本文主要是介绍Solr通过edismax提升评分并打印评分规则,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先看一下DisMax query parser的定义:
The DisMax query parser is designed to process simple phrases (without complex syntax) entered by users and to search for individual terms across several fields using different weighting (boosts) based on the significance of each field. Additional options enable users to influence the score based on rules specific to each use case
(independent of user input).
再看eDisMax(The Extended DisMax Query Parser)的定义:
The Extended DisMax (eDisMax) query parser is an improved version of the DisMax query parser,includes improved boost function: in Extended DisMax, the boost function is a multiplier rather than an addend, improving your boost results; the additive boost functions of DisMax (bf and bq) are also supported.
In addition to all the DisMax parameters, Extended DisMax includes these query parameters:
【The boost Parameter 】
A multivalued list of strings parsed as queries with scores multiplied by the score from the main query for all matching documents. This parameter is shorthand for wrapping the query produced by eDisMax using the BoostQParserPlugin
即通过boost参数可以在原有的评分基础上再乘以这个参数,该参数可以为某个field。
比如从Mysql中向solr导入以下数据:
+----+--------------------------------+--------+
| id | keyword | weight |
+----+--------------------------------+--------+
| 3 | 中国 | 1.0 |
| 4 | 美国人民 | 1.0 |
| 5 | 人民群众 | 1.0 |
| 6 | 美国人民 | 1.0 |
| 7 | 中国人民解放军 | 2.0 |
| 8 | 中国很好,美国也不错 | 10.0 |
| 9 | chinese people | 1.0 |
| 10 | my god, you are chinese | 1.0 |
| 11 | you are chinese people | 1.0 |
| 12 | 中国中国 | 1.0 |
+----+--------------------------------+--------+
在执行查询时,可以通过设置debugQuery来打印评分规则(可以在Raw Query Parameters中设置debugQuery=true或者直接勾选debugQuery如下图所示),
例如,不进行boost提分,直接查询关键词:
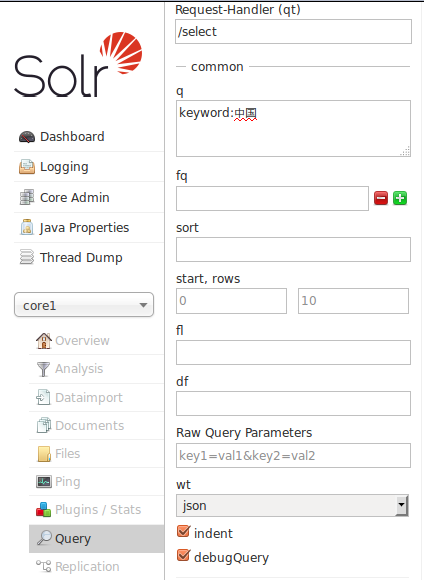
返回结果中的评分详情:
"debug": {
"rawquerystring": "keyword:中国",
"querystring": "keyword:中国",
"parsedquery": "(keyword:中国 keyword:china)/no_coord",
"parsedquery_toString": "keyword:中国 keyword:china",
"explain": {
"3": "\n0.7724356 = sum of:\n 0.7724356 = weight(keyword:中国 in 0) [ClassicSimilarity], result of:\n 0.7724356 = score(doc=0,freq=1.0), product of:\n 0.4562129 = queryWeight, product of:\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.2694467 = queryNorm\n 1.6931472 = fieldWeight in 0, product of:\n 1.0 = tf(freq=1.0), with freq of:\n 1.0 = termFreq=1.0\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 1.0 = fieldNorm(doc=0)\n",
"7": "\n0.24138615 = sum of:\n 0.24138615 = weight(keyword:中国 in 4) [ClassicSimilarity], result of:\n 0.24138615 = score(doc=4,freq=1.0), product of:\n 0.4562129 = queryWeight, product of:\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.2694467 = queryNorm\n 0.5291085 = fieldWeight in 4, product of:\n 1.0 = tf(freq=1.0), with freq of:\n 1.0 = termFreq=1.0\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.3125 = fieldNorm(doc=4)\n",
"8": "\n0.3862178 = sum of:\n 0.3862178 = weight(keyword:中国 in 5) [ClassicSimilarity], result of:\n 0.3862178 = score(doc=5,freq=1.0), product of:\n 0.4562129 = queryWeight, product of:\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.2694467 = queryNorm\n 0.8465736 = fieldWeight in 5, product of:\n 1.0 = tf(freq=1.0), with freq of:\n 1.0 = termFreq=1.0\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.5 = fieldNorm(doc=5)\n",
"12": "\n0.54619443 = sum of:\n 0.54619443 = weight(keyword:中国 in 9) [ClassicSimilarity], result of:\n 0.54619443 = score(doc=9,freq=2.0), product of:\n 0.4562129 = queryWeight, product of:\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.2694467 = queryNorm\n 1.1972358 = fieldWeight in 9, product of:\n 1.4142135 = tf(freq=2.0), with freq of:\n 2.0 = termFreq=2.0\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.5 = fieldNorm(doc=9)\n"
},
当设置 edismax query方式以及boost参数以后(本例中用weight 列作为要提分的权重,lucene的原始评分乘以这个权重为最终得分),如:
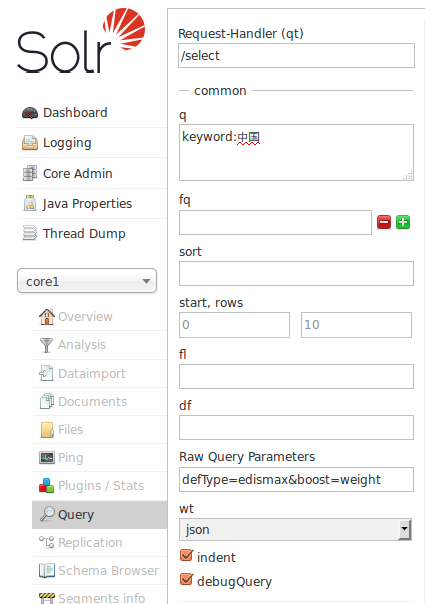
评分详情:
"debug": {
"rawquerystring": "keyword:中国",
"querystring": "keyword:中国",
"parsedquery": "BoostedQuery(boost(+(keyword:中国 keyword:china),float(weight)))",
"parsedquery_toString": "boost(+(keyword:中国 keyword:china),float(weight))",
"explain": {
"3": "\n0.7724356 = boost(keyword:中国 keyword:china,float(weight)), product of:\n 0.7724356 = sum of:\n 0.7724356 = weight(keyword:中国 in 0) [ClassicSimilarity], result of:\n 0.7724356 = score(doc=0,freq=1.0), product of:\n 0.4562129 = queryWeight, product of:\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.2694467 = queryNorm\n 1.6931472 = fieldWeight in 0, product of:\n 1.0 = tf(freq=1.0), with freq of:\n 1.0 = termFreq=1.0\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 1.0 = fieldNorm(doc=0)\n 1.0 = float(weight)=1.0\n",
"7": "\n0.4827723 = boost(keyword:中国 keyword:china,float(weight)), product of:\n 0.24138615 = sum of:\n 0.24138615 = weight(keyword:中国 in 4) [ClassicSimilarity], result of:\n 0.24138615 = score(doc=4,freq=1.0), product of:\n 0.4562129 = queryWeight, product of:\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.2694467 = queryNorm\n 0.5291085 = fieldWeight in 4, product of:\n 1.0 = tf(freq=1.0), with freq of:\n 1.0 = termFreq=1.0\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.3125 = fieldNorm(doc=4)\n 2.0 = float(weight)=2.0\n",
"8": "\n3.862178 = boost(keyword:中国 keyword:china,float(weight)), product of:\n 0.3862178 = sum of:\n 0.3862178 = weight(keyword:中国 in 5) [ClassicSimilarity], result of:\n 0.3862178 = score(doc=5,freq=1.0), product of:\n 0.4562129 = queryWeight, product of:\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.2694467 = queryNorm\n 0.8465736 = fieldWeight in 5, product of:\n 1.0 = tf(freq=1.0), with freq of:\n 1.0 = termFreq=1.0\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.5 = fieldNorm(doc=5)\n 10.0 = float(weight)=10.0\n",
"12": "\n0.54619443 = boost(keyword:中国 keyword:china,float(weight)), product of:\n 0.54619443 = sum of:\n 0.54619443 = weight(keyword:中国 in 9) [ClassicSimilarity], result of:\n 0.54619443 = score(doc=9,freq=2.0), product of:\n 0.4562129 = queryWeight, product of:\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.2694467 = queryNorm\n 1.1972358 = fieldWeight in 9, product of:\n 1.4142135 = tf(freq=2.0), with freq of:\n 2.0 = termFreq=2.0\n 1.6931472 = idf(docFreq=4, maxDocs=10)\n 0.5 = fieldNorm(doc=9)\n 1.0 = float(weight)=1.0\n"
},
可以看到id为7的记录其weight为2.0, 评分提升了两倍,id为8的记录其weight为10.0, 评分提升了10倍.
这篇关于Solr通过edismax提升评分并打印评分规则的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



