本文主要是介绍Apache Doris整体架构、FE元数据管理及数据组织,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1. Doris整体架构
2. FE 元数据管理
3. Doris数据组织
1. Doris整体架构
Doris主要分为FE和BE两个组件,FE主要负责查询的编译,分发和元数据管理(基于内存,类似HDFS NN);BE主要负责查询的执⾏和存储系统。
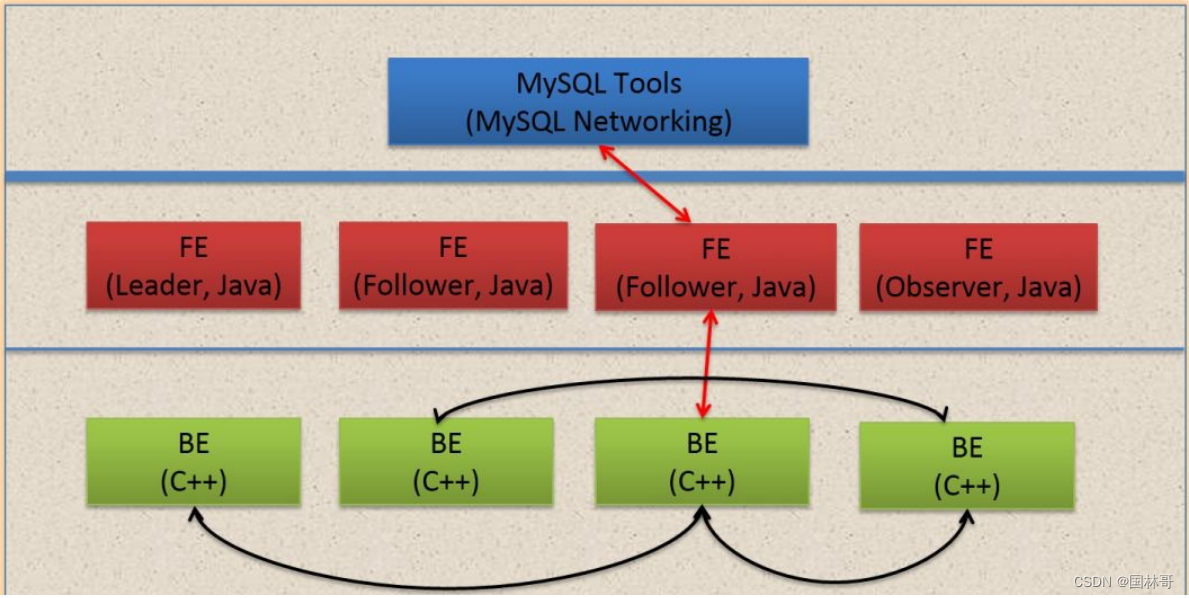
1、这张图是Doris的整体架构。Doris的架构很简洁,只设FE(Frontend)、BE(Backend)两种⾓⾊、两个进程,不依赖于外部组件,⽅便 部署和运维。
2、以数据存储的⾓度观之,FE存储、维护集群元数据;BE存储物理数据。
3、以查询处理的⾓度观之, FE节点接收、解析查询请求,规划查询计划,调度查询执⾏,返回查询结果;BE节点依据FE⽣成的物理计划, 分布式地执⾏查询。
4、FE主要有有三个⾓⾊,⼀个是leader,⼀个是follower,还有⼀个observer。leader跟follower,主要是⽤来达到元数据的⾼可⽤,保证单节点宕机的情况下,元数据能够实时地在线恢复,⽽不影响整个服务。
5、右边observer只是⽤来扩展查询节点,就是说如果在发现集群压⼒⾮常⼤的情况下,需要去扩展整个查询的能⼒,那么可以加 observer的节点。observer不参与任何的写⼊,只参与读取。
2. FE 元数据管理
元数据层⾯,Doris采⽤Paxos协议以及Memory + Checkpoint + Journal的机制来确保元数据的⾼性能及⾼可靠。
元数据的每次更新,都⾸先写⼊到磁盘的⽇志⽂件中(WAL溢⾎⽇志),然后再写到内存中,最后定期checkpoint到本地磁盘上。相当于是⼀个纯内存的⼀个结构,也就是说所有的元数据都会缓存在内存之中,从⽽保证FE在宕机后能够快速恢复元数据,⽽且不丢失元数据。
Leader、follower和 observer它们三个构成⼀个可靠的服务,这样如果发⽣节点宕机的情况,在百度内部⼀般是部署⼀个leader两个follower,外部公司⽬前来说基本上也是这么部署的。就是说三个节点去达到⼀个⾼可⽤服务。
单机的节点故障时基本上三个就够了,因为FE节点只存了⼀份元数据,它的压⼒不⼤,所以如果FE太多的时候它会去消耗机器资源, 所以多数情况下三个就⾜够了,可以达到⼀个很⾼可⽤的元数据服务。

3. Doris数据组织
数据主要存储在BE⾥⾯,BE节点上物理数据的可靠性通过多副本来实现,默认是3副本,副本数可配置且可随时动态调整,满⾜不同可⽤性级别的业务需求。



这篇关于Apache Doris整体架构、FE元数据管理及数据组织的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






