本文主要是介绍cyberrt component 实现分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在自动驾驶系统中,通信是很重要的一个方面。传感器(摄像头,激光雷达,毫米波雷达等)发出来的数据要在多个模块之间(感知,规划,预测,控制)进行流转处理。数据在模块之间的流转即通信,不管是进程内通信,还是一台机器内的多个进程间的通信,还是跨机器的通信。
在通信模型中有两种典型的方式:轮询和中断(事件)。
(1)轮询
轮询,即线程周期性查看数据是不是到来,如果有数据则进行处理,没有数组则这次空转。dpdk 中就使用了轮的方式来接收数据;linux 网卡驱动中,也存在轮询的方式进行收包。
(2)中断(事件)
linux 网卡驱动收包,也存在中断的方式,当报文到达网卡之后,会发出硬中断,硬中断会触发网络收包软中断,在软中断中进行收包。从广义上来说,事件触发的方式也属于中断方式,在用户态使用 epoll 接收数据时,epoll 在内核的实现也属于事件触发。
轮询和中断(事件)可以看做一个时间维度,一个是事件维度。在大部分场景下,事件触发方式是有优势的,事件到来之后就能得到立即处理,实时性好;事件到来之后才会处理,没有轮询方式中空转的情况,不会浪费 cpu 资源。
在做应用开发时,开发的服务的呈现形式往往有两种,一种是独立的服务,服务中有 main() 函数,可以独立部署;一种是模块式开发,服务开发出来是一个模块,模块中没有 main() 函数,模块需要依赖调度框架来执行。linux 内核模块,nginx 中的模块,都是模块式开发。
在自动驾驶系统中,往往也采用模块式开发。有专门的团队负责开发提供框架,业务方基于框架进行开发。这样可以做到解耦,让业务方只关心业务开发,不关心底层的调度和通信方面的实现,这也是中间件的价值所在。
cyberrt 中提供的组件就是向业务方提供的开发的基类。组件包括两种,分别是时间维度的定时组件 TimerComponent 以及事件触发的 Component。本文关注事件触发的 Component。
1 Component 例子
apollo 源码中有一个 Componnet 的例子,路径如下:
https://github.com/ApolloAuto/apollo/tree/master/cyber/examples/common_component_example
源码:
从如下代码中可以看到,组件继承 Component 类之后,只需要实现 Init() 和 Proc() 两个函数即可。这个组件需要接收并处理两个数据,分别是 msg0 和 msg1,组件只要实现数据的处理逻辑即可。底层通信层如何接收消息,接收到消息之后什么时候调用 Proc() 函数,都不需要业务方关心,降低了业务开发的复杂度。
using apollo::cyber::Component;
using apollo::cyber::ComponentBase;
using apollo::cyber::examples::proto::Driver;class CommonComponentSample : public Component<Driver, Driver> {public:bool Init() override;bool Proc(const std::shared_ptr<Driver>& msg0,const std::shared_ptr<Driver>& msg1) override;
};
CYBER_REGISTER_COMPONENT(CommonComponentSample)bool CommonComponentSample::Init() {AINFO << "Commontest component init";return true;
}bool CommonComponentSample::Proc(const std::shared_ptr<Driver>& msg0,const std::shared_ptr<Driver>& msg1) {AINFO << "Start common component Proc [" << msg0->msg_id() << "] ["<< msg1->msg_id() << "]";return true;
}配置文件:
配置文件中包括了组件编译出来的动态库的路径,以及组件需要处理的数据类型。
module_config {module_library : "cyber/examples/common_component_example/libcommon_component_example.so"components {class_name : "CommonComponentSample"config {name : "common"readers {channel: "/apollo/prediction"}readers {channel: "/apollo/test"}}}}2 Component 最大特点:数据融合
就像上边这个例子,组件需要处理两个消息 msg0 和 msg1。如果只有其中一个消息到来的话,那么 Proc() 函数是不会被调用的,只有两个数据都到来只后 Proc() 函数才会被调用。
Component 底层最大的功能和特点就是数据融合,判断多个消息是不是都到来了。如果不需要数据融合,组件只需要处理一个消息,那么 Component 的价值就不大了。因为我们使用的通信中间件,比如 dds,在接收侧都是可以注册回调的,当数据到来时,底层调用回调函数。直接使用通信中间件就可以,没必要再使用 Component。
自动驾驶业务中有很多数据融合的场景,这种调度逻辑也被称作 dag。
如下图所示,有 4 个组件,component1 ~ component4。component1 发布 channel1 的数据,component2 和 component3 接收 channel1 的数据,然后处理,处理之后分别发布 channel2 和 channel3 的数据。component4 需要 channel2 和 channel3 的数据都到来之后才能执行,但是这两个消息的到来肯定是有时间差的,这就需要 Component 底层进行判断,两个消息都到来再执行 component4。
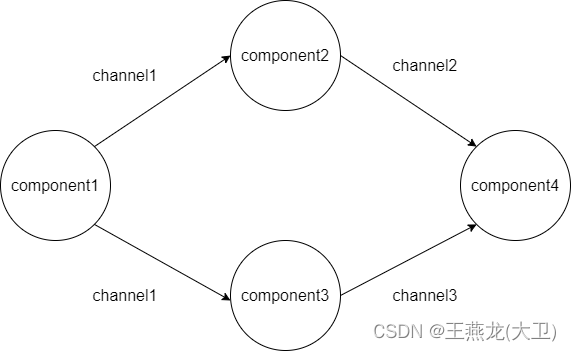
3 Component 实现
Component 源码:
https://github.com/ApolloAuto/apollo/blob/master/cyber/component/component.h
从源码中可以看出,Component 支持处理的消息类型的个数最多是 4 个,当然也支持 3 个,2 个,1 个。
template <typename M0, typename M1, typename M2, typename M3>
bool Component<M0, M1, M2, M3>::Process(const std::shared_ptr<M0>& msg0,const std::shared_ptr<M1>& msg1,const std::shared_ptr<M2>& msg2,const std::shared_ptr<M3>& msg3);template <typename M0, typename M1, typename M2, typename M3>
bool Component<M0, M1, M2, M3>::Initialize(const ComponentConfig& config);3.1 类,对象,概念
| 概念 | 解释 |
| ComponentBase | 这个是一个基类,TimerComponent 和 Component 都是基于这个类派生出来。 有两个重要的成员,node 和 readers,node 相当于通信的句柄,用来创建 reader,writer;readers 用来保存所有的 reader。 Component 内部创建 reader,构造函数的形参就是需要 sub 的数据,不需要用户自己创建 reader;writer 需要用户自己创建,所以 Component 内部维护了 reader 而没有维护 writer。 |
| Node | Component 内部有个 node,node 可以创建 reader。 里边有一个 reader 集合,用于保存 Component 内的 reader。 node 就相当于管理通信的句柄,一个通信的节点当做一个 node。 属性包括 node_name, 以及 readers,最重要的就这两个,readers 是一个 map,key 是 node name, value 是 reader。 |
| Reader | reader 里边的成员主要有两个,一个是收到数据的时候回调函数,一个是 receiver,receiver 负责接收数据。 |
| DataVisitor | Datavisitor 简称 dv。 dv 里边主要的成员也是有两个,一个是 channel buffer,针对每个类型的 msg,存储这种 msg 的数据,另一个是 fusion,Fusion 就是对多个 msg 进行融合。 dv 作为数据的中转站,主要作用有两个,一个是使用 buffer 保存数据,另一个是收到数据之后唤醒消费这个数据的任务。 buffer: 用于缓存数据。 有两种类型的 buffer,一个是只保存单个 channel 的数据,另外一个是保存融合数据,叫 buffer_fusion, buffer_fusion 在 data_fusion 中管理。 notifier: 唤醒处理数据的任务。 data_fusion: 负责数据对齐和融合,data fusion 里边注册了一个回调,这个回调中做的事情是判断数据是不是都来了,如果都来了,则将数据放到 buffer_fusion 中。 task 中就是判断 fusion data 有没有数据,如果有数据则把数据再拆分到 msg0, msg1,msg2 中,调用用户的回调函数。 每个 reader 都会创建一个 visitor,同时 Component 里边会创建一个总的 data visitor。 |
| RoutineFactory | 这个类里边创建了一个回调函数,这个函数里边就是 fetch 的逻辑,数据都到来之后就会调用回调函数,回调函数赋值在了 create_routine。 |
| Scheduler | 调度器 |
| Task | component 初始化的最后一个步骤是创建 Task, 创建 Task 的时候会把上边创建的 factory 以及 datavisitor 传进去。task 在 cyberrt 里边叫做 croutine。 传递 datavisitor 是要给这个 datavisitor 的 notifier 设置 callback,有数据的时候就会调用这个 callback, 唤醒这个 task。 |
| channel | channel 表示一个通信的基本单位,用来标志一个通信通道,类似于网络编程中的 socket,也类似于 dds 中的 topic。 channel name 要全局唯一,内部使用的时候是使用 channel id 来表示一个 channel 的,channel id 是基于 channel name 计算的哈希值。 channel 信息需要卸载配置文件中,在代码中用 ReaderConfig 来维护。 |
3.2 源码分析
3.2.1 初始化
template <typename M0, typename M1, typename M2, typename M3>
bool Component<M0, M1, M2, M3>::Initialize(const ComponentConfig& config) {// 创建 Node, 加载配置文件// Node 代表一个通信的节点,配置文件中包括这个组件需要处理的数据node_.reset(new Node(config.name()));LoadConfigFiles(config);// 配置校验// 消息少于 4 个则返回错误if (config.readers_size() < 4) {AERROR << "Invalid config file: too few readers_." << std::endl;return false;}// 组件初始化,业务侧自己实现if (!Init()) {AERROR << "Component Init() failed." << std::endl;return false;}bool is_reality_mode = GlobalData::Instance()->IsRealityMode();// 解析配置文件,配置在 ReaderConfig 中维护ReaderConfig reader_cfg;reader_cfg.channel_name = config.readers(1).channel();reader_cfg.qos_profile.CopyFrom(config.readers(1).qos_profile());reader_cfg.pending_queue_size = config.readers(1).pending_queue_size();// 创建 Readerauto reader1 = node_->template CreateReader<M1>(reader_cfg);...reader_cfg.channel_name = config.readers(0).channel();reader_cfg.qos_profile.CopyFrom(config.readers(0).qos_profile());reader_cfg.pending_queue_size = config.readers(0).pending_queue_size();std::shared_ptr<Reader<M0>> reader0 = nullptr;if (cyber_likely(is_reality_mode)) {reader0 = node_->template CreateReader<M0>(reader_cfg);} else {...}if (reader0 == nullptr || reader1 == nullptr || reader2 == nullptr ||reader3 == nullptr) {AERROR << "Component create reader failed." << std::endl;return false;}readers_.push_back(std::move(reader0));readers_.push_back(std::move(reader1));readers_.push_back(std::move(reader2));readers_.push_back(std::move(reader3));if (cyber_unlikely(!is_reality_mode)) {return true;}auto sched = scheduler::Instance();std::weak_ptr<Component<M0, M1, M2, M3>> self =std::dynamic_pointer_cast<Component<M0, M1, M2, M3>>(shared_from_this());auto func =[self](const std::shared_ptr<M0>& msg0, const std::shared_ptr<M1>& msg1,const std::shared_ptr<M2>& msg2, const std::shared_ptr<M3>& msg3) {auto ptr = self.lock();if (ptr) {ptr->Process(msg0, msg1, msg2, msg3);} else {AERROR << "Component object has been destroyed." << std::endl;}};std::vector<data::VisitorConfig> config_list;for (auto& reader : readers_) {config_list.emplace_back(reader->ChannelId(), reader->PendingQueueSize());}// 创建一个融合 DataVisitorauto dv = std::make_shared<data::DataVisitor<M0, M1, M2, M3>>(config_list);// 创建 Taskcroutine::RoutineFactory factory =croutine::CreateRoutineFactory<M0, M1, M2, M3>(func, dv);return sched->CreateTask(factory, node_->Name());
}3.2.2 Reader
Reader 中会创建 Receiver 和 DataVisitor 以及 Task,Receiver 负责接收数据;DataVisitor 负责缓存数据,并且唤醒消费这个数据的 Task。
Reader 最底层的数据分发函数是 Dispatch(),当接收到数据时调用这个函数。
buffers_map_ 是一个全局的数据结构,key 是 channel id,value 是 buffer。一个 channel id 对应的 buffer 可能不止一个,如果有多个 reader,那么就会有多个 buffer。收到数据之后将数据放到每个监听 buffer 中。将 buffer 放到 buffers_map_ 中是在 Datavisitor 的构造函数中完成的。
notifier_->Notify() 是将监听这个消息的 Task 唤醒,同样有一个全局数据结构 notifies_map_,key 是 channel id,value 是回调函数,也就是处理这个消息的函数。将 notifier 加到 notifiers_map_ 中也是在 DataVisitor 的构造函数中完成的。在 DataVisitor 构造的时候 notifier_->callback 还没有赋值,赋值实在 CreateTask()中调用 visitor->RegisterNotifyCallback() 完成的,这也很好理解,在 CreateTask()之前还没有回调函数的,当然也不能挂载。
// cyber/data/data_dispatcher.htemplate <typename T>
bool DataDispatcher<T>::Dispatch(const uint64_t channel_id,const std::shared_ptr<T>& msg) {BufferVector* buffers = nullptr;if (apollo::cyber::IsShutdown()) {return false;}if (buffers_map_.Get(channel_id, &buffers)) {for (auto& buffer_wptr : *buffers) {if (auto buffer = buffer_wptr.lock()) {std::lock_guard<std::mutex> lock(buffer->Mutex());buffer->Fill(msg);}}} else {return false;}return notifier_->Notify(channel_id);
}3.3 核心,中枢
由 3.2.2 节的分析可以知道 DataVisitor 是 Component 底层调度的中枢。DataVisitor 连接了通信层和任务调度层。
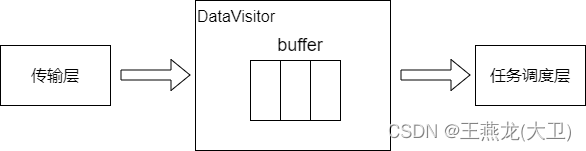
3.4 收到数据之后的函数调用过程
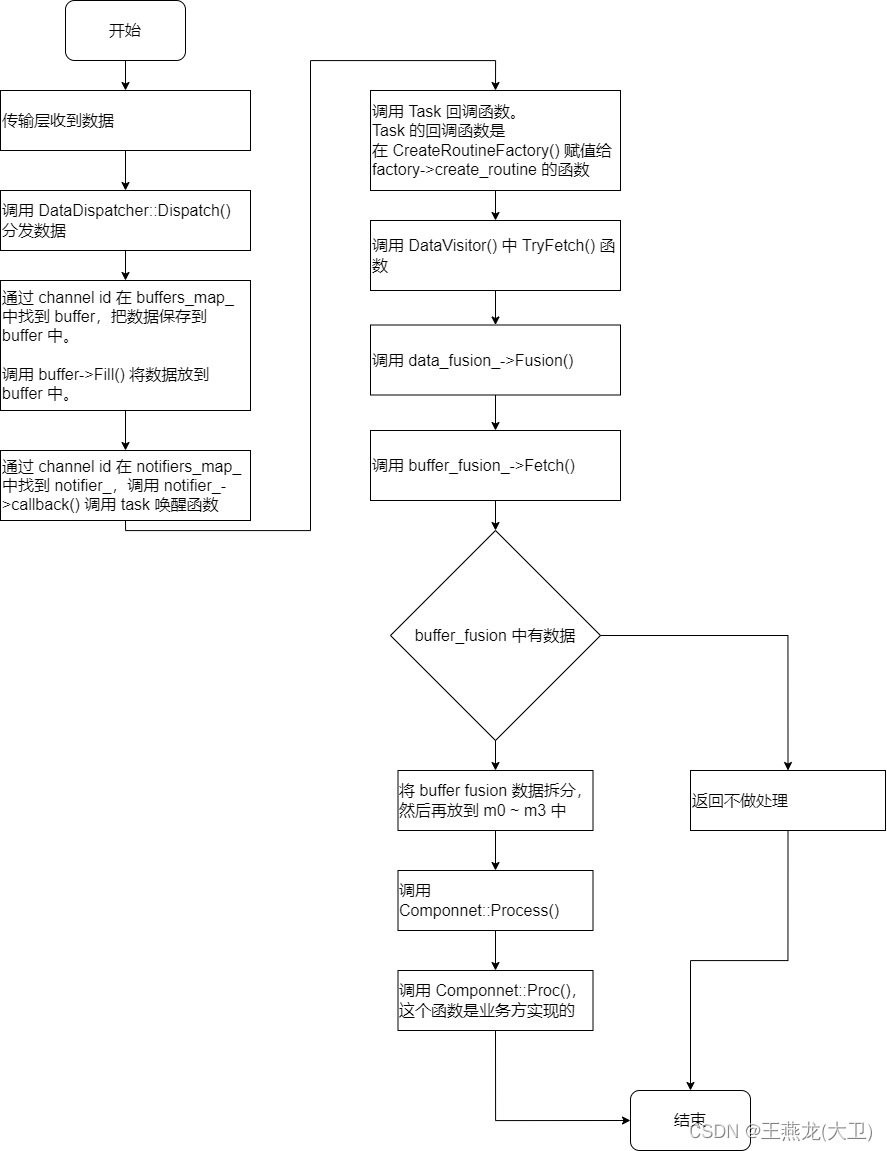
4 Component 问题探讨
4.1 数据融合条件单一
当 msg 个数大于 1 的时候,会通过 SetFusionCallback() 注册一个融合回调函数。
当收到数据的时候在 Dispach() 函数中调用 Fill() 的时候会调用融合回调函数。从如下的实现可以看出来,只有 msg0 到来的时候才会调用融合回调函数,如果消息到来的顺序依次是 msg1, msg2, msg3, msg0,msg0 最后到来,那么这种逻辑是没问题的,msg0 到来的时候,4 个消息都到来了。如果消息发来顺序是 msg0, msg1, msg2, msg3,msg0 是第一个到来的,那么在 msg0 到来的时候,会直接返回,等后边 msg1 ~ msg3 都到来的时候也无法融合,只有下一个 msg0 到来的时候才会融合,这样就把上次到来的 msg0 丢了。
这种实现方式可能会出现问题,在实际使用中应该多一些策略,比如 msg1 ~ msg3 到来的时候都进行融合判断,这样会更合理一些。
AllLatest(const ChannelBuffer<M0>& buffer_0,const ChannelBuffer<M1>& buffer_1,const ChannelBuffer<M2>& buffer_2,const ChannelBuffer<M3>& buffer_3): buffer_m0_(buffer_0),buffer_m1_(buffer_1),buffer_m2_(buffer_2),buffer_m3_(buffer_3),buffer_fusion_(buffer_m0_.channel_id(),new CacheBuffer<std::shared_ptr<FusionDataType>>(buffer_0.Buffer()->Capacity() - uint64_t(1))) {buffer_m0_.Buffer()->SetFusionCallback([this](const std::shared_ptr<M0>& m0) {std::shared_ptr<M1> m1;std::shared_ptr<M2> m2;std::shared_ptr<M3> m3;if (!buffer_m1_.Latest(m1) || !buffer_m2_.Latest(m2) ||!buffer_m3_.Latest(m3)) {return;}auto data = std::make_shared<FusionDataType>(m0, m1, m2, m3);std::lock_guard<std::mutex> lg(buffer_fusion_.Buffer()->Mutex());buffer_fusion_.Buffer()->Fill(data);});}这篇关于cyberrt component 实现分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






