本文主要是介绍百度慧眼人口位置数据使用说明,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简要介绍百度慧眼人口位置数据获取后,数据的简要介绍以及常用处理方法。
一、数据简介
(一)数据基本原理(个人猜想)
以下纯属个人猜想,官方并未给出完整接口说明。
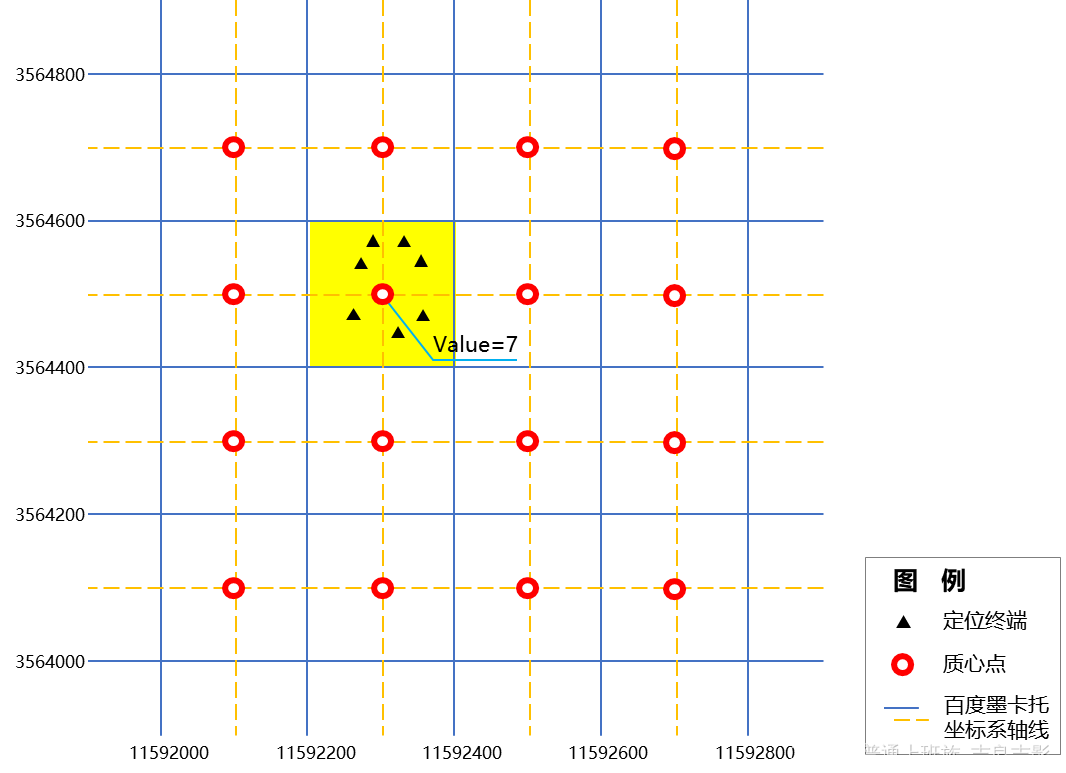
百度慧眼人口位置数据(以下简称“慧眼数据”)主要数据来源于对调用百度地图定位SDK终端定位数据的统计值。首先,百度地图按照百度墨卡托坐标系(bdmc09)将全国划分成200*200的渔网(如下图蓝色实线所示),对某时段内(平台内置为1个小时)调用过定位SDK的终端数量进行统计。如下图黄色区域内,假定该时段内共有7个终端定位数据,那么将该区域的热力值(value)赋值给质心点。
(二)字段说明
原始数据样式如下:
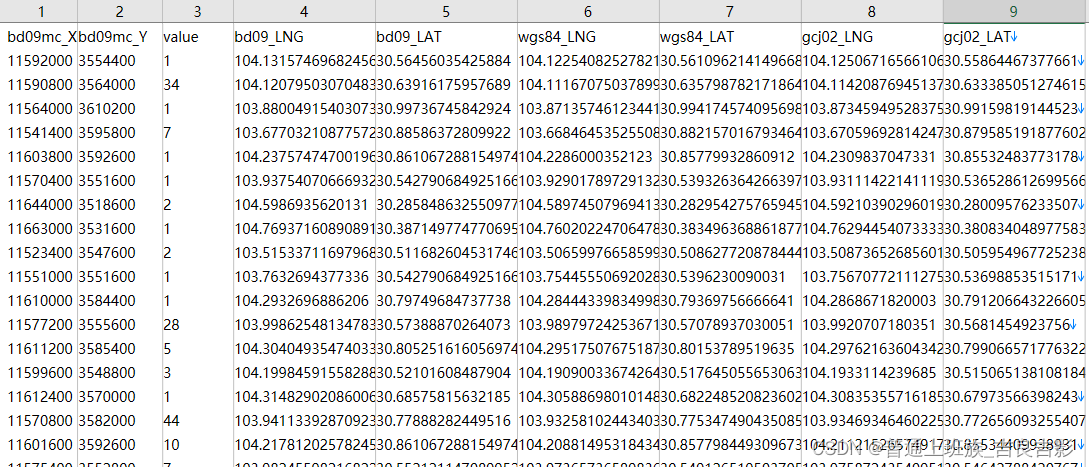
bd09mc_X,bd09mc_Y:百度墨卡托坐标系(为投影坐标系)横纵轴坐标,以上面黄色区域质心为例,对应的坐标为“11592300,3564500”;
value:该时段内质心点对应区域内调用定位的终端数统计数,单位:次;
bd09_LNG,bd09_LAT:百度坐标系(为地理坐标系)横纵轴坐标;
wgs84_LNG,wgs84_LAT:WGS 1984坐标系(为地理坐标系,EPSG:4326)横纵轴坐标;
gcj02_LNG,gcj02_LAT: GCJ-02坐标系(也称:火星坐标系,为地理坐标系)横纵轴坐标。
二、常用操作
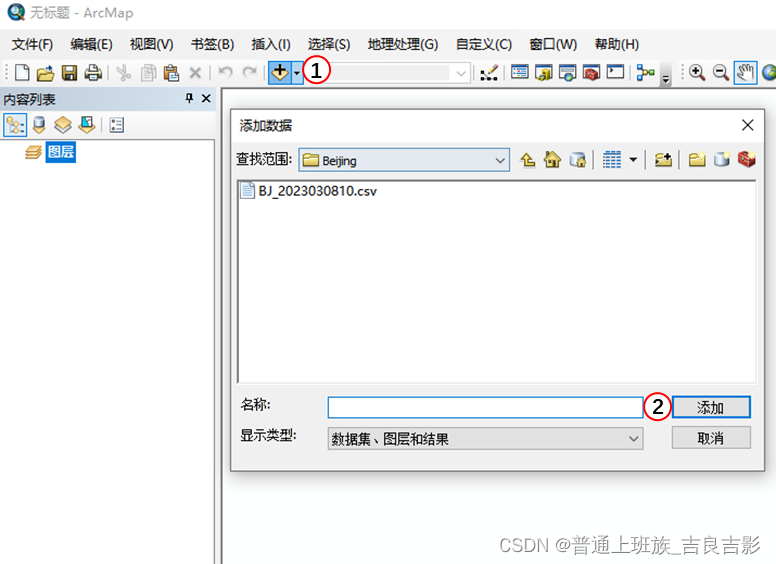
(一)数据导入
以arcgis 10.7操作为例:
添加数据
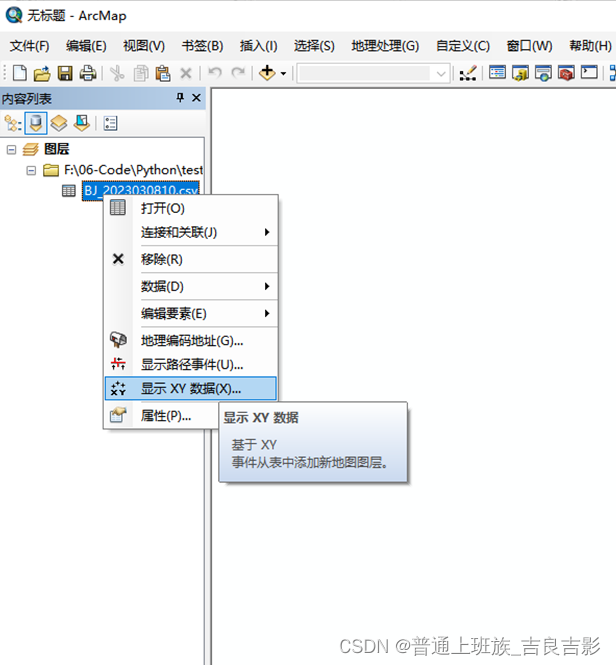
显示XY数据
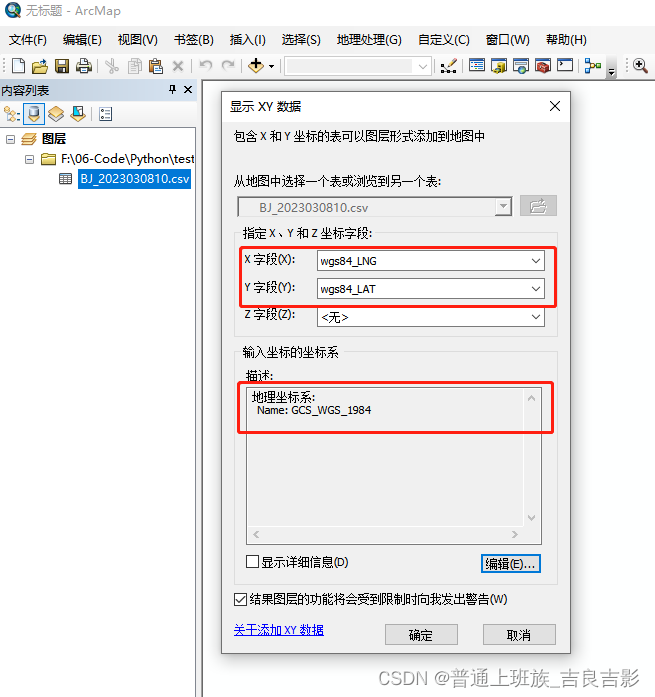
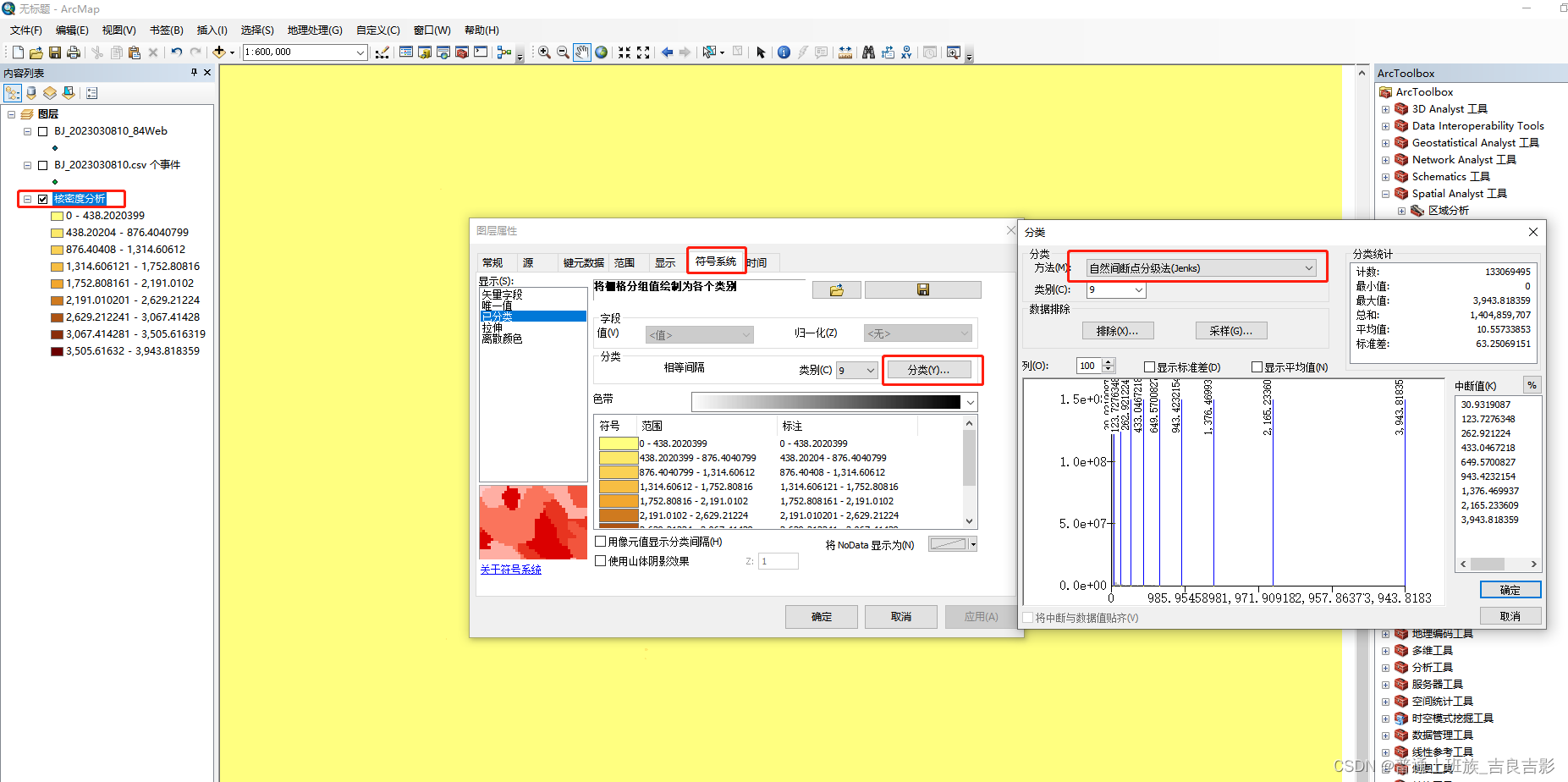
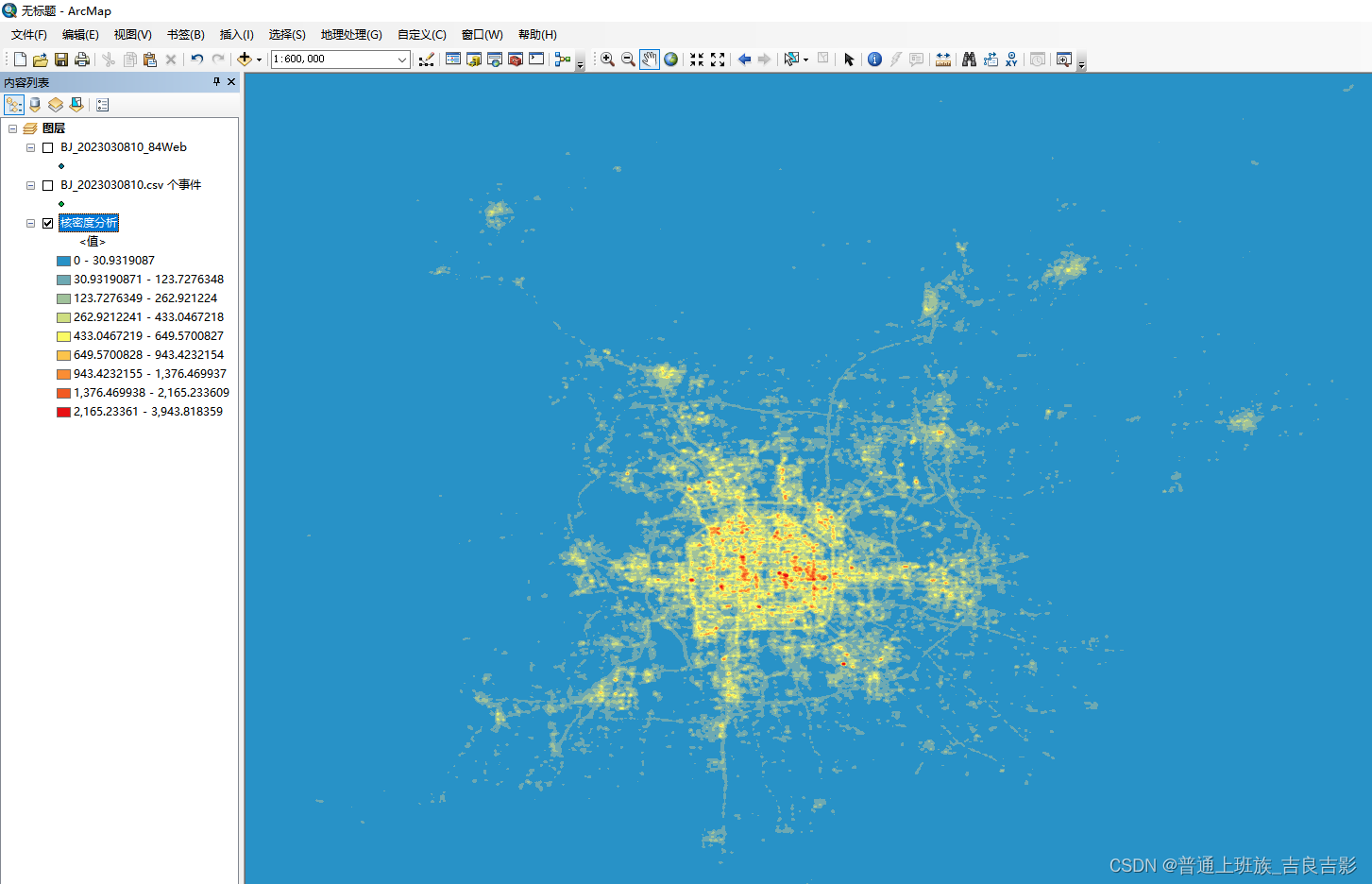
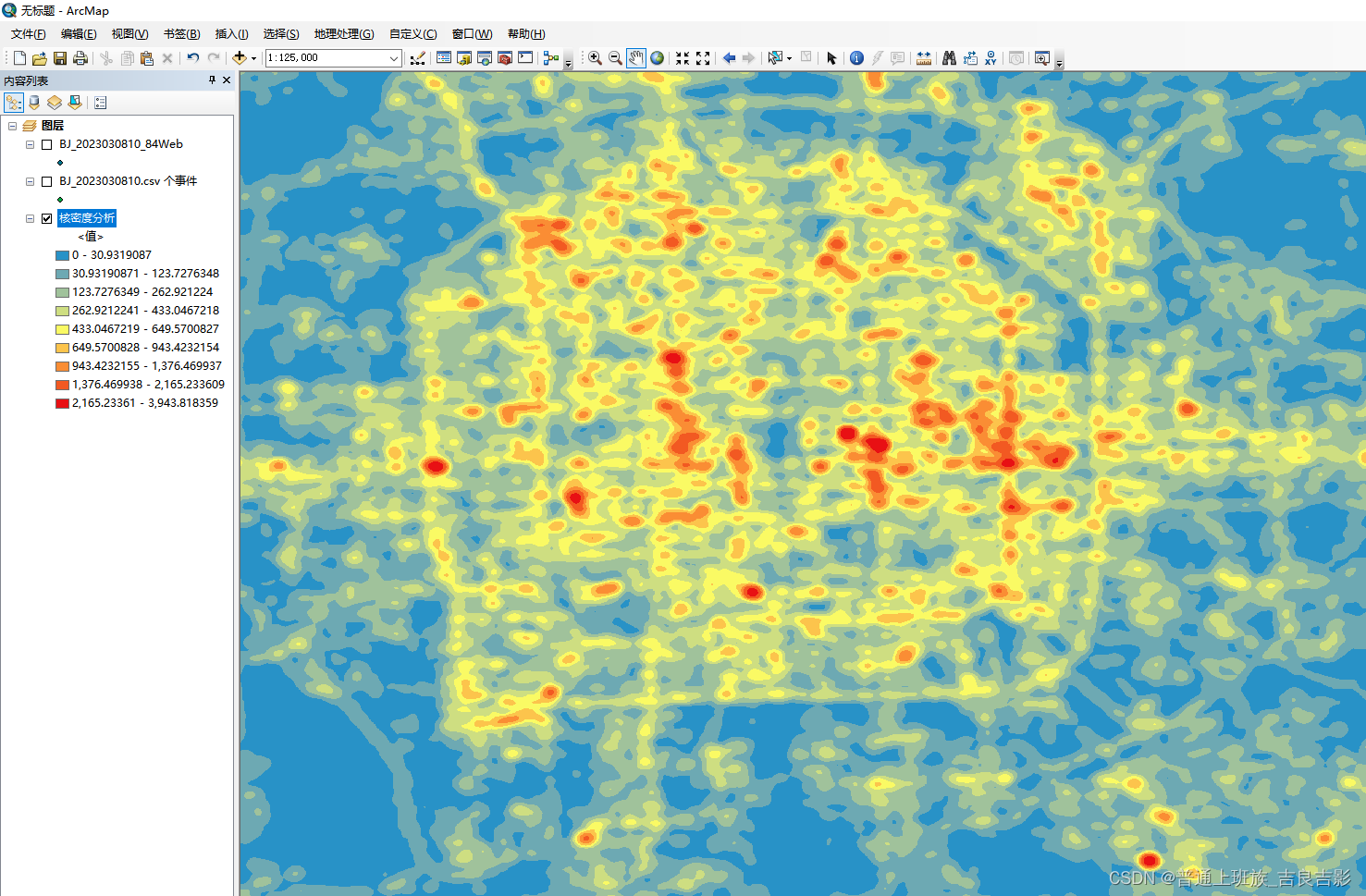
(二) 核密度分析
1.转投影坐标系
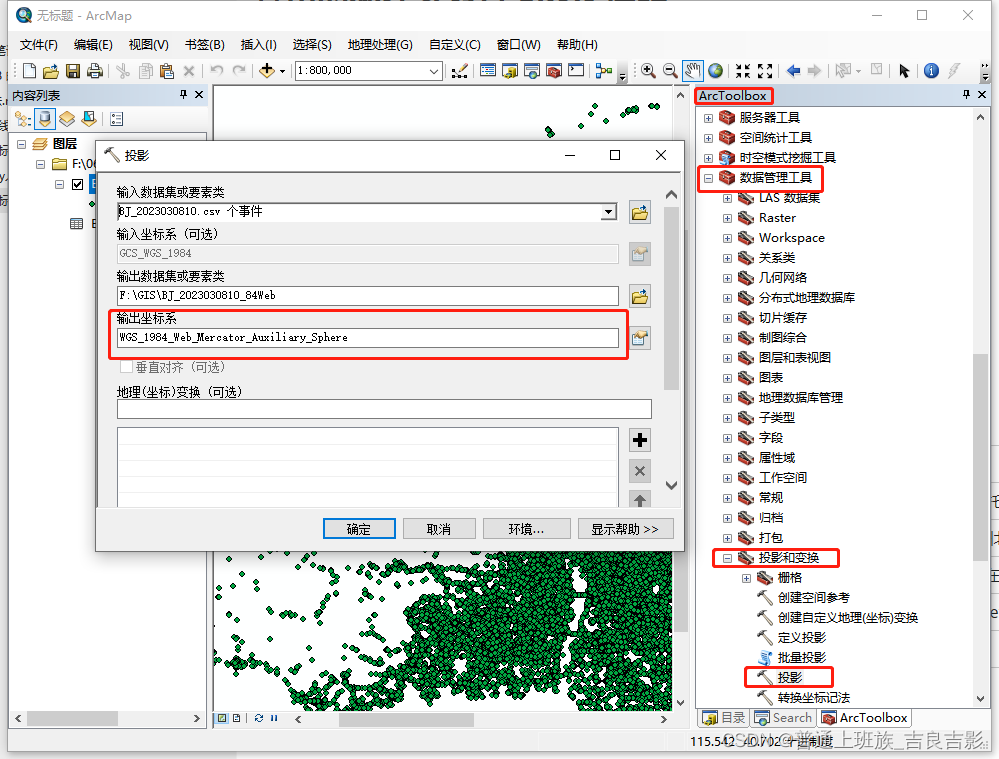
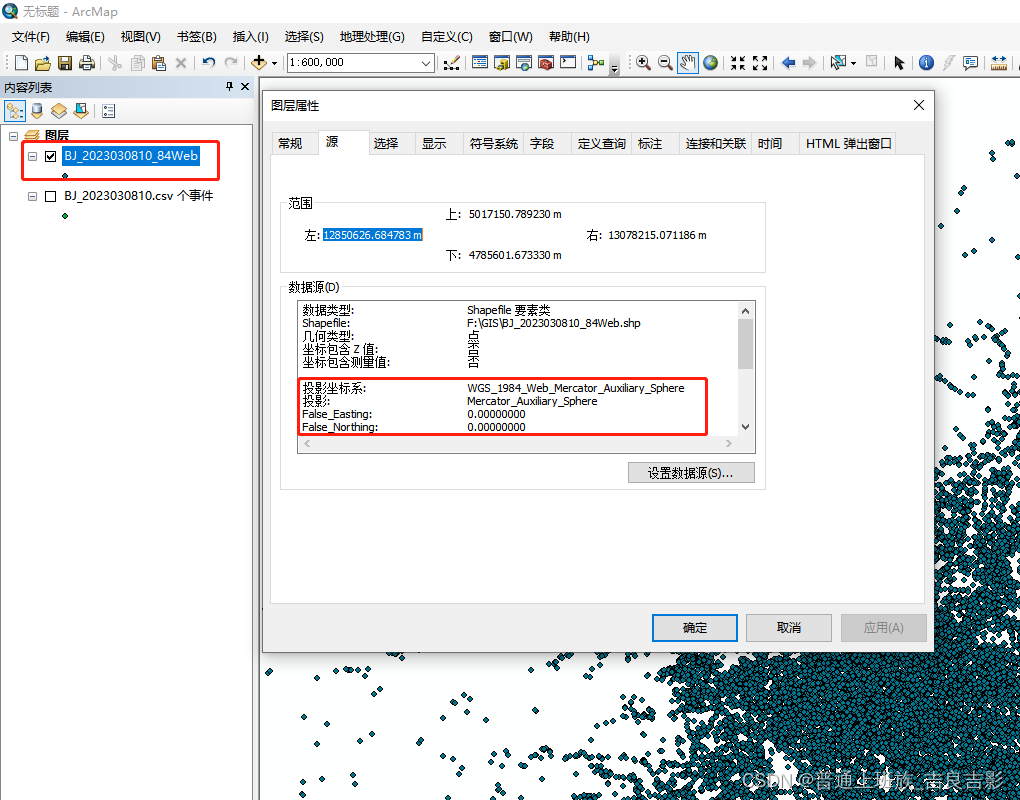
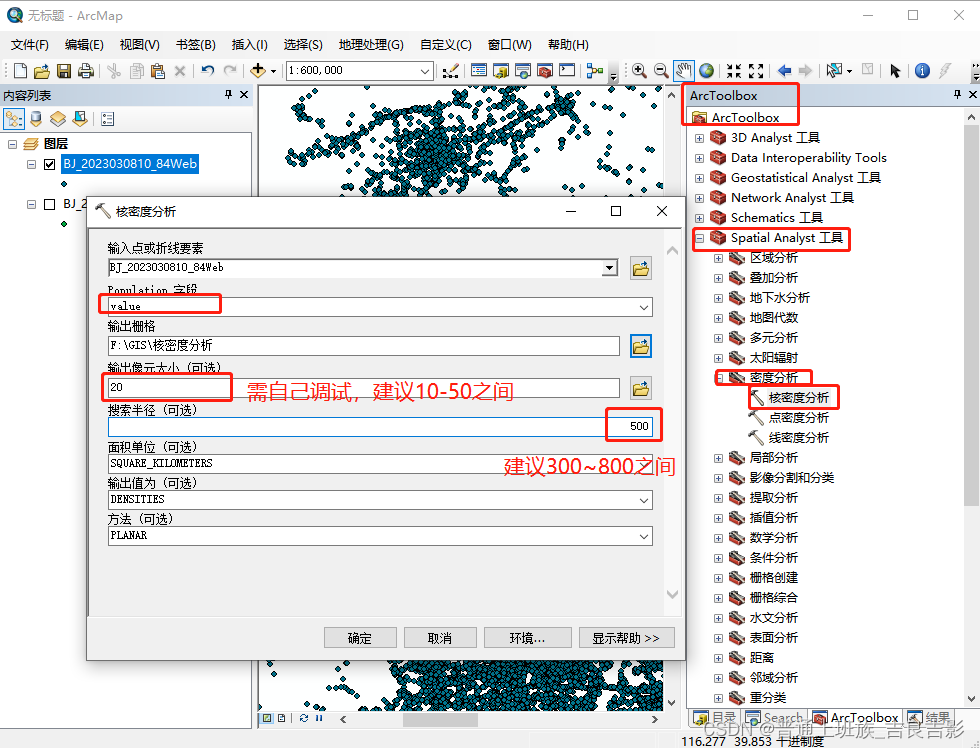
2.核密度分析
3.样式调节
建议先用“自然间段法”调节出粗分类的初步阈值,结合自己研究需要再来自定义细分阈值。
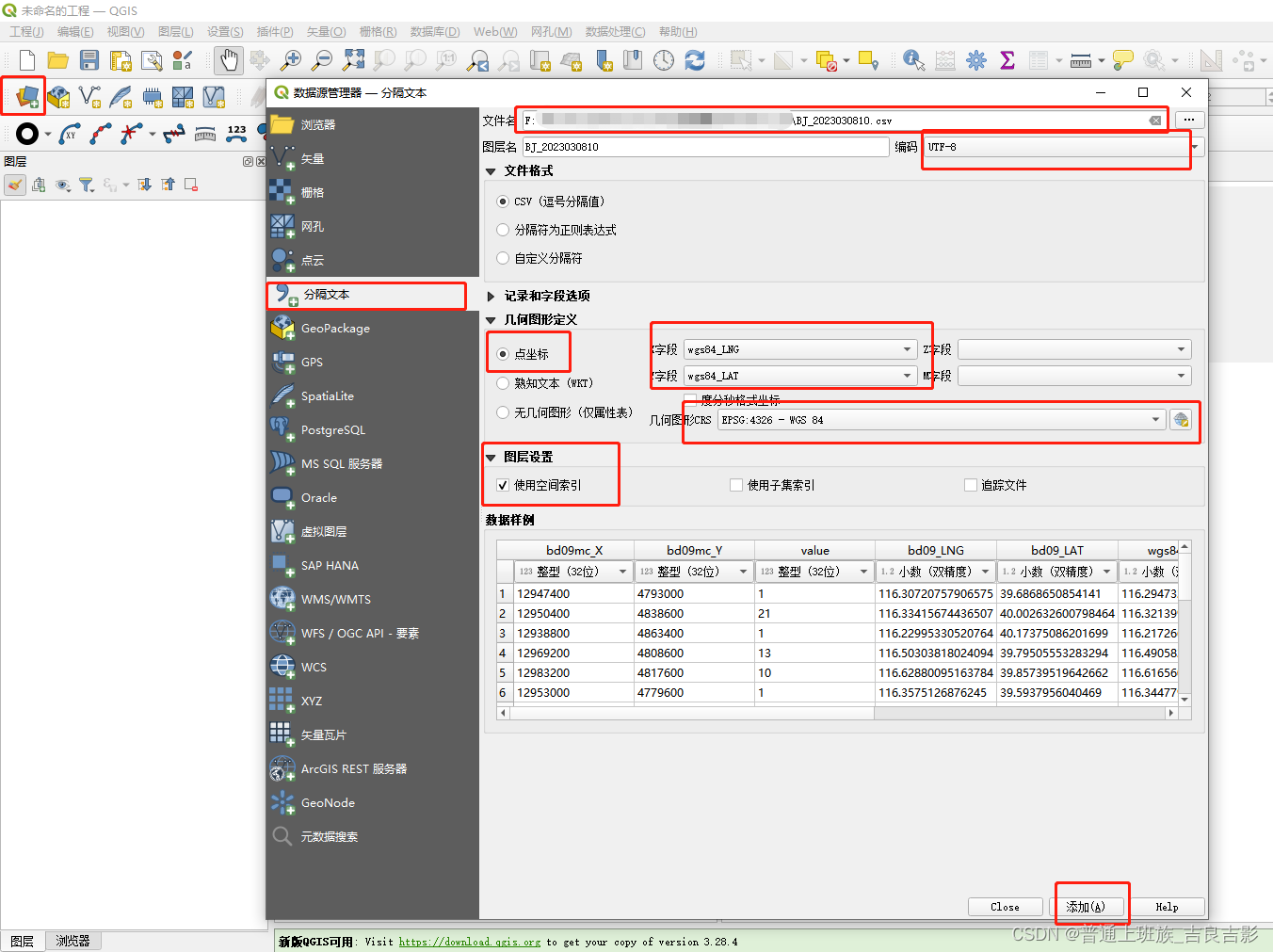
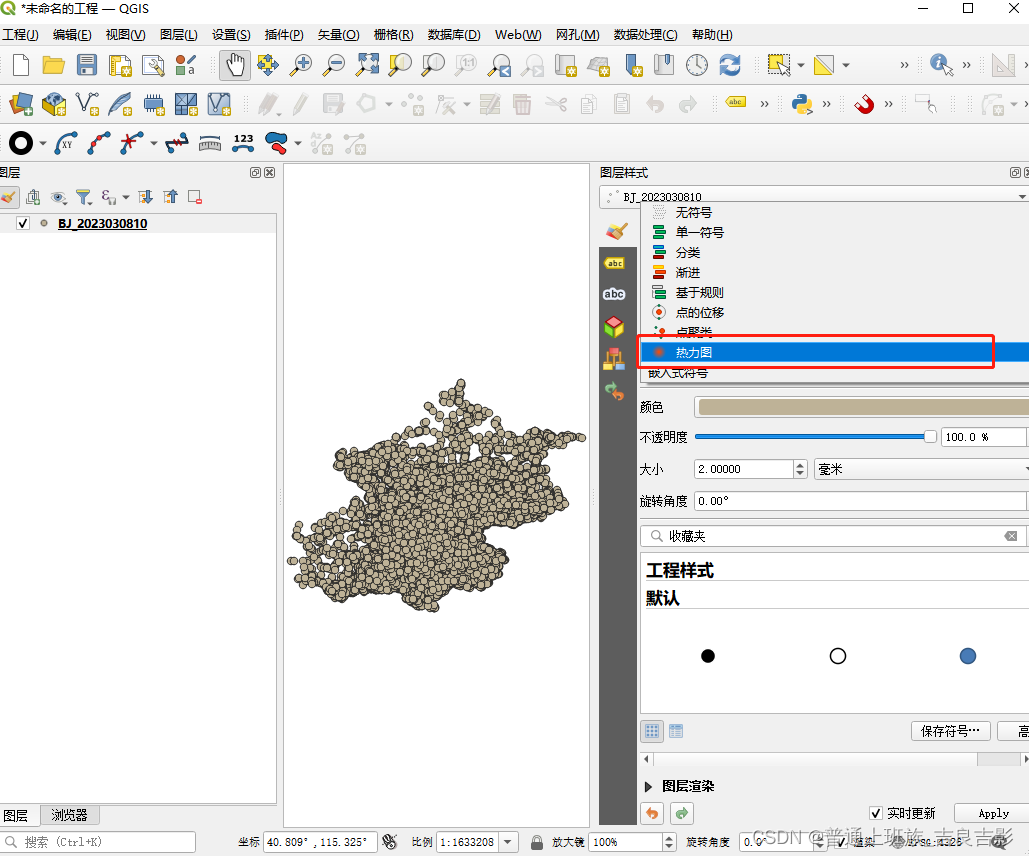
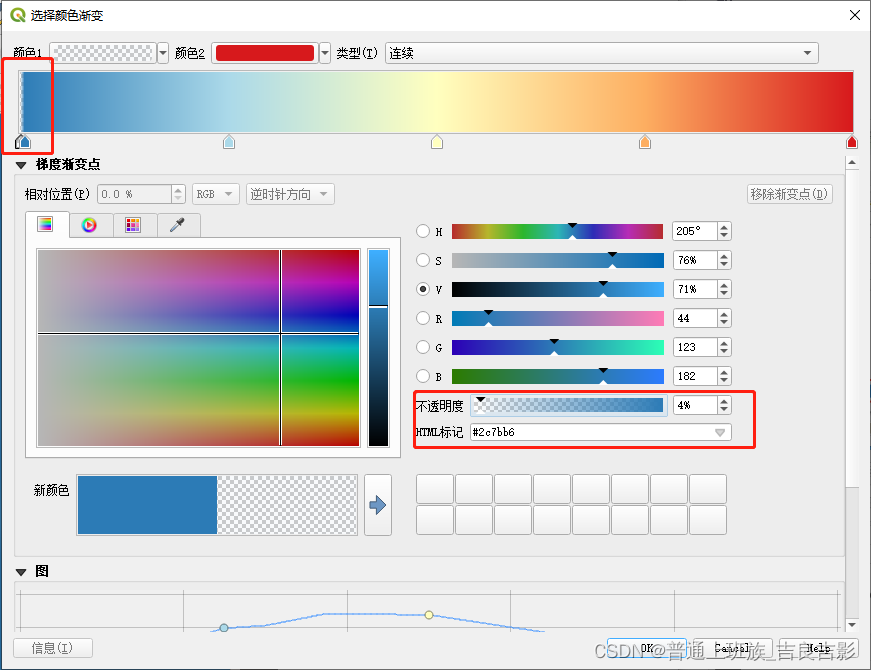
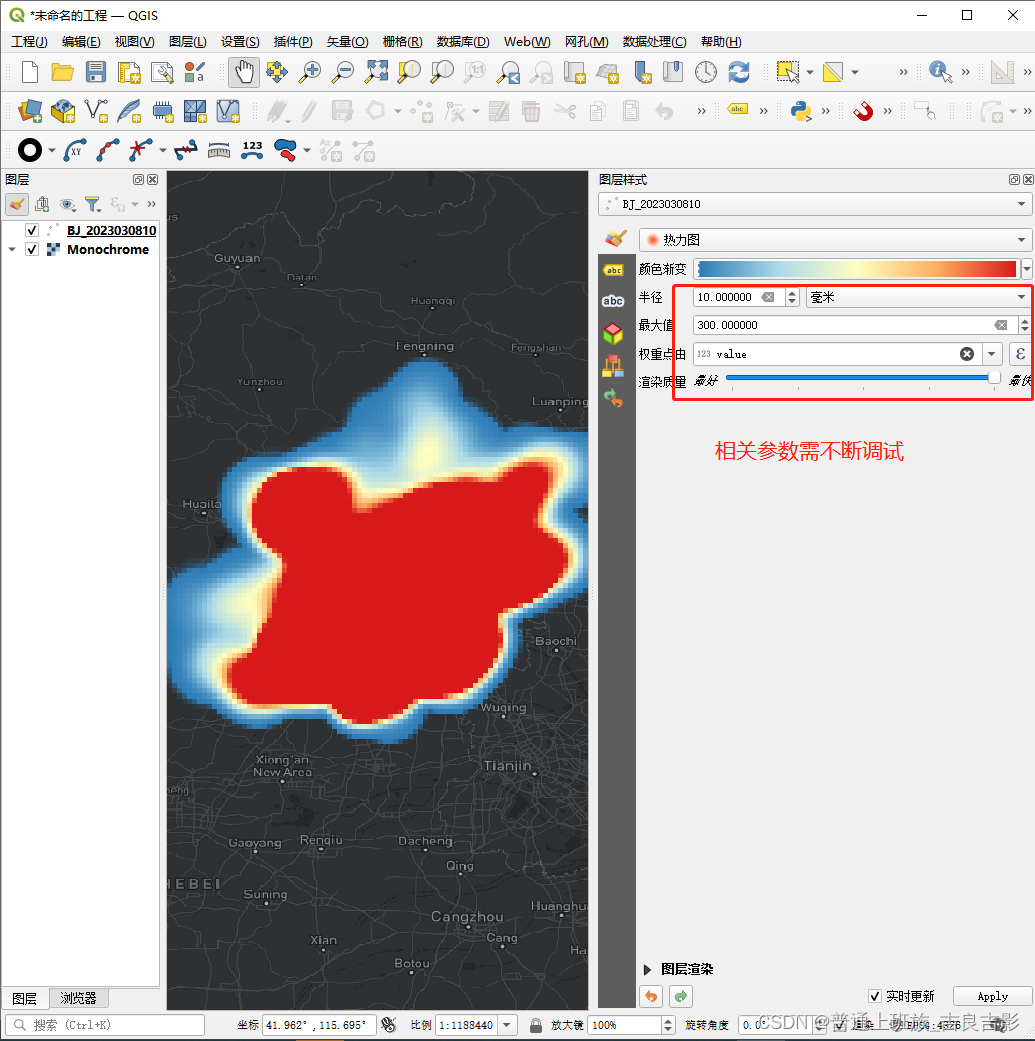
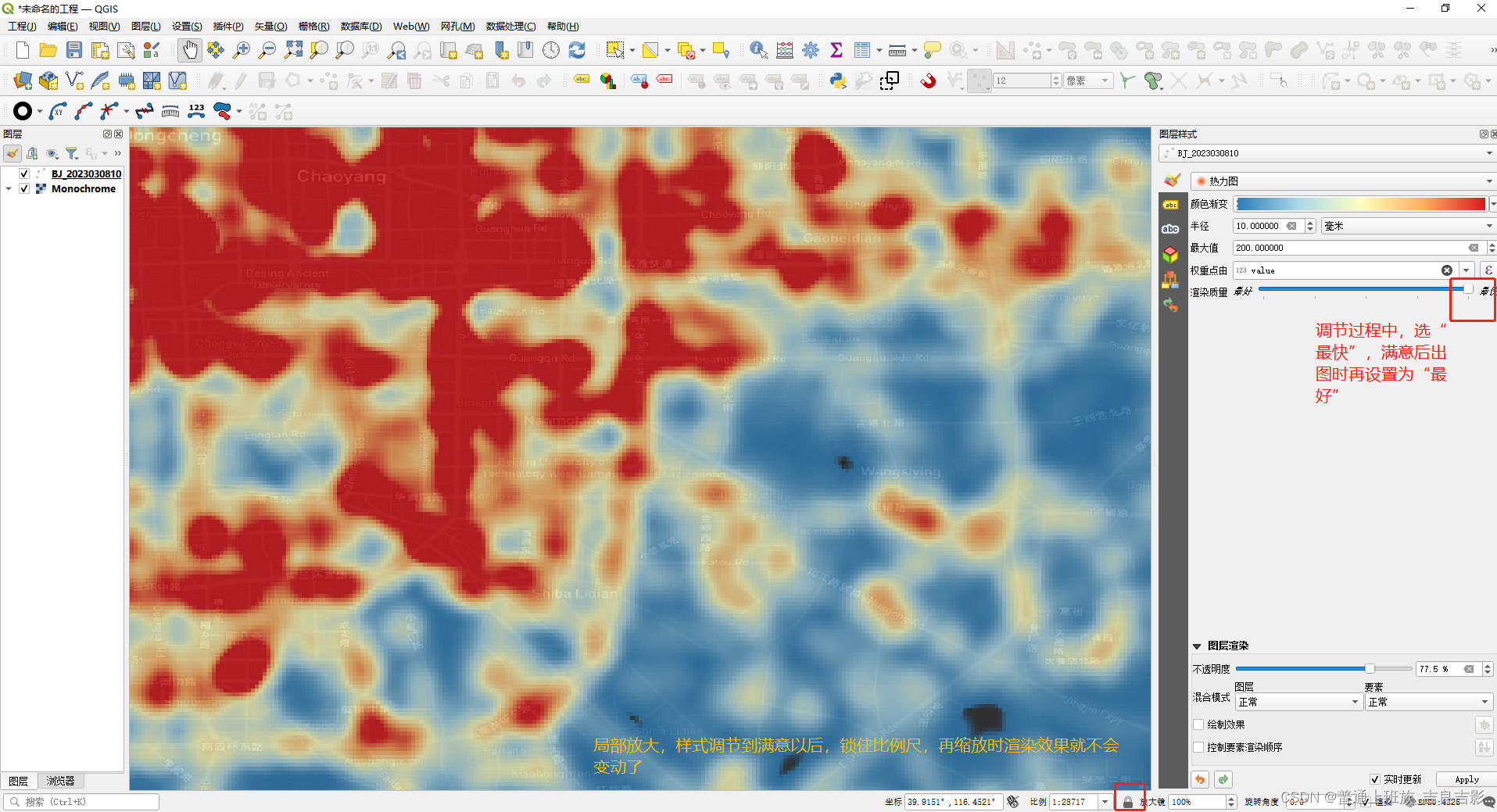
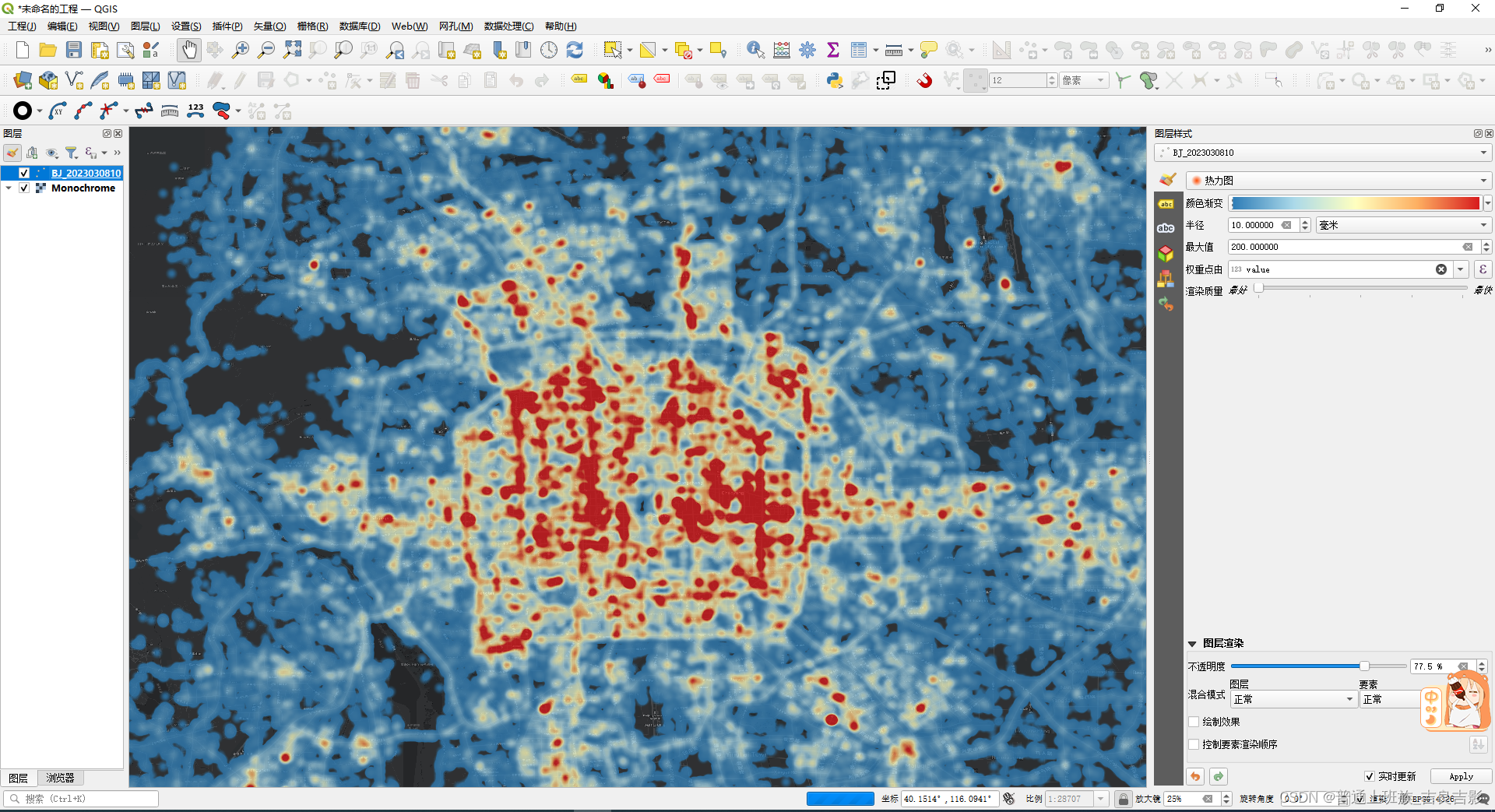
(三)热力图
arcgis不支持热力图功能,传统gis类工具中arcgis pro 和QGIS支持,下面以qgis 3.28.2为例:
qgis添加底图,自行百度可以解决
这篇关于百度慧眼人口位置数据使用说明的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







