -v
$(pwd)/k230_sdk/toolchain:/opt/toolchain -w $(pwd) k230_docker /bin/bash
# 默认使用canmv板卡, 如果需要使用其他板卡, 请使用 make CONF=k230_xx_defconfig, 支持的
板卡在configs目录下
make
编译完成后会在 output/k230_xx_defconfig/images 目录下生成 sysimage-sdcard.img 镜像。
按下图步骤,建立连接。点击如下按钮:

选择除大小核串口外的第三个串口:

连接建立后,选择文件->打开文件,选择解压的部署包mp_deployment_source中的##_image.py和##__video.py,编辑更改kmodel和deploy_config.json文件的拷贝路径。

点击左下角的绿色三角按钮运行,点击串行终端查看命令行输出。
总结
K210的介绍就到这里,接下来给大家介绍最新的K230芯片开发板,如需购买可以到pdd和淘宝搜索维脑科技,购买CANMV-K230开发吧;
这篇关于AI嵌入式K210项目(29)-模型加载的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








