本文主要是介绍WDK李宏毅学习笔记第十三周01_Anomaly Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Anomaly Detection(异常侦测)
文章目录
- Anomaly Detection(异常侦测)
- 摘要
- 1、Anomaly Detection简介
- 1.1 Problem Formulation
- 1.2 What is Anomaly?
- 1.3 Applications
- 2、Anomaly Detection做法
- 2.1 Binary Classification
- 2.2 Categories
- 2.3 With Classifier(有label的data)
- 2.3.1 做法
- 2.3.2 衡量model level的方法
- 2.4 Possible Issues
- 2.5 Without label(无label的data)
- 2.5.1 做法
- 2.5.2 Outlook: Auto-encoder
- 方法
- 结论
摘要
本章要讲的是让机器更深层次的认识自己,做到”知之为知之,不知为不知“,该技术常用于Anomaly Detection。Anomaly Detection的方法主要分为两大类,一类的有监督的Anomaly Detection,另一类是无监督的Anomaly Detection。前者是在Classifier的Model上引入Confidence score,设置Confidence score的阈值来决定输入数据是否异常,后者常用的方法是在Gaussian Distribution引入Confidence score。1、Anomaly Detection简介
1.1 Problem Formulation
首先给model一些训练数据,我们需要的是找到一个function,该function可以区分与训练数据不同的数据,例如,当input data与训练数据相似时,输出normal,不像则输出anomaly。如此,就有两个关键问题,第一:怎样的数据才是similar? 第二:怎样的数据是anomaly的? 将在后面说明这两个问题的解决办法。

1.2 What is Anomaly?
以宝可梦举例,假如training data是很多雷丘,那么比卡丘是anomaly。当training data是比卡丘,那么雷丘是anomaly。当training data是宝可梦,则数码宝贝是anomaly。

1.3 Applications
Anomaly Detection在实际生活中有很多重要的应用,如欺诈侦测、网络系统的入侵侦测、癌细胞侦测。

2、Anomaly Detection做法
2.1 Binary Classification
一个很直觉的方法就是Binary Classification,它是收集很多正常的资料和异常的资料,将正常的资料标记为class 1,异常资料作为class 2,然后machine就进行分类model的训练。

但是它的缺点也是直觉的,也就是通常异常资料是数量太多,没法全部收集用来训练的,例如当正常资料是宝可梦,那么不是宝可梦的资料都是异常的,这时异常资料已经多到不可能全部收集了。

2.2 Categories
为了方便理解,我们将Anomaly Detection的方法分为如下两类。
- 所有training data都有其对应的label,我们可用这些data训练一个classifier,但是在training data里,并没有Unknown的类别,所以如果需要machine能够识别异常数据,需要Open-set Recognition让machine识别异常。
- 所有training data都没有label,当input新的data时,我们需要machine能够辨别这些data和training data是否相似。这里又可以分为两类,一类是training data中没有混杂异常资料,是干净的,一类是training data中混杂着异常资料,是被污染的。
2.3 With Classifier(有label的data)
2.3.1 做法
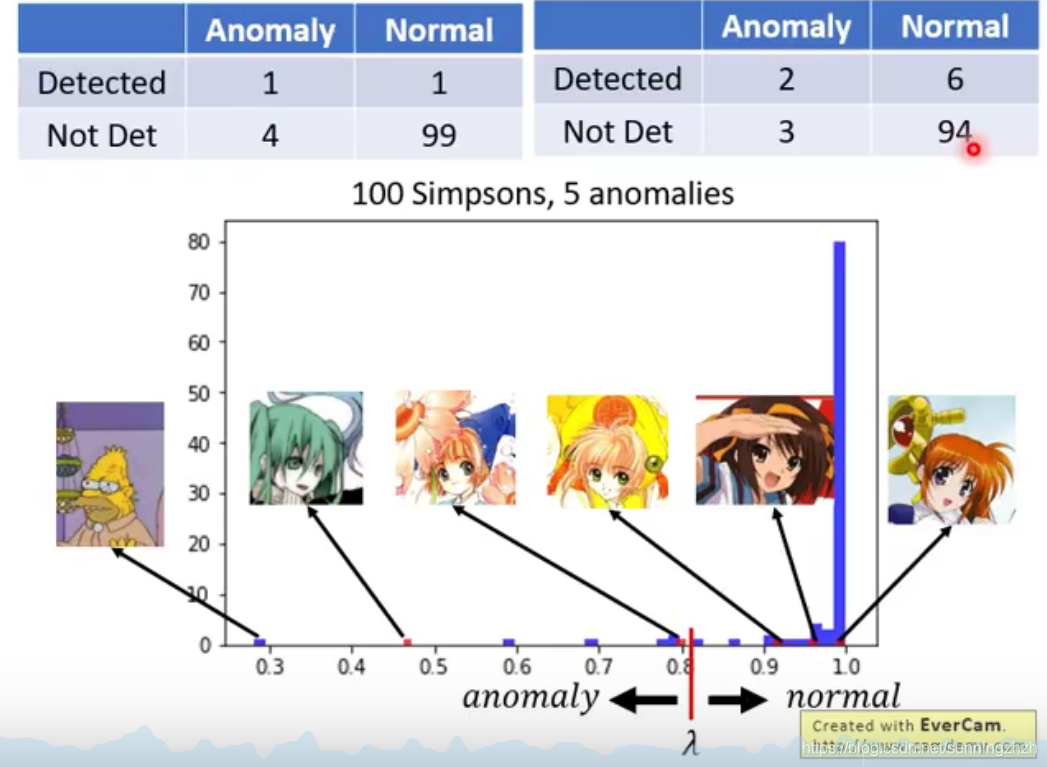
我们假设说我们收集了很多辛普森家庭的人物,且他们都有其对应的label。然后用这些data训练一个classifier。

现在该classifier可以进行分类的任务了,但是我们希望该classifier不仅能完成分类的任务,还可以进行异常侦测,这要怎么做?我们可以让machine在分类的同时输出其对该答案是正确的信心分数,设置信心分数的阈值进行异常侦测。

那如何得到信心分数?这个是很直觉的,因为分类model在进行分类时的输出都是一个分布,我们只需将该分布的最大值输出。

2.3.2 衡量model level的方法
我们现在已经有训练集,可以用其训练model,但是model的好坏需要怎样衡量?我们可以设置验证集,验证集中有正常资料,也有异常资料,将其输入到训练好model,看其输出的正确程度,就可知道model的好坏了。

如何计算model在验证集上的正确程度?一般都是用正确率来衡量model的好坏,但是在异常侦测中,用正确率衡量model的好坏是不行的。例如下图,将阈值λ设置在0.3时,这时model将所有的5个异常资料判断成正常的,这时如果计算model的正确率有0.952,正确率很高,但明显该系统并不好。

我们可以分析,model出错总共分为两类,一类是将异常的资料认为是正常的,一类是将正常的资料误认为是异常的。这时候我们就设置不同的阈值λ得到不同的分布矩阵。我们可以根据不同的问题,来设置不同的权重来给model打分。
2.4 Possible Issues
用Classifier做分类还是有一些问题的,例如当我们在做猫狗分类时,machine会因为老虎有猫的特征,狼有狗的特征而认为其是正常的。

有两个解决办法如下:
- machine在做分类的同时还要学会打分,当看到正常资料时,confidence score就高,看到异常资料时,confidence score就低。但是该方法存在一个问题就是很多时候是没法收集很多的异常的资料。
- 在第一个方法的基础上,learning一个生产器model来自己产生异常的资料,产生的异常资料最好是和正常资料有相似点的资料,这样可以加强机器的辨别能力。
2.5 Without label(无label的data)
2.5.1 做法
用一个probability density function sample所有的data, function中的参数θ决定function的形状,machine要自己学出最好的θ使得sample的数据几率最大。

一个常用的probability density function 就是Gaussian Distribution。

2.5.2 Outlook: Auto-encoder
该方法采用的是Encoder-Decoder框架,它是将所有的training data通过Encoder编码为code,然后通过Decoder还原出原来的图片,希望还原的图片与原图片越接近越好。在testing时,当输入异常图片时,因为其和training图片特征不同,所以机器在还原时,没法很好的抓住其关键特征,导致还原度不够高,以此来辨别该图片是异常的。

方法
- Binary Classification是有监督的Anomaly Detection,它是将正常资料分为一类,异常资料分为一类,然后训练一个分类器,以此实现Anomaly Detection。
- With Classifier是有监督的Anomaly Detection,它是在Classifier的基础上,引入Confidence score,让机器知道自己答案的可信度,设置Confidence score阈值,从而实现异常检测。
- Gaussian Distribution的异常侦测是无监督的Anomaly Detection,它和With Classifier的方法相似,不同点在于它是在Gaussian Distribution的分类器上引入Confidence score。
- Auto-encoder是无监督的Anomaly Detection,它的想法是用Encoder-Decoder 模型将Training data中的重要特征抓住,并以此来对数据进行降维,当异常数据输入时,model还会以同样的方法对数据进行降维,但如此降维后的数据将无法很好的还原出来,当还原度低于一定阈值时,machine就会知道该数据是异常的。
结论
通常情况下,异常资料是数量很多或者难以全面收集的,所以Binary Classification方法缺陷很大,使用局限性较大。With Classifier是一个不差的model,它得到的结果也是不差的,适用性也较广,但是它是线性的,当异常资料和正常资料有一定的相似性时,它是很容易误判的。Gaussian Distribution的异常侦测则可以较好的解决这个问题,而且还是无监督的。Auto-encoder则是比较新颖的异常侦测方法,但当训练数据本身类别很多时,该方法可能得不到好的结果。
这篇关于WDK李宏毅学习笔记第十三周01_Anomaly Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








