本文主要是介绍【论文解读】Latency-Aware Collaborative Perception,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Latency-Aware Collaborative Perception
- 摘要
- 引言
- 方法
- System
- SyncNet
- 实验
摘要
协作感知最近显示出提高单智能体感知感知能力的巨大潜力。现有的协同感知方法通常考虑理想的通信环境。然而,在实践中,通信系统不可避免地存在延迟问题,导致安全关键应用中潜在的性能下降和高风险,如自动驾驶。为了减轻不可避免的延迟造成的影响,从机器学习的角度来看,我们提出了第一个延迟感知协同感知系统,该系统从多个代理主动适应异步感知特征到同一个时间戳,提高了协作的鲁棒性和有效性。为了实现这种特征级同步,我们提出了一种新的延迟补偿模块SyncNet,该模块利用特征注意共生估计和时间调制技术。实验结果表明,所提出的具有SyncNet的延迟感知协同感知系统在通信延迟场景下的性能优于目前最先进的协同感知方法15.6%,在严重延迟下保持协同感知优于单一智能体感知
引言
为了解决延迟问题,从机器学习的角度来看,我们提出了第一个延迟感知协同感知系统,该系统从多个代理主动适应异步感知特征到相同的时间戳,提高了协作的鲁棒性和有效性。如图2所示,我们的延迟感知协同感知系统遵循中间协作框架[15],由五个组件组成:
i)编码模块,从原始数据中提取感知特征;
ii)通信模块,在不同的通信延迟下跨代理传输感知特征;
iii)延迟补偿模块,将多个agent的特征同步到同一个时间戳;
iv)融合模块,聚合所有同步的特征,生成融合特征;
v)解码模块,采用融合特征得到最终的感知输出。
我们的延迟感知协同感知系统的主要优点是它能够在聚合之前同步协作特征,减轻延迟引起的效果,而不是直接聚合接收到的异步特征
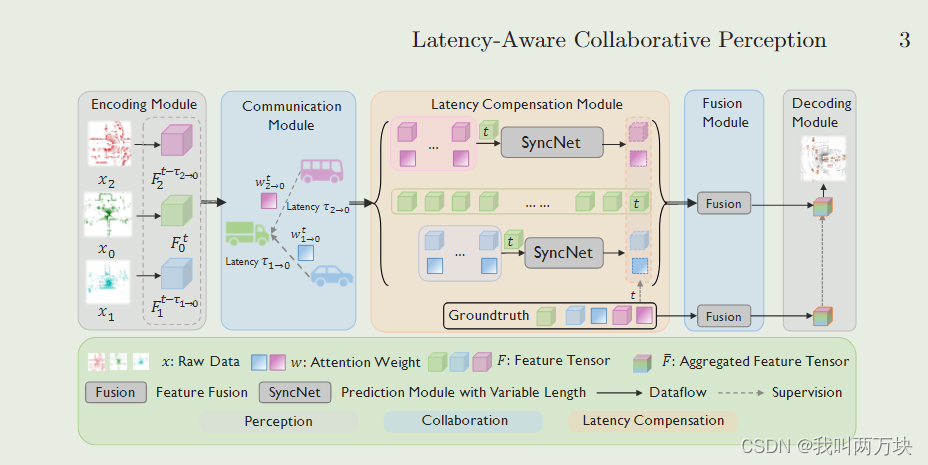
图2:提出的延迟感知协同感知系统概述:关键模块是延迟补偿模块。为了实现这一点,我们提出了SyncNet,它利用历史协作信息从延迟问题引起的多个代理同步异步信息。
该系统的关键部件是延迟补偿模块,旨在实现特征级同步。为了实现这一点,我们提出了一种新的SyncNet,它利用历史协作信息来同时估计当前特征和相应的协作注意力,这两者由于延迟而未知。与常见的时间序列预测方法相比,所提出的SyncNet有两个主要区别:
i)特征水平估计,而不是输出水平预测;
ii)耦合特征和相关协作注意力的估计,而不是预测单个输出
我们的主要贡献:
- 我们首次提出了协作感知中的通信延迟挑战,并提出了一种新的延迟感知协作感知系统,该系统通过减轻不可避免的通信延迟的影响来促进强大的多主体感知。
- 我们提出了一种新的延迟补偿模块,称为SyncNet,以实现特征级同步。它实现了对两类关键协作信息的共生估计,包括中间特征和协作注意力,相互增强。
- 我们进行了全面的实验,结果表明,与之前的方法相比,我们提出的SyncNet在延迟场景中实现了巨大的性能改进,并在严重延迟的情况下保持了协作感知优于单代理感知。
方法
System
由于在现实的通信系统中,通信延迟是不可避免的,因此我们重点关注一个感知延迟的协同感知系统;也就是说,给定一个具有不可控制延迟的非理想通信信道,我们的目标是通过减轻延迟的影响来优化每个代理的感知能力。
我们认为在一个场景中有N个智能体感知环境。设X(t)i、F(t)i和Y(t)i分别为第i个智能体在时间戳t的原始观测值、感知特征和最终感知输出;τ (t)j→i为第j个agent向第i个agent传输数据的时间延迟(latency);W(t)j→代表agent j和agent i在时间戳t时的协作注意力。协作注意力由可学习网络fattention(F(t)i, F(t)j)计算,在协作感知系统的所有协作特征之间点明智地分配注意力。注意,i)延迟值τ (t)j→i是时变的,我们省略了它的上标t只是为了简化符号;ii)本工作认为协作发生在离散时间戳,并且τ是离散的,因为每个代理具有一定的观测采样率。实验结果还验证了在合理小的时间间隔内对连续时间进行离散时,得到的失配较小。然后,将提出的延迟感知协同感知表述为
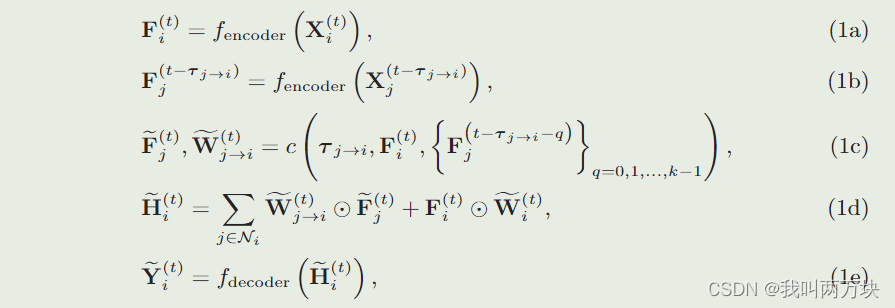
其中,[F(t)j]为同步后第j个智能体在时间戳t处的估计特征,[W(t)j→i]为第i个智能体与第n个智能体在时间戳t处的估计协作注意力,[H(t)i]为第i个智能体在时间戳t处的估计协作信息聚合后的估计特征,[Niis]为第i个智能体的邻居,k为超参数。
步骤(1a)考虑从观测数据中提取感知特征,其中fencoder(·)为编码网络。在步骤(1b)中,我们从其他具有不同延迟时间的智能体接收感知特征。为了补偿延迟,步骤(1c)通过利用来自同一代理的历史特征和自我代理i感知的实时特征来估计时间戳t的特征和协作注意力,其中c(·)表示估计网络。这里我们假设每个智能体可以在内存中存储k帧的历史特征。步骤(1d)融合了所有估计的协作信息。最后,步骤(1e)输出最终感知输出,其中fdecoder(·)为解码器网络。与图2对应,步骤(1a)和(1b)构成编码模块;步骤(1c)有助于延迟补偿模块;步骤(1d)为延时融合模块;步骤(1e)构成解码模块。
提出的延迟感知系统有四个优点:1)我们明确地将通信延迟纳入协作感知系统的设计中,这在以前的工作中从未做过;见(1b) (1c);Ii)我们通过从历史协作信息中估计缺失信息来减轻延迟的影响;见(1 c)。我们考虑特征级同步,而不是同步感知输出,因为它允许端到端学习框架具有更大的学习灵活性;iii)在(1c)中,我们同时估计了耦合协作特征和注意力。如果我们只估计特征,我们将需要基于估计的特征来计算协作关注。这将放大估计误差,导致级联失败;iv)采用基于注意的估计,利用(1c)中的协作注意促进对感知敏感区域的更精确的估计;见(1 d)。
SyncNet
由于延迟补偿模块是延迟感知协同感知系统的关键,即(1c)中的c()。它的功能是利用历史信息来实现延迟补偿。SyncNet包括两个部分:
- feature-attention共生估计,采用双分支金字塔LSTM同时估计实时特征和协作注意力;
- 时间调制,利用延迟时间自适应调整协作特征的最终估计。
特征-注意力共生估计
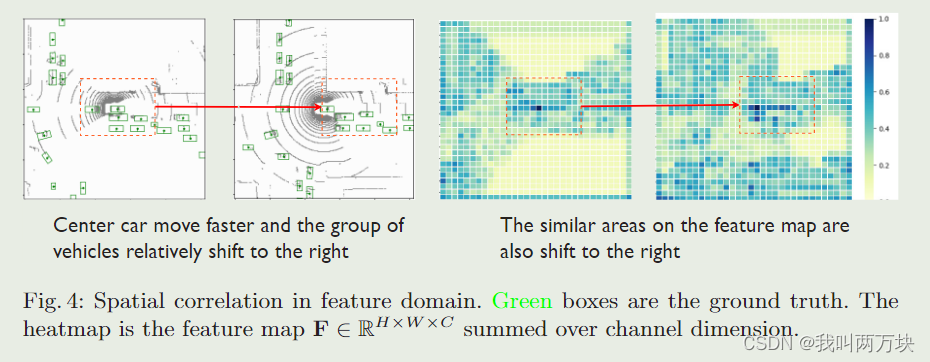
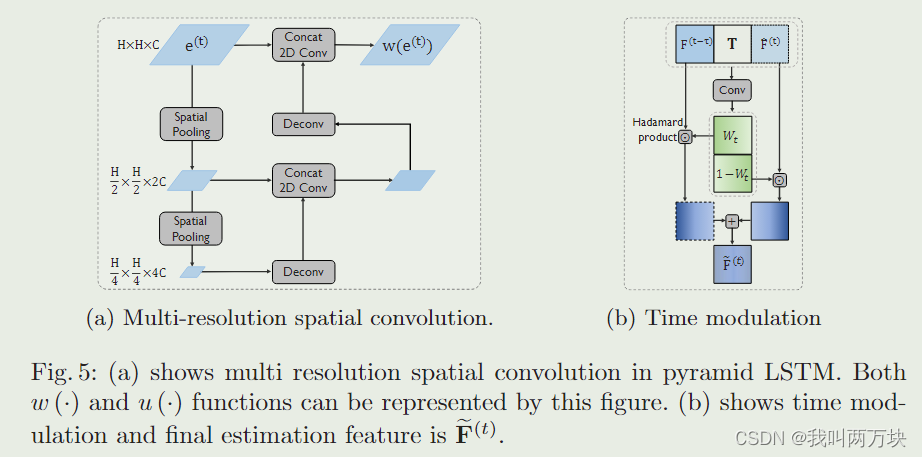
特征-注意力共生估计(FASE)利用一种新的双分支架构,包括特征估计分支和注意力估计分支,同时估计特征及其相应的协作注意力。双LSTM网络的两个分支共享相同的输入,包括自我代理i感知的实时特征和协作者j感知的k帧历史特征。每个分支由一个金字塔LSTM实现,该LSTM对一系列历史协作信息建模并估计当前状态。金字塔LSTM专门用于捕获空间相关的协作特征。如图4所示,当红框内的车辆组相对于中心车辆相对右移时,特征上的相似区域也会发生相同的移动。事实表明,空间信息对我们的估计任务是重要的。我们将LSTM[10]中的矩阵乘法修改为多尺度卷积结构;详见图5a。本文提出的金字塔LSTM与普通LSTM的主要区别在于:LSTM[10]没有专门考虑提取空间特征;convl - lstm[23]提取单尺度空间特征;而所提出的金字塔LSTM则是为了在多个尺度上捕捉局部到全局的特征。
整个过程如算法1所示,其中τ为延迟时间,k为历史帧,t0为当前时间,W(t)j和F(t)j分别为时间戳t时第j个agent到第ith个agent的协作注意力和特征,j (F)j和j W(t)j分别为时间戳t时协作注意力和特征的估计,e(t)是时间戳t时金字塔LSTM的输入,h(t)F,c(t)F,h(t)W和c(t)W分别是金字塔LSTM在每个分支中的隐藏状态和细胞状态。

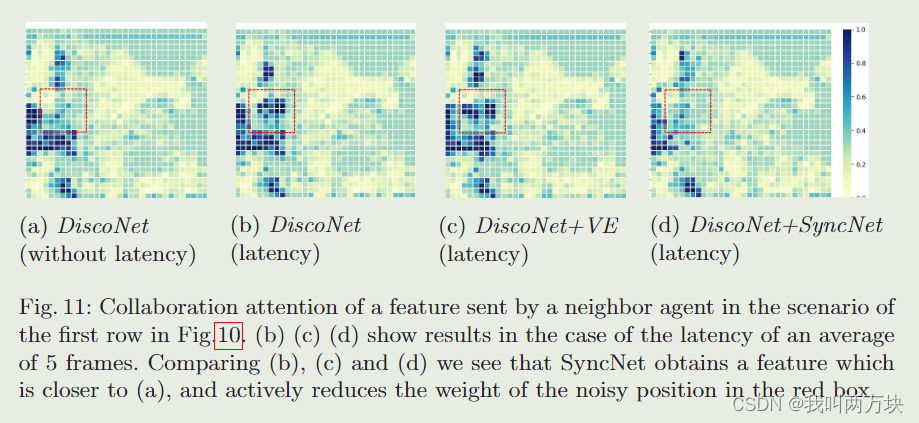
所提出的特征-注意力共生估计具有三个特点:1)双分支结构同时推断协同特征和相应的协同注意力,保持独立性并消除级联故障;Ii)估计网络将协作关注作为输入,从而聚焦于更多信息领域,促进更有效的估计;Iii)在理想协同下,可学习的注意力估计网络获取特征的信息,并从注意力和融合特征中获得监督。在端到端优化过程中,它不仅可以无延迟地模拟计算出的权重分布,还可以主动学习减少对特征中噪声较大的空间位置的关注。
时间调制
虽然FASE实现了c(·)的基本功能,但我们发现,当延迟较低时,延迟引起的性能下降相对于FASE导致的估计噪声较小。为了解决这个问题,我们提出了时间调制,它将原始(在低延迟下工作良好)和估计(在高延迟下工作良好)的特征融合在一起,以延迟时间为条件,产生更全面和可靠的估计。
设M(t)F, M(t)W∈RH×W为反映每个空间区域估计不确定程度的置信度矩阵,TF∈RH×W ×C, TW∈RH×W为延时时间τ∈R展开得到的延时张量,其形状分别与ω F(t)和ω W(t)相同。时间调制的工作原理如下
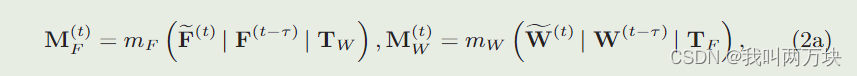
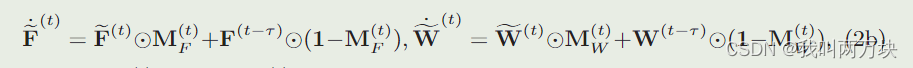
其中mF(·)和mW(·)均为具有sigmoid激活函数的轻量级卷积神经网络,1∈RH×W为所有元素均为1的矩阵。步骤(2a)分别利用FASE估计的协同特征/注意力、最新的异步特征/注意力和延迟张量进行拼接,得到每个空间区域特征估计的置信度。根据置信度矩阵,步骤(2b)分别将估计的特征/注意力和最新的异步特征/注意力组合起来。我们期望当延迟高时,置信度矩阵的权重会更高,估计的特征/注意力对最终估计的贡献会更大;如图5b所示。
实验
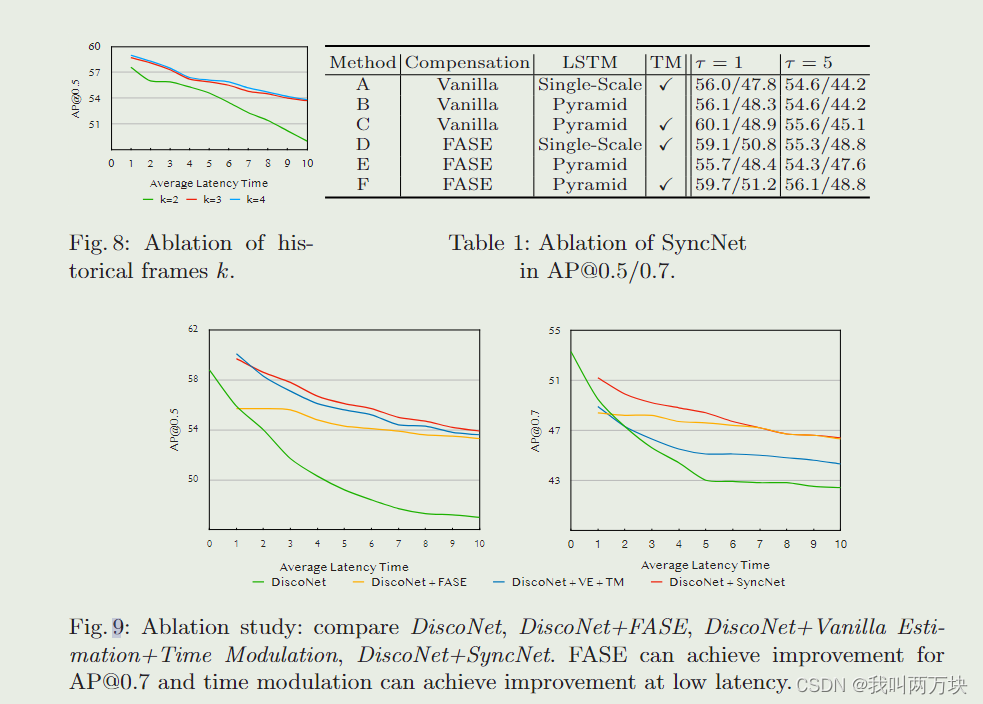
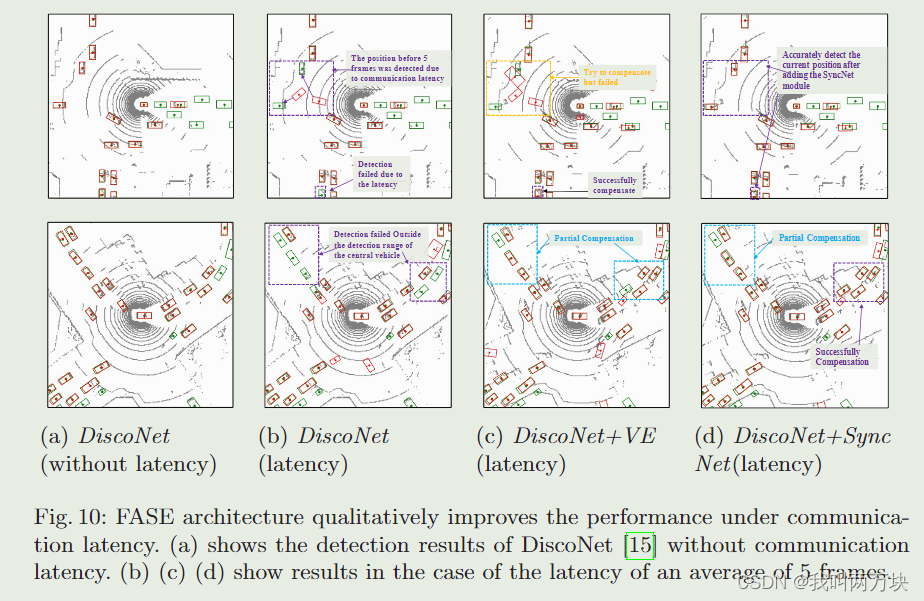
这篇关于【论文解读】Latency-Aware Collaborative Perception的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





