本文主要是介绍从一到无穷大 #24 LogReducer:讨论日志中热点的影响,识别及在线解决方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- LogReducer
- 系统性分析日志影响,原因
- 在线日志缩减框架
- 反省
- 总结
引言
排查问题单效率依赖于可观测性三件套 Logging,Metrics 和 Tracing。Metrics(时序数据库,ES)和Tracing(OpenTelemetry,ES)依赖于外部系统,不是今天讨论的重点。
Logging保存在本地存储介质,一般来讲本地存储介质的系统盘因为成本效益配置不会很高,其次全量记录日志成本又过高,此时利用有限的空间存储最长时间详细的离散事件对于排查问题就显得尤为重要,从而使得事后可以通过这些记录来完整分析程序的异常行为。
在最近的运营过程中,线上排查问题的效率成了一个瓶颈,主要原因在于Logging刷的太快,很多有用的信息容易被刷新。
LogReducer这篇文章阐述了微信的工程师如何通过在线和离线的方式减少日志对于程序的影响,我认为这篇文章的主要贡献分为以下两个方面:
- 对真实世界系统中的日志热点进行了系统研究,以揭示日志热点的影响、日志热点出现的原因以及如何解决这些问题
- 提出了一种基于eBPF的非侵入式、不依赖语言且高效的日志缩减框架,可自动识别日志热点并即时缩减日志,将日志热点的修复时间从平均 9 天缩短到测试中的 10 分钟
事实上这篇文章的思路相对容易理解;
离线的方法就是静态分析,得到出现频率最高的日志,让开发人员去修改代码,灰度发布,但是这个方法的关键在于即时性差,但是也很好理解,因为日志不是关键路径,开发人员修改代码的意愿没有那么大,这更是SRE该关心的事情(目前这方面事情在我们这边其实是开发在管23333)。
在线的方法是基于用户态分析日志热点,基于eBPF Map[3]将热点信息从用户态传递到内核态,然后对write系统调用挂kprobe的勾子,在检测到写入目标日志文件的内容匹配到热点时写入失败,以此做到非侵入且不依赖于语言。
我简单看了下LogReducer 的代码[4],只看到了在线分析的代码,没看到离线分析的代码,但是好在并不难,花了点时间撸了两个脚本,分别可以求出一个namespace内所有机器上日志的热点和单独一个pod内部某种日志的热点,在我们的线上系统执行了下,立马发现了几个日志总量占用率高达30%以上的日志热点,甚至极端pod存在占用率90%以上的日志热点。

kubectl --kubeconfig=cls-abs7dhqw-config get pod -o wide -n ctsdbi-5p0zhq7y | grep -E ‘gateway’ | awk ‘{print $1}’ | while read pod; do
echo $pod
kubectl --kubeconfig=cls-abs7dhqw-config exec $pod -n ctsdbi-5p0zhq7y – /bin/bash -c “cd /xstor/data/log; cat gateway.debug..log | awk -F’,’ '{ key=$5; sub(/[,],[,]*,[,],[,]*,[,],/, “”); value=$0; count[key]++; size[key]+=length(value); total+=length(value) } END { for (key in count) print count[key], size[key], key }'”
done | awk ‘{ count[$3]+=$1; size[$3]+=$2; total+=$2 } END { for (key in count) print count[key], size[key], size[key]*100/total “%”, key }’ | sort -k2nr | head -n 50
cat gateway.debug..log | awk -F’,’ '{ key=$5; sub(/[,],[,]*,[,],[,]*,[,],/, “”); value=$0; count[key]++; size[key]+=length(value); total+=length(value) } END { for (key in count) print count[key], size[key], size[key]*100/total “%”, key }’ | sort -k2nr | head -n 50
LogReducer
系统性分析日志影响,原因
日志本身并不是零成本的记录,其生命周期包含:
- Write log: 每当执行流达到日志语句时,服务都会将日志持续写入日志文件,包含字符串构造,拷贝等;
- Scrape log: log agent 会持续从日志文件中获取文件
- Send log: log agent 将日志通过网络发送到外部系统
- Store log: 部分系统为了安全,会全量存储日志,这里存在存储开销
从生命周期中,我们可以得出结论,日志不仅会影响存储成本,还会在写日志时消耗资源(如 CPU),在发送日志时消耗网络带宽。
文章在对微信2w个以上的微服务进行分析,发现其中20个微服务占用了52.8%以上的存储空间,文章前半部分主要基于这五个问题进行分析:
- RQ1: How do log hotspots impact storage?
- RQ2: How do log hotspots impact runtime?
- RQ3: What are the root causes of log hotspots?
- RQ4: What are the fixing solutions of log hotspots?
- RQ5: How long do developers take to fix log hotspots?
答案如下:
- storage impact
Finding:日志热点普遍存在于不同的服务中。少数日志热点平均占用了相应存储空间的 57.86%。
Implication:减少日志热点对降低存储开销具有成本效益。 - runtime impact
Finding:日志热点会导致无法控制的资源消耗(如 CPU、内存、IO 和网络 带宽)和性能下降。
Implication:减少日志热点不仅能优化应用程序的资源消耗,还能提高其性能。 - root causes
Finding:在所有根本原因中,最常见的两个根本原因是日志级别不正确和忘记测试日志,共占 63.15%。这里具体事项可以看原文。
Implication:不同服务的根本原因有共同点,了解这些根本原因有助于减少日志热点的发生。 - fixing solutions
Finding:在解决方案中,最常见的两种修复解决方案是更正日志级别和删除日志语句,共占 61.69%。
Implication:开发人员可以从历史解决方案中获益,这些解决方案不仅能加快修复速度,还能在开发阶段防止出现日志热点。 - fix log hotspots spending time
Finding: 对于 97% 的日志热点,开发人员至少需要 3 天,平均需要 9 天来修复。修复历史热点后,19 项服务中有 18 项会遇到新的日志热点。
Implication: 自动填补生产环境中日志热点检测和修复之间的空白时间是非常重要和必要的,这其实映射出需要在线修复,但是以目前我们的运营来看问题不大,因为这是一个已知事件,而且我们的日志没有全量存储到外部系统,所以ROI不是很高
在线日志缩减框架
文章提到这里的设计有如下四个难点:
- 海量日志。微信每天产生约 75-100 万亿行日志。这种方法必须足够快,才能在不影响应用程序性能的情况下处理如此大量的日志。
- 无需开发人员费力。日志减少方法对开发人员应该是透明的,不应给开发人员带来额外负担。
- 多种程序语言。微信包含由不同团队使用不同编程语言开发的 20,000 多种服务。日志缩减方法应兼容多种语言。
- 在线生产环境。微信在生产环境中为数十亿用户提供服务。为避免影响服务质量,应即时启用日志缩减方法,而不是重启服务。
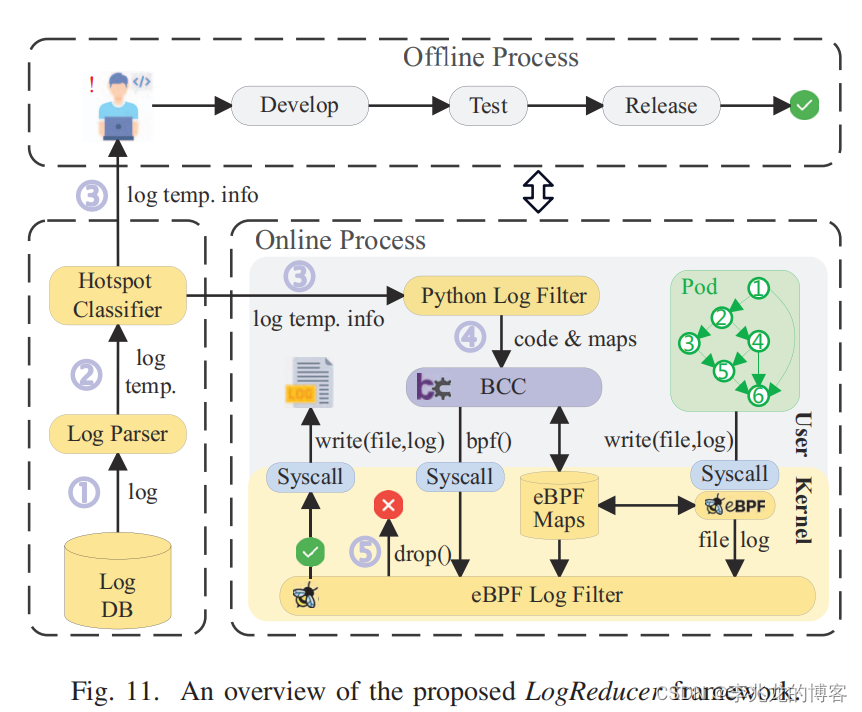
最终的框架看起来像是这样子,原理如下:
- Log Parser:定期从日志数据库中查询服务日志,并将原始日志解析为日志模板;
- Hotspot Classifier:根据日志模板的存储信息判断服务是否包含日志热点;
- 如果存在日志热点,Hotspot Classifier:会触发离线和在线流程的日志缩减过程。在离线过程中,LogReducer 会通知服务的开发人员,以修复热点的根本原因
- 在在线流程中,Python Log Filter 会将 eBPF 代码和日志模板信息加载到内核空间,这里的流程就是获取此进程所有打开的fd,分别获取其日志文件名称,如果写入的fd和这些fd相同,则进入过滤逻辑,执行模版过滤,这里我觉得都没有模版的必要,直接日志文件+行数完事;
- 当服务实例试图将日志写入文件时,eBPF Log Filter 会拦截 write() 系统调用,如果截获的日志内容与日志热点的日志模板相匹配,LogReducer 就会将其丢弃。
这里到这里大家都会有一个疑问,为什么过滤不放在用户态?当然这样需要每个语言都适配,但是这样就节省了一次系统调用。文中给出的测试结果是内核态比用户态更高效,结论是:
This is because when filtering hotspots in user space, all raw logs must be copied from kernel space to user space, which is extremely taxing on the time and CPU.

我不能理解这个结论,因为原则上这个过滤的过程完全可以放在用户态日志框架中,存在数量级的性能差异一定是实现有问题。
但是问题也不大,因为这个东西工程上的解决方案一定是靠改代码和灰度,在线修改hook wirte,风险过高,其次收益较小,而且要求系统适配eBPF,基本不太可能大范围推广,但是申请个专利,发个论文还是没问题的。
反省
这篇文章思路并不难,但是仍然发表在软件工程顶会上,这个问题于我个人而言无法被解决吗?从编码难度上讲我毕设的eBPF程序比这个难的多。从问题的角度讲,日志热点的问题在我们的日常运营中非常常见,无论是之前的KV还是现在的时序,但是没有人想到要去把这件事情真正的当作项目去做。
一方面可以认为这是工程和学术的区别,工程师在业务增长阶段更愿意投身ROI较高的产品和模块,通常忽略这些对性能没有直接较大影响的模块。另一方面可以认为是缺乏提出问题的能力,从目前计算机业务所涉及的知识来看,能提出问题多半是可以解决问题的。
在去年的时候因为降本增效,对象存储曾做过日志成本缩减,我当时还在负责对象存储索引层,所以可以说我既有解决这个问题的能力,也有遇到问题的场景,缺的就是体系化的看待每一件事情,这是一个需要长期自我鞭策改变的事情。
总结
这篇文章是二月十八号凌晨四点半我在机场等飞机前一小时加上飞机上一小时快速通读完成,逞着还有余力,遂迅速在下午把文章中的思路应用到我们的系统,立马发现了很多日志热点,这个优化也将成为下一个版本的一个重点。
提到这篇文章,LogReducer事实上是我在看谭神的年终总结是偶然发现的,事实上我和谭神的职业起点职责,方向,时间点都相似,希望能紧跟着谭神的脚步,至少三年后回看这几年不至于被落的太远。
参考:
- LogReducer: Identify and Reduce Log Hotspots in Kernel on the Fly ICSE 2023
- 2023 年终总结:从清华 Apache IoTDB 组到创业公司天谋科技
- eBPF: 深入探究 Map 类型
- https://github.com/IntelligentDDS/LogReducer
- 在bpfTrace中使用USDT
这篇关于从一到无穷大 #24 LogReducer:讨论日志中热点的影响,识别及在线解决方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





