本文主要是介绍VLP、多模态图文任务(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
图文检索、视觉问答(VQA)和图像描述和可以说是文献中最广泛研究的三个图文任务。它们要求AI系统理解输入图像和文本内容。受到语言模型预训练的巨大成功的启发,再加上NLP和CV社区中使用的体系结构的统一,对于开发用于图文任务的VLP方法产生了激增的研究兴趣。具体而言,将大量的图像-标题对输入到同时处理图像和文本的模型中进行预训练,以获得编码丰富的多模态知识并有助于下游任务。
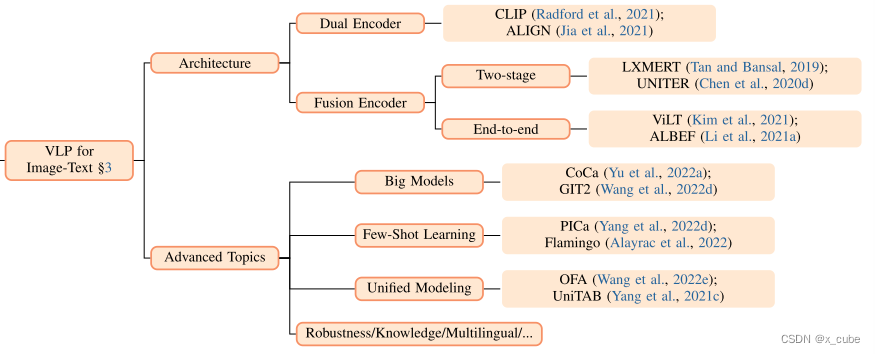
多模态图文任务介绍如下,分为3篇文章介绍。其中123在本文介绍。45分别一篇文章介绍。
- 概述了代表性的VLP模型,并将其分为几个类别。
- 描述了用于VLP的基于Transformer的模型体系结构,并从多个方面解析模型设计,包括图像编码器、文本编码器、多模态融合等等。
- 常用的预训练目标。
- 图文任务实例代码介绍。
- 列举了一些高级研究课题,包括基础模型、多模态少样本学习、统一VL建模、VLP知识、鲁棒性评估、模型压缩等等。
1. VLP模型概述
我们将VLP方法大致分为两类:
(i) 双编码器(dual encoder)和 (ii) 融合编码器(fusion encoder)。
1.1 双编码器(dual encoder)
对于双编码器,图像和文本分别进行编码,模态交互仅通过图像和文本特征向量之间的点积(如余弦相似性)进行处理。这种模型架构对于图像检索任务非常有效。当进行扩展时,可以通过大规模对比预训练从零开始学习一个强大的图像编码器。如CLIP 和 ALIGN 。然而,由于缺乏深度的多模态融合,CLIP 在VQA和视觉推理任务上表现较差。
1.2 融合编码器(fusion encoder)
对于融合编码器,除了使用图像编码器和文本编码器之外,通常还会使用额外的Transformer层来建模图像和文本表示之间的深度交互。主要的例子包括UNITER 、VinVL 、SimVLM 和 METER 。
优点:这种融合编码器架构在VQA和图像描述任务上实现了卓越的性能,
缺点:但是在应用于图像检索时效果非常低效,因为需要对所有可能的图像-文本对(匹配或不匹配)进行编码,以计算排名的相似性分数。
最近的研究,例如ALBEF 、UFO 和VLMo ,还表明可以将双编码器和融合编码器的设计封装到一个框架中,使得模型既适用于快速图像检索,又可用于VQA和图像描述任务。
在基于融合编码器的方法中,根据模型是否可以进行端到端预训练,我们进一步将其分为两类。这种分类也大致反映了VLP方法随时间演变的方式。具体而言,大多数早期的VLP方法,采用两阶段的预训练流程,首先从预训练的目标检测器中提取图像区域特征。最近,端到端预训练方法变得流行起来,其中图像特征可以从卷积神经网络(CNN)、视觉Transformer(ViTs)或仅使用图像块嵌入提取,并且模型梯度可以反向传播到视觉骨干网络进行端到端训练。端到端的VLP方法在所有主要的VL任务上取得了新的最先进水平。


1.2.1 基于目标检测器的VLP模型:
早期的方法使用预训练的OD来提取视觉特征。其中,ViLBERT和LXMERT使用协同注意力进行多模态融合,其中分别对区域特征和文本特征应用两个Transformer,并在后期阶段通过另一个Transformer融合两种模态的表示。

另一方面,VisualBERT、Unicoder-VL、VL-BERT和UNITER使用融合注意力模块将区域特征和文本特征输入到单个Transformer中。OSCAR将额外的图像标签输入到Transformer模型中,而VinVL则使用更强大的预训练目标检测器进行特征提取,并在VL任务中展示了最先进的性能。

一方面,区域特征是对象级别和语义丰富的;另一方面,提取区域特征可能耗时,并且预训练的目标检测器通常在预训练期间被冻结,这可能限制了VLP模型的容量。
1.2.2 端到端的VLP模型:
研究人员尝试以端到端的方式预训练VL模型的不同方法。具体而言,我们根据对图像进行编码的方式将其进一步分为两个子类。
-
基于CNN的网格特征。PixelBERT和CLIP-ViL直接将来自CNN的网格特征和文本直接输入到Transformer中。SOHO首先使用学习到的视觉词典对网格特征进行离散化,然后将离散化特征输入到跨模态模块中。虽然直接使用网格特征可以高效,但通常需要使用不一致的优化器来处理CNN和Transformer。例如,PixelBERT和CLIP-ViL分别使用AdamW优化Transformer和SGD优化CNN。
-
基于ViT的图像块特征。近年来,视觉Transformer(ViTs)成为CV中一个越来越活跃的研究主题。其中,ViLT直接将图像块特征和文本标记嵌入输入到预训练的ViT模型中,然后在图像-文本数据集上对模型进行预训练。ViTCAP进一步扩展了ViLT用于图像描述任务。这也带来了后续的工作,如UFO和VLMo。其中,UFO使用相同的Transformer同时进行图像/文本编码和多模态融合,而VLMo则包括额外的多模态专家层。此外,visual parsing、ALBEF、METER、BLIP、X-VLM和FIBER都使用ViT作为图像编码器(如普通的ViT和Swin Transformer),并为模型预训练设计了不同的目标。


1.3 研究进展

现在,我们以VQA任务为案例研究,来说明大规模VLP推动的研究进展。
- 从2017年8月到2019年8月,许多任务特定的方法被开发出来,包括使用以对象为中心的视觉特征、先进的注意力机制设计、对象关系建模以及Transformer的应用等。相应的VQA准确度从约66%提升到约71%。
- 从2019年8月到2021年8月,视觉-语言预训练(VLP)成为主流趋势。它首先从基于OD的VLP模型开始,将VQA准确度从约71%提升到约78%;然后基于卷积网络和视觉Transformer的端到端VLP方法主导了领域。
- 从2021年8月到2022年8月,我们目睹了大规模多模态基础模型的蓬勃发展,例如SimVLM、Florence、Flamingo、CoCa、GIT和BEiT-3。当这些模型在模型大小和预训练数据集大小两方面进行扩展时,VQA的性能进一步提升,从约80%提升到约84%。
2. 模型框架
给定一对图像和文本,VL模型首先通过文本编码器和视觉编码器提取文本特征和视觉特征
。这里,N是句子中的标记数,M是图像的视觉特征数,可以是图像区域/网格/补丁的数量,具体取决于所使用的特定视觉编码器。然后,将文本和视觉特征提供给多模态融合模块,生成跨模态表示,然后可选地将其馈送到解码器中,生成最终的输出。该通用框架的示意图如图所示:

在许多情况下,图像/文本骨干、多模态融合模块和解码器之间没有明确的界限。在本文中,我们将仅接收图像/文本特征作为输入的模型部分称为相应的视觉/文本编码器,将同时接收图像和文本特征作为输入的模型部分称为多模态融合模块。此外,如果还有其他模块将多模态特征作为输入生成输出,我们称之为解码器。
2.1 视觉编码器
有三种类型的视觉编码器:
(i)目标检测器(OD)
(ii)普通的卷积神经网络(CNN)
(iii)视觉Transformer
OD:
在VL研究中,最广泛使用的目标检测器是Faster R-CNN,在Visual Genome(VG)数据集上进行了预训练,如BUTD所示。在VinVL中,基于ResNeXt-152 C4架构的更强大的OD模型被预训练于多个公共OD数据集(包括COCO、OpenImages、Objects365和VG),通过使用这种更强大的OD模型,观察到了在广泛的VL任务中显著的性能提升。还采取额外的措施对图像区域的位置信息进行编码,通常表示为7维向量。然后将视觉特征和位置特征馈送到全连接层,以投影到相同的嵌入空间。每个区域的最终嵌入是通过将两个FC输出相加,然后通过一个层归一化层来获取的。

论文地址:Faster r-cnn: Towards real-time object detection with region proposal networks
CNN:
在PixelBERT和SOHO中,采用了从ImageNet分类中预训练的ResNet-50、ResNet-101和ResNeXt-152。在CLIP-ViL中,使用从CLIP中预训练的ResNet-50、ResNet-101和ResNet-50x4。在SimVLM中,他们分别使用ResNet-101和ResNet-152的前三个块(不包括Conv stem)作为基础模型和大模型,并且使用通道更多的ResNet-152的大型变种作为巨型模型。通常观察到,更强大的CNN骨干网络会导致更强大的下游性能。
ViT:
首先将图像划分为图像块,然后将其展平为向量并进行线性投影,以获取patch embeddings。学习可训练的特殊标记[CLS]的嵌入也被添加到序列之前。这些patch embeddings与可学习的一维位置嵌入和一个潜在的图像类型嵌入一起,被送入多层Transformer块以获得最终的输出图像特征。已经研究了不同的ViT变体用于VLP,例如纯ViT,DeiT,BEiT,Swin Transformer和CLIP-ViT。
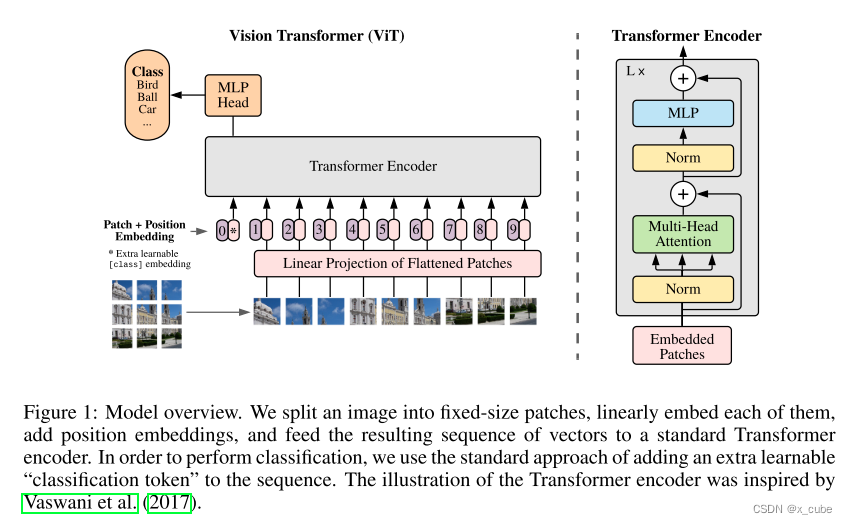
简而言之,无论使用何种视觉编码器,输入图像都被表示为一组特征向量 。
2.2 文本编码器
在BERT和RoBERTa之后,VLP模型首先将输入句子分段为一系列子词,然后在句子的开头和结尾插入两个特殊标记以生成输入文本序列。在获取文本嵌入(text embeddings)之后,现有的工作要么直接将其输入到多模态融合模块,要么在融合之前将其输入到几个文本特定的层。对于前者,融合模块通常使用BERT进行初始化,因此文本编码和多模态融合的作用在单个BERT模型中相互交织和吸收,在这种情况下,我们将文本编码器视为词嵌入层。
语言模型(LM)预训练在各种任务上都取得了令人印象深刻的性能,并且提出了不同的预训练LM。在METER中,作者研究了使用BERT、RoBERTa、ELECTRA、ALBERT和DeBERTa进行文本编码。在Flamingo中,使用了具有70B参数的巨型预训练LM作为文本编码器,并在VLP过程中保持冻结以进行多模态少样本学习。
简而言之,无论使用何种文本编码器,输入文本都被表示为一组特征向量 。


2.3 多模态融合
对于像CLIP和ALIGN这样的双编码器,融合是通过图像和文本特征向量之间的点积来实现的。对于融合编码器,它同时接收 和
作为输入,并学习到上下文的多模态表示,用
和
表示。 主要有两种类型的融合模块,即co-attention和merged attention,双流模式和单流模式。如图:

-
单流模式(merged attention)文本特征和视觉特征被简单地连接在一起,然后输入到一个单独的Transformer块中。单流架构通过合并注意力来融合多模态输入,通常也被叫做 merged attention。单流架构的参数效率更高,因为两种模式都使用相同的参数集。
-
双流模式(co-attention)是指视觉和文本编码特征没有组合在一起,而是独立输入到两个不同的 Transformer 块,这两个 Transformer 块不共享参数,而是通过交叉注意力实现跨模态交互,因此也被叫做 co-attention。
对于基于区域的VLP模型,co-attention模块和merged-attention模块可以实现相当的性能。然而,merged-attention模块在参数效率上更高,因为相同的参数集被用于两种模态。对于端到端的VLP模型,如METER所示,co-attention表现更好。然而,目前没有定论认为哪种模块更好,这在模型设计中很大程度上是一种经验选择。在mPLUG中,co-attention模块和merged-attention模块的组合被用于多模态融合。而在BLIP和FIBER中,则通过简单地在图像和文本骨干网络中插入跨注意力模块来进行融合,这可能更加轻量高效。在MLP-ViL中,作者研究了使用MLP架构进行多模态融合的方法。
2.4 讨论:共享骨干的统一建模
Transformer现已成为通用的计算引擎。在UFO中,作者试图使用相同的Transformer共享骨干进行图像/文本编码和多模态融合。在MS-CLIP和VATT中,也使用相同的共享骨干进行对比预训练,跨多模态应用。在VLMo中,进一步添加了混合模态专家层,而相同的自注意力层被用于图像/文本编码和多模态融合。这种专家混合设计在多个视觉-语言任务中取得了良好的性能。
2.5 编码器-解码器 vs 仅编码器

大多数VLP模型采用仅编码器架构,将跨模态表示直接输入基于MLP的输出层生成最终输出。这种仅编码器设计自然适合VQA和视觉推理等VL理解任务。在用于图像字幕生成时,同一个编码器充当解码器,通过使用因果掩码逐个生成输出标记的字幕。
在NLP领域的T5和BART的启发下,VL-T5、OFA、DaVinci 提倡使用基于Transformer的编码器-解码器架构,首先将跨模态表示输入解码器,然后再进入输出层。在这些模型中,解码器同时关注编码器的表示和先前生成的标记,自回归地生成输出。编码器-解码器架构的使用可以实现各种图像-文本任务的统一化,并且适用于零/少样本学习的VLP模型,也是生成任务的自然选择。在MDETR中,作者也采用了编码器-解码器架构,但解码器被设计为并行生成边界框,遵循DETRE的开创性工作。
3 预训练对象
现在,我们介绍如何设计预训练任务。首先,我们将回顾掩码语言建模(MLM)和图像-文本匹配(ITM),这两者几乎在每个VLP模型中广泛使用。然后,我们将把重点转移到图像-文本对比(ITC)学习和各种掩码图像建模(MIM)任务上。
3.1 Masked Language Modeling (MLM)
在VLP中,与图像-文本对一起使用的MLM也被证明是有用的。在MLM中,给定一个图像-文本对,我们随机地以15%的概率掩盖输入的单词,并用特殊标记[MASK]替换被掩盖的单词。目标是基于其周围的单词
![]() 和配对图像
和配对图像来预测这些掩码标记,通过最小化负对数似然:
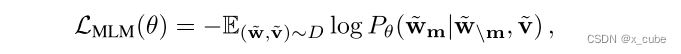
其中θ表示可训练参数。每个配对(,
)是从整个训练集D中抽样的。在VLP中使用了几种MLM变体。
- Seq-MLM:为了使预训练模型适应图像解释生成,观察到在预训期间添加一个seq2seq因果掩码是有益的。也就是说,在Seq-MLM中,模型仅能使用其前面的上下文来预测掩码标记,这与模型在推理过程中执行图像解释生成的方式一致。
- LM:BLIP和CoCa在VLP中使用直接语言建模。模型根据图像逐个标记地自回归地预测图像说明。
- Prefix-LM:在SimVLM中采用编码器-解码器框架,提出了一种PrefixLM预训练目标。首先将一句话分成两部分,对前缀序列和输入图像启用双向注意力,同时在剩余的标记上采用因果注意力掩码。
3.2 Masked Image Modeling (MIM)
类似于MLM目标,研究人员已经研究了各种用于预训练的遮蔽图像建模(MIM)任务。具体而言,该模型被训练用于根据剩余的可见图块-m或区域和所有的词
来重建被遮蔽的图块或区域

MIM的设计可以分为两类。
3.2.1 对于基于OD的VLP模型
例如LXMERT和UNITER,其中一些输入区域被随机遮蔽(即,被遮蔽区域的视觉特征被替换为零),模型通过最小化均方差损失来回归原始区域特征。研究人员还尝试首先使用预训练的对象检测器为每个区域生成对象标签,这些标签可以包含高层次的语义信息,然后模型被训练用于预测遮蔽区域的对象标签而不是原始区域特征。
3.2.2 对于端到端的VLP模型
例如ViLT和METER,研究人员已经研究了使用遮蔽图块回归/分类进行遮蔽图像建模的方法。具体而言,
- 对于具有离散VQ标记的MIM,在BEiT的启发下,首先提取输入图块的离散VQ标记,然后训练模型以重构离散标记。具体而言,首先使用DALL-E中的VQ-VAE模型将每个图像分解为一系列离散标记。然后,调整图像大小,使得图块的数量等于标记的数量,因此每个补丁对应一个离散标记。然后,我们随机遮蔽15%的图块,并像之前一样将遮蔽的图块输入模型,但现在模型被训练用于预测离散标记而不是遮蔽的图块。
- 对于具有批内负样本的MIM,通过模仿使用文本词汇的MLM,使用由批内负样本构建的动态词汇表,模型被训练用于通过重构输入补丁来选择原始补丁。具体而言,在每个训练步骤中,我们采样一个图像-标题对的批次
,其中B为批次大小。我们将{vk}B k=1中的所有补丁视为候选图块。对于每个遮蔽的图块,我们遮蔽输入补丁的15%。模型需要从候选补丁集合中选择原始图块。模型被训练以最大化其概率,类似于噪声对比估计。
值得注意的是,最近的最先进的VLP模型(例如VinVL,ALBEF,VLMo)在预训练期间不使用MIM,并且在ViLT和METER中,作者还证明MIM对下游性能并不有帮助。然而,也有最近的研究采用了遮蔽的视觉语言建模(如MaskVLM和VL-BEiT),尝试在保持其他模态完整的同时随机遮蔽补丁/标记。
3.3 Image-Text Matching (ITM)
在ITM中,给定一批匹配或不匹配的图像-说明对,模型需要识别哪些图像和说明相对应。大多数VLP模型将图像-文本匹配视为二元分类问题。具体而言,将一个特殊标记(即[CLS])附加在输入句子的开头以学习全局跨模态表示。然后,我们将模型分别使用匹配或不匹配的图像字幕对作为输入,每种情况的概率相等,对[CLS]标记顶部添加一个分类器来预测一个二元标签y,指示采样的图像说明是否匹配。具体而言,将输出得分表示为
,我们应用二元交叉熵损失进行优化:

除了随机采样负的图像-文本对之外,还可以通过下面介绍的图像-文本对比损失来挖掘更难的负对。据报道,在ALBEF,VLMo和FIBER中,这种方法已被证明在提高下游性能方面是有效的。
3.4 Image-Text Contrastive Learning (ITC)
早期的VLP模型,如UNITER和VinVL,在预训练阶段并未使用ITC(一个例外是Light-ningDOT)。虽然在VLP之前广泛研究了ITC损失,但在端到端VLP的背景下,它主要由CLIP和ALIGN用于预训练双编码器。随后,它也被用于像ALBEF中那样预训练融合编码器。请注意,在多模态融合之前(即使用w和v,而不是),此ITC损失是应用于图像和文本编码器的输出上。具体来说,给定一个大小为N的图像-文本对批次,ITC旨在从所有可能的N2个图像-文本对中预测N个匹配对。为了计算图像到文本和文本到图像的相似性,我们有:
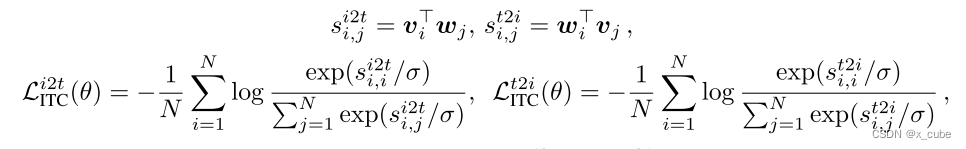
其中,σ是一个学习得到的温度超参数,i2t和t2i 分别是图像到文本和文本到图像的对比损失。可以通过三重对比学习(TCL),多模态可学习码本(CODIS)或ITC和ITM之间的循环交互(LoopITR)来进一步增强ITC损失。
ITM和ITC的异同
-
图文匹配(Image-Text Matching):
- 目标:图文匹配任务旨在判断给定的图像和文本是否相匹配,即图像和文本是否表达了相同的语义含义或话题。
- 示例:给定一张图像和一个描述,模型需要判断描述是否准确地描述了图像内容。
- 损失函数:通常使用交叉熵损失来计算模型对于图文匹配任务的预测结果与真实标签之间的差异。
- 应用:图文匹配任务可以应用于图像标注、图像搜索等场景,通过将图像和文本之间建立良好的匹配关系,提升模型在多模态理解任务上的性能。
-
图文对比学习(Image-Text Contrastive Learning):
- 目标:图文对比学习任务旨在让模型学习将图像和文本表示映射到共享的向量空间中,并使得相匹配的图像和文本在该空间中更接近,而不匹配的图像和文本则更远离。
- 示例:给定一对图像和文本,模型需要通过学习将它们映射到相应的向量表示,使得匹配的图像和文本对在向量空间中距离更近,而不匹配的图像和文本对距离更远。
- 损失函数:常用的损失函数包括对比损失(contrastive loss)和三元组损失(triplet loss),用于衡量模型对于相同类别的样本对之间的距离要小于不同类别的样本对之间的距离。
- 应用:图文对比学习任务可以应用于图像检索、零样本图像分类等场景,通过学习图像和文本在共享向量空间中的表示,实现多模态信息的对齐和相似性度量。
综上所述,图文匹配和图文对比学习都是VLP中用于训练模型的任务形式,但目标和损失函数的设计不同,分别关注于图像和文本之间的匹配关系和相似性度量。
3.5 Other Pre-training Tasks
除了上面介绍的典型预训练任务外,研究人员还探索了其他可能性。例如:
- UNITER提出了一种单词-区域对齐目标,试图使用最优传输来对齐图像和文本特征。
- 在E2E-VLP,MDETR,GLIP和X-VLM中,从目标检测中进行边界框预测和短语定位直接用作细粒度的预训练任务。
参考文献:
Vision-Language Pre-training: Basics, Recent Advances, and Future Trends
LXMERT: Learning Cross-Modality Encoder Representations from Transformers 2019
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks 2019
UNITER: Universal image-text representation learning
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 2021
这篇关于VLP、多模态图文任务(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







