本文主要是介绍【机器学习PAI实战】—— 玩转人工智能之商品价格预测...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

【机器学习PAI实战】—— 玩转人工智能之商品价格预测
【机器学习PAI实战】—— 玩转人工智能之你最喜欢哪个男生?
【机器学习PAI实战】—— 玩转人工智能之美食推荐
前言
我们经常思考机器学习,深度学习,以至于人工智能给我们带来什么?在数据相对充足,足够真实的情况下,好的学习模型可以发现事件本身的内在规则,内在联系。我们去除冗余的信息,可以通过最少的特征构建最简单、误差最小的模型,以此将学习到的规则,逻辑应用到具体的场景中,帮助我们可以快速准确的处理某些繁琐重复的工作。
在本篇的案例中,我们将对回归模型做一次具体的分析和应用。回归可以做什么?与分类模型不同,分类模型的预测值是固定的,而回归模型可以预测连续型的数据结果。比如商品销量预测,商品价格预测等等。常用的回归模型包括线性回归,加权线性回归,岭回归以及树回归。在接下来的具体场景中,我们将分析上述的回归算法,选择最适合目前场景和已有数据的回归算法。
场景描述
某收藏爱好者,欲购买某知名品牌的积木套装。为了了解现在的市场行情,他收集了关于该品牌积木的生成日期,是否为全新的,积木数量,原始价格等特征和已交易的价格。他想要根据这些数据,来预估现在市场上正在出售的积木价格,才可以选择合适的价格购入,但他发现经凭借经验来预测这些价格,往往不够准确,而且繁琐重复的工作相当耗费精力。并且他了解到阿里PAI平台,可以通过智能的方法,针对具体场景快速搭建解决方案。但是自己的问题能不能被很好的解决,具体该怎么去实施还是一头雾水,下面就让我们伴随他一起走进阿里机器学习平台PAI的实战。
数据分析
在拿到收集到的数据之后,我们要先对数据进行简单的分析,来选择合适的算法。
price date number is_new origin_price
0 85.00 2006 797 0.0 49.99
1 102.50 2006 799 0.0 49.99
2 77.00 2006 795 0.0 49.99
3 162.50 2006 800 0.0 49.99
4 699.99 2002 3094 0.0 269.99
5 602.00 2002 3093 0.0 269.99
6 515.00 2002 3090 0.0 269.99
7 510.00 2002 3090 0.0 269.99
8 375.00 2002 3086 0.0 269.99
9 850.00 2002 3096 1.0 269.99
10 740.00 2002 3096 0.0 269.99
11 759.00 2002 3096 1.0 269.99
12 730.00 2002 3096 0.0 269.99
13 750.00 2002 3096 1.0 269.99
14 910.00 2007 5195 0.0 499.99
15 1199.99 2007 5195 1.0 499.99
16 811.88 2007 5194 0.0 499.99
17 1324.79 2007 5195 0.0 499.99
18 850.00 2007 5195 1.0 499.99
19 800.00 2007 5195 1.0 499.99
20 810.00 2007 5194 0.0 499.99
21 1075.00 2007 5195 1.0 499.99
22 1050.00 2007 5195 0.0 499.99
我们截取了部分数据,从第三列到第为列特征含义依次是生成年份,积木数量,是否为全新以及原价。第二列为收集到的已交易的价格。
- 数据类型
我们惊喜的发现,所有数据都是连续性的,而不是标称性数据。所谓连续型就是不可枚举,数值是联系可变的,而标称型数据就是几个固定的值,比如学生性别,手机型号,衣服尺码(L,XL,XXL)等。如果不是连续型数据,就需要做数据的量化处理。
- 数据特征分析
通过上面的部分数据,我们可以直观的看出下面信息。
1,年份和原价具有强相关性,换句话说年份和原价具有对等关系,这两个特征为重复特征,其包含的信息是一样的;2,是否为全新这个特征,是二值特征。不能表示商品的新旧程度。3,积木数量若存在缺失,将严重影响价格。4,收藏品价格会在一定程度上高于原价。
- 数据量
我们从这位收藏爱好者处了解到,其收集到的数据不足100条。希望的场景是,如果再给一组样本,可以快速的给出预测的价格。
场景抽象化
接下来,我们就需要把具体的问题抽象化。假设我们只用原价一个特征来预估商品价格。
price=f(origin_price)=w*origin_price+b
f(x)就是一种目标值的计算公式。w,b就是线性回归系数,一旦得到这些系数,再输入新的特征值(原价)就可以计算出商品的交易价格。如果输入特征为多维的即:
price=f(date,number,is_new,origin_price,)=w1*date+w2*number+w3*is_new+w4*origin_price+b
当然我们有策略选择哪些系数是最优的。在模型的学习和预测中,我们遇到带标签的数据,即已经知道交易价格的数据。通过这些标签值和我们预测值的比较来判断这组回归系数是不是最好的。
E=error(price-predicted_price)=||price-predicted_price||l
当这组系数在所有数据中误差为最小的,我们就可以说学习到了最优的参数来拟合训练数据。
模型选择
我们知道这个问题可以通过回归算法来解决,就兴致冲冲的打开了PAI 可视化建模页面进入了自己搭建的机器学习项目。进入方法如下:
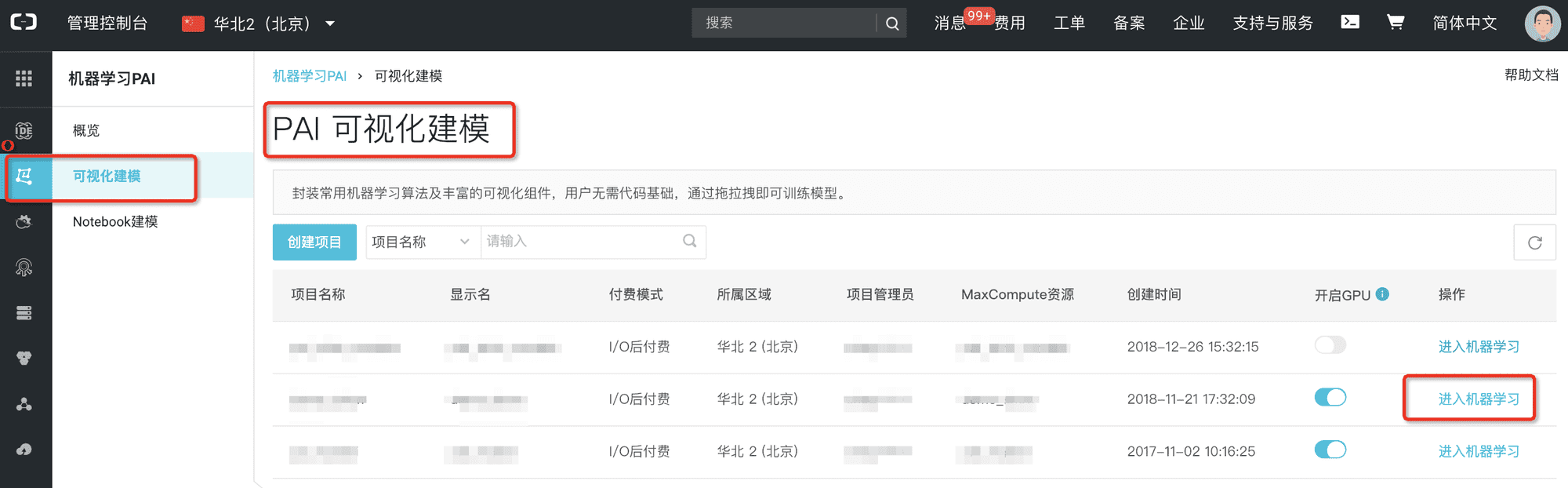
在组件栏发现有好多回归算法可以选择。

但是这么多算法该如何选择?
模型的选择绝大程度上依赖样本的特征,如果特征值与样本呈现明显的线性关系,我们就选择线性回归模型。比 如一本书的厚度和页码的关系。非线性回归的例子也有很多,比如圆形容器的蓄水量和容器的半径的关系。当然大多是非线性回归也可以转化成线性回归,这里就不细谈。
GBDT回归,是树回归的一种,可以解决线性和非线性回归问题。
AdaBoost回归是一种强化回归算法,AdaBoost是集成学习算法,可以将弱学习器强化为强学习器,可以应用在分类和回归算法。这里AdaBoost回归就是一种强化的集成回归算法。
PS-SMART,PS-线性回归,分别是基于PS是参数服务器(Parameter server)的GBDT算法和线性回归算法。主要用于大规模数据的学习预测任务。
针对上面样例,直观的发现,价格与特征呈明显的线性关系。我们可以选择线性回归作为尝试。
数据处理
在模型训练之前,需要对对训练数据进行预处理。主要包括类型的转化,量化,缺失值填充等等。现在我们有一份txt的格式的离线数据,内容样本如上所示。通过对数据的分析,现有数据不需要进行类型的转化和量化,可以进行缺失值的填充。在进入预处理之前,我们需要将训练样本放到odps表中。
- 首先,打开dataworks-数据开发,如下图所示,进入Dataworks 自己项目下的数据开发平台:
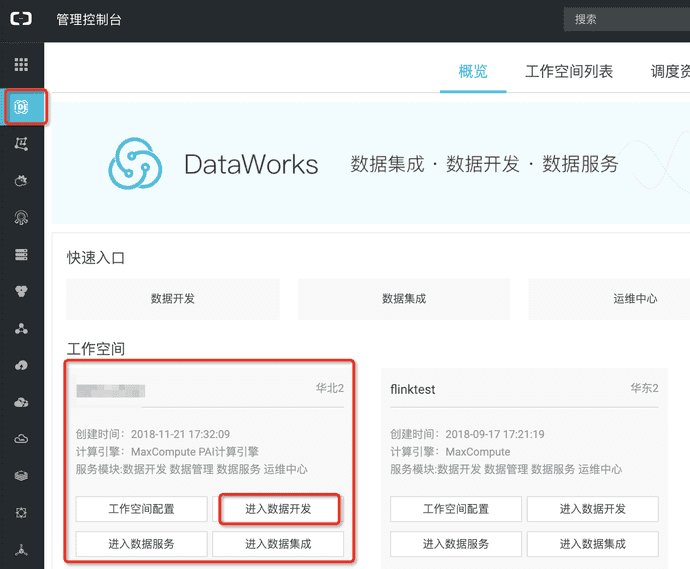
- 新建节点,输入下面代码,选中代码,点击运行按钮,新建odps表。
CREATE TABLE if not EXISTS item_features
(
price Double COMMENT "预测价格",
production_date BIGINT COMMENT "production_date",
quantity BIGINT COMMENT "数量",
is_new DOUBLE COMMENT "1:new,0:old",
original_price DOUBLE COMMENT "原价"
)
LIFECYCLE 7
;
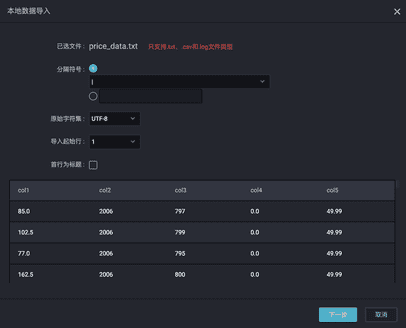
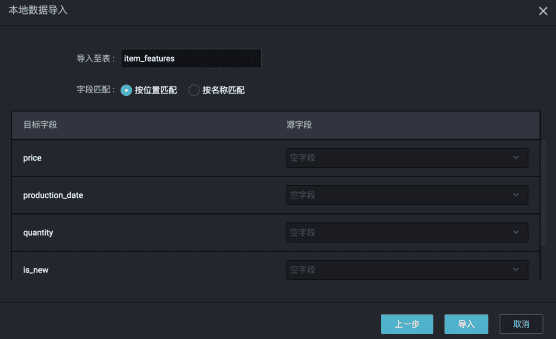
- 将本地数据导入到odps表中。
分隔符为本地文件的列之间的分隔符,默认为逗号。如果本地文件中第一行不是标题,则选择起始行为1,不勾选首行为标题。下一步,然后输入新建的odps表名,选择按位置匹配(只有前面选择首行为标题,才可以选择按名称匹配),然后导入。

至此,我们对数据有了充足的了解,知道选择何种模型,需要对数据做什么预处理,而且训练数据也已准备好了。接下来,我就需要在PAI 可视化建模页面,拖拽组件,搭建可视化训练流程。
模型训练
- 首先进入PAI 可视化建模页面,点击实验-新建空白实验。

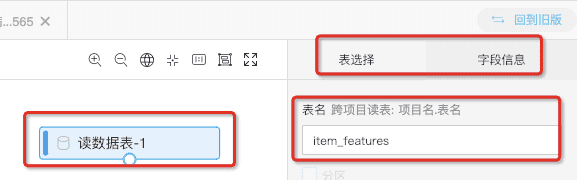
- 拖拽数据读取组件,源/目标-读数据表。
双击拖入的读数据表组件,再表名列输入,前面新建的odps表名。可以在字段信息栏看到表中部分数据。
- 拖入缺省值填充组件,数据预处理-缺失值填充。
训练数据中,可能存在部分特征值缺失的情况,缺失值填充可以选择多种测试填充缺失值。
在右侧属性栏,选择进行填充的参数,原值类型和填充值策略。

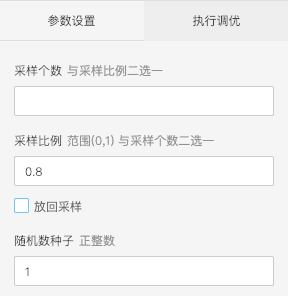
- 样本随机采样
对于所有的训练数据,我们可以有重叠的选择出训练集和测试集。拖入两个随机采样组件,数据预处理-采样与过滤-随机采样。字段参数设置如下图:

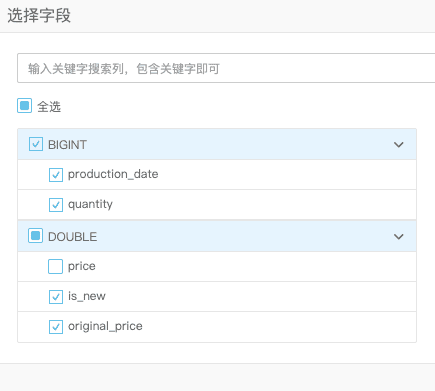
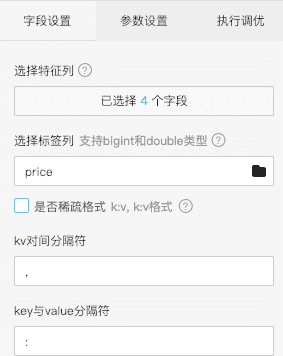
- 线性回归算法
拖入线性回归算法组件,机器学习-回归-线性回归。特征列选择 date number is_new origin_price特征,标签列为price。
至此,如下图所示,模型训练的流程已搭建完成。点击运行,就可以依托PAI平台服务,进行模型训练了。

模型测试
通过模型训练,学习得到了线性回归模型。在PAI平台上,我们可以一键拖拽测试组件,机器学习-预测。对学习到的模型就行测试,并可以直观的观测模型预测的结果。
如下图所示:


模型部署
详情参考在线部署使用说明。
- 查看模型
在线性回归模型组件,右键选择模型选项-查看模型,就可以看到学习到的模型。
- 保存模型
右键选择保存模型,就可以将模型保存到我的模型下。通过模型定位,就可以定位到我的模型处。
- 一键部署
模型训练完成之后,点击部署-在线部署。输入自定义的服务名称(全网唯一,调用服务时使用)。

在已部署模型页可以看到,自己部署的所有服务。
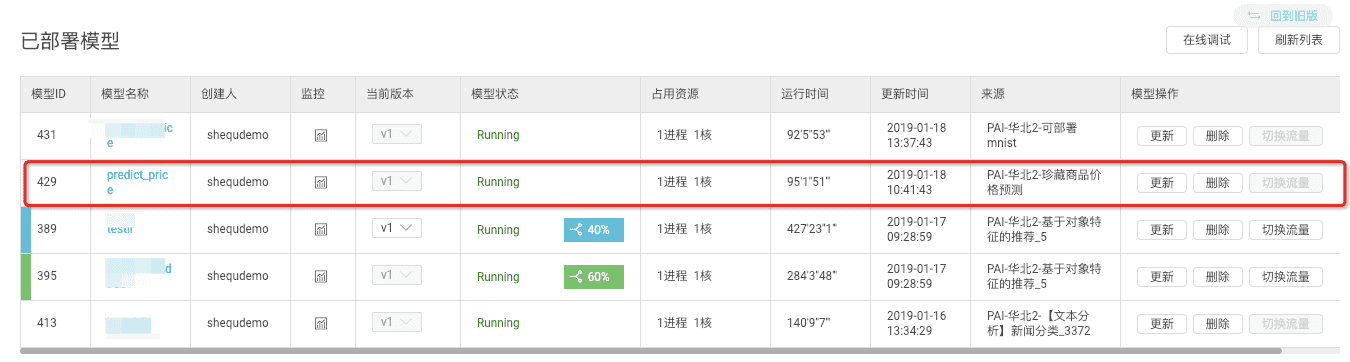
服务测试
详情参考在线部署使用说明。
注意事项,body参数要按照特征值的数量给出,每一条是一个字典,字段要和表结构一致,多条数据以数组形式添加。
总结
回归算法和分类算法类似,也是对目标值的预测。其中回归算法主要用于对联系值的预测,而分类算法预测的则是离散值。在PAI平台上有常用的各类回归算法,如果有兴趣,可以一一尝试,选择最适合自己场景和数据的回归算法。在接到一个具体的场景和问题后,通常我们需要一系列的步骤去解决这个问题,收集数据,准备数据,分析数据,算法选择,训练算法,测试算法,使用算法。同时,PAI平台中这些回归算法组件还支持部分算法参数的调整,比如迭代次数,最小误差,以及正则化系数等等,我们可以在训练算法模型中调整这些参数以达到最小可接受的误差。
人人用得起的机器学习平台↓↓↓↓

海量资源点击领取
更有kindle、技术图书抽奖活动,百分百中奖
这篇关于【机器学习PAI实战】—— 玩转人工智能之商品价格预测...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








