本文主要是介绍2小时,5大步骤,100+人用数睿数据无代码搭建了一套培训申请系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前几天“00后职校女生自学低代码月薪破万”的话题上了微博热搜,再次把“低代码”推上风口浪尖,评论也是众说纷纭,撇开明显的广告嫌疑以及用特例推导结论的套路,至少说明以低/无代码为代表的新型软件开发方法已经逐渐走入大众视野。
经济学家熊彼特在1912年《经济发展理论》中指出,所谓创新就是建立一种新的生产函数,然后把过去的旧生产要素,用新函数重新组合起来。
我们认为无代码开发就是在构建一种全新的生产函数,在产业数字化的大背景下,无代码让企业管理创新和试错的成本下降,让数字化与业务越来越近,让IT从“成本”变成“生产力”。
重新认识无代码
• 无代码与低代码的求同存异
在无代码的科普环节,和低代码的对比是一个避不开的话题。毫无疑问,无代码与低代码都提供了可视化的开发界面,通过拖拉拽就能生成相应的应用程序。说白了,两者都打破了技术上的限制,降低开发门槛,能够敏捷快速地开发符合企业个性化需求的应用程序。
大部分人理解两者的区别主要在于程序员参与编写代码量的多少:低代码解决的是程序员代码繁重的问题,核心是减少代码量、帮助程序员减负,提升的是程序员写代码的效率;而无代码的门槛更低,非IT出身的业务人员无需通过手工编码也能掌握软件开发。
网上现在有很多对比无代码和低代码的文章,大部分都是根据使用场景去判断的。无代码由于操作更简单,完全不需要写代码,就被判断只能搭建轻量级的简单应用,再加上部分媒体过分神话“公民开发”的概念,也让一些专业开发人员对无代码直接定性为“乌托邦”,其实是有失公允的。
深入来看,数睿数据认为无代码和低代码解决的问题和解题思路都是不同的。
• 证明题:无代码不仅是生产力工具
软件产品是一个完整的生态系统,如果只是搭建静态页面,低代码完全没问题,但是系统自身有各种各样的复杂度:组件之间的关联、内部业务逻辑、形式复杂等,这些复杂度无法通过工具来解决,假设能解决,也只是把复杂度放在工具里(定制开发)。
无代码是怎么解决这些复杂度的?我们从软件工程的角度去改变了软件项目的落地方式,包含了需求沟通、应用设计,中间的应用构建、测试,以及最后的实施运维。低代码提升了软件开发的效率,而无代码这种全新的生产函数变革了软件的生产方式。
也有观点认为写代码其实是程序员工作中相对轻松的部分,框架设计、需求拆解、排期安排、和产品经理沟(撕)通(逼)才是真的复杂图片无代码可以赋能那些拥有行业知识与经验的业务人员直接参与软件的实现,甚至是后期的运维和实施,让软件开发不再是程序员的专利。当感受到痛点的人被赋权去开发解决方案时,用户可以自行开发与自己的实际工作方式相匹配的工具,结果完全是独一无二的。
前几天数睿数据联合LowCode低码时代推出了《低码三小时·全民开发大讲堂》第一期·一小时开发企业软件,由CSDN等多家知名IT技术平台同步直播。
伴随我们的教员讲解和培训文档,来自企业和高校用户共120多人积极讨论互动,参与了课程实操环节,来看看他们是如何通过5大步骤轻松搭建一个培训申请系统的吧。
五大步骤搭建一套培训申请系统
Step1. 数据准备
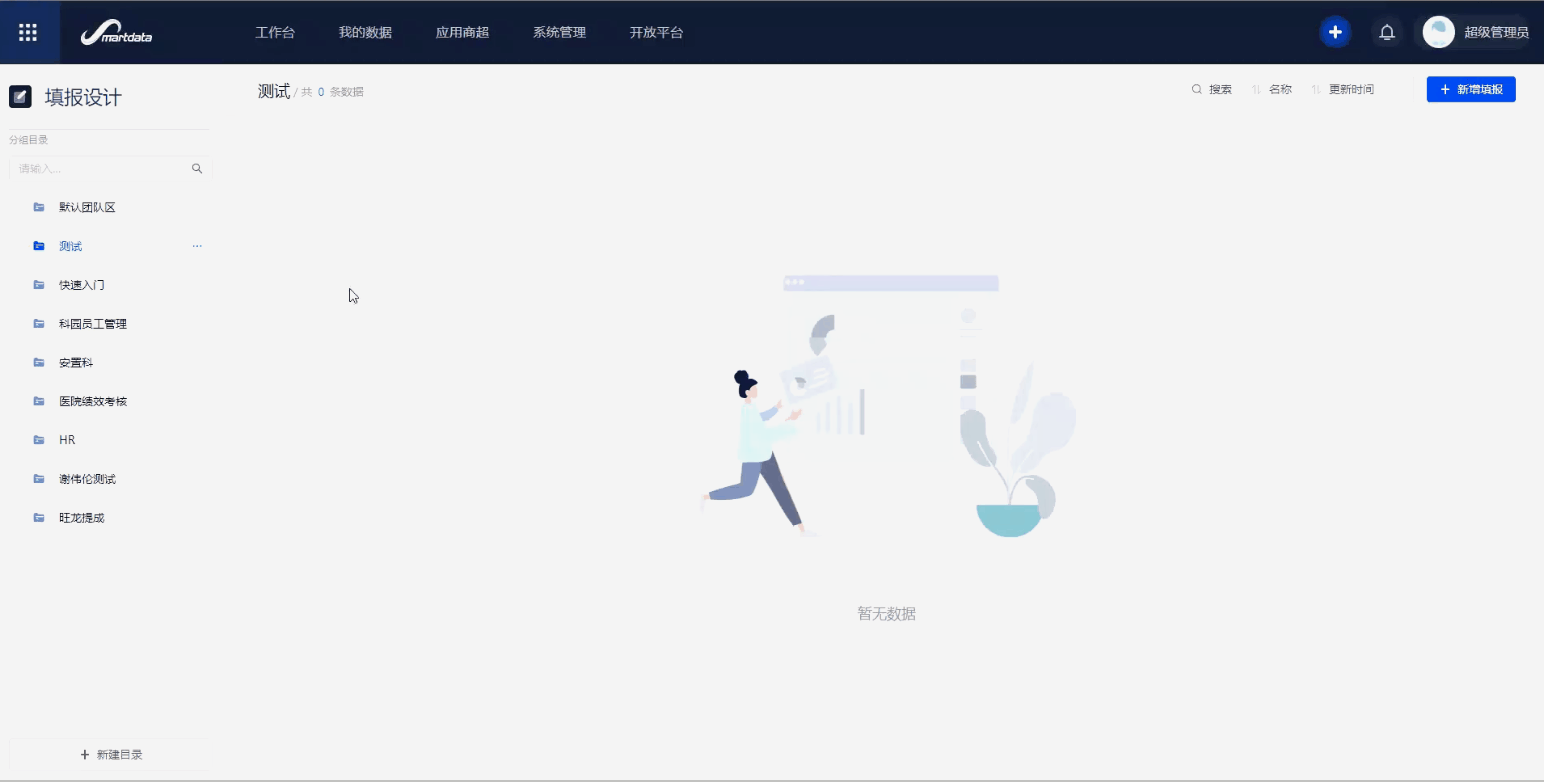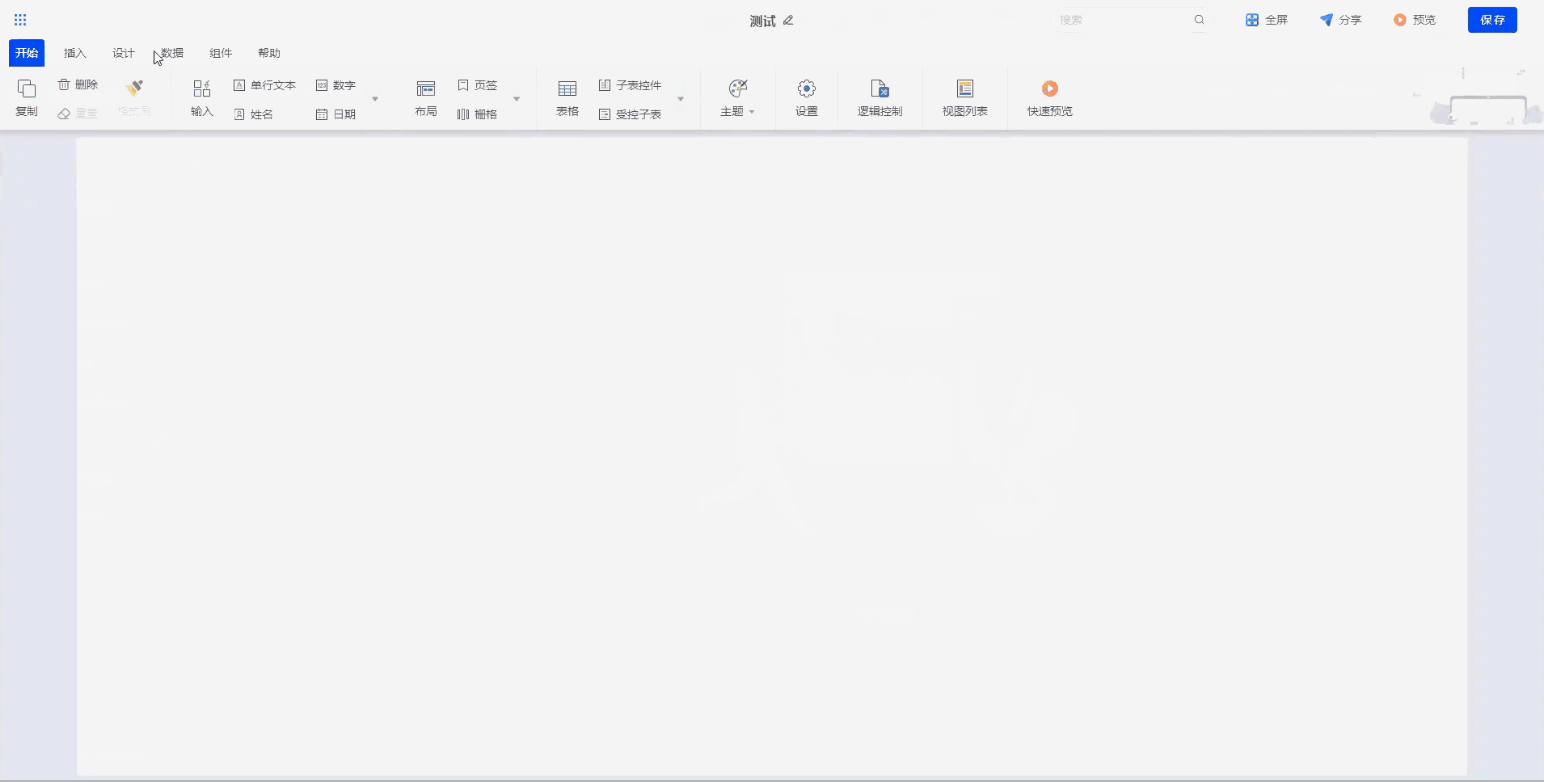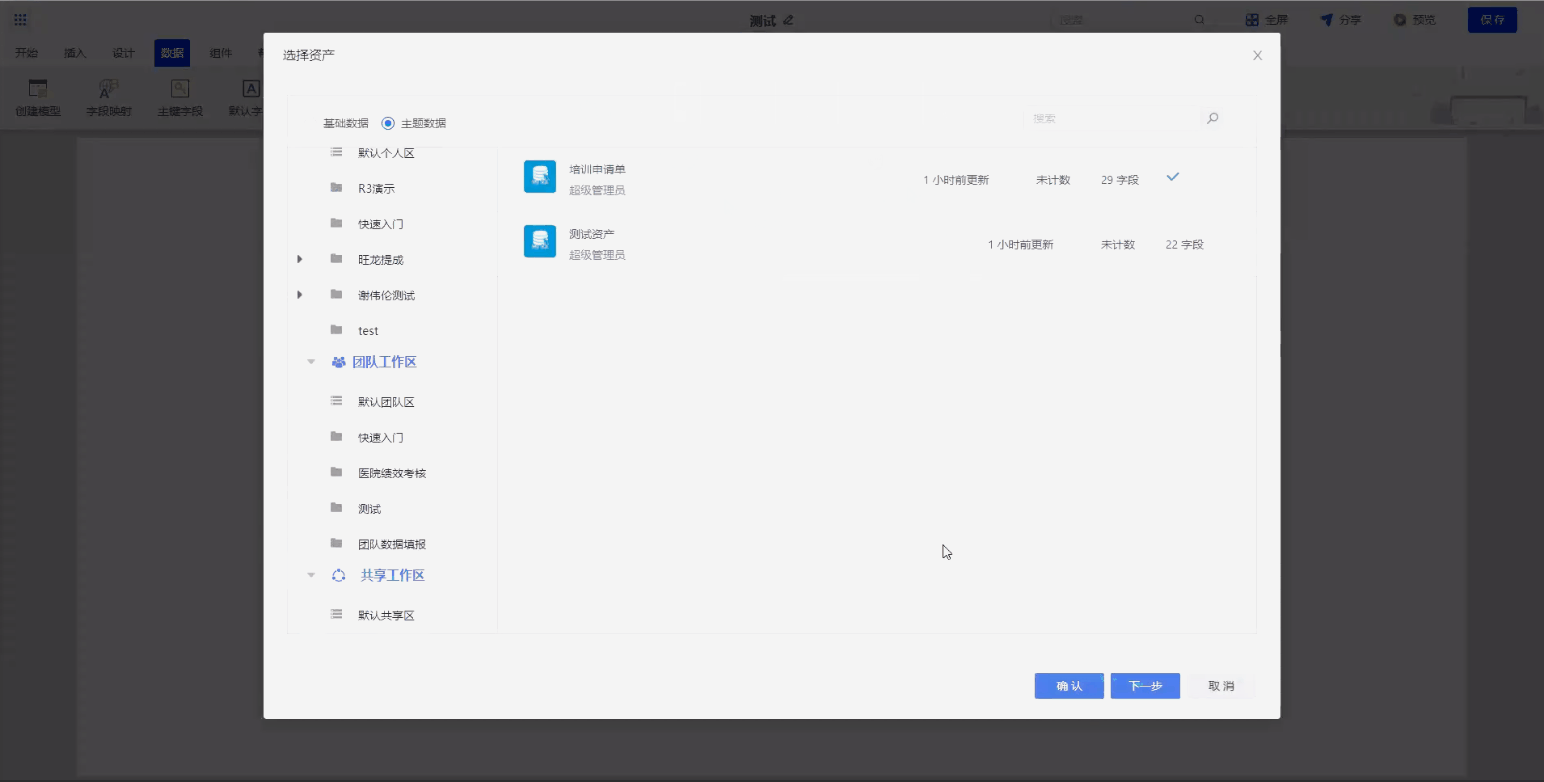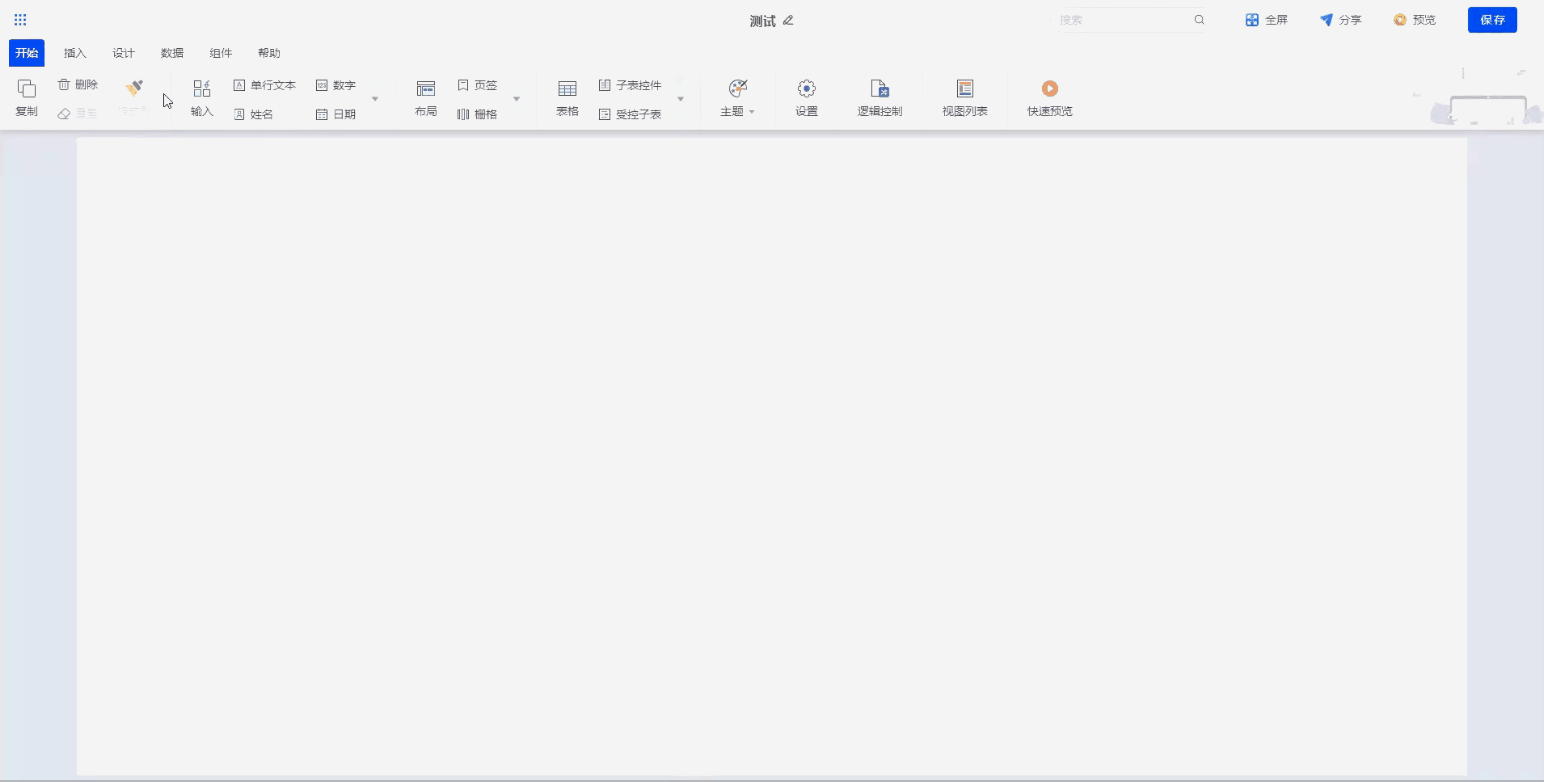
接入数据源、创建资产。数据字段包括申请人、申请时间、事件名称、时间类型等培训申请过程要用到的数据。
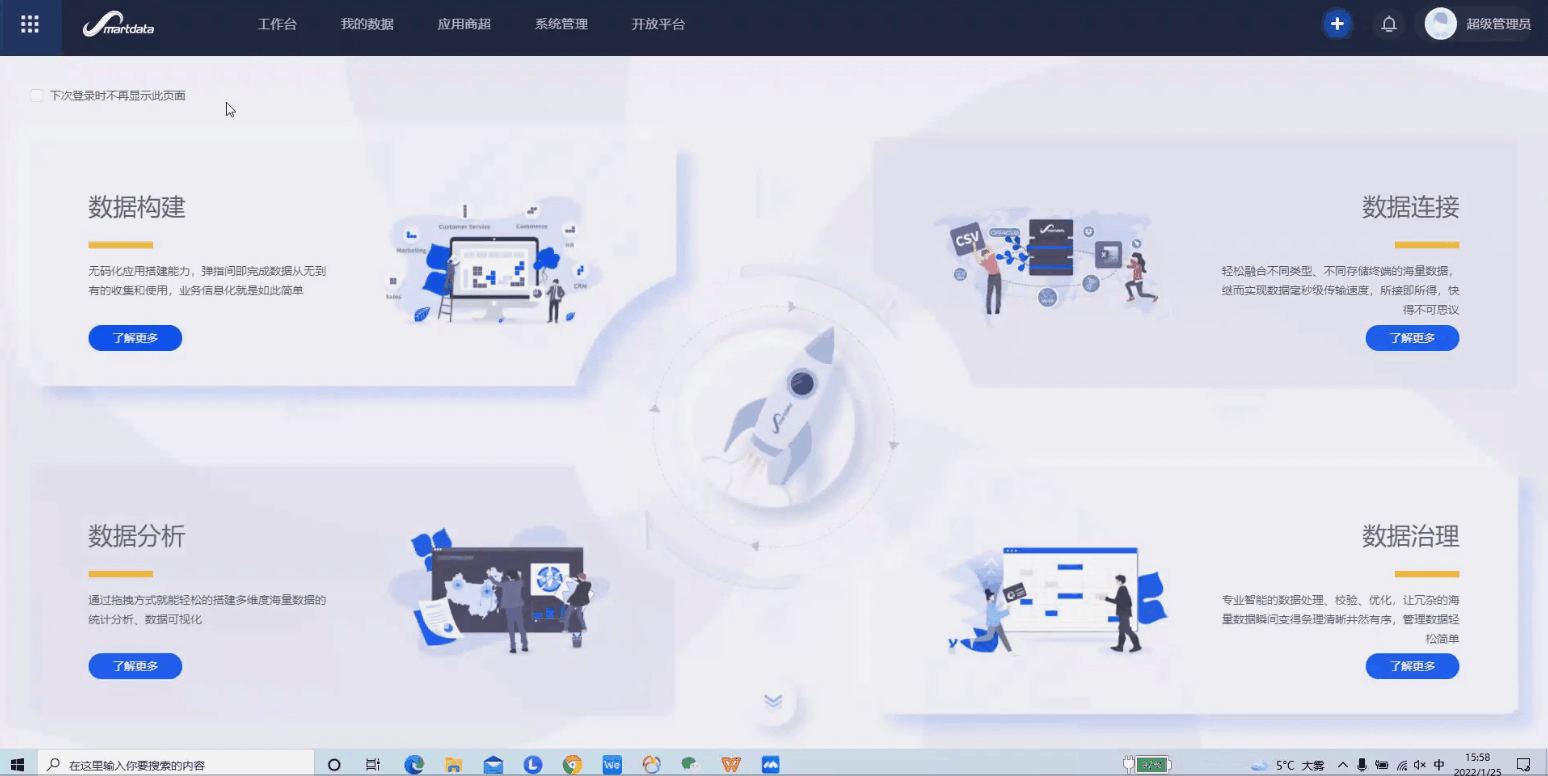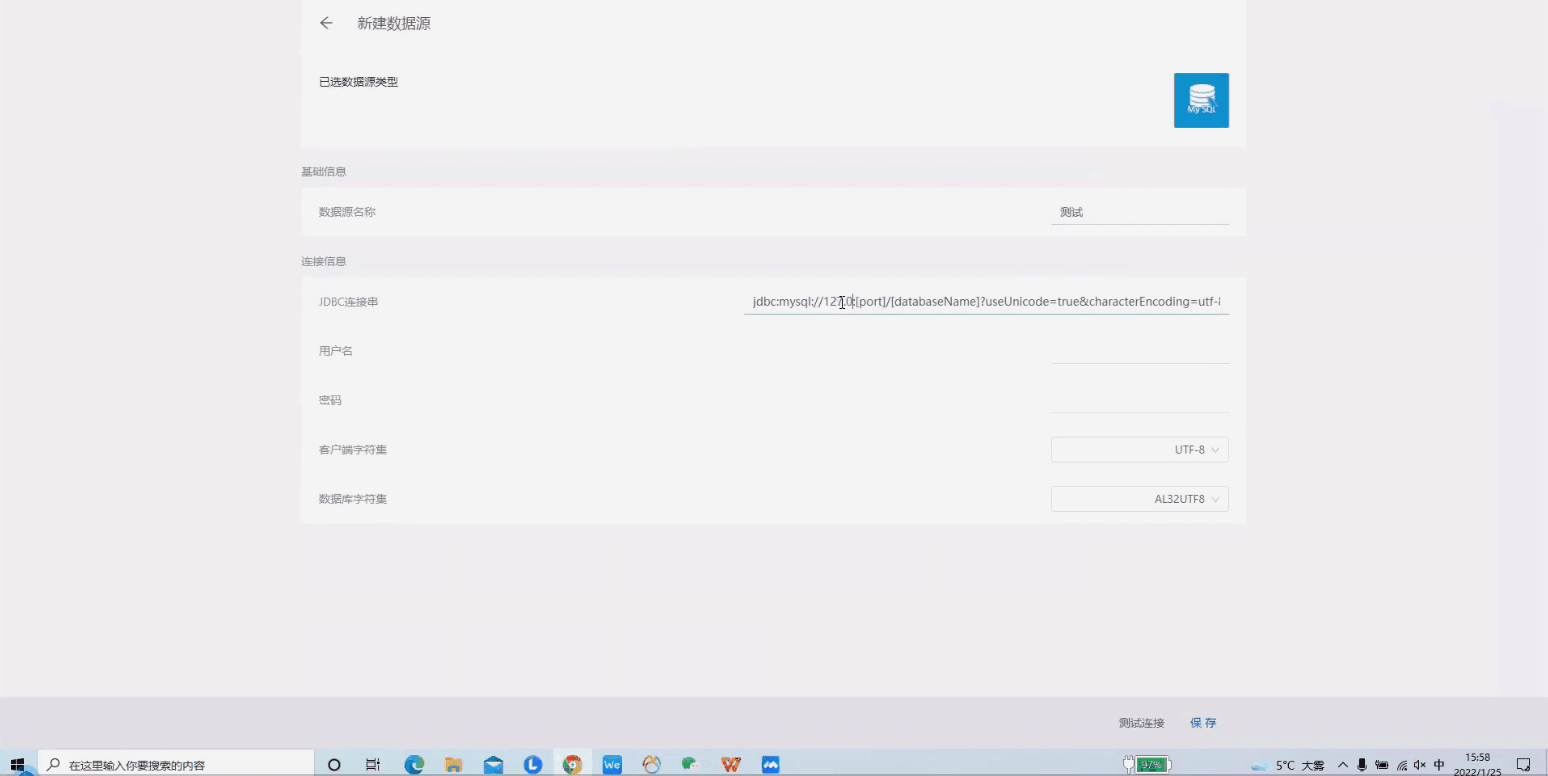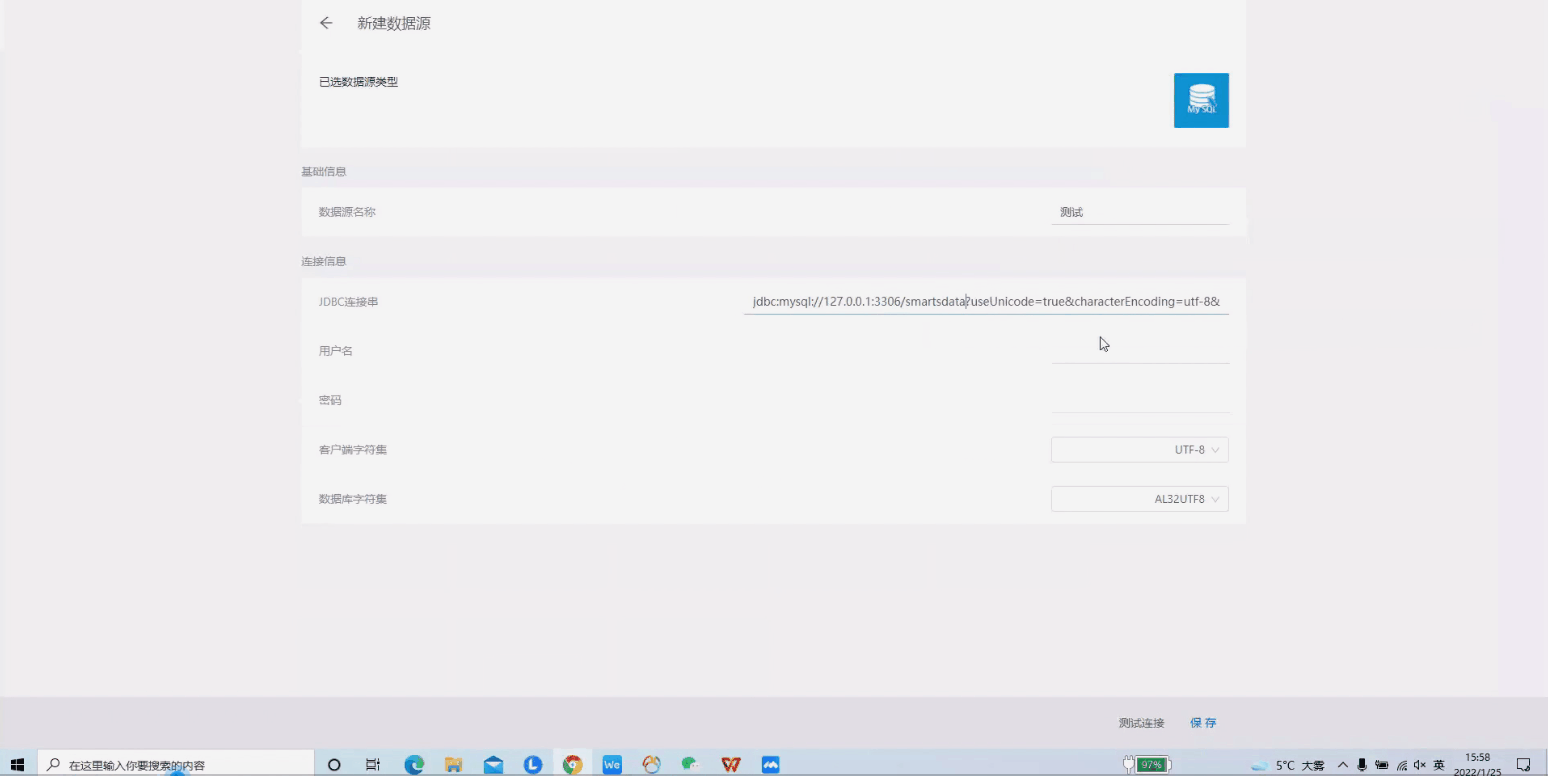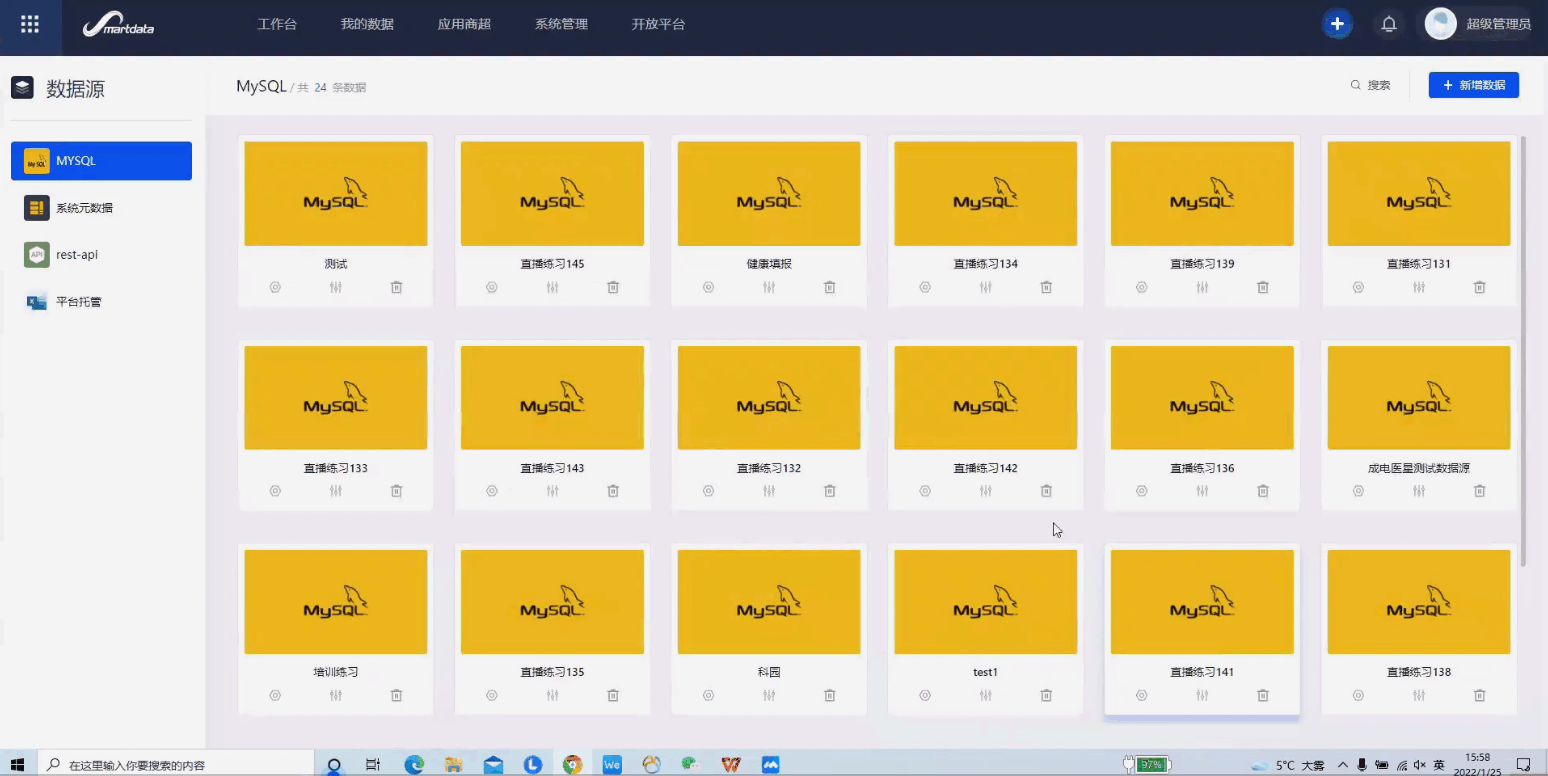 接入数据源
接入数据源 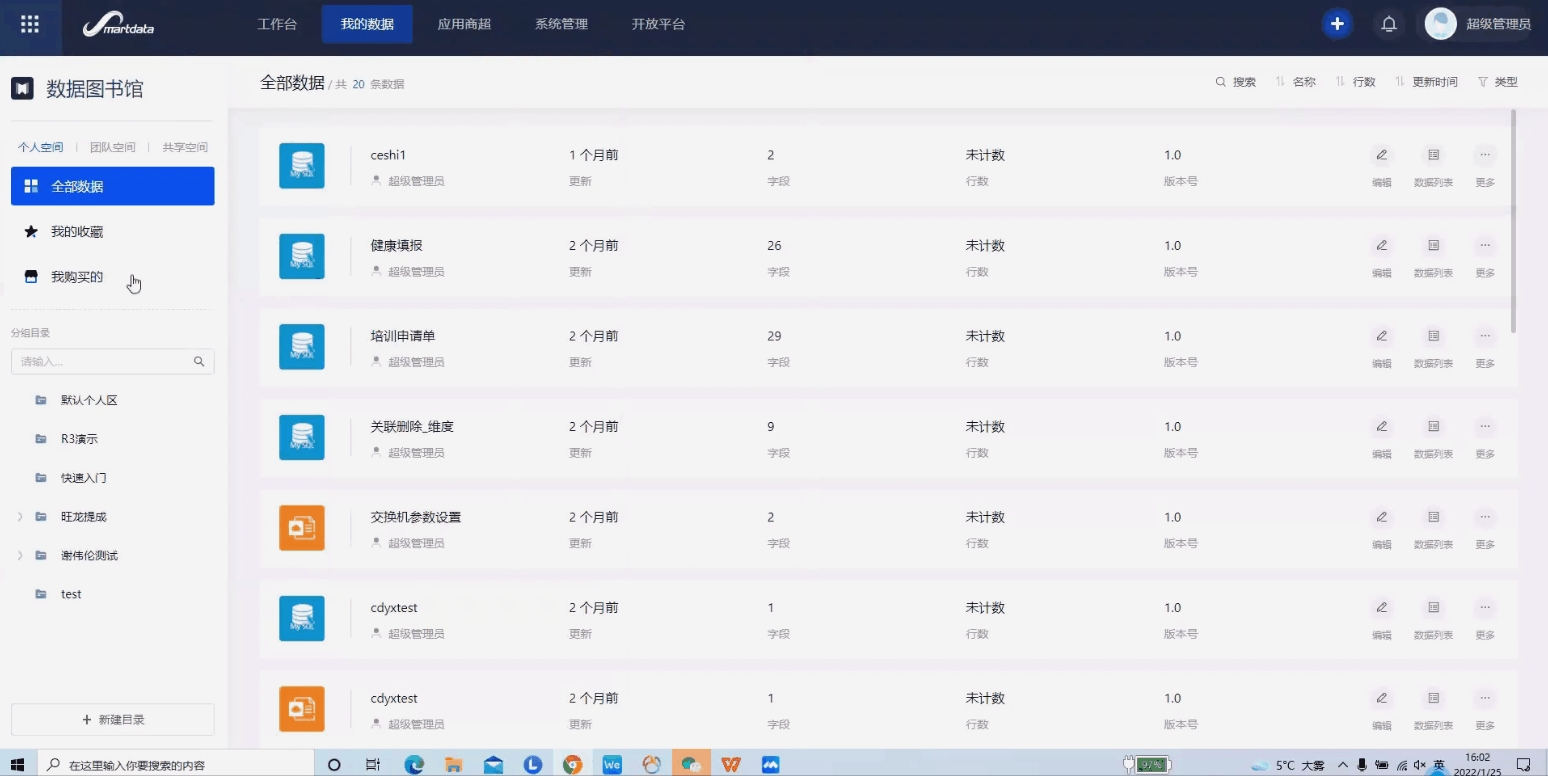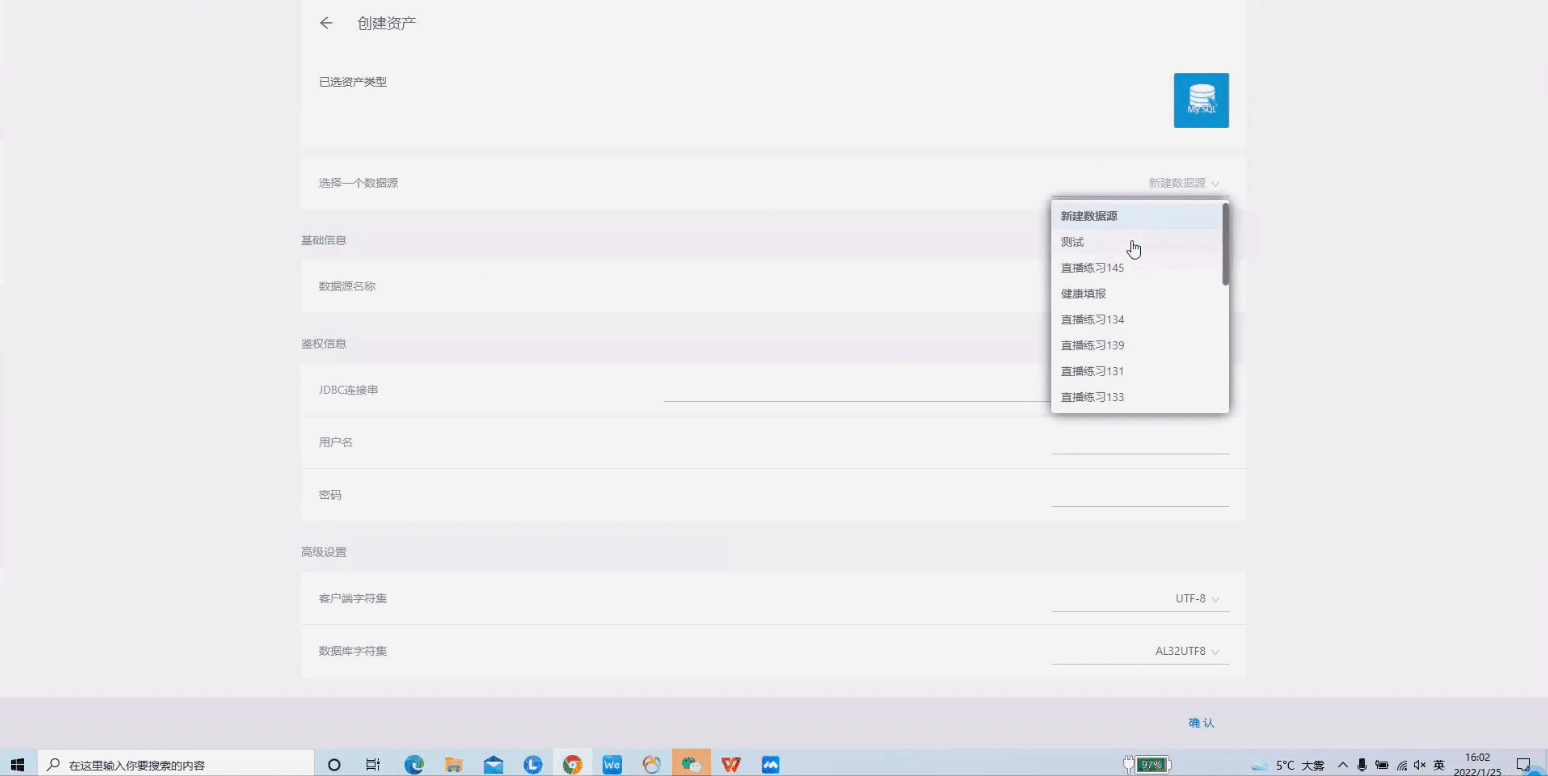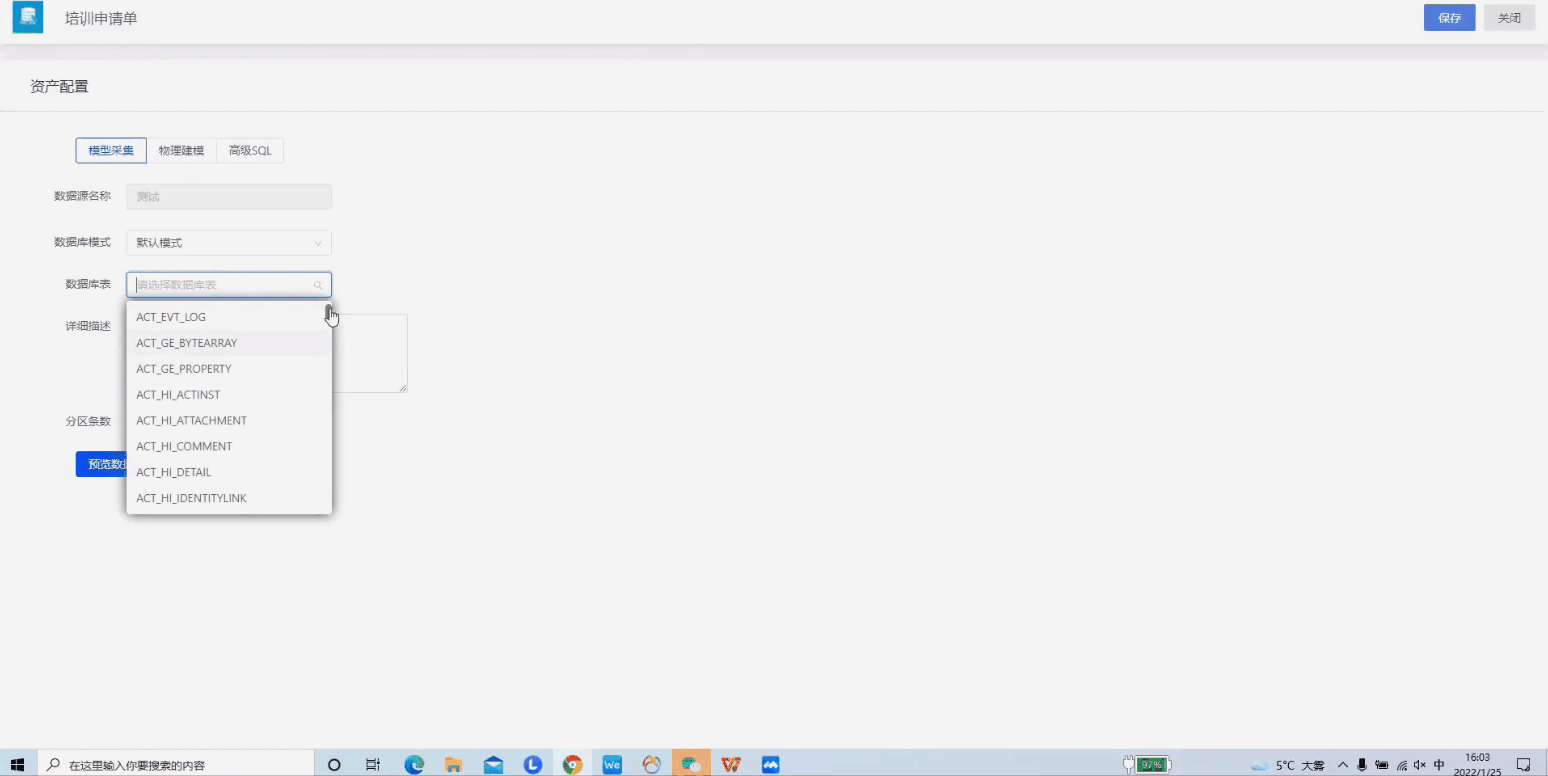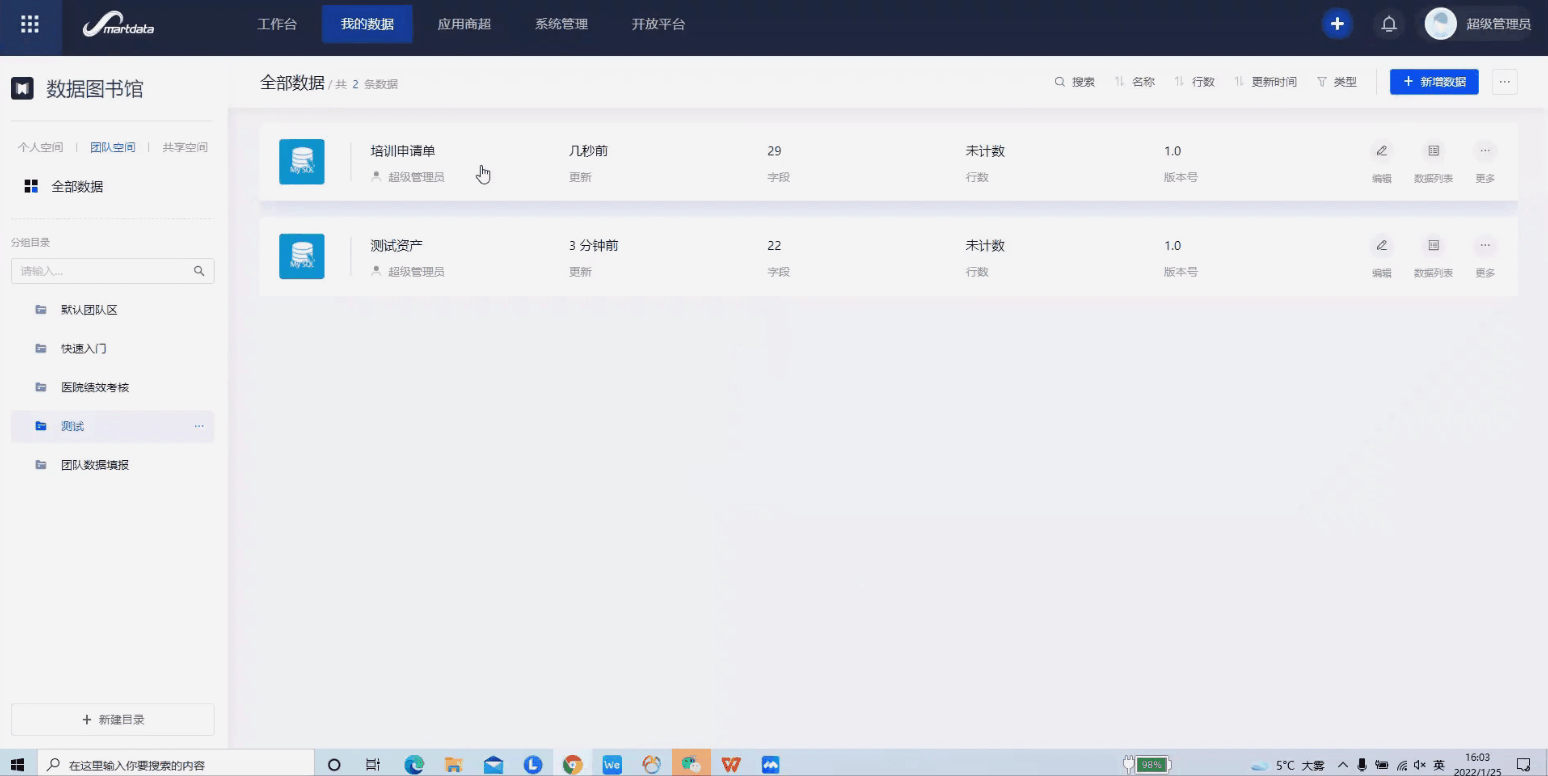
创建数据资产
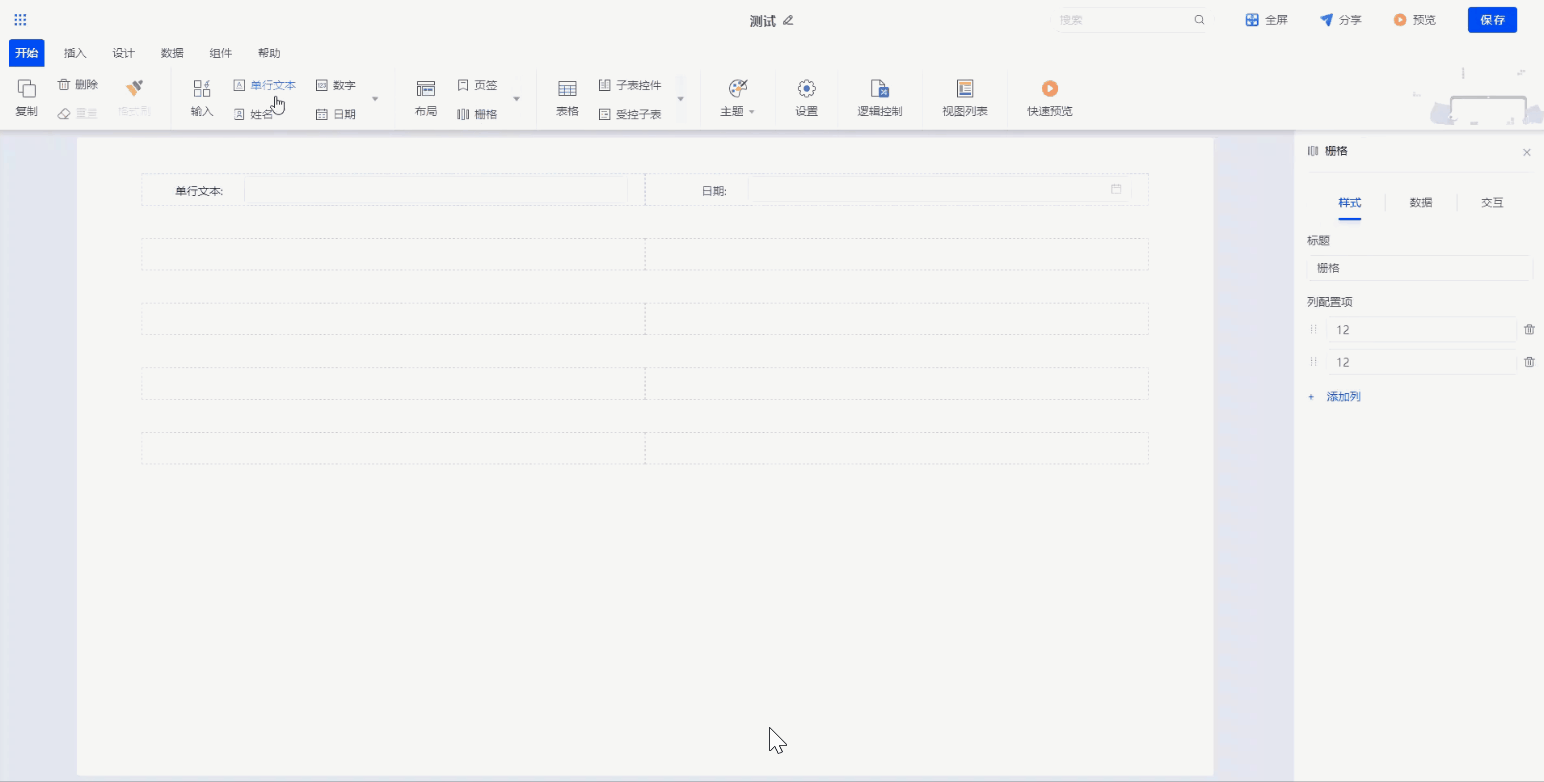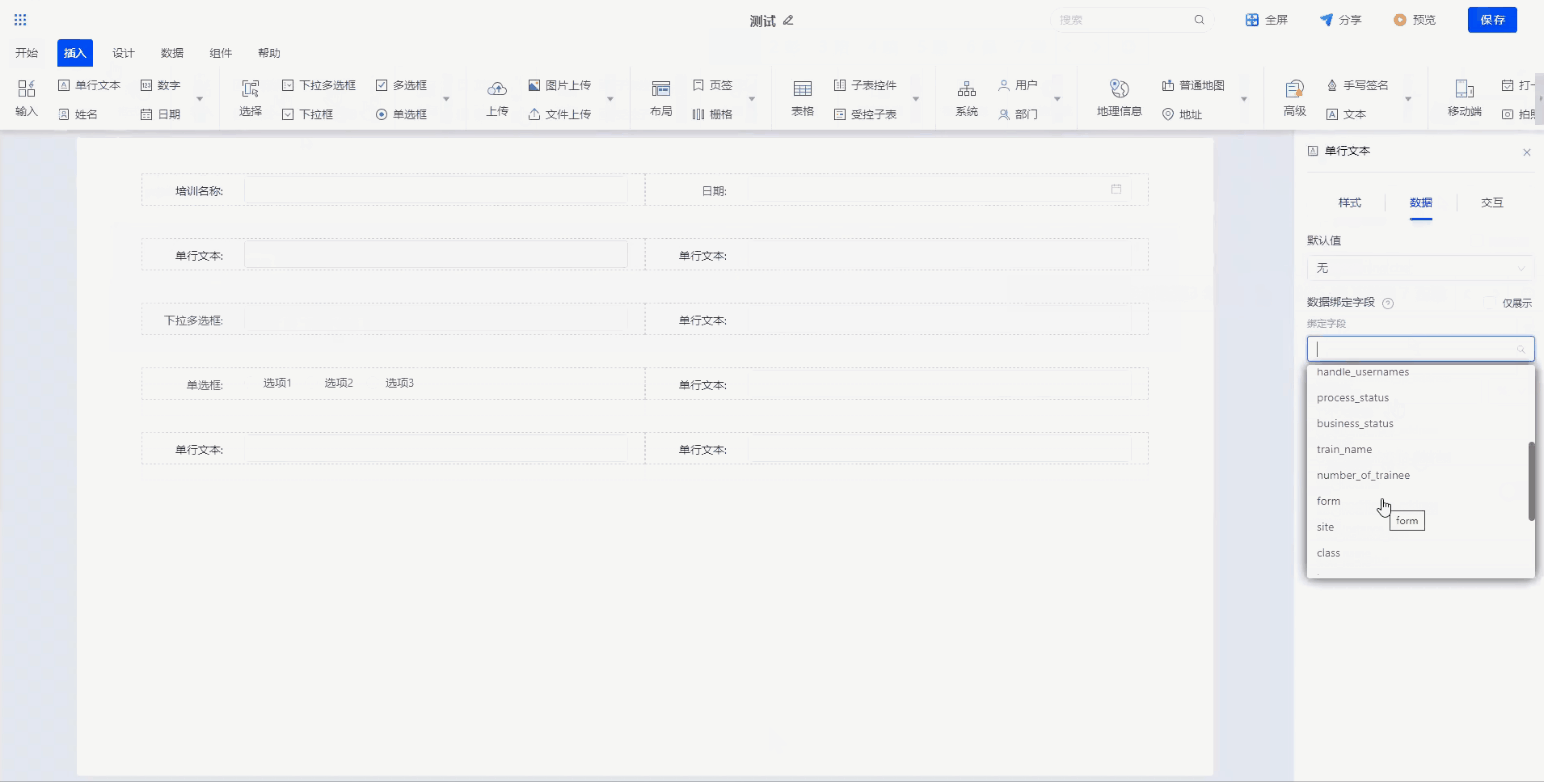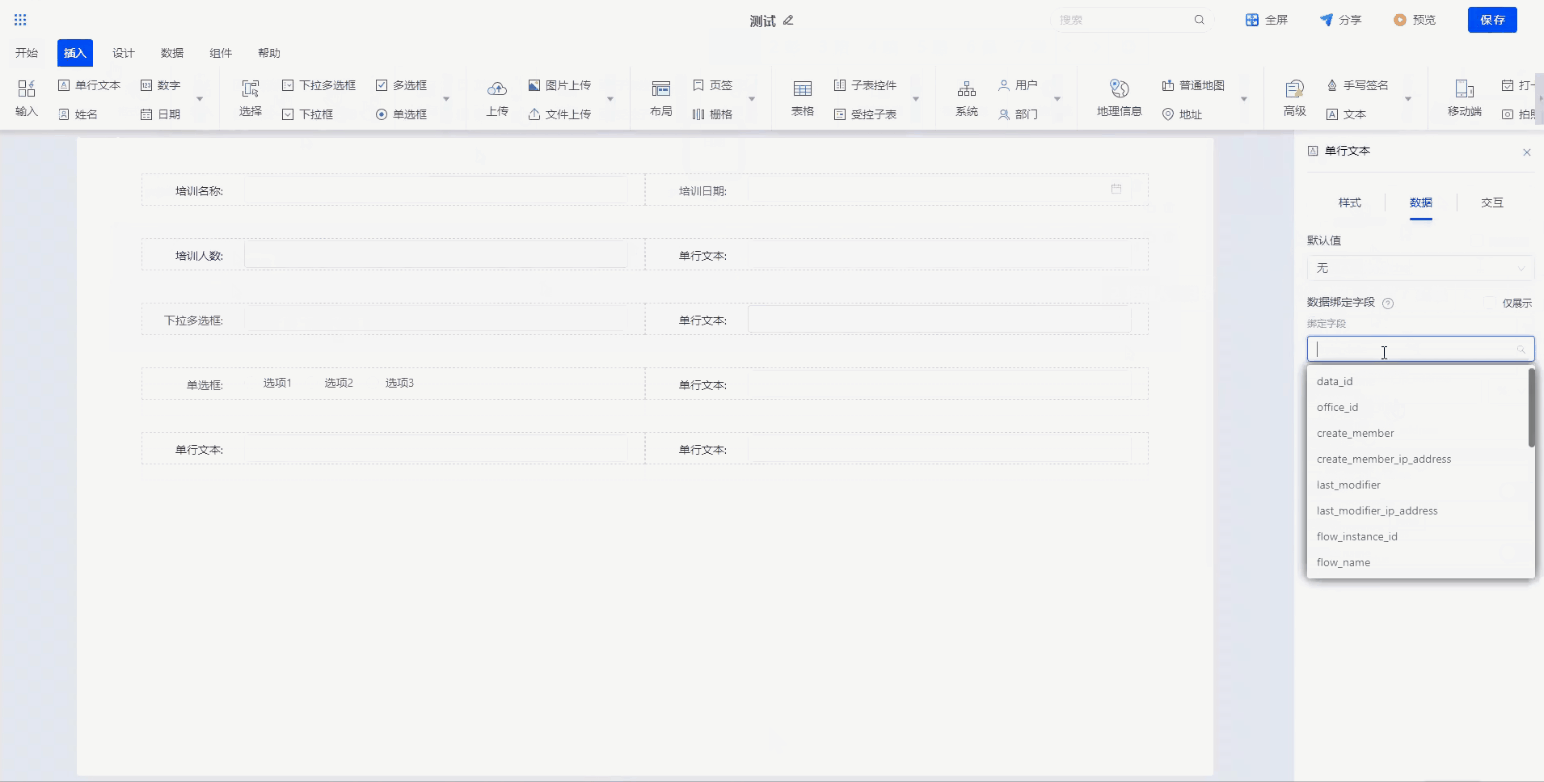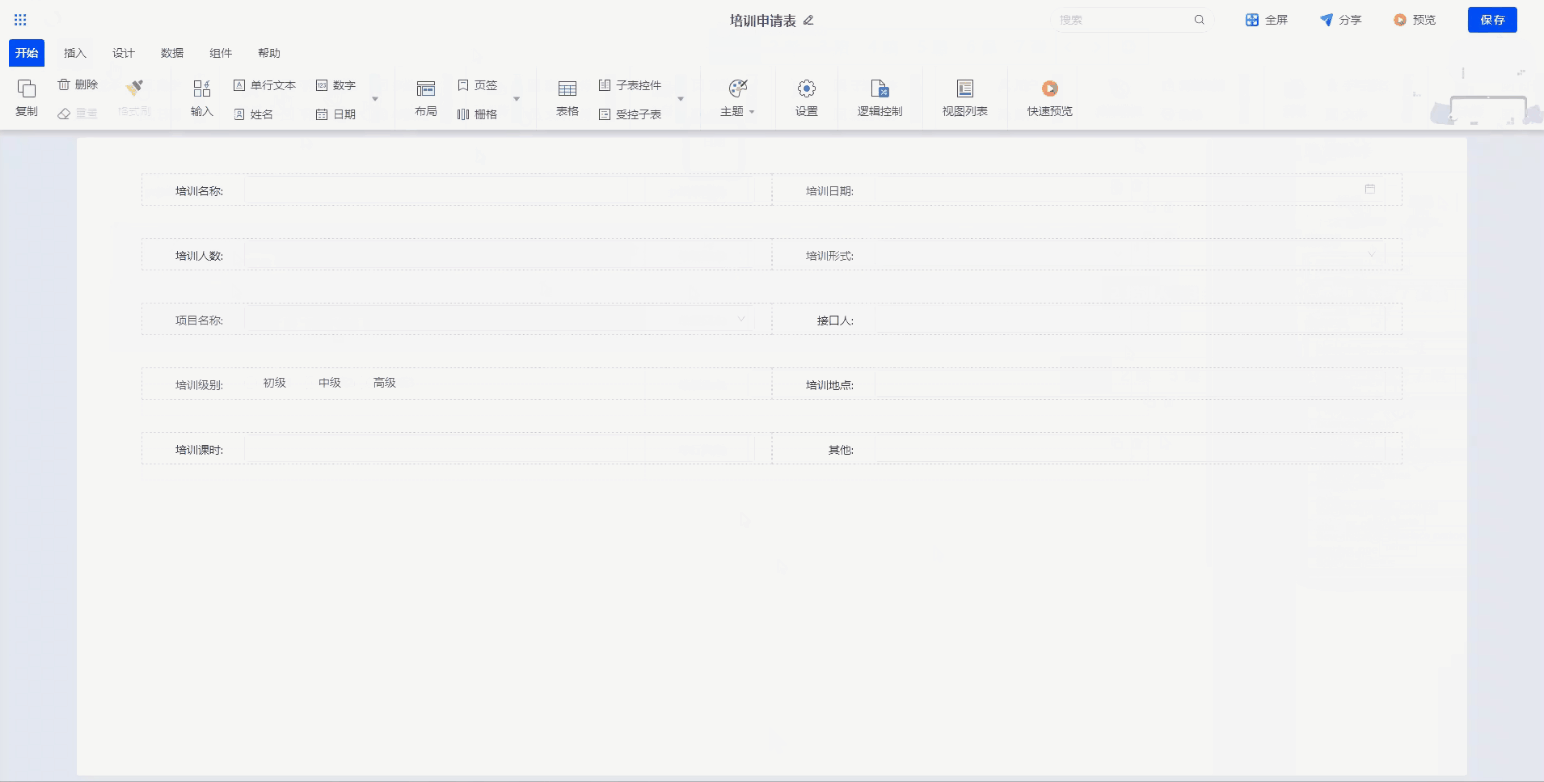
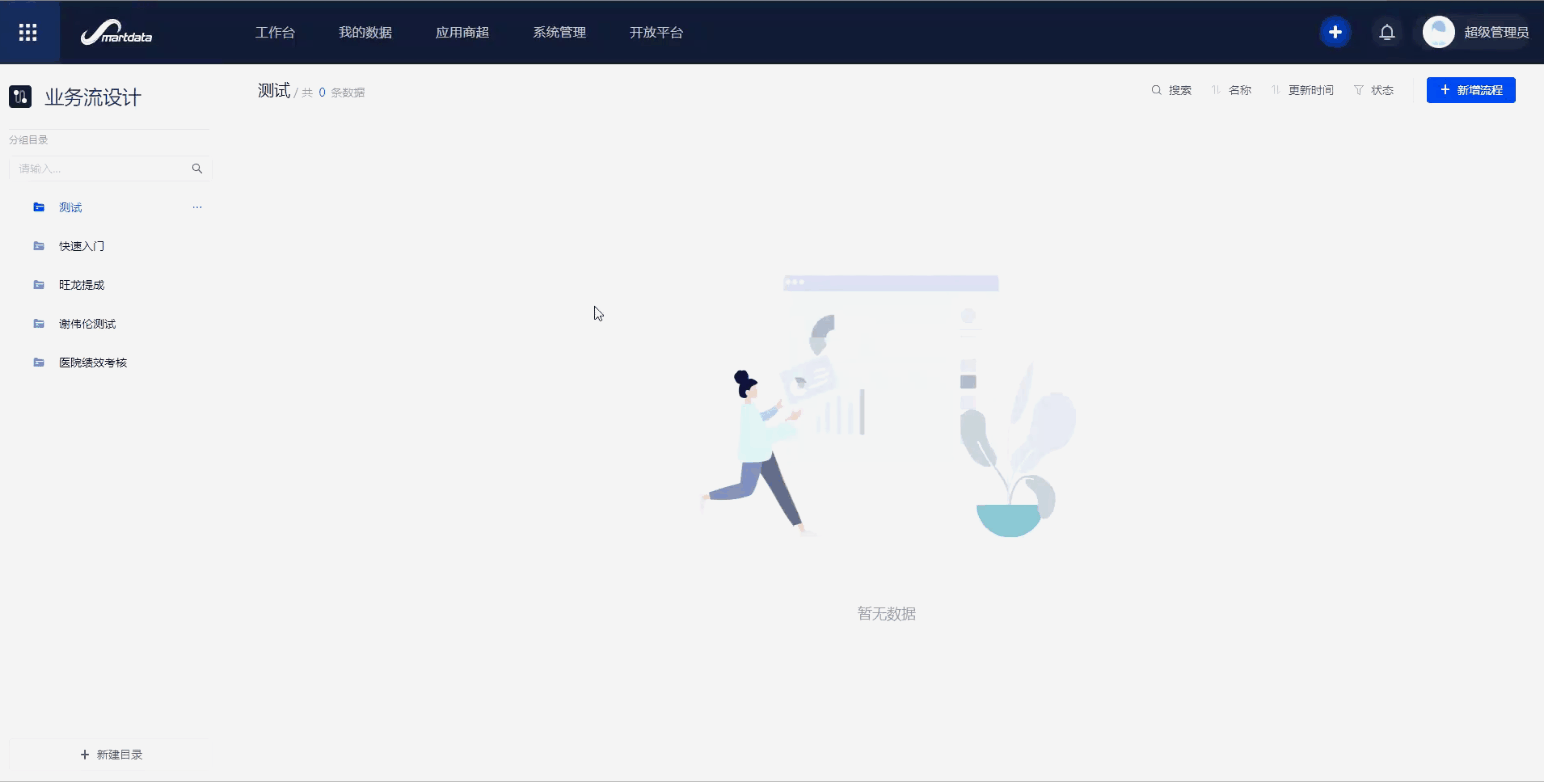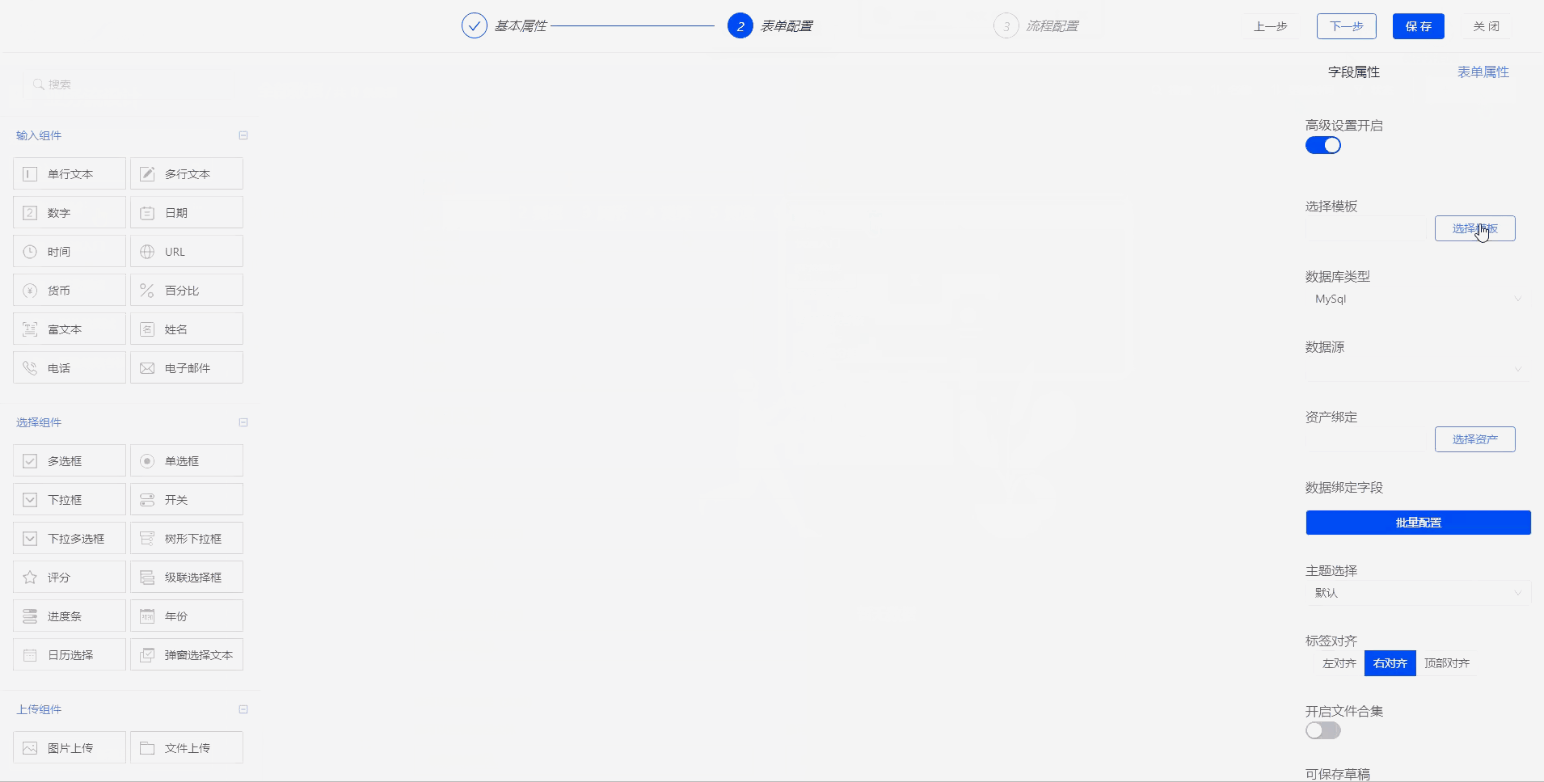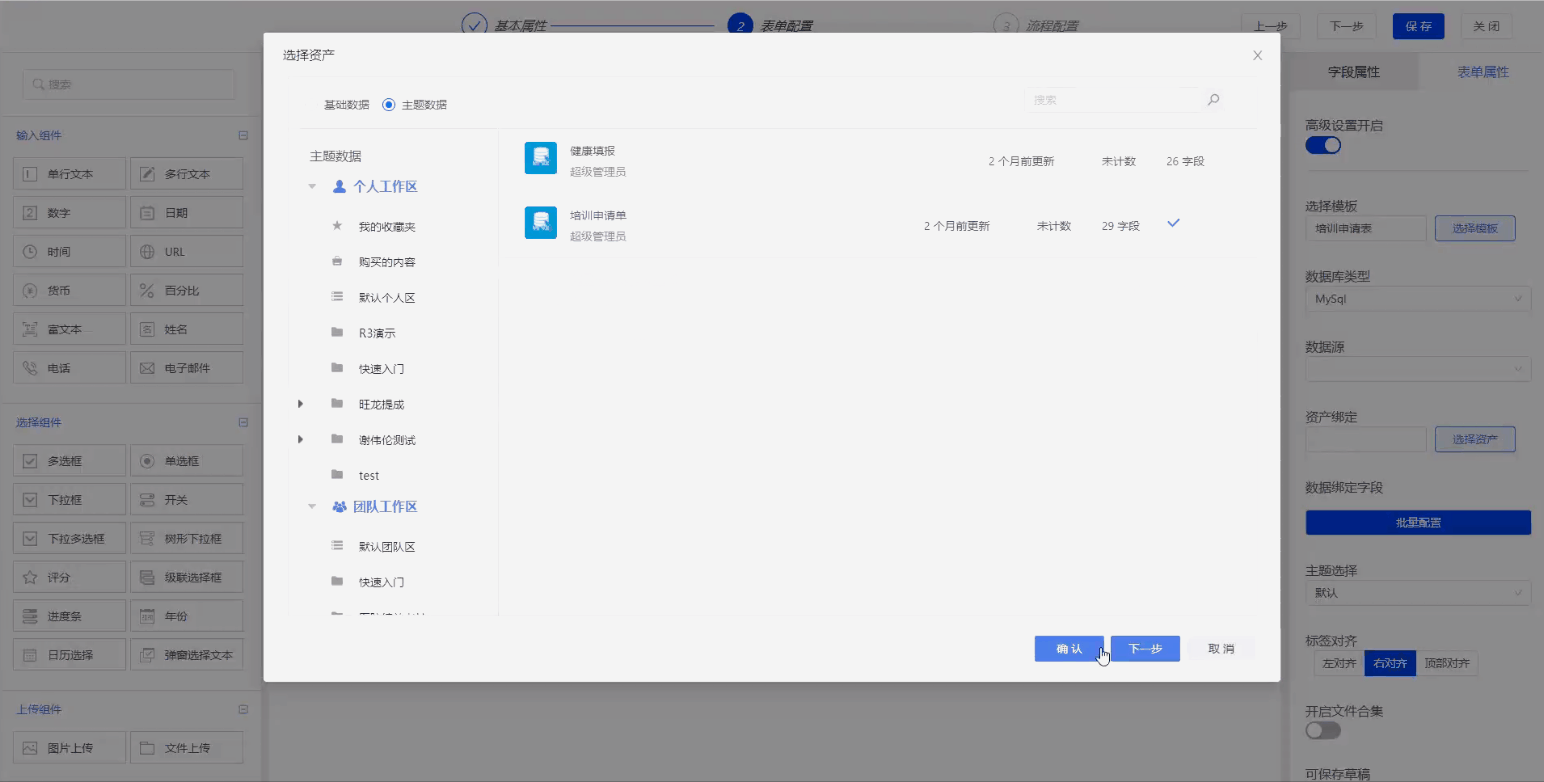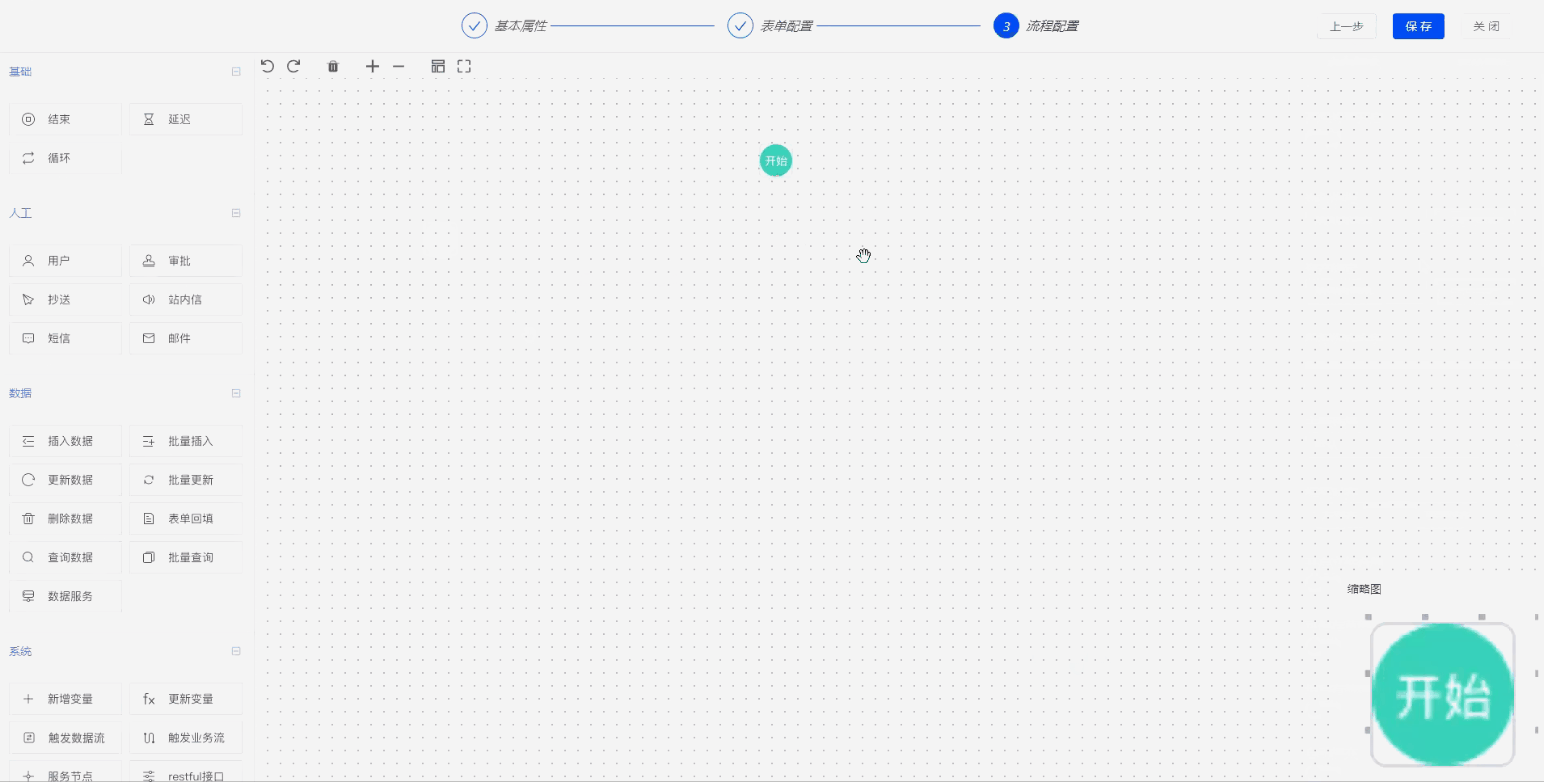
Step2. 填报设计
通过组件拖拽,对培训申请表进行样式设计。同时对申请人、申请信息、申请日期这些信息进行数据绑定,和底层数据库字段进行一一对应,实现前端和数据库的联动。
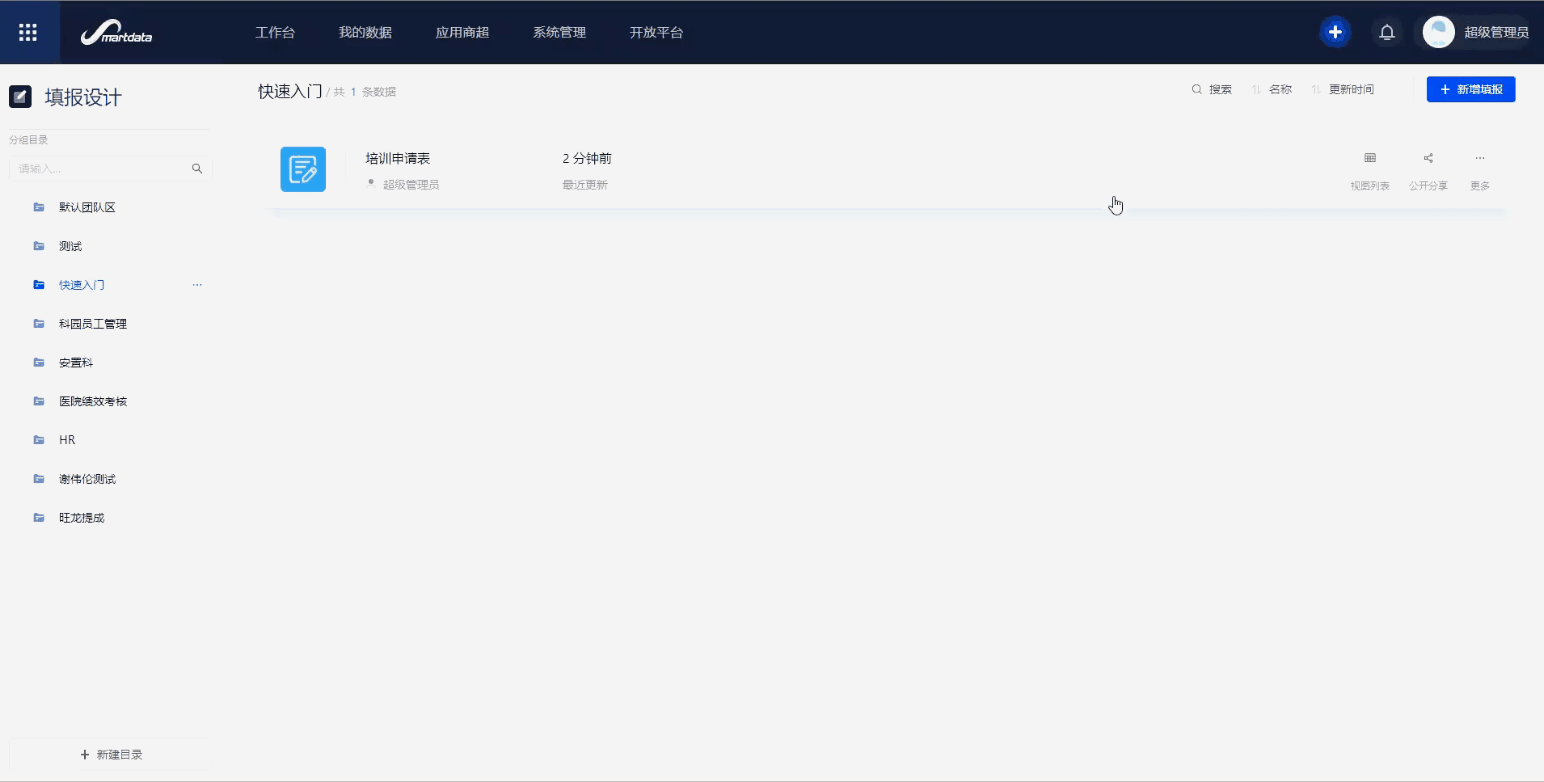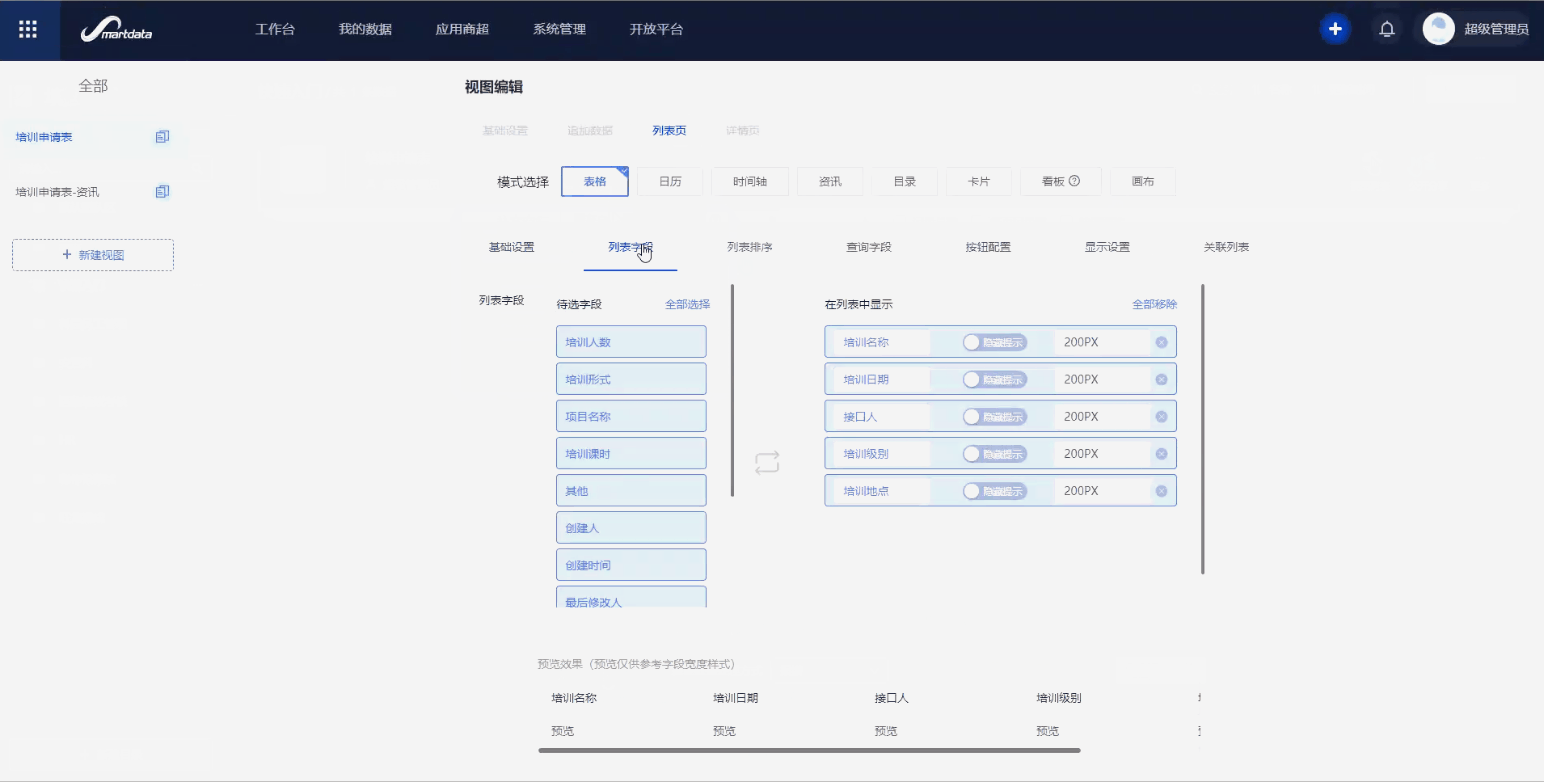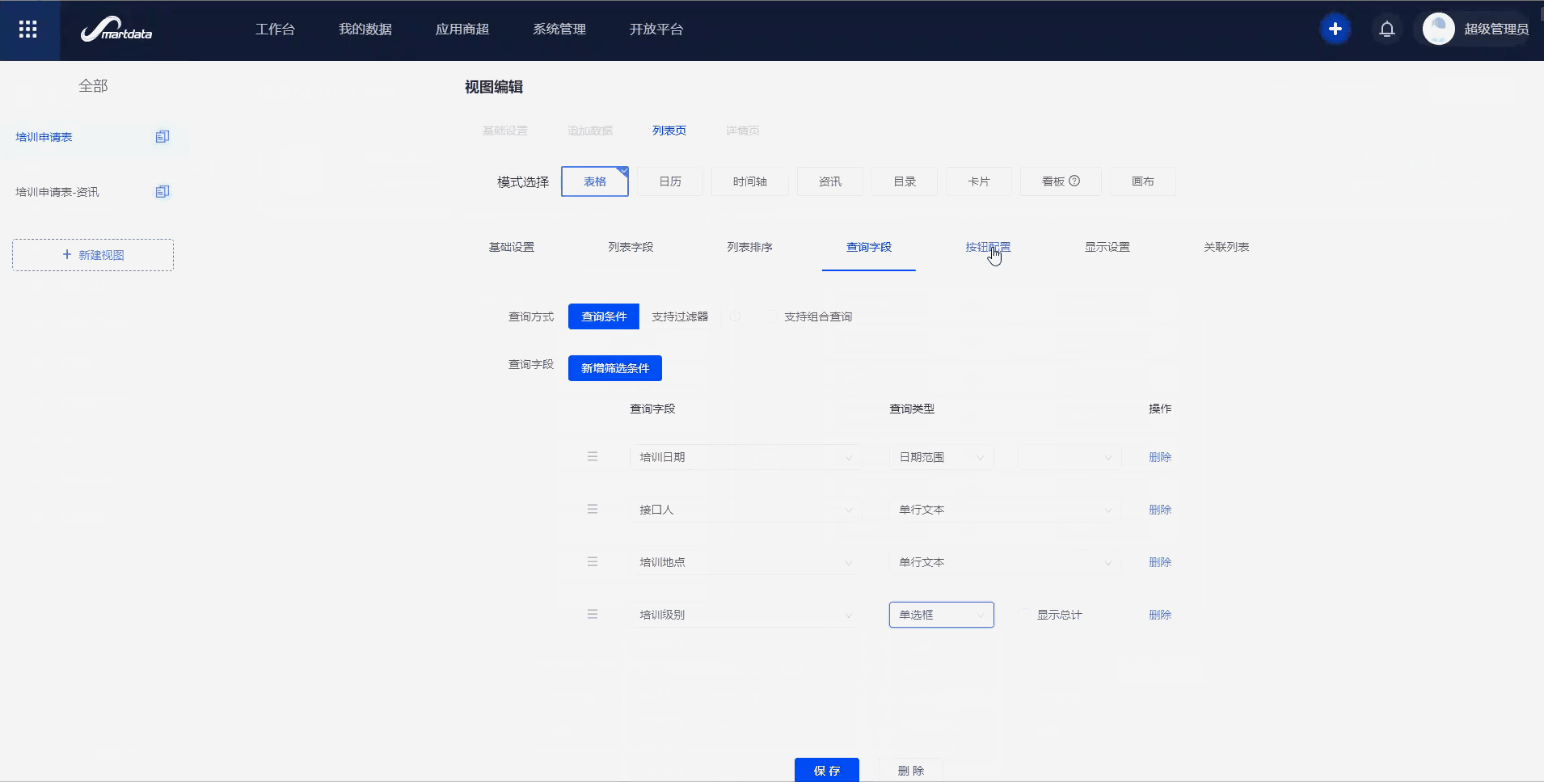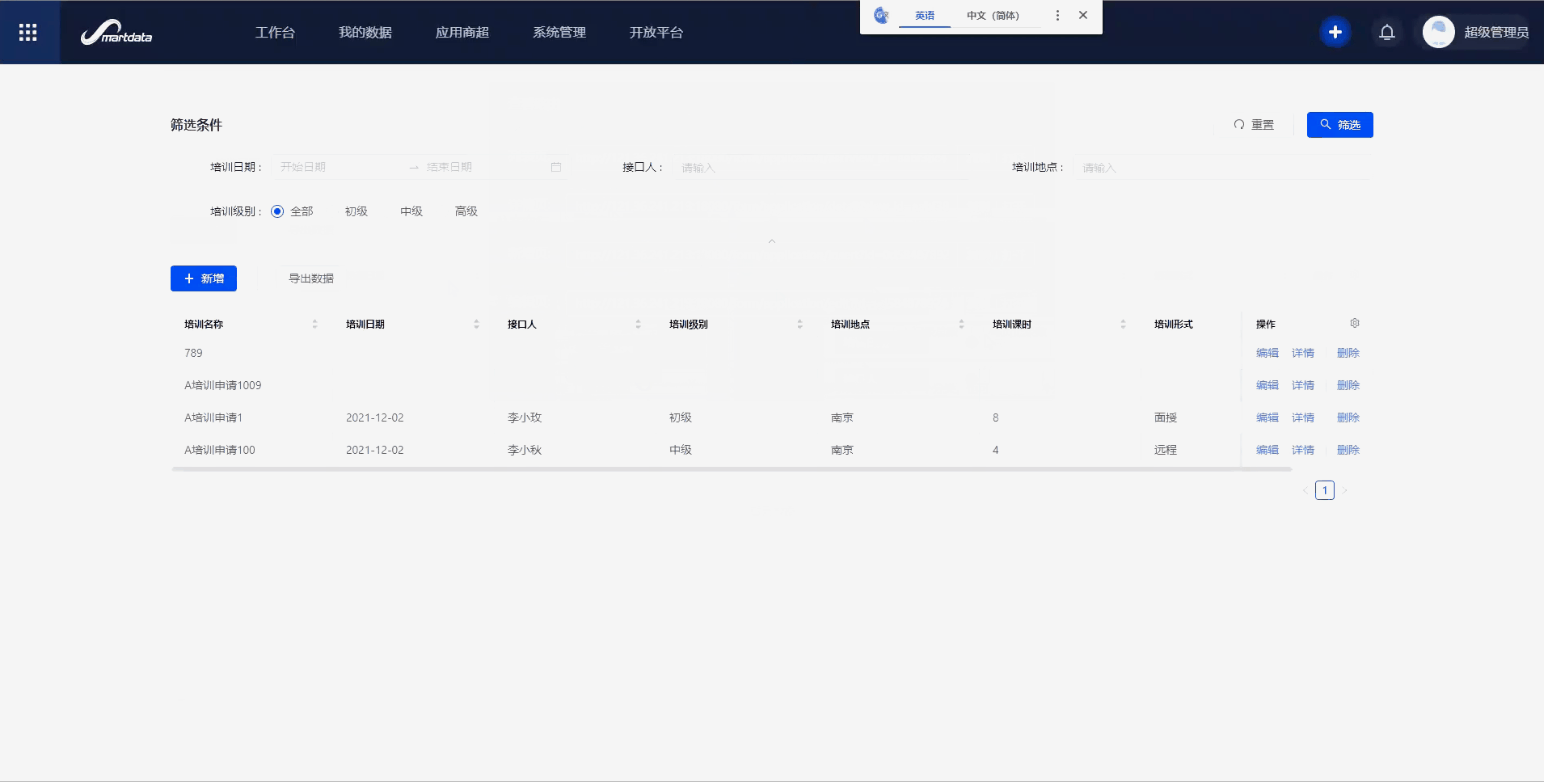
Step3. 视图设计
通过列表页展示培训申请的相关信息,可以自定义选择要展示的字段,比如申请人、申请日期等。也可以配置筛选条件,比如通过事件类型、事件名称进行筛选。
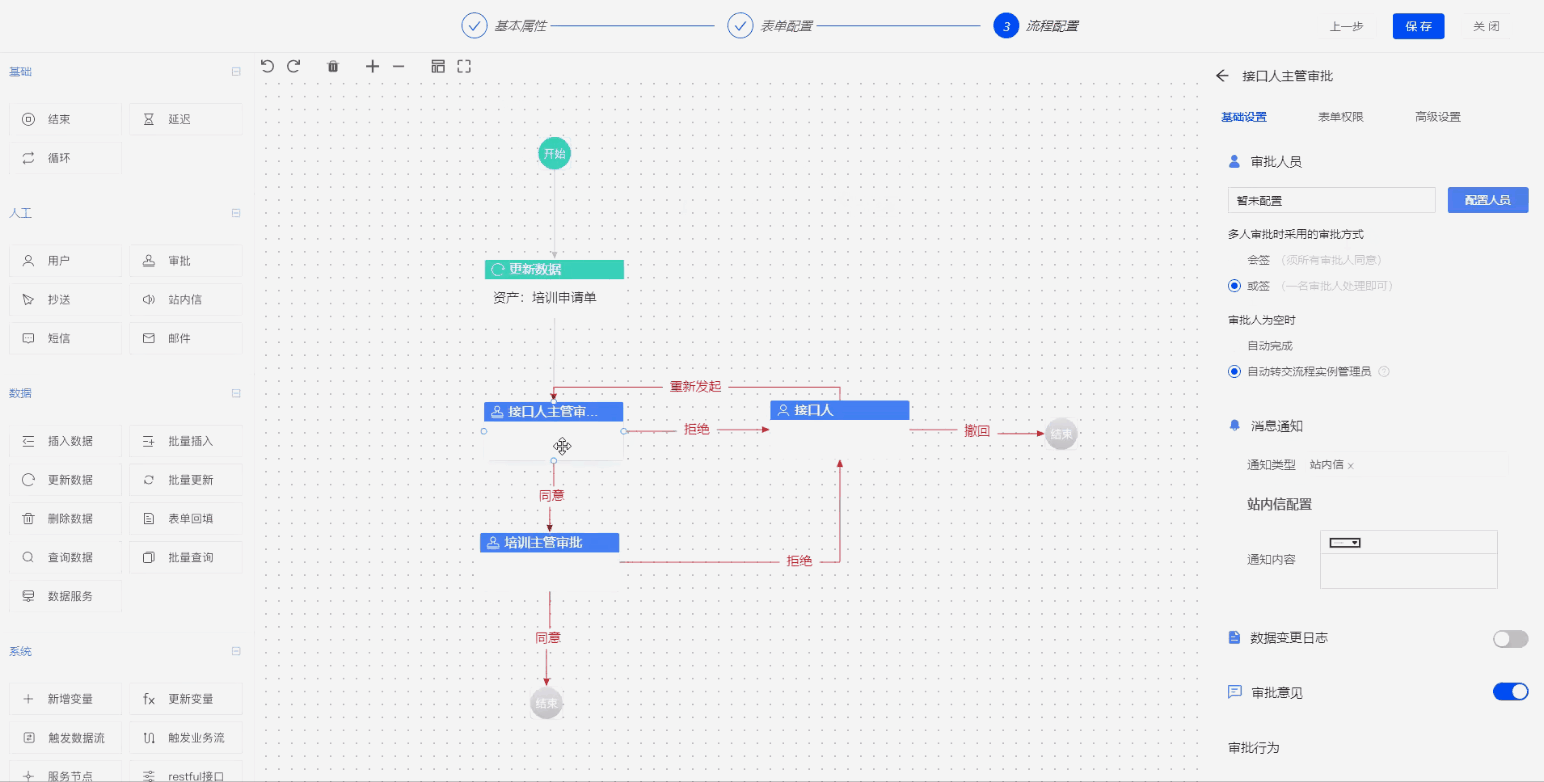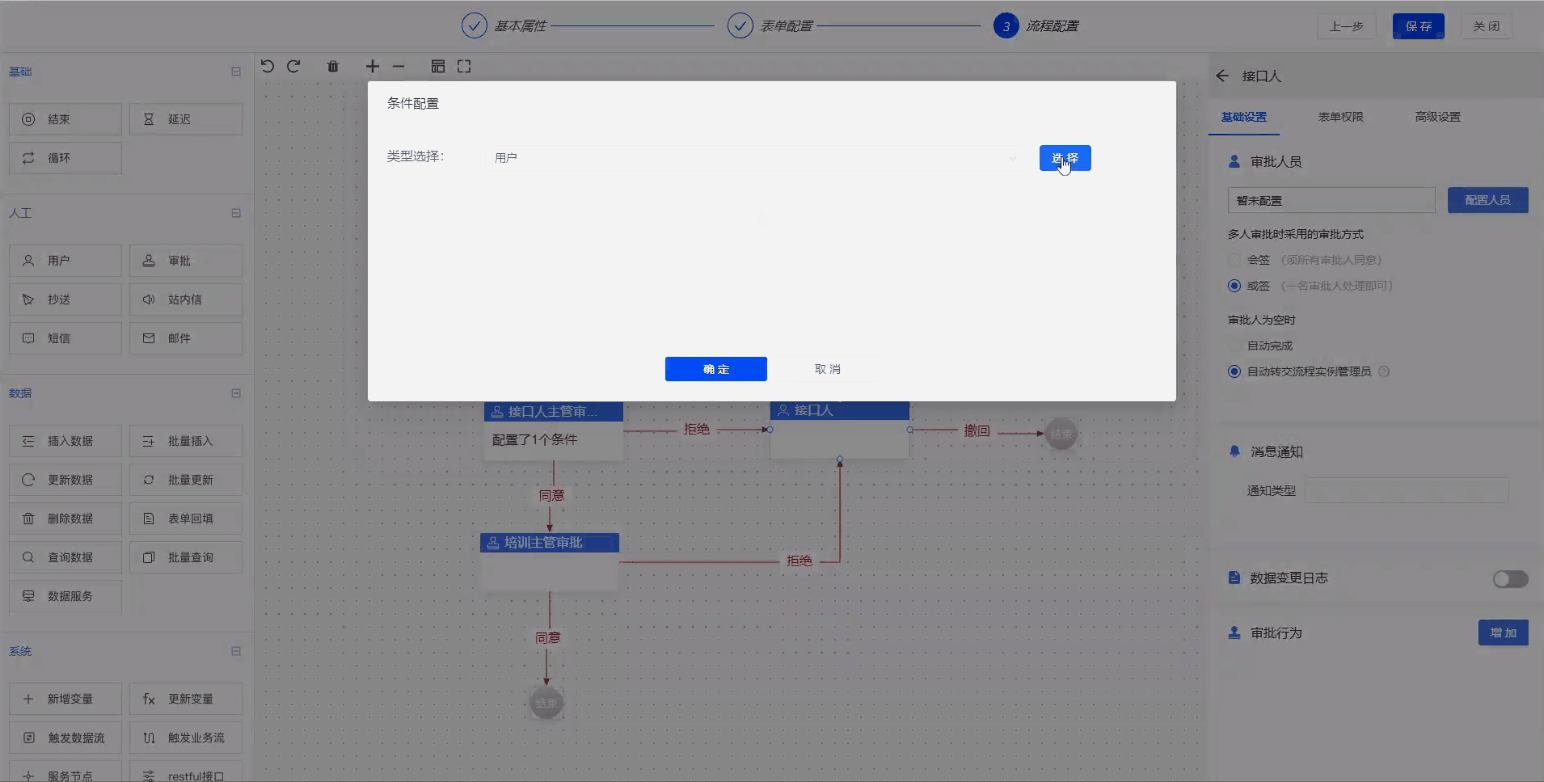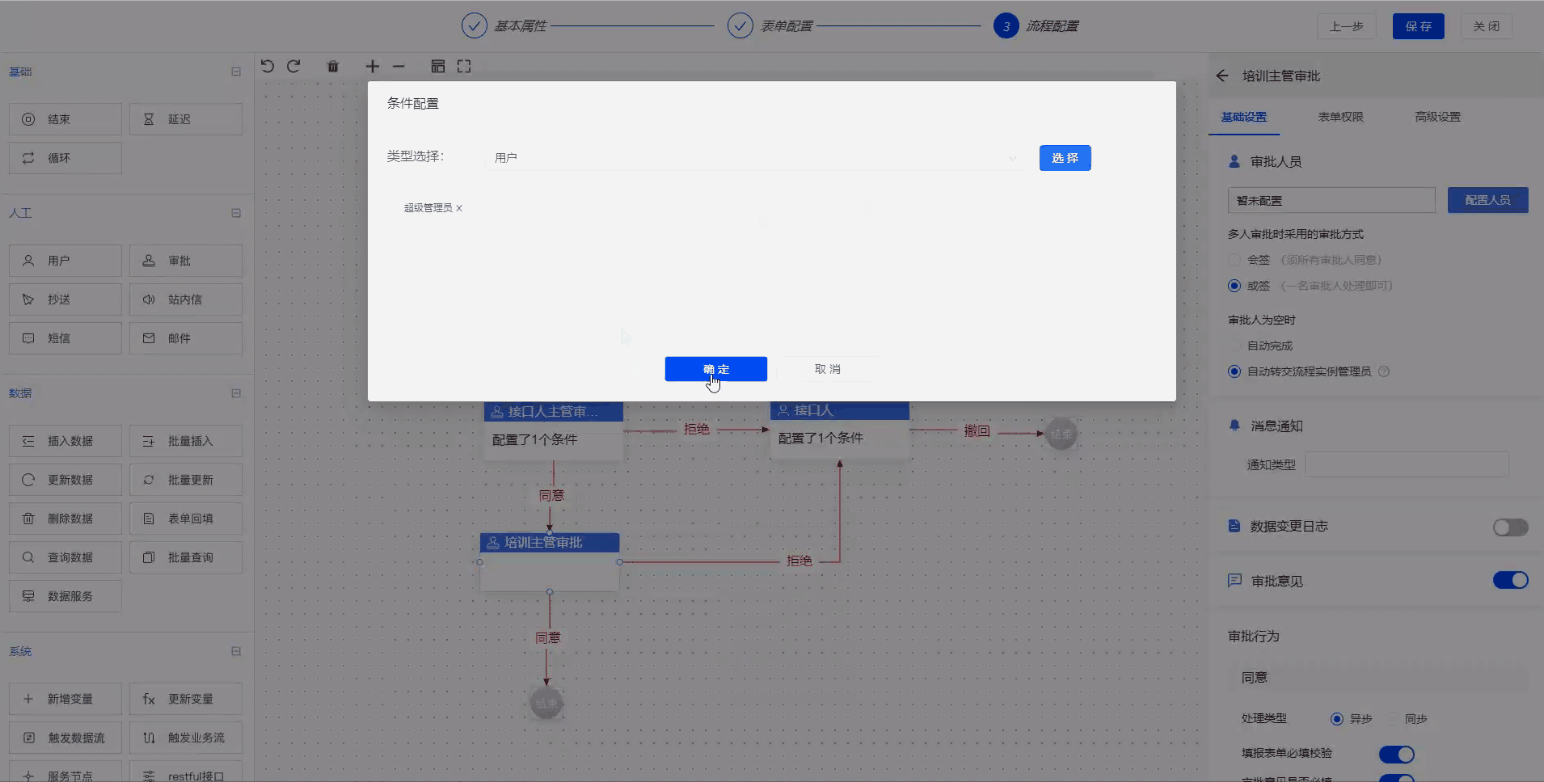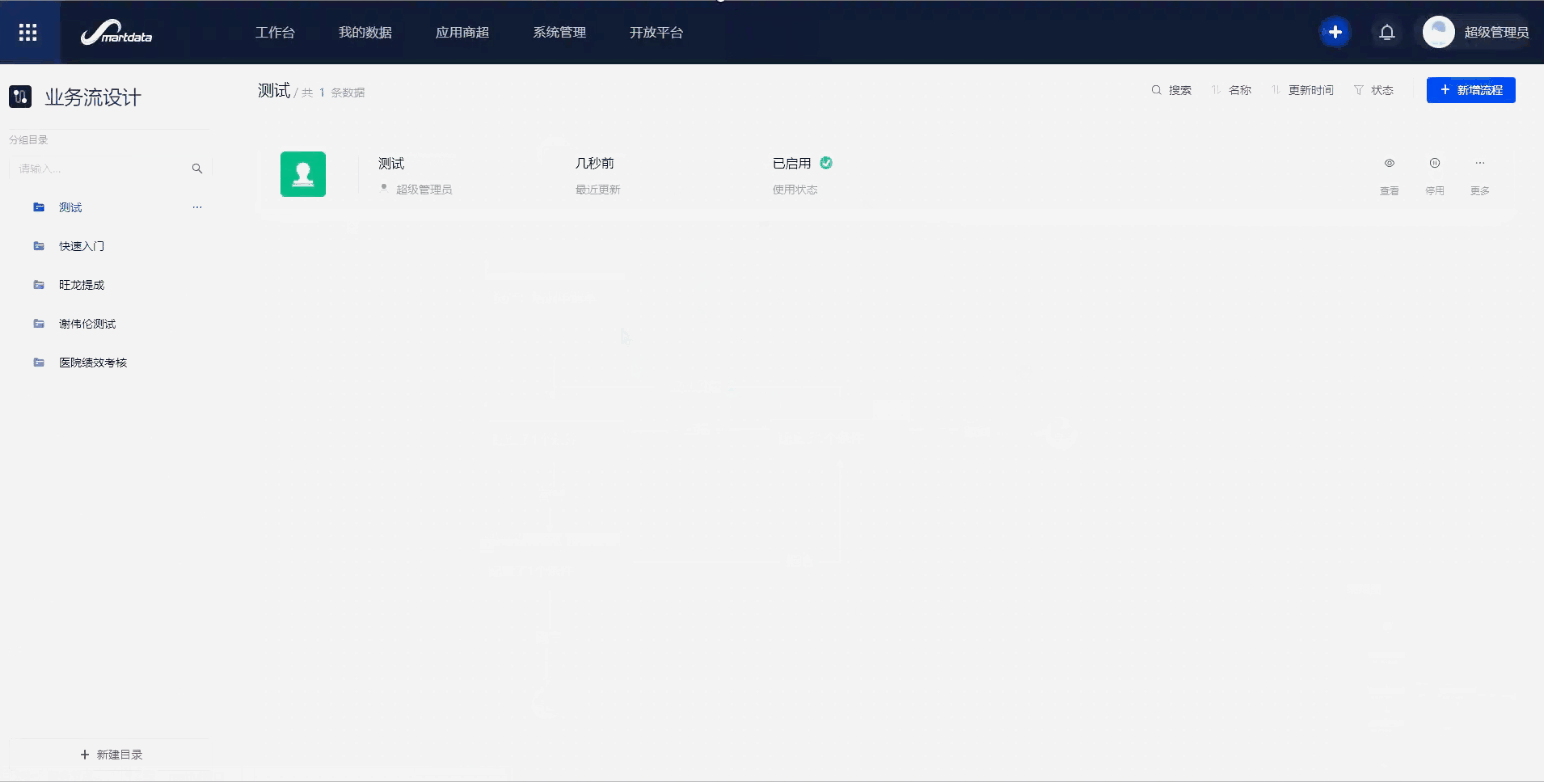
Step4. 审批流设计
首先创建每个用户的审批权限,比如A用户只能有提交权限、B用户有审批和提交的权限。然后进行表单绑定,将做好的填报设计导入进来,目的是当流程传到每个节点时,每个用户会看到不同的申请信息。最后通过拖拽的方式创建审批流程图,实现整个培训申请的业务流程。

Step5. 应用设计与发布
最后考虑整个培训申请系统的布局:比如有哪些菜单、每个菜单由什么元素组成。举个例子:培训申请这个菜单,展示的内容其实就是填报的内容,只需要在这个页面上进行导入,就可以实现这个效果。
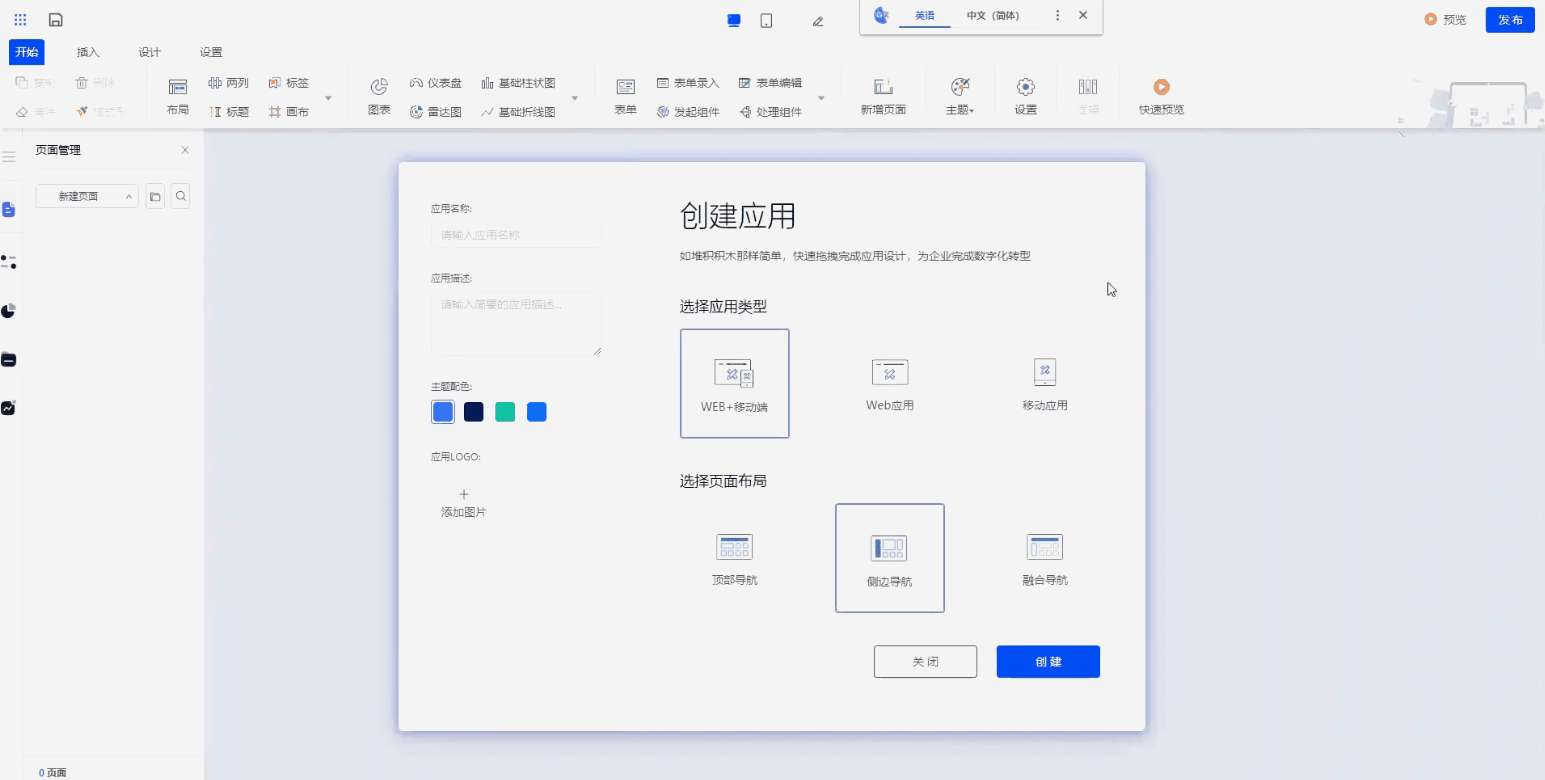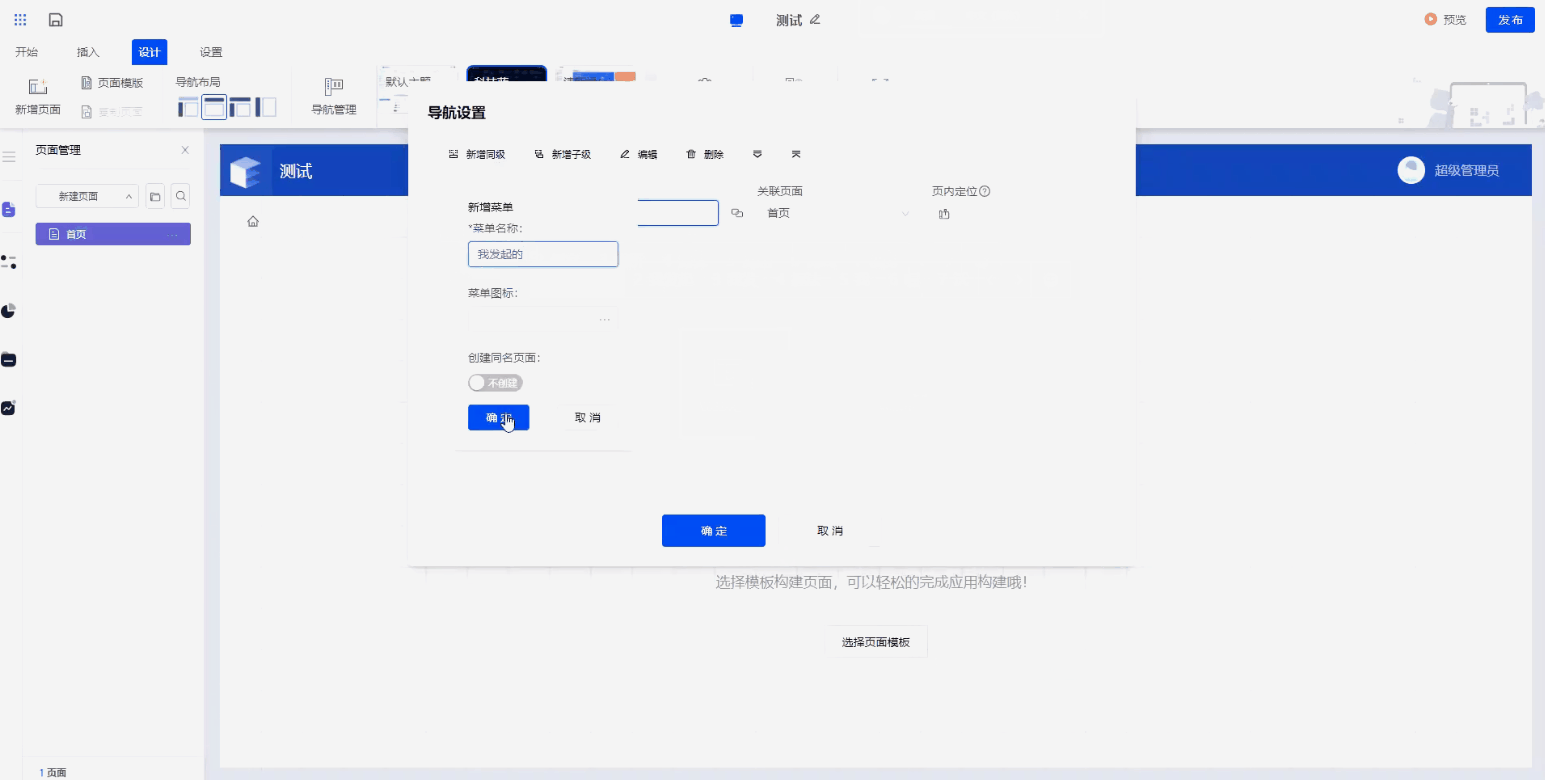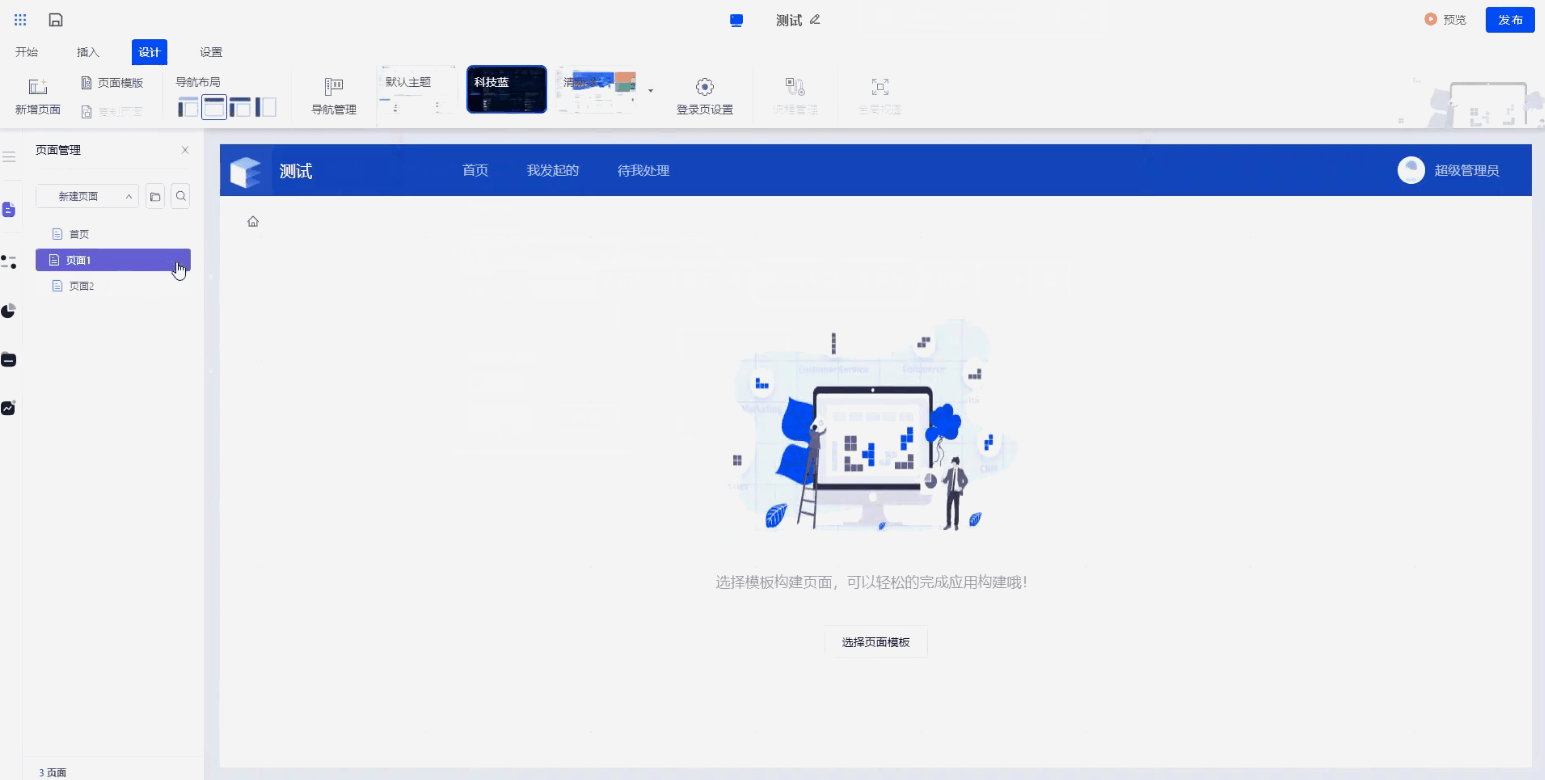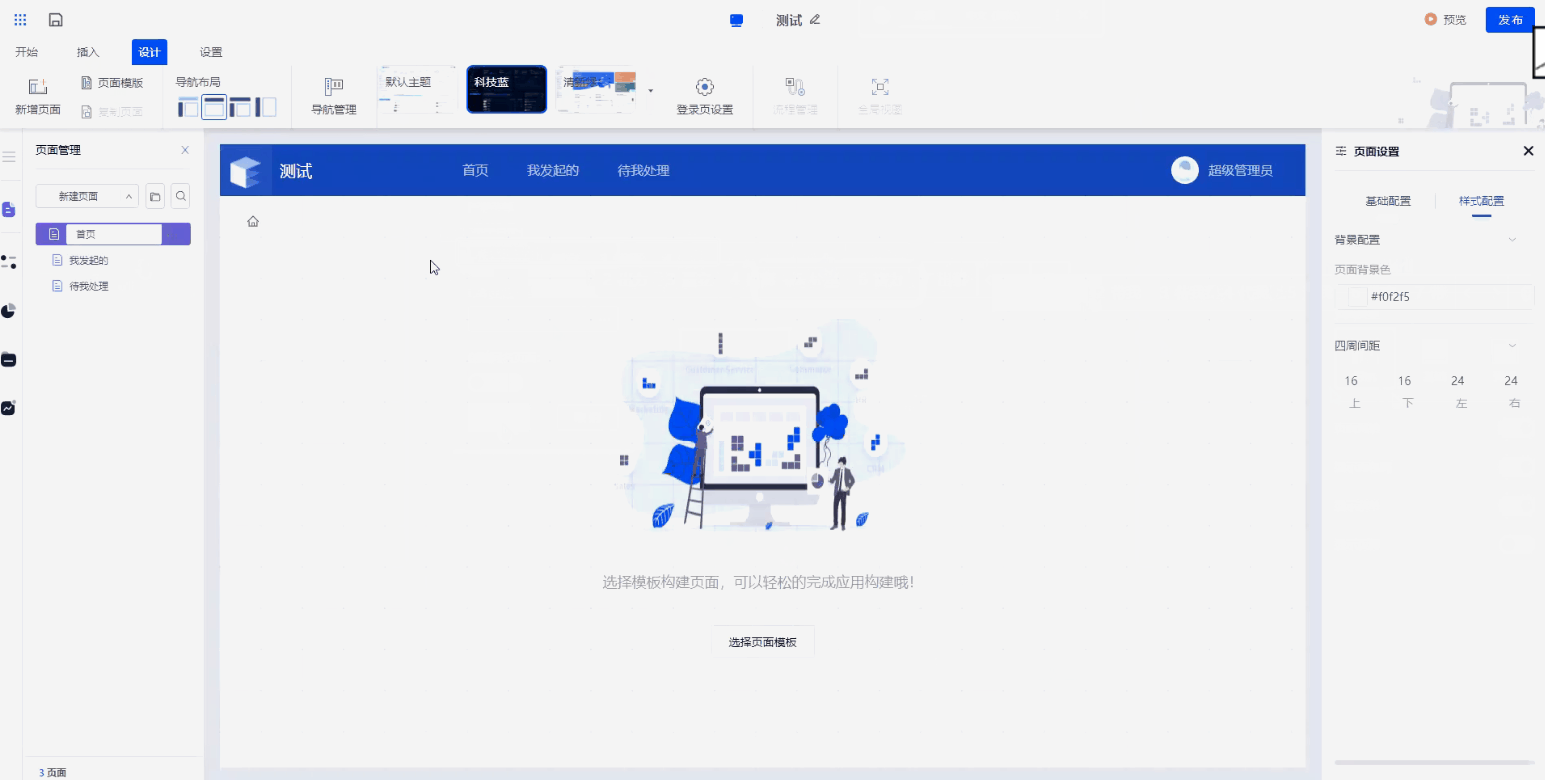
创建web应用
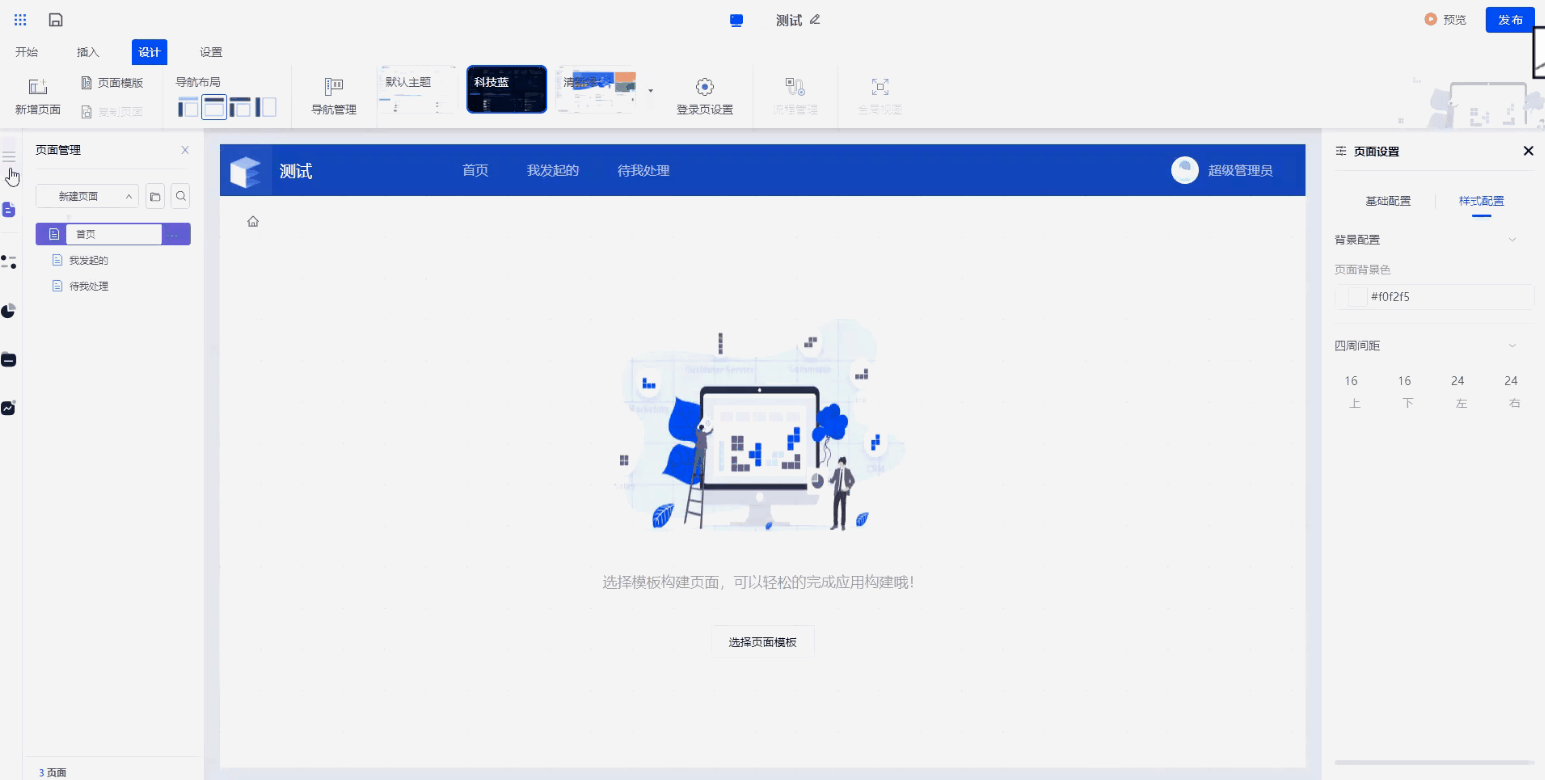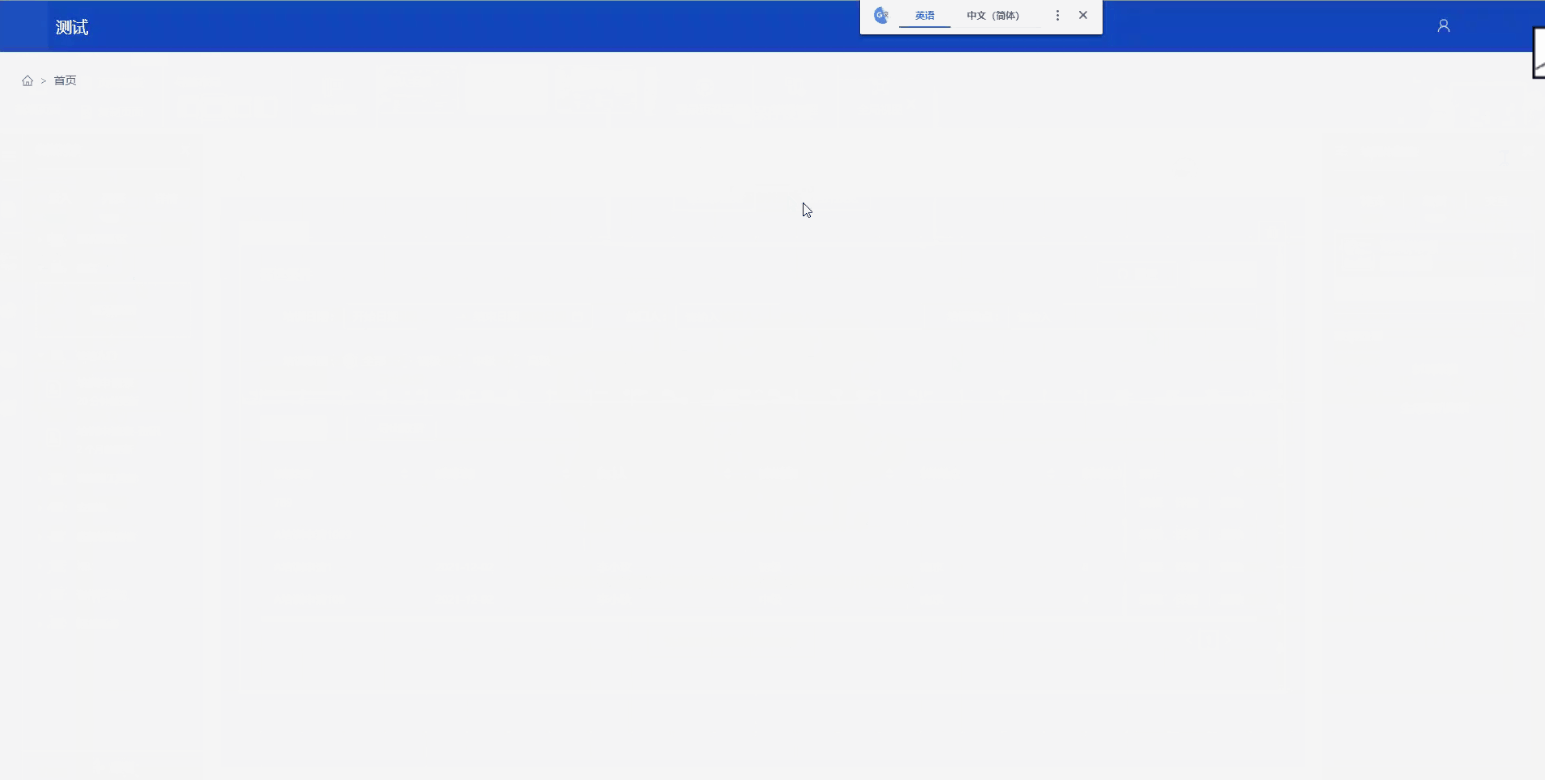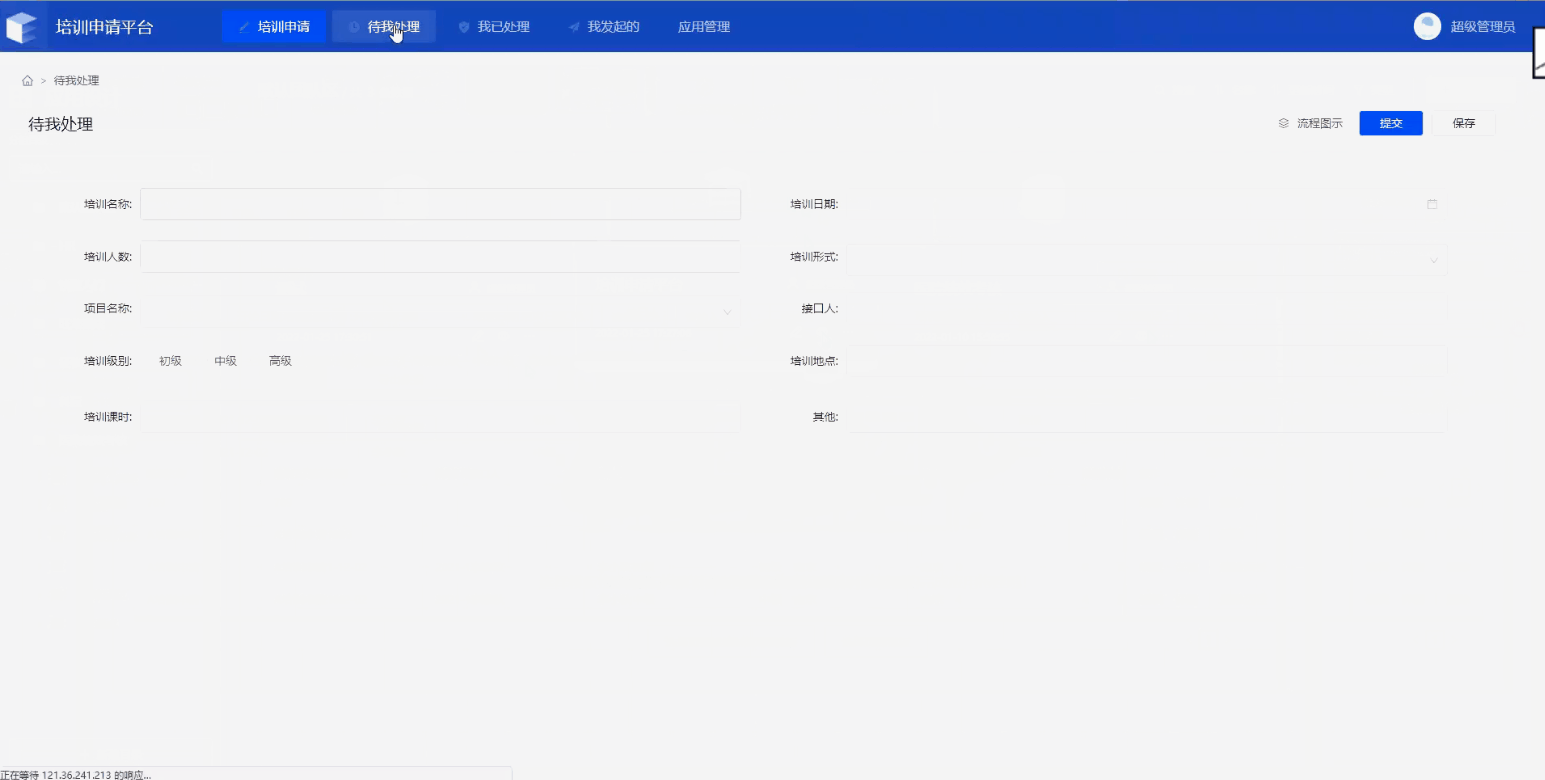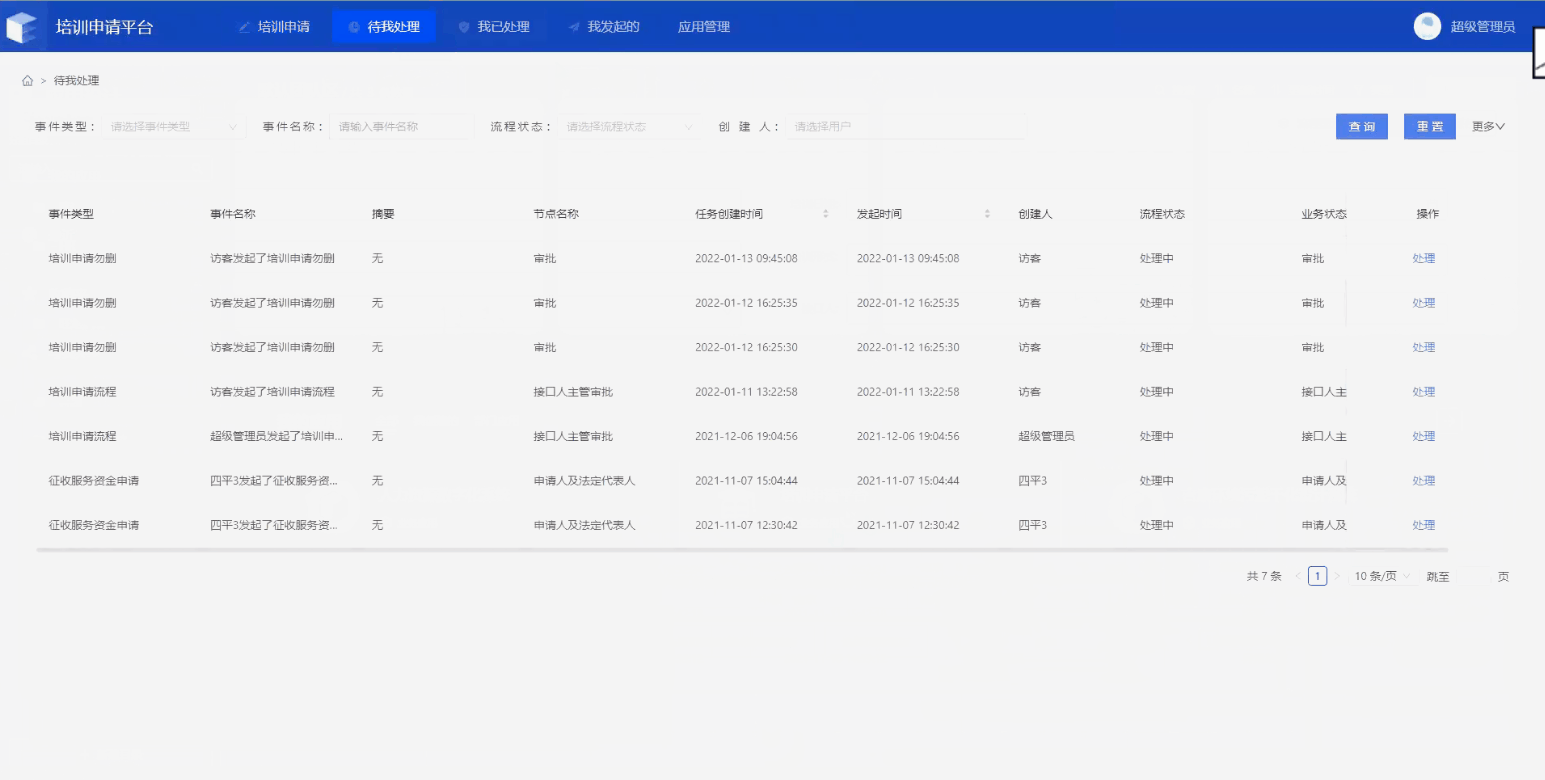
导入填报的内容
这次公开课群里昵称为“Selene”的同学基于自己对业务的理解,跟随讲师的讲解,对照课件在两小时内容成功配置了这套培训系统,表示非常有成就感,课后还联系我们炫了一下最后的配置成果👇
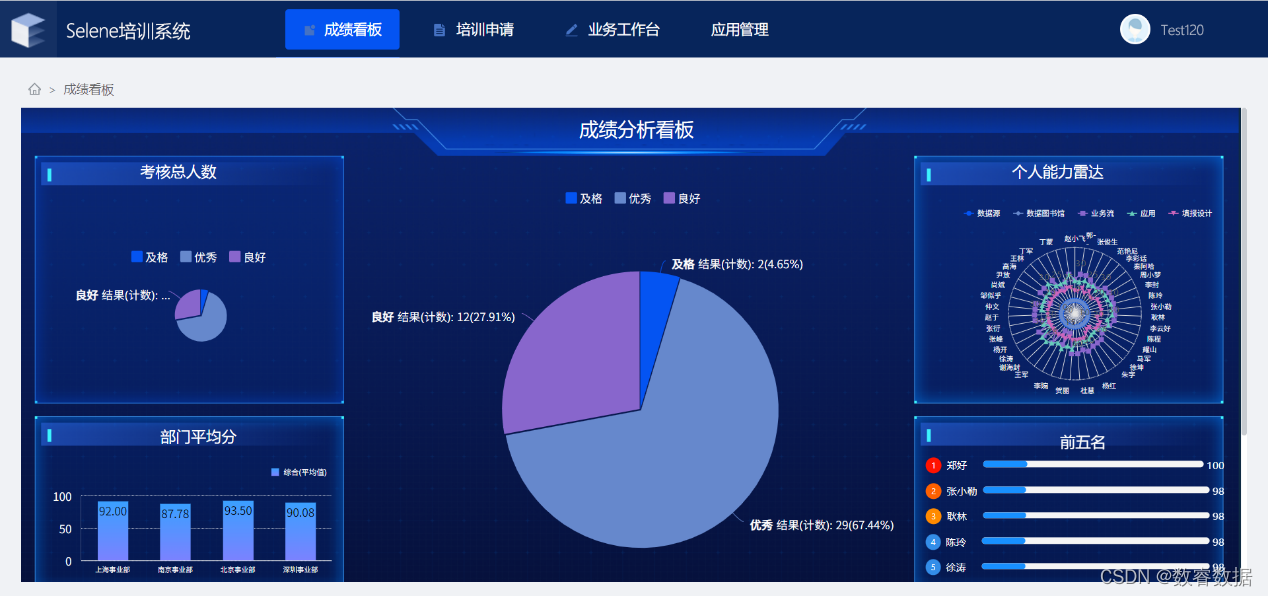
如果你错过了这场直播也没关系,联系我们也可以获取体验账号和培训课件图片
本质探究:极致的无代码=把复杂留给自己
只要开了“代码”的口子,面对复杂场景时代码会越积越多,势必会弱化组件能力,所以数睿数据追求的是极致的无代码,将技术与应用分离,让更多人参与应用设计和装配。
当然也并不是说我们不需要代码,Smartdata平台本身是代码开发的,组件也需代码开发。追求极致的无代码其实也在倒逼产品提升能力,把复杂留给自己,把简单带给用户。
Smartdata的“无代码”主要体现在两个方面,一是软件装配的无码化,二是最终目标软件形态的无码化,也就是我们生成的软件不是一堆的代码,而是一个可执行的数据包。
理论上所有软件都能通过Smartdata进行配置,但是涉及行业复杂的领域模型或者配置复杂度与写代码相当的场景我们还是不建议用无代码配置。
Smartdata无代码软件平台通过模块化、无码化、复用化,发挥更多人的创造性,为快速变化发展的企业级业务提供兼具灵活性和敏捷性的个性化支撑系统,可能是实现IT敏捷和打造韧性企业的最优解。
这篇关于2小时,5大步骤,100+人用数睿数据无代码搭建了一套培训申请系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








