本文主要是介绍十大经典排序算法之一--------------堆排序(java详解),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.堆排序基本介绍:
- 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。
- 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆, 注意 : 没有要求结点的左孩子的值和右孩子的值的大小关系。
- 每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆
大顶堆&&小顶堆(图解):
大顶堆:
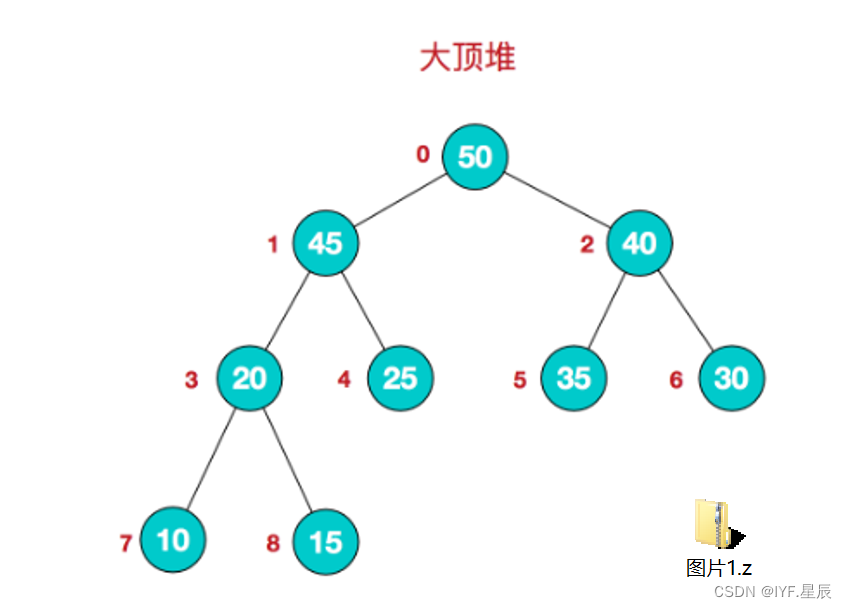
其中,二叉树节点外面标注的是堆对应的数组下标,也就是:

小顶堆:
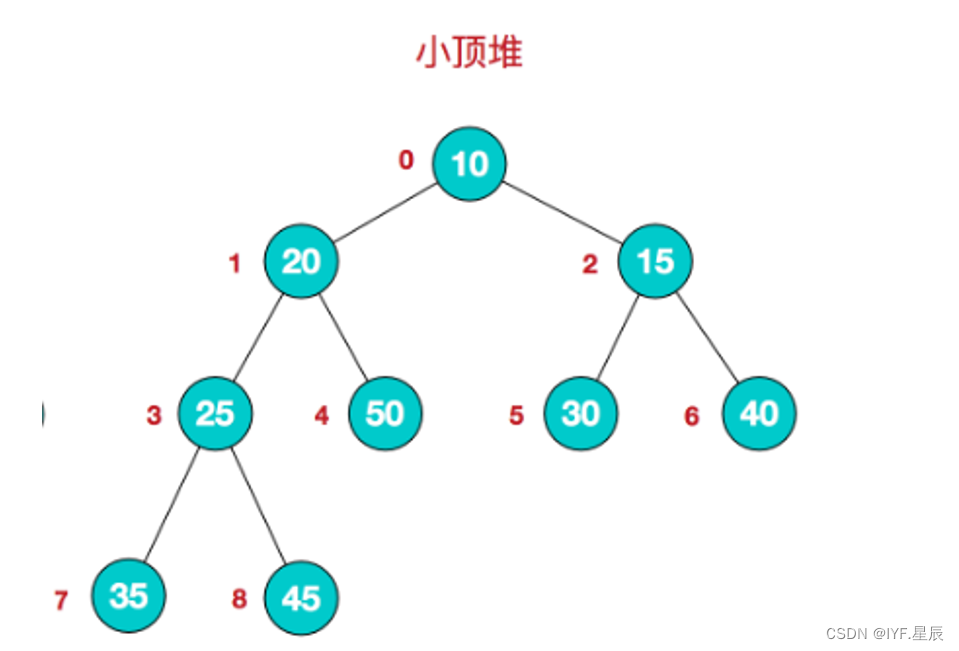
*假设我们有了一个待排序的数组,并且构建好了他的逻辑结构,怎么能通过孩子找到双亲,或者通过双亲找到左右孩子呢?其实也很好理解,我们拿一颗二叉树出来就能很轻易的得出公式:
具体公式: parent = (child - 1) / 2 ;
leftchild = parent * 2 + 1 ;
rightchild = parent * 2 + 2 ;
rightchild = leftchild + 1;
二.堆排序详解:
2.1.堆排序的基本思路(这里以顺序排序为主):
- 将待排序序列构造成一个大顶堆
- 此时,整个序列的最大值就是堆顶的根节点
- 将其与末尾元素进行交换,此时末尾就为最大值
- 然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了
①.构建大顶堆:
1).以给定的无序堆为例:
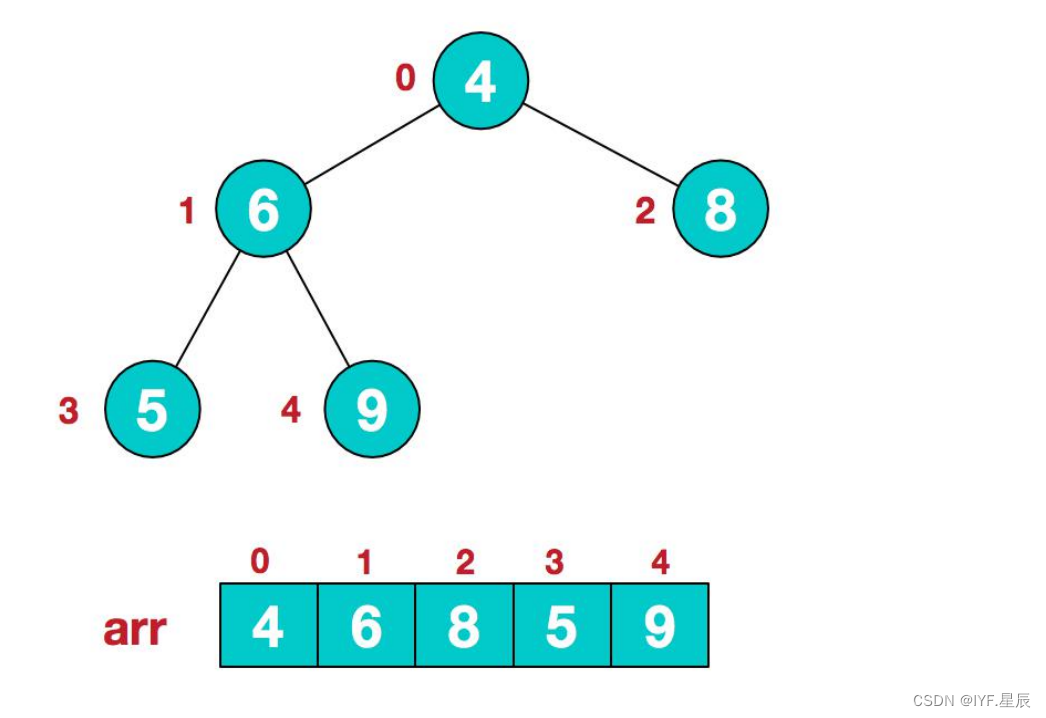
2).此时我们从最后一个非叶子节点开始(叶子节点自然不用调整,最后一个非叶子节点为:
arr.length / 2 - 1;也就是下面的6节点 ),从左至右,从上至下进行调整:
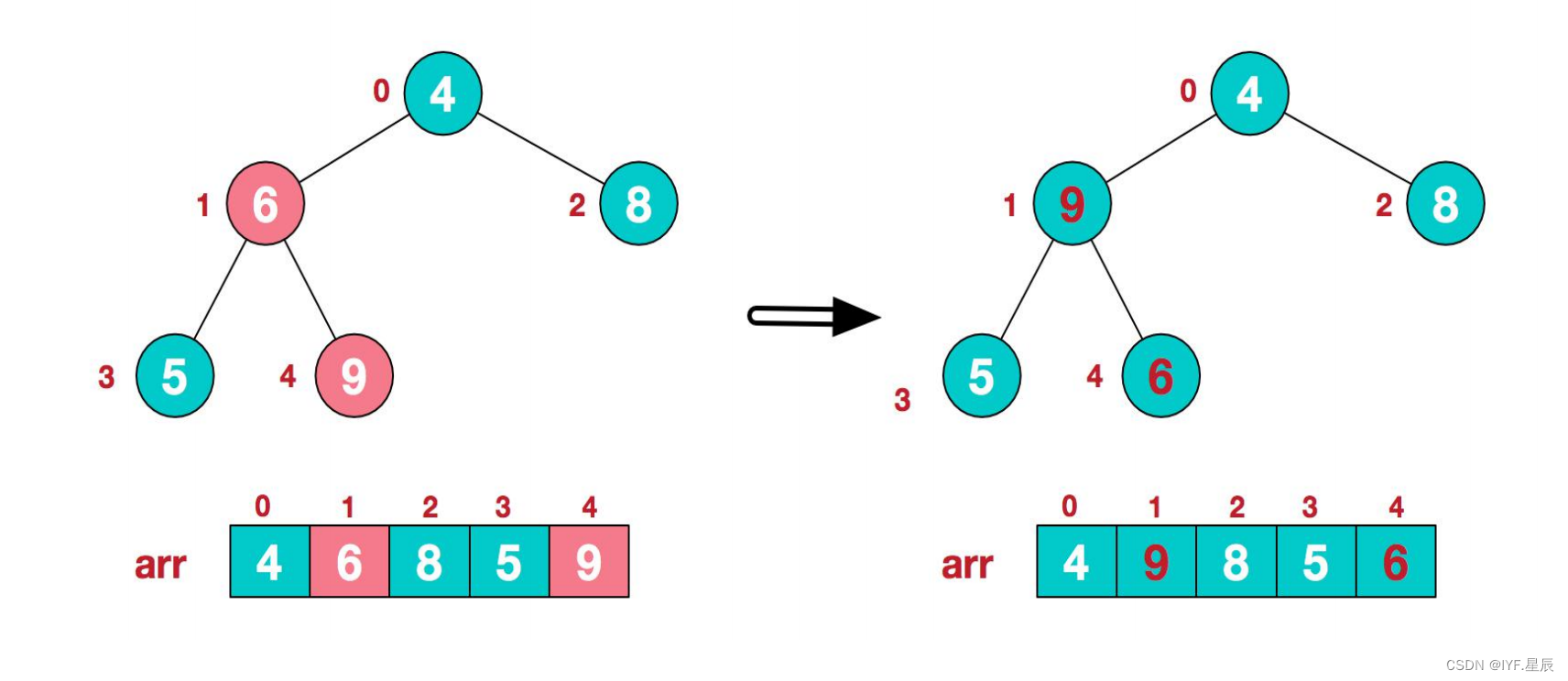 3).找到第二个非叶节点4,由于【4,9,8】中9最大,4和9交换:
3).找到第二个非叶节点4,由于【4,9,8】中9最大,4和9交换:
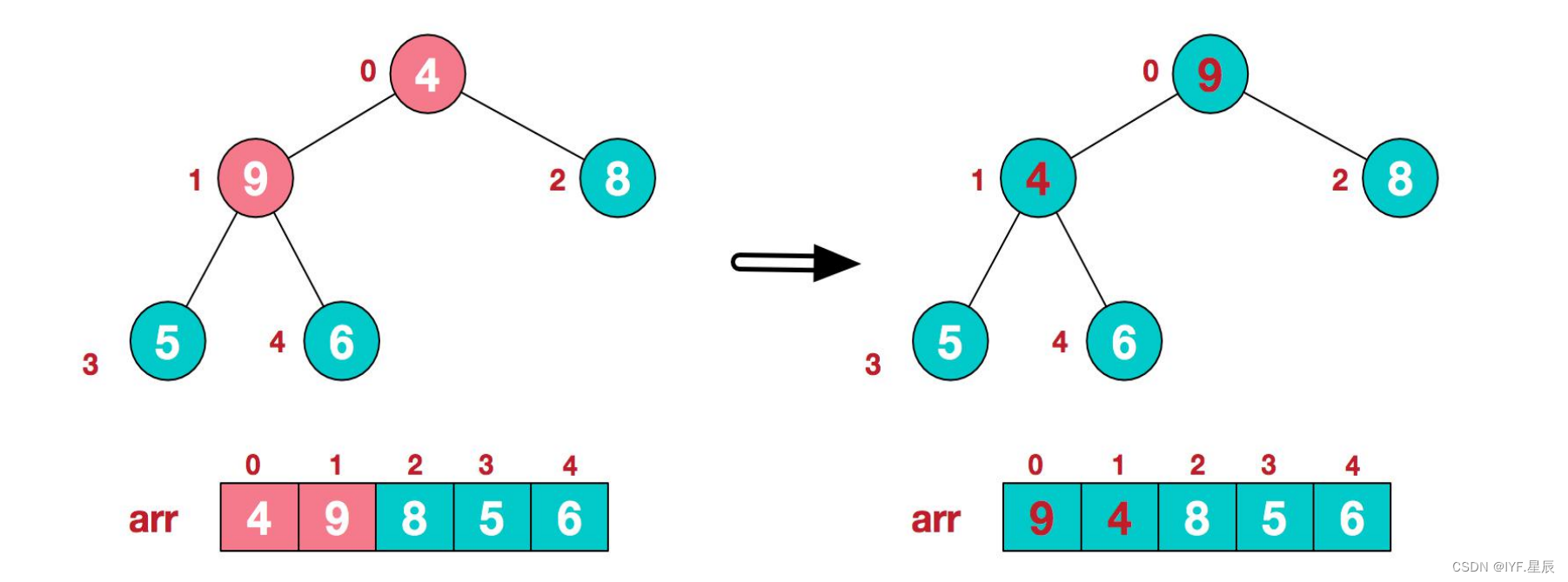
4).这时,交换导致了子根【4,5,6】结构混乱(因为我们要建立的是大顶堆),继续调整,【4,5,6】中6最大,交换4和6:

此时,我们就将一个无序序列构造成了一个大顶堆
建大堆代码实现:
//将一个数组(二叉树), 调整成一个大顶堆/*** @param arr 待调整的数组* @param i 表示非叶子结点在数组中索引* @param length 表示对多少个元素继续调整, length 是在逐渐的减少*/public static void adjustHeap(int arr[], int i, int length) {int temp = arr[i];//先取出当前元素的值,保存在临时变量//开始调整//说明//1. k = i * 2 + 1 k 是 i结点的左子结点for(int k = i * 2 + 1; k < length; k = k * 2 + 1) {if(k+1 < length && arr[k] < arr[k+1]) { //说明左子结点的值小于右子结点的值k++; // k 指向右子结点}if(arr[k] > temp) { //如果子结点大于父结点arr[i] = arr[k]; //把较大的值赋给当前结点i = k; //!!! i 指向 k,继续循环比较} else {break;//!}}//当for 循环结束后,我们已经将以i 为父结点的树的最大值,放在了 最顶(局部)arr[i] = temp;//将temp值放到调整后的位置}②.将堆顶元素与末尾元素进行交换,使末尾元素最大,然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素,如此反复,重建,交换:
1).将堆顶元素9和末尾元素4进行交换:
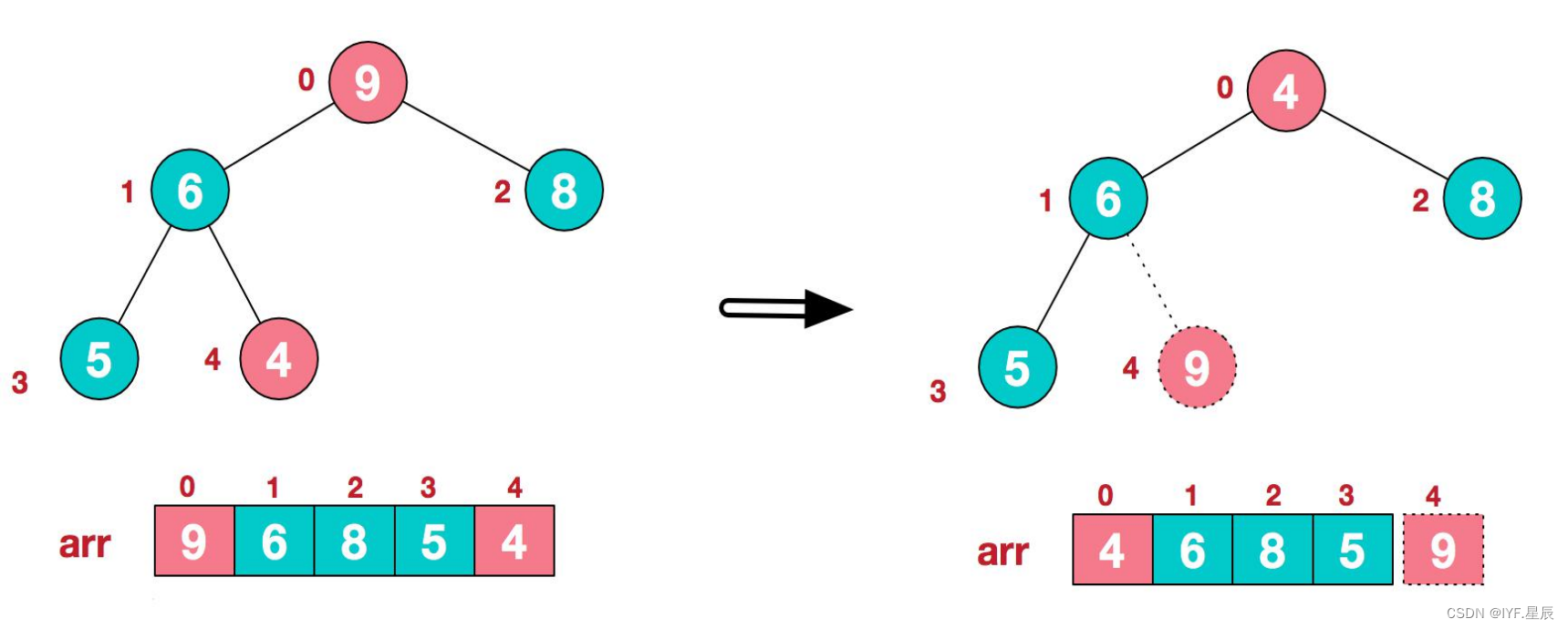
2).重新构建堆,使其继续满足堆的定义(除去9的数组建堆):
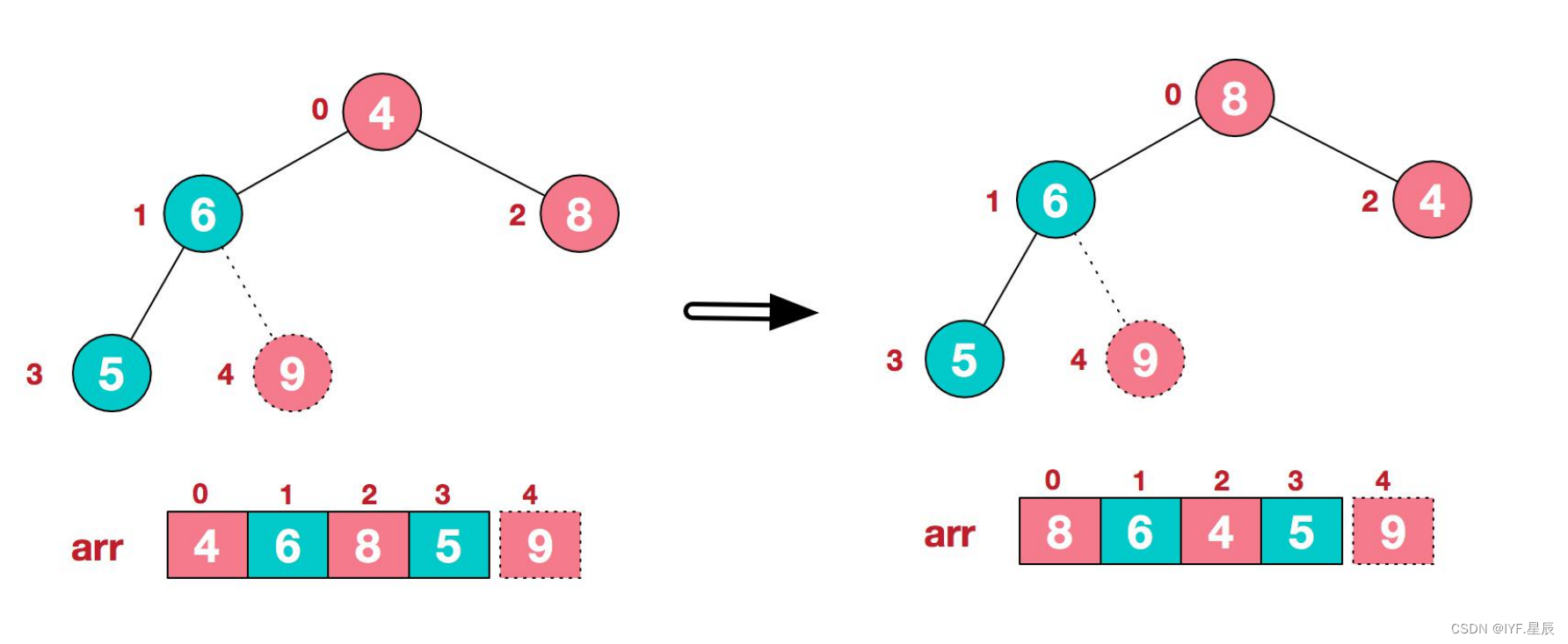
3).后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序:
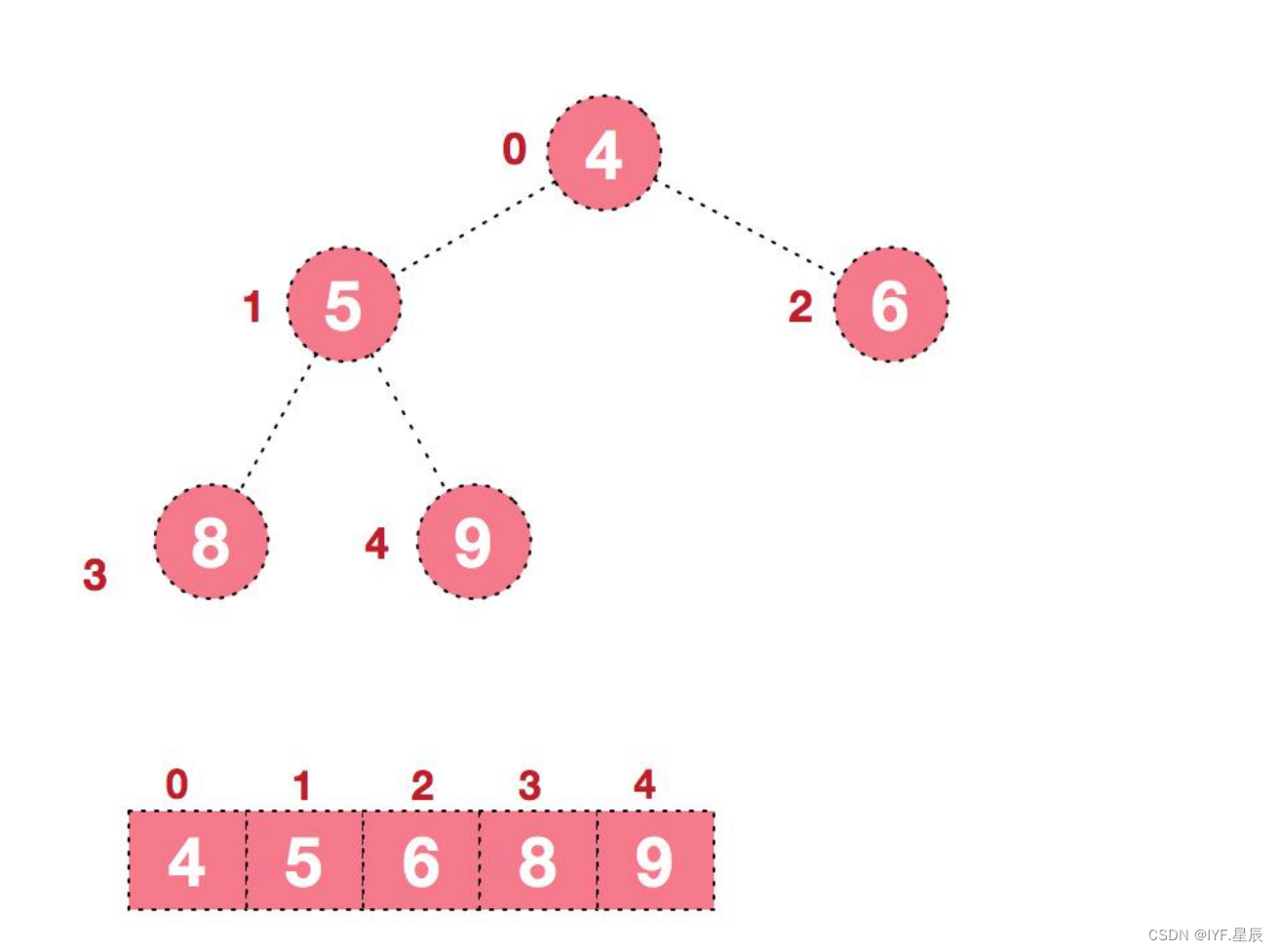
到这里你想必也能理解为什么是建大堆而不是小堆了吧,这个排序(顺序)过程实际就是利用堆顶的元素最大,使其和最后n-1个元素进行交换(数组的大小是逐渐缩小的),最终使得整个序列有序
heapSort方法实现:
//编写一个堆排序的方法public static void heapSort(int arr[]) {int temp = 0;//将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆,这里是建大堆for(int i = arr.length / 2 -1; i >=0; i--) {adjustHeap(arr, i, arr.length);}/** 2).将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;3).重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。*/for(int j = arr.length-1;j >0; j--) {//交换temp = arr[j];arr[j] = arr[0];arr[0] = temp;adjustHeap(arr, 0, j); }//System.out.println("数组=" + Arrays.toString(arr)); }堆排序完整代码:
import java.util.*;
public class HeapSort {
//测试数据public static void main(String[] args){int[] arr = {4,6,8,5,9};heapSort(arr);System.out.println("堆排序:"+Arrays.toString(arr));}public static void heapSort(int[] arr){int temp = 0;for(int i = arr.length / 2 - 1;i >= 0;i--){adjustHeap(arr,i,arr.length);}for(int j = arr.length - 1;j > 0;j--){temp = arr[j];arr[j] = arr[0];arr[0] = temp;adjustHeap(arr,0,j);}}public static void adjustHeap(int[] arr,int i,int length){int temp = arr[i];for(int k = 2 * i + 1;k < length;k = k * 2 + 1){if(k + 1 < length && arr[k] < arr[k+1]){k++;}if(arr[k] > temp){arr[i] = arr[k];i = k;}else{break;}}arr[i] = temp;}
}运行结果:
 很明显,排序成功
很明显,排序成功
堆排序速度测试:
public static void main(String[] args){// 创建要给8000000个的随机的数组int[] arr = new int[8000000];for (int i = 0; i < 8000000; i++) {arr[i] = (int) (Math.random() * 8000000); // 生成一个[0, 8000000) 数}System.out.println("排序前");Date data1 = new Date();SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");String date1Str = simpleDateFormat.format(data1);System.out.println("排序前的时间是=" + date1Str);heapSort(arr);Date data2 = new Date();String date2Str = simpleDateFormat.format(data2);System.out.println("排序前的时间是=" + date2Str);} 这里给8000000个数组排序,只用了2秒左右,可以看出堆排序的效率是相当的高
这里给8000000个数组排序,只用了2秒左右,可以看出堆排序的效率是相当的高
小结:
堆排序是一种基于二叉堆数据结构的排序算。它的主要思想是将待排序的元素构建成一个最大堆(或最小堆),然后依次将堆顶元素与堆的最后一个元素交换,并重新调整堆,使得剩余元素仍然满足堆的性质。重复这个过程,直到所有元素都被排序。
堆排序的步骤如下:
- 构建最大堆:将待排序的数组看作是一个完全二叉树,从最后一个非叶子节点开始,依次向上调整每个节点,使得每个节点都满足最大堆的性质。
- 交换堆顶元素和最后一个元素:将堆顶元素与堆的最后一个元素交换位置,此时最大元素已经排好序。
- 调整堆:将剩余元素重新调整为最大堆,再次找到最大元素并交换到堆顶。
- 重复步骤2和步骤3,直到所有元素都被排序。
堆排序的时间复杂度为O(nlogn),其中n为待排序数组的长度。它是一种不稳定的排序算法,因为在调整堆的过程中可能会改变相同元素的相对顺序。
博客到这里也是结束了,制作不易,喜欢的小伙伴可以点赞加关注支持下博主,这对我真的很重要~~

这篇关于十大经典排序算法之一--------------堆排序(java详解)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




