本文主要是介绍G2O优化构建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
g2o是一个通用的图优化库,可以应用到任何能够表示成图优化的最小二乘问题。例如BA,icp,曲线拟合等。
构建G2O优化器
构建G2O优化是一种图优化,所以需要准备顶点和边
顶点:待优化的变量(状态)
边:顶点之间的约束关系,常用误差表示
针对一个曲线拟合的问题
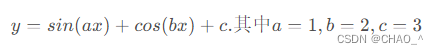
顶点为我们所需要求解的a,b,c,边就为预测值与观测值之间的差值。
定义顶点和边
顶点继承自g2o::BaseVertex,边继承自public g2o::BaseUnaryEdge
边有一元边,二元边和多元边,分别需要继承自
g2o::BaseUnaryEdge<D, E, VertexXi>
g2o::BaseBinaryEdge<D, E, VertexXi, VertexXj>
g2o::BaseMultiEdge<D, E>其中D表示误差值的维度,E表示测量值的数据类型,VertexXi表示连接顶点类型。
核心需要重载实现computeError函数,用于计算误差
一元边:

多元边:
边的误差计算
void computeError() override {const VertexParams *params = dynamic_cast<const VertexParams *>(vertex(0));//顶点const double &a = params->estimate()(0);const double &b = params->estimate()(1);const double &c = params->estimate()(2);// double fval = a * exp(-lambda * measurement()(0)) + b;double fval = sin(a * measurement()(0)) + cos(b * measurement()(0)) + c;_error(0) = std::abs(fval - measurement()(1));}配置优化器
定义优化器
选择优化算法
构建图(添加顶点和边)
添加顶点
添加顶点的时候,每个顶点为设置一个ID,在添加边的时候可以使用ID来查找顶点。
在添加顶点的时候,会设置一个初始估计值,后续的误差计算会拿出顶点的当前估计值参与运算
VertexParams *params = new VertexParams();
params->setId(0);
//设置初始值
params->setEstimate(Eigen::Vector3d(0.7, 2.4, 2));//初始化顶点的估计值
optimizer.addVertex(params);添加边
在添加边的时候会设置顶点和测量值。,一元边只需要设置一个顶点,二元边需要设置两个顶点。这一步设置的顶点,需要跟上一步添加的顶点一一对应起来,边添加完成后,顶点和边会构成一个图。顶点和测量值会在计算误差的时候参与运算。
for (int i = 0; i < numPoints; ++i) {EdgePointOnCurve *e = new EdgePointOnCurve;e->setInformation(Eigen::Matrix<double, 1, 1>::Identity());e->setVertex(0, params);e->setMeasurement(points[i]);optimizer.addEdge(e);
}执行优化
optimizer.initializeOptimization();optimizer.computeInitialGuess();optimizer.computeActiveErrors();optimizer.setVerbose(false);optimizer.optimize(maxIterations);雅各比矩阵
雅克比矩阵存储了误差项的每一维相对于顶点各优化成员的偏导数。
其中linearizeOplus()函数为计算雅各比矩阵的函数,对于非线性优化问题,雅各比矩阵的自动求导可以提高优化的速度。
这篇关于G2O优化构建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



