本文主要是介绍【datawhale202206】pyTorch推荐系统:精排模型 DeepFMDIN,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
小结
补充了推荐系统的相关背景知识,可以更好地理解本次所学习的两个模型:DeepFM和DIN在推荐系统中的作用(精排)。
随后学习了DeepFM和DIN两个模型的结构,理解模型的诞生背景或许是更加值得关注的。
DeepFM的大背景尝试让模型是学习更多的特征,来提升推荐模型的效果,创新点在于并行处理了FM和DNN,使得高低阶的特征更好地被结合和学习;
DIN的大背景是在累积了足够多的历史用户行为数据的应用场景,创新点是引入了注意力机制有针对性地处理历史用户行为数据。在DIN中,由于大背景与常规推荐系统任务不同(有大量用户历史行为数据),因此需要了解历史用户行为数据是如何在模型输入中被表示的,以及如何在模型及代码实现中处理(本身不等长-》multi-hot等长-》输入模型稠密后不等长-》代码实现时padding等长,mask标记)
目录
- 小结
- 0 rechub和推荐系统
- 0.1 rechub项目及安装
- 0.2 推荐系统
- 0.2.1 推荐系统是什么
- 0.2.2 推荐系统的算法框架
- 0.2.3 推荐系统的评价标准
- 1 DeepFM
- 1.1 模型诞生的背景
- 1.2 模型的结构(思考题2)
- 1.3 模型的代码实现
- 1.4 借助rechub实操
- 1.4.1 数据集介绍及特征工程
- 1.4.2 训练
- 2 DIN
- 2.1 模型诞生的背景
- 2.2 DIN模型结构及原理
- 2.2.1 论文原文用到的数据集及baseline模型
- 2.2.2 DIN模型架构
- 2.3 模型的代码实现
- 2.4 借助rechub实操
- 2.4.1 数据集介绍及特征工程
- 2.4.2 训练
- 参考材料
0 rechub和推荐系统
0.1 rechub项目及安装
rechub是一个聚焦复现业界实用的推荐模型,以及泛生态化的推荐场景的项目,目标是易用易拓展,项目地址
可以通过下面指令安装
#稳定版
pip install torch-rechub#最新版(推荐)
1. git clone https://github.com/datawhalechina/torch-rechub.git
2. cd torch-rechub
3. python setup.py install
本次在colab上配置环境,实现如下:
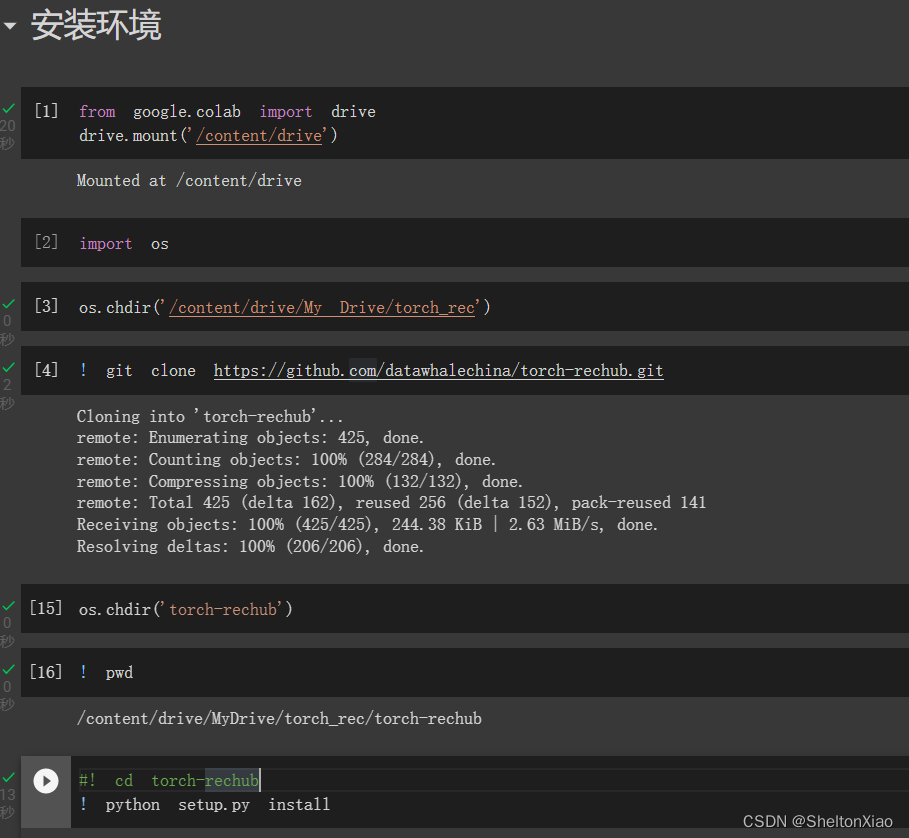
项目主页提供了更详细的介绍及使用的简单示例。
0.2 推荐系统
0.2.1 推荐系统是什么
在 推荐系统入门这篇博客中有蛮好的简单介绍。
推荐系统是一种 信息过滤系统,根据用户的历史行为、社交关系、兴趣点算法可以判断用户当前感兴趣的物品或内容。你也可以将它理解为一家只为你而开的商店。店铺里摆放的都是你需要的,或者适合你的商品。
实现推荐的方式分为:
- Content-based Filtering:给内容打标签,推荐相似的其他内容
- Collaborative Filtering:给用户打标签,根据相似用户的行为推荐
- Using data to solve problems:有了数据后实现,依然是分为内容和用户行为两个方面,分析data判断相似度,然后推荐solve problems
- 物品本身:Content-based 基于物品本身的内容,而不是用户购买/浏览物品的行为
- 用户行为:
显性反馈数据:用户明确表示对物品的喜欢行为:评分,喜欢,收藏,购买
隐性反馈数据:不能明确反映用户喜好的行为:浏览,停留时间,点击
0.2.2 推荐系统的算法框架
由于主要涉及的项目是推荐系统的算法模型,所以我们要熟悉的是推荐系统的算法架构,由召回,粗排,排序,重排等四个算法环节组成,下面这张图是一个简单的说明。
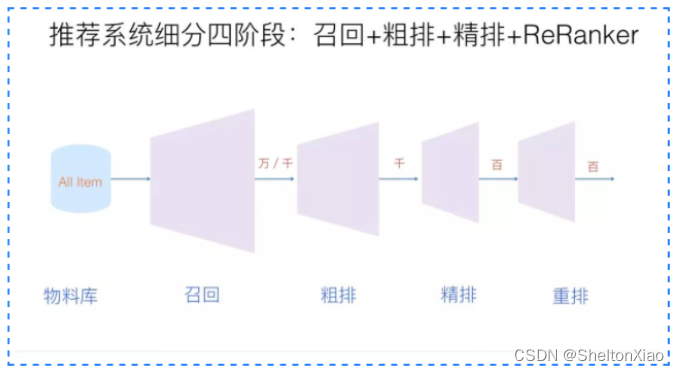
对应地,四个算法环节的功能可以简单理解为:
- 召回:可以理解为一个快速地筛选及形成值得注意的数据的过程,具体为实现从推荐池中选取几千上万的item,送给后续的排序模块;
- 粗排:可以理解为初步过滤计算,实现缩减精排层计算量的过程;
- 精排:获取粗排模块的结果,对候选集进行打分和排序。精排需要在最大时延允许的情况下,保证打分的精准性,是整个系统中至关重要的一个模块,也是最复杂,研究最多的一个模块。精排系统构建一般需要涉及样本、特征、模型三部分;
- 重排:根据具体的使用目的,对精排的结果进行微调;
- 混排:如果有多种数据源,在这里进行一个结合。
其中,对于上图中提到的物料库,显然它不会是以一个原始所有数据堆积的形式实现的,而是被整理为描述(用户/商品)画像的数据形式。一般推荐系统还会加入多模态的一个内容理解(包含文本理解,关键词标签,内容理解,知识图谱等)。
下图是微信看一看的内容画像框架,可以帮助理解物料库里放的到底是什么东西,从而对我们推荐算法所需要处理的数据有一个理解。
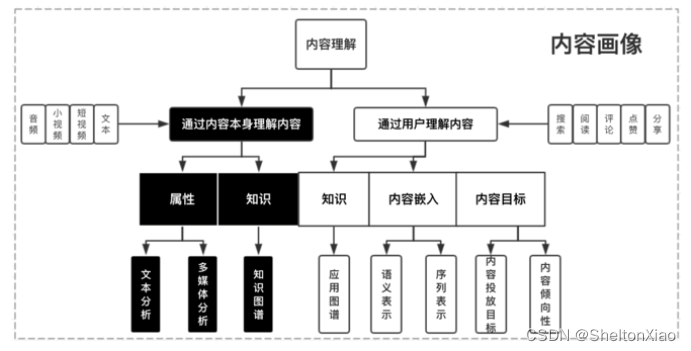
下面这段文字可以帮助我们更好地理解推荐算法在实际推荐系统中的作用,及我们需要关注的地方。
我们在入门学习推荐系统的时候,更加关注的是哪个模型AUC更高、topK效果好,哪个模型更加牛逼的问题,从基本的协同过滤到点击率预估算法,从深度学习到强化学习,学术界都始终走在最前列。一个推荐算法从出现到在业界得到广泛应用是一个长期的过程,因为在实际的生产系统中,首先需要保证的是稳定、实时地向用户提供推荐服务,在这个前提下才能追求推荐系统的效果。
算法架构的设计思想就是在实际的工业场景中,不管是用户维度、物品维度还是用户和物品的交互维度,数据都是极其丰富的,学术界对算法的使用方法不能照搬到工业界。当一个用户访问推荐模块时,系统不可能针对该用户对所有的物品进行排序,那么推荐系统是怎么解决的呢?对应的商品众多,如何决定将哪些商品展示给用户?对于排序好的商品,如何合理地展示给用户?
所以一个通用的算法架构,设计思想就是对数据层层建模,层层筛选,帮助用户从海量数据中找出其真正感兴趣的部分。
也就是说,对实际推荐系统而言,不是只需要做出一个简单的推荐算法模型就可以,因为会受到数据源质量及数量规模的限制和影响。因此,考虑可以利用合理的算法架构,筛选数据,然后最大化算法模型的效果。
而本次所涉及到的,是精排环节的模型。
精排层,也是我们学习推荐入门最常常接触的层,我们所熟悉的算法很大一部分都来自精排层。这一层的任务是获取粗排模块的结果,对候选集进行打分和排序。精排需要在最大时延允许的情况下,保证打分的精准性,是整个系统中至关重要的一个模块,也是最复杂,研究最多的一个模块。
精排是推荐系统各层级中最纯粹的一层,他的目标比较单一且集中,一门心思的实现目标的调优即可。最开始的时候精排模型的常见目标是ctr,后续逐渐发展了cvr等多类目标。精排和粗排层的基本目标是一致的,都是对商品集合进行排序,但是和粗排不同的是,精排只需要对少量的商品(即粗排输出的商品集合的topN)进行排序即可。因此,精排中可以使用比粗排更多的特征,更复杂的模型和更精细的策略(用户的特征和行为在该层的大量使用和参与也是基于这个原因)。
精排层模型是推荐系统中涵盖的研究方向最多,有非常多的子领域值得研究探索,这也是推荐系统中技术含量最高的部分,毕竟它是直接面对用户,产生的结果对用户影响最大的一层。目前精排层深度学习已经一统天下了,精排阶段采用的方案相对通用,首先一天的样本量是几十亿的级别,我们要解决的是样本规模的问题,尽量多的喂给模型去记忆,另一个方面时效性上,用户的反馈产生的时候,怎么尽快的把新的反馈给到模型里去,学到最新的知识。
0.2.3 推荐系统的评价标准
根据目的,推荐系统显然是具有有现实意义的评价标准的,当评价目标的定义有变化时,推荐结果也会发生变化。
评价目标包括但不限于下图(来源 推荐系统入门):

- 准确度:打分系统,top N推荐
- 覆盖率:对物品长尾的发掘能力
- 多样性:推荐列表中物品两两之间的不相似性
- 新颖度:给用户suprise
- 惊喜度:推荐和用户历史兴趣不相似,却满意的
- 信任度:提供可靠的推荐理由
- 实时性:实时更新程度
具体到评价标准,例子包括
- CTR:点击率(点击量/展示量)
- CVR:转化的情况,商家关注的指标(转化量/点击量)
- GPM:平均1000次展示,平均成交金额
- 等
根据场景需求进行选择。场景很多,包括(来源 推荐系统入门):

本次涉及的模型,均是面对CTR(点击率)的模型。
1 DeepFM
1.1 模型诞生的背景
对于CTR问题,被证明的最有效的提升任务表现的策略是特征组合(Feature Interaction),在CTR问题的探究历史上来看就是如何更好地学习特征组合,进而更加精确地描述数据的特点。
显然,随着特征组合的增多,会导致模型复杂度的爆炸,从而拖慢计算速度。而推荐系统的实际应用还有一个非常重要的要求是实时性,因此“如何高效地学习特征组合”成为一个很重要的问题。
DNN是很好地解决这一问题的方法,但也存在局限性:需要合理处理特征的表述形式,来防止维度猛增,在此基础上增加层数,可以实现高阶特征组合,但仍缺少低阶的特征组合。
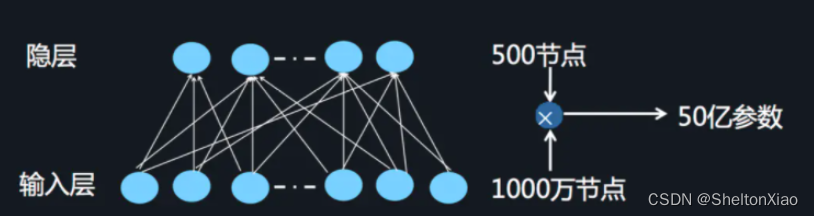
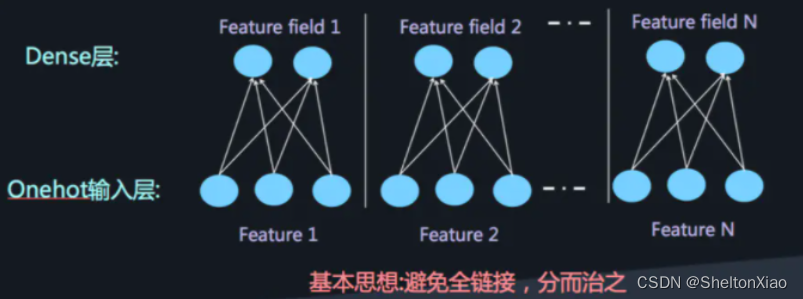
当我们使用DNN网络解决推荐问题的时候存在网络参数过于庞大的问题,这是因为在进行特征处理的时候我们需要使用one-hot编码来处理离散特征,这会导致输入的维度猛增。这里借用AI大会的一张图片:
这样庞大的参数量也是不实际的。为了解决DNN参数量过大的局限性,可以采用非常经典的Field思想,将OneHot特征转换为Dense Vector
此时通过增加全连接层就可以实现高阶的特征组合,如下图所示:
但是仍然缺少低阶的特征组合。
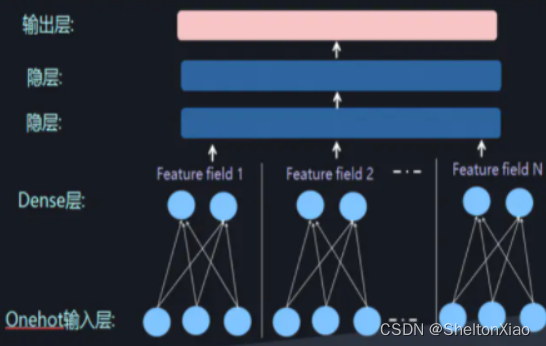
此时在DNN中引入FM来表示低阶特征组合,这就有了FNN(串行FM和DNN),和PNN(在FNN的基础上又串入了一个product层)。
结合FM和DNN其实有两种方式,可以并行结合也可以串行结合。这两种方式各有几种代表模型。在DeepFM之前有FNN,虽然在影响力上可能并不如DeepFM,但是了解FNN的思想对我们理解DeepFM的特点和优点是很有帮助的。
FNN是使用预训练好的FM模块,得到隐向量,然后把隐向量作为DNN的输入,但是经过实验进一步发现,在Embedding layer和hidden layer1之间增加一个product层(如上图所示)可以提高模型的表现,所以提出了PNN,使用product layer替换FM预训练层。
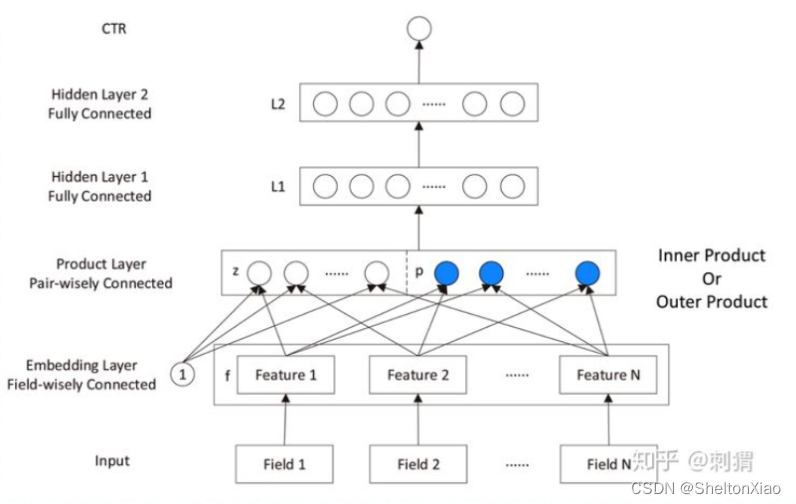
但是上述模型由于直接串行了FM和DNN,对低阶特征的学习还是不太够,所以又进化出了Wide&Deep模型(改串行为并行),由google提出(具体可以参考教程)。
FNN和PNN模型仍然有一个比较明显的尚未解决的缺点:对于低阶组合特征学习到的比较少,这一点主要是由于FM和DNN的串行方式导致的,也就是虽然FM学到了低阶特征组合,但是DNN的全连接结构导致低阶特征并不能在DNN的输出端较好的表现。
将串行方式改进为并行方式能比较好的解决这个问题。于是Google提出了Wide&Deep模型,但是如果深入探究Wide&Deep的构成方式,虽然将整个模型的结构调整为了并行结构,在实际的使用中Wide Module中的部分需要较为精巧的特征工程,换句话说人工处理对于模型的效果具有比较大的影响(这一点可以在Wide&Deep模型部分得到验证)。
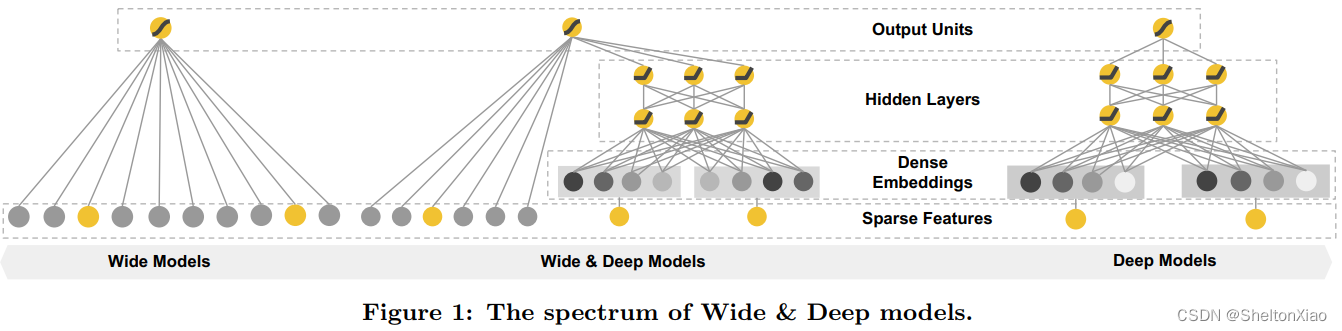
但是,简单的并行结合仍然存在问题,主要受限于特征的组合形式:
在output Units阶段直接将低阶和高阶特征进行组合,很容易让模型最终偏向学习到低阶或者高阶的特征,而不能做到很好的结合。
DeepFM就是在这个背景下诞生的,它试图解决高阶及低阶的良好结合问题。
1.2 模型的结构(思考题2)
先摆出一个模型图
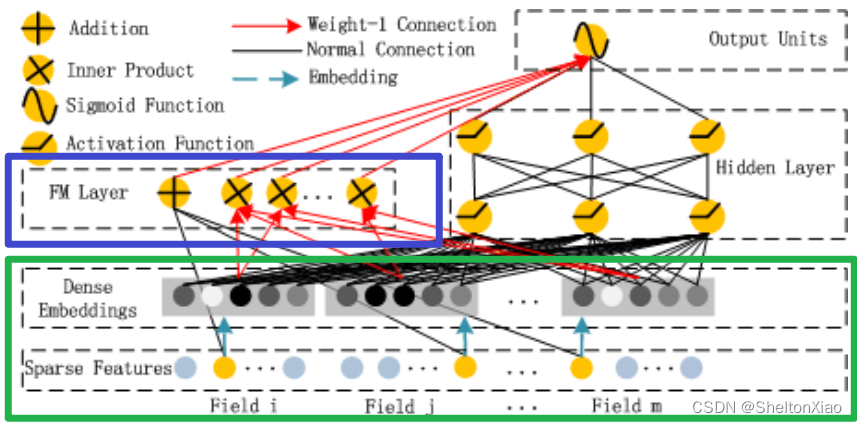
其中:前面的Field和Embedding处理是和前面的方法是相同的,如上图中的绿色部分;DeepFM将Wide部分替换为了FM layer如上图中的蓝色部分
教程中提示我们模型中有三个需要注意的地方:
-
Deep模型部分
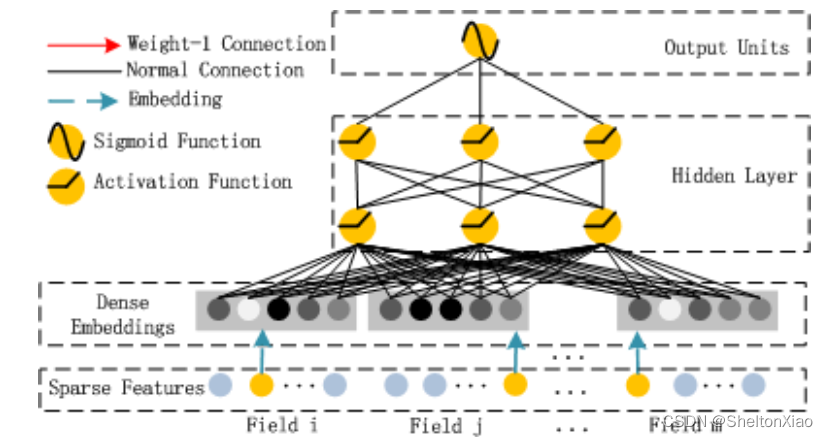
Deep Module是为了学习高阶的特征组合,使用用全连接的方式将Dense Embedding输入到Hidden Layer,这里面Dense Embeddings就是为了解决DNN中的参数爆炸问题,这也是推荐模型中常用的处理方法。Embedding层的输出是将所有id类特征对应的embedding向量concat到到一起输入到DNN中。
-
FM模型部分
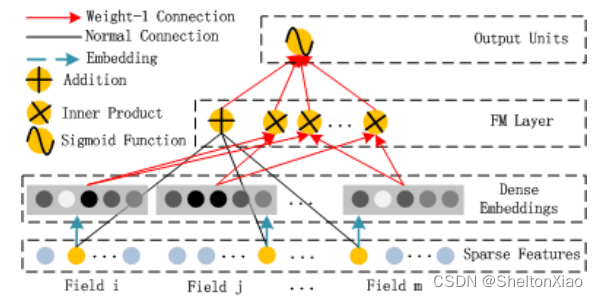
FM Layer是由一阶特征和二阶特征Concatenate到一起在经过一个Sigmoid得到logits。在实现的时候需要分开考虑。
-
Sparse Feature中黄色和灰色节点代表什么意思【思考题2】
在DeepFM模型的结构图中,Sparse Features中的黄色节点与模型连接,参与了训练,而灰色节点没有参与训练。
根据原论文,黄色节点代表输入的稀疏向量中数值为1的点,灰色节点代表数值为0的点,因为数值0输入模型中学习得到的权重也仍然为零,所以可以看作是不参与训练。
(Sparse Feature全部为需要dense的离散特征(类别型特征))
1.3 模型的代码实现
rechub中实现了DeepFM模型,整体模型架构如下:
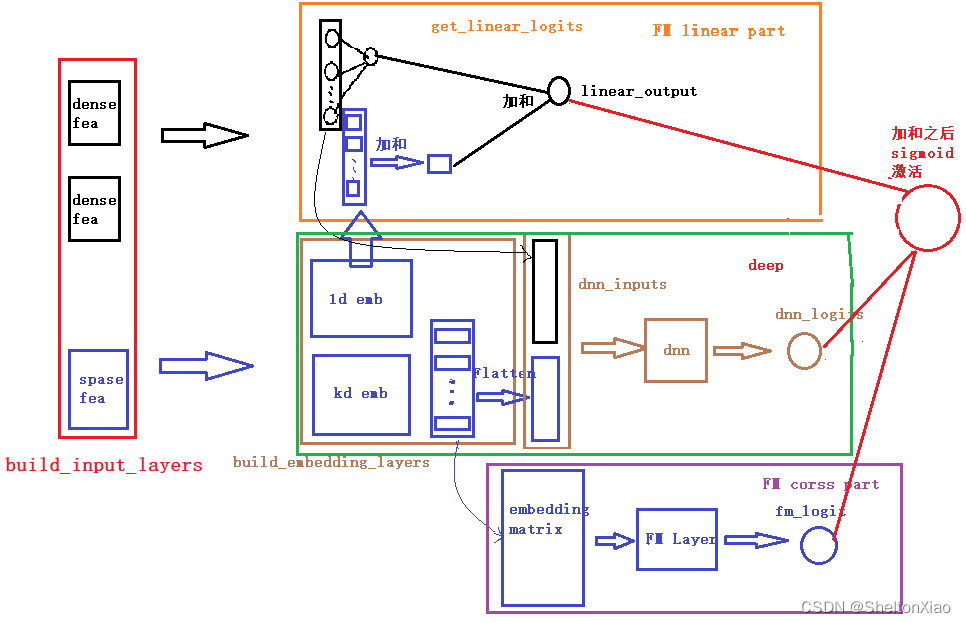
模型大致由两部分组成
- FM(进一步细分为一阶特征的处理和二阶特征的处理)
- DNN
因此实现细化为 - FM的线性特征处理
- FM的二阶特征交叉处理
- DNN的高阶特征交叉
在代码中也能够清晰的看到这个结构。此外每一部分可能由是由不同的特征组成,所以在构建模型的时候需要分别对这三部分输入的特征进行选择。
代码如下,更详细的代码见GitHub
def DeepFM(linear_feature_columns, dnn_feature_columns):# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embeddinglinear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logitslinear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型# embedding层用户构建FM交叉部分和DNN的输入部分embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)# 将输入到dnn中的所有sparse特征筛选出来dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))fm_logits = get_fm_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers) # 只考虑二阶项# 将所有的Embedding都拼起来,一起输入到dnn中dnn_logits = get_dnn_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)# 将linear,FM,dnn的logits相加作为最终的logitsoutput_logits = Add()([linear_logits, fm_logits, dnn_logits])# 这里的激活函数使用sigmoidoutput_layers = Activation("sigmoid")(output_logits)model = Model(input_layers, output_layers)return model
1.4 借助rechub实操
具体notebook代码见Torch-Rechub Tutorial: DeepFM
本文对应的colab文件见PyTorch推荐系统,相关的代码标注也包含在其中。
1.4.1 数据集介绍及特征工程
使用了Criteo Labs发布的在线广告数据集(数据集描述如下)
它包含数百万个展示广告的点击反馈记录,该数据可作为点击率(CTR)预测的基准。 数据集具有40个特征,第一列是标签,其中值1表示已点击广告,而值0表示未点击广告。 其他特征包含13个dense特征和26个sparse特征。
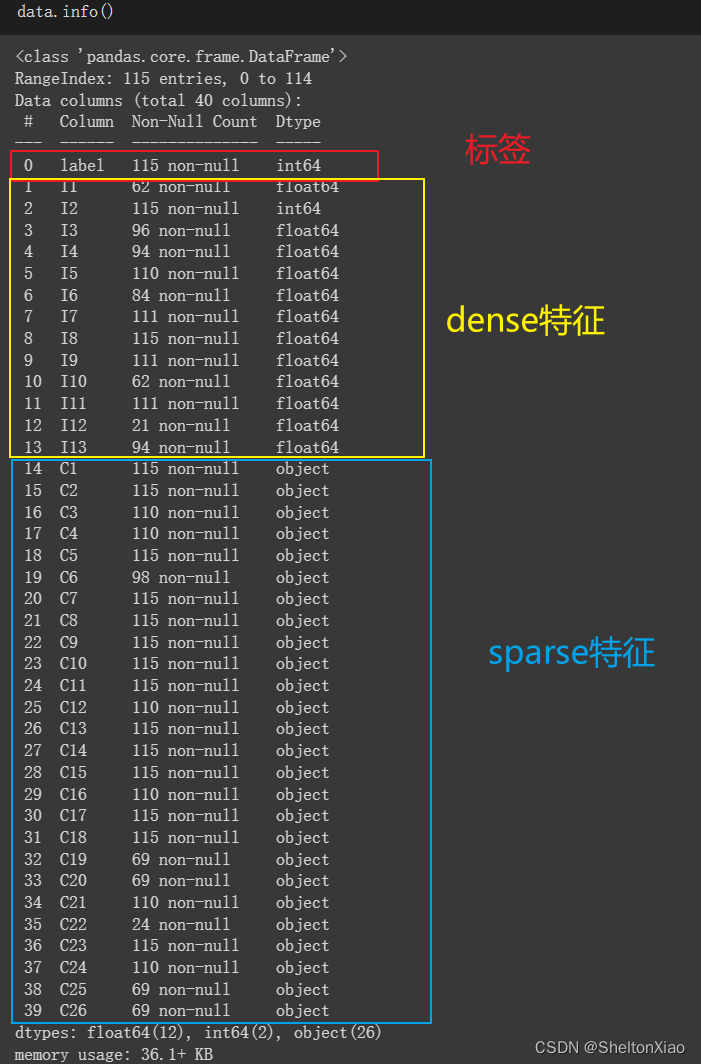
随后进行特征工程
对dense特征,分别进行两种操作:
- MinMaxScaler归一化
- 离散化为Sparse特征,*为什么要这么做,是受限于模型的能力吗?
这里用的是criteo比赛冠军分享的一种离散化思路
def convert_numeric_feature(val):v = int(val)if v > 2:return int(np.log(v)**2)else:return v - 2
对Sparse特征:
- 直接LabelEncoder编码,映射为数值,生成Embedding向量
再把他们转化为rechub对应好的Dence Feature和Sparse Feature形式(其实是个标记了,还是需要传入X的)。
重点:将每个特征定义为torch-rechub所支持的特征基类,dense特征只需指定特征名,sparse特征需指定特征名、特征取值个数(vocab_size)、embedding维度(embed_dim)
1.4.2 训练
定义rechub里头的DeepFM模型后,定义CTRTrainer确定workflow。
跑一个epoch效果如下
epoch: 0
train: 100%|██████████| 1/1 [00:00<00:00, 5.05it/s]
validation: 100%|██████████| 1/1 [00:00<00:00, 6.40it/s]
epoch: 0 validation: auc: 0.4583333333333333
validation: 100%|██████████| 1/1 [00:00<00:00, 6.15it/s]test auc: 0.2625
对比WideDeep模型的效果:
epoch: 0
train: 100%|██████████| 1/1 [00:00<00:00, 4.53it/s]
validation: 100%|██████████| 1/1 [00:00<00:00, 5.58it/s]
epoch: 0 validation: auc: 0.16666666666666666
validation: 100%|██████████| 1/1 [00:00<00:00, 6.13it/s]test auc: 0.6625
以及DCN模型的效果
epoch: 0
train: 100%|██████████| 1/1 [00:00<00:00, 5.30it/s]
validation: 100%|██████████| 1/1 [00:00<00:00, 6.15it/s]
epoch: 0 validation: auc: 0.29166666666666663
validation: 100%|██████████| 1/1 [00:00<00:00, 5.70it/s]test auc: 0.475
在validation上效果蛮好的,但是过拟合有点严重。
再跑4个epoch看看,效果如下:
| DeepFM | WideDeep | DCN | |
|---|---|---|---|
| best validation auc | 0.7083 | 0.625 | 0.4583 |
| test auc | 0.1 | 0.3125 | 0.1375 |
过拟合就还蛮严重的。
2 DIN
2.1 模型诞生的背景
Deep Interest Network(DIN)是2018年阿里巴巴提出来的模型, 该模型基于业务的观察,从实际应用的角度进行改进,相比于之前很多“学术风”的深度模型, 该模型更加具有业务气息。
该模型的应用场景是阿里巴巴的电商广告推荐业务, 这样的场景下一般会有大量的用户历史行为信息。DIN模型的创新点或者解决的问题就是使用了注意力机制来对用户的兴趣动态模拟。
DIN模型的创新点或者解决的问题就是使用了注意力机制来对用户的兴趣动态模拟, 而这个模拟过程存在的前提就是用户之前有大量的历史行为了,这样我们在预测某个商品广告用户是否点击的时候,就可以参考他之前购买过或者查看过的商品,这样就能猜测出用户的大致兴趣来,这样我们的推荐才能做的更加到位,所以这个模型的使用场景是非常注重用户的历史行为特征(历史购买过的商品或者类别信息),也希望通过这一点,能够和前面的一些深度学习模型对比一下。
其实简单来说,就是先前的模型对于有大量历史交互行为的问题,无法表达用户广泛的兴趣,若不加以注意力的考虑,会导致维度过多。
因为原来的模型在得到各个特征的embedding之后,就蛮力拼接了,然后就各种交叉等。这时候根本没有考虑之前用户历史行为商品具体是什么,究竟用户历史行为中的哪个会对当前的点击预测带来积极的作用。)
如果想表达的准确些, 那么就得加大隐向量的维度,让每个特征的信息更加丰富, 那这样带来的问题就是计算量上去了,毕竟真实情景尤其是电商广告推荐的场景,特征维度的规模是非常大的。 并且根据上面的例子, 也并不是用户所有的历史行为特征都会对某个商品广告点击预测起到作用。所以对于当前某个商品广告的点击预测任务,没必要考虑之前所有的用户历史行为。
这样, DIN的动机就出来了,在业务的角度,我们应该自适应的去捕捉用户的兴趣变化,这样才能较为准确的实施广告推荐;而放到模型的角度, 我们应该考虑到用户的历史行为商品与当前商品广告的一个关联性,如果用户历史商品中很多与当前商品关联,那么说明该商品可能符合用户的品味,就把该广告推荐给他。
而一谈到关联性的话, 我们就容易想到“注意力”的思想了, 所以为了更好的从用户的历史行为中学习到与当前商品广告的关联性,学习到用户的兴趣变化, 作者把注意力引入到了模型,设计了一个"local activation unit"结构,利用候选商品和历史问题商品之间的相关性计算出权重,这个就代表了对于当前商品广告的预测,用户历史行为的各个商品的重要程度大小, 而加入了注意力权重的深度学习网络,就是这次的主角DIN。
2.2 DIN模型结构及原理
2.2.1 论文原文用到的数据集及baseline模型
工业上的CTR预测数据集一般都是multi-group categorial form的形式,就是类别型特征最为常见,这种数据集一般长这样:
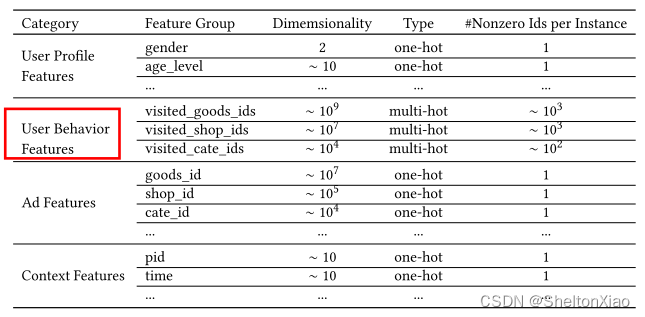
亮点在于红框标出的用户兴趣信息,以multi-hot的形式表达(为了使维度一致)。
对于特征编码,作者这里举了个例子:
[weekday=Friday, gender=Female, visited_cate_ids={Bag,Book}, ad_cate_id=Book], 这种情况我们知道一般是通过one-hot的形式对其编码, 转成系数的二值特征的形式。
但是这里我们会发现一个visted_cate_ids, 也就是用户的历史商品列表, 对于某个用户来讲,这个值是个多值型的特征, 而且还要知道这个特征的长度不一样长,也就是用户购买的历史商品个数不一样多,这个显然。这个特征的话,我们一般是用到multi-hot编码,也就是可能不止1个1了,有哪个商品,对应位置就是1, 所以经过编码后的数据长下面这个样子:
这个就是喂入模型的数据格式了,这里还要注意一点 就是上面的特征里面没有任何的交互组合,也就是没有做特征交叉。
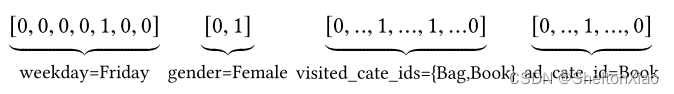
baseline模型,是Embedding&MLP的形式。
DIN网络的基准也是他,只不过在这个的基础上添加了一个新结构(注意力网络)来学习当前候选广告与用户历史行为特征的相关性,从而动态捕捉用户的兴趣。
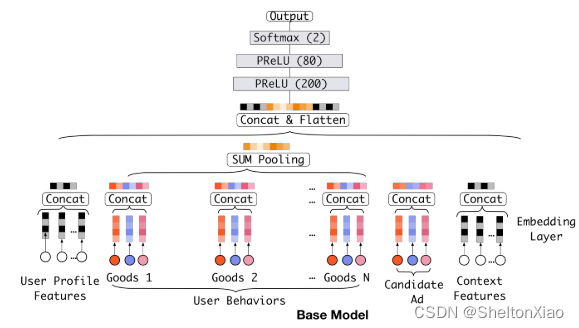
结构如上图,分为三大模块:
- Embedding Layer
把高维稀疏的输入转成低维稠密向量, 每个离散特征下面都会对应着一个embedding词典(可以理解为是唯一的位置编码), 维度是 D × K D\times K D×K, 这里的 D D D表示的是隐向量的维度, 而 K K K表示的是当前离散特征的唯一取值个数
所谓的唯一取值,就是对应one-hot和multi-hot里头的那个1。 - pooling layer and Concat layer
pooling层的作用是将用户的历史行为embedding这个最终变成一个定长的向量.
Concat layer层的作用就是拼接了,就是把这所有的特征embedding向量,如果再有连续特征的话也算上,从特征维度拼接整合,作为MLP的输入。
因为每个用户历史购买的商品数是不一样的, 也就是每个用户multi-hot中1的个数不一致,这样经过embedding层,得到的用户历史行为embedding的个数不一样多,也就是上面的embedding列表 t i t_i tii不一样长, 那么这样的话,每个用户的历史行为特征拼起来就不一样长了。
而后面如果加全连接网络的话,需要定长的特征输入。 所以往往用一个pooling layer先把用户历史行为embedding变成固定长度(统一长度)
所以有了这个公式:
e i = p o o l i n g ( e i 1 , e i 2 , . . . e i k ) e_i=pooling(e_{i1}, e_{i2}, ...e_{ik}) ei=pooling(ei1,ei2,...eik)
这里的 e i j e_{ij} eij是用户历史行为的那些embedding。 e i e_i ei就变成了定长的向量, 这里的 i i i表示第 i i i个历史特征组(是历史行为,比如历史的商品id,历史的商品类别id等), 这里的 k k k表示对应历史特种组里面用户购买过的商品数量,也就是历史embedding的数量,看上面图里面的user behaviors系列,就是那个过程了。
- MLP
就是普通的全连接,用了学习特征之间的各种交互。
然后是点击率预测任务,所以是一个二分类问题,损失函数用的是log对数似然。
2.2.2 DIN模型架构
采用了基模型的结构,并加了一个local activation unit注意力机制来学习用户兴趣与当前候选广告间的关联程度, 用在了用户历史行为特征上面, 能够根据用户历史行为特征和当前广告的相关性给用户历史行为特征embedding进行加权。
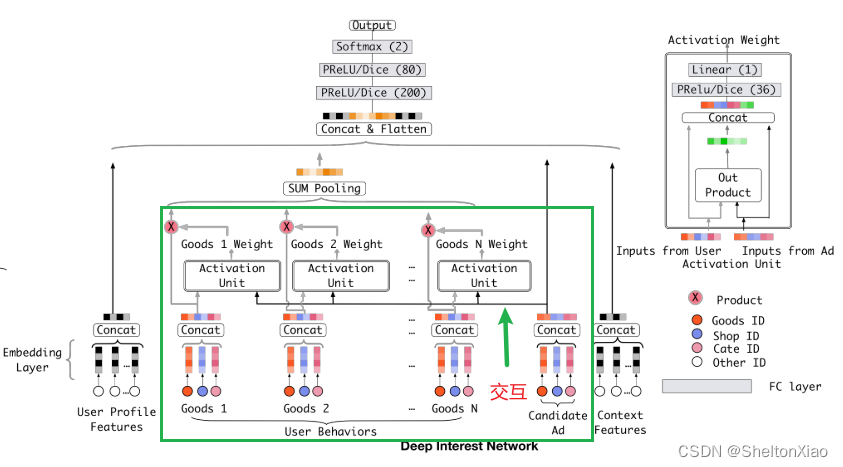
这里改进的地方已经框出来了。
相比于base model, 加了一个local activation unit, 是一个前馈神经网络,输入是用户历史行为商品和当前的候选商品, 输出是它俩之间的相关性.
这个相关性相当于每个历史商品的权重,把这个权重与原来的历史行为embedding相乘求和就得到了用户的兴趣表示 v U ( A ) \boldsymbol{v}_{U}(A) vU(A), 这个东西的计算公式如下:
v U ( A ) = f ( v A , e 1 , e 2 , … , e H ) = ∑ j = 1 H a ( e j , v A ) e j = ∑ j = 1 H w j e j \boldsymbol{v}_{U}(A)=f\left(\boldsymbol{v}_{A}, \boldsymbol{e}_{1}, \boldsymbol{e}_{2}, \ldots, \boldsymbol{e}_{H}\right)=\sum_{j=1}^{H} a\left(\boldsymbol{e}_{j}, \boldsymbol{v}_{A}\right) \boldsymbol{e}_{j}=\sum_{j=1}^{H} \boldsymbol{w}_{j} \boldsymbol{e}_{j} vU(A)=f(vA,e1,e2,…,eH)=j=1∑Ha(ej,vA)ej=j=1∑Hwjej
这里的 { v A , e 1 , e 2 , … , e H } \{\boldsymbol{v}_{A}, \boldsymbol{e}_{1}, \boldsymbol{e}_{2}, \ldots, \boldsymbol{e}_{H}\} {vA,e1,e2,…,eH}是用户U的历史行为特征embedding, v A v_{A} vA表示的是候选广告A的embedding向量, a ( e j , v A ) = w j a(e_j, v_A)=w_j a(ej,vA)=wj表示的权重或者历史行为商品与当前广告A的相关性程度。
输入除了历史行为向量和候选广告向量外,还加了一个它俩的外积操作,作者说这里是有利于模型相关性建模的显性知识。
这里有一点需要特别注意,就是这里的权重加和不是1, 准确的说这里不是权重, 而是直接算的相关性的那种分数作为了权重,也就是平时的那种scores(softmax之前的那个值),这个是为了保留用户的兴趣强度。(也就是不做归一化了)
2.3 模型的代码实现
rechub中实现了DIN模型,整体模型架构如下:
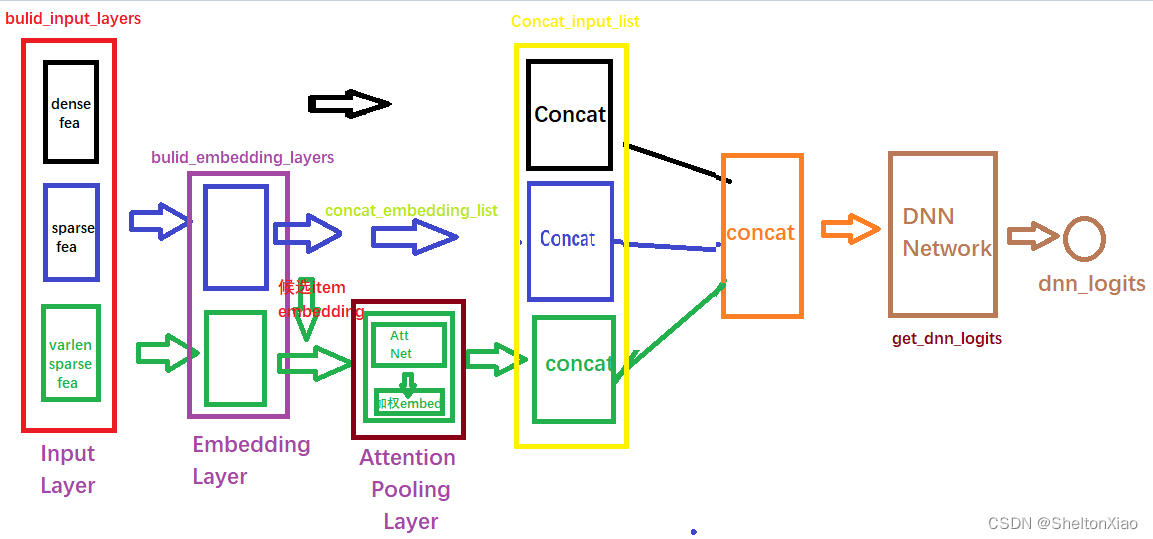
模型的输入分为三类
- Dense数值连续型
只需等待拼接后进入DNN - Sparse离散型
需要先通过embedding层转成低维稠密向量,然后拼接起来放着,等待拼接后进入DNN。
注意有个特征的embedding向量还得拿出来用,就是候选商品的embedding向量,这个还得和后面的计算相关性,对历史行为序列加权。 - VarienSparse变长离散型
一般指的用户的历史行为特征,变长数据, 首先会进行padding操作成等长, 然后建立Input层接收输入,然后通过embedding层得到各自历史行为的embedding向量, 拿着这些向量与上面的候选商品embedding向量进入AttentionPoolingLayer去对这些历史行为特征加权合并,最后得到输出。
考虑到用户购买行为显然是不等长的,特别说明了向量等长操作的问题(使用padding保证维度一致,同时mask标记)
还有一点需要说明的是这种历史行为是序列性质的特征, 并且不同的用户这种历史行为特征长度会不一样, 但是我们的神经网络是要求序列等长的,所以这种情况我们一般会按照最长的序列进行padding的操作(不够长的填0), 而到具体层上进行运算的时候,会用mask掩码的方式标记出这些填充的位置,好保证计算的准确性。 在我们给出的代码中,大家会在AttentionPoolingLayer层的前向传播中看到这种操作。
代码如下,更详细的代码见GitHub
# DIN网络搭建
def DIN(feature_columns, behavior_feature_list, behavior_seq_feature_list):"""这里搭建DIN网络,有了上面的各个模块,这里直接拼起来:param feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是数据的特征封装版:param behavior_feature_list: A list. 用户的候选行为列表:param behavior_seq_feature_list: A list. 用户的历史行为列表"""# 构建Input层并将Input层转成列表作为模型的输入input_layer_dict = build_input_layers(feature_columns)input_layers = list(input_layer_dict.values())# 筛选出特征中的sparse和Dense特征, 后面要单独处理sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns))# 获取Dense Inputdnn_dense_input = []for fc in dense_feature_columns:dnn_dense_input.append(input_layer_dict[fc.name])# 将所有的dense特征拼接dnn_dense_input = concat_input_list(dnn_dense_input) # (None, dense_fea_nums)# 构建embedding字典embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)# 离散的这些特特征embedding之后,然后拼接,然后直接作为全连接层Dense的输入,所以需要进行Flattendnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)# 将所有的sparse特征embedding特征拼接dnn_sparse_input = concat_input_list(dnn_sparse_embed_input) # (None, sparse_fea_nums*embed_dim)# 获取当前行为特征的embedding, 这里有可能有多个行为产生了行为列表,所以需要列表将其放在一起query_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)# 获取历史行为的embedding, 这里有可能有多个行为产生了行为列表,所以需要列表将其放在一起keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)# 使用注意力机制将历史行为的序列池化,得到用户的兴趣dnn_seq_input_list = []for i in range(len(keys_embed_list)):seq_embed = AttentionPoolingLayer()([query_embed_list[i], keys_embed_list[i]]) # (None, embed_dim)dnn_seq_input_list.append(seq_embed)# 将多个行为序列的embedding进行拼接dnn_seq_input = concat_input_list(dnn_seq_input_list) # (None, hist_len*embed_dim)# 将dense特征,sparse特征, 即通过注意力机制加权的序列特征拼接起来dnn_input = Concatenate(axis=1)([dnn_dense_input, dnn_sparse_input, dnn_seq_input]) # (None, dense_fea_num+sparse_fea_nums*embed_dim+hist_len*embed_dim)# 获取最终的DNN的预测值dnn_logits = get_dnn_logits(dnn_input, activation='prelu')model = Model(inputs=input_layers, outputs=dnn_logits)return model2.4 借助rechub实操
具体notebook代码见Torch-Rechub Tutorial: DIN
本文对应的colab文件见PyTorch推荐系统,相关的代码标注也包含在其中。
2.4.1 数据集介绍及特征工程
用Amazon-Electronics生成新数据集完成了实操。
原数据是json格式,我们提取所需要的信息预处理为一个仅包含user_id, item_id, cate_id, time四个特征列的CSV文件。
注意:examples文件夹中仅有100行数据方便我们轻量化学习
对于DIN模型所需的特征,分为三类
- Dense特征:又称数值型特征,例如薪资、年龄,在DIN中我们没有用到这个类型的特征。
- Sparse特征:又称类别型特征,例如性别、学历。本教程中对Sparse特征直接进行LabelEncoder编码操作,将原始的类别字符串映射为数值,在模型中将为每一种取值生成Embedding向量。
- Sequence特征:序列特征,比如用户历史点击item_id序列、历史商铺序列等,序列特征如何抽取,是我们在DIN中学习的一个重点,也是DIN主要创新点之一。
在这里理解数据集的构成是很重要的。在实操中我们尝试从原始数据集中确定历史序列特征(借助create_seq_features),特征如下:
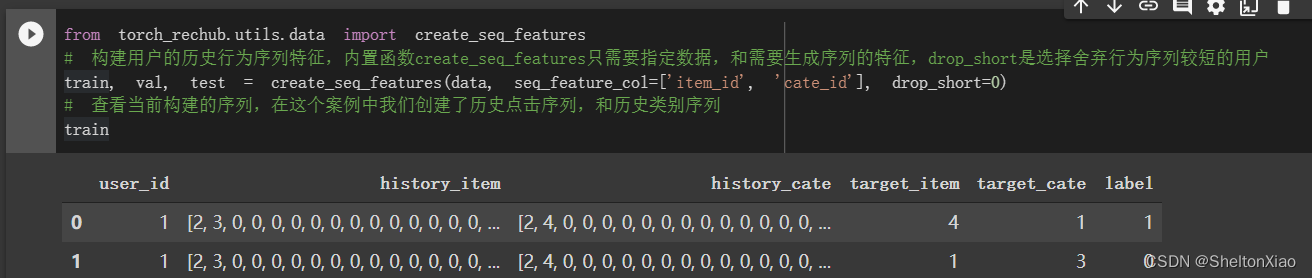
由于对应不同类型的特征,模型会有不同的处理方式,因此这里还是需要用rechub的内置数据类进行特征类型标注
在这个案例中,因为我们使用user_id,item_id和item_cate这三个类别特征,使用用户的item_id和cate的历史序列作为序列特征。在torch-rechub我们只需要调用DenseFeature, SparseFeature, SequenceFeature这三个类,就能自动正确处理每一类特征。
最后把输入数据转化为字典形式
2.4.2 训练
然后定义模型训练即可
epoch: 0
train: 100%|██████████| 1/1 [00:00<00:00, 6.56it/s]
validation: 100%|██████████| 1/1 [00:00<00:00, 7.16it/s]
epoch: 0 validation: auc: 1.0
epoch: 1
train: 100%|██████████| 1/1 [00:00<00:00, 6.55it/s]
validation: 100%|██████████| 1/1 [00:00<00:00, 7.57it/s]
epoch: 1 validation: auc: 1.0
epoch: 2
train: 100%|██████████| 1/1 [00:00<00:00, 6.40it/s]
validation: 100%|██████████| 1/1 [00:00<00:00, 6.76it/s]
epoch: 2 validation: auc: 1.0
validation: 100%|██████████| 1/1 [00:00<00:00, 6.92it/s]test auc: 1.0
由于数据量很小,3个epoch就达到了很好的效果
参考材料
- torch-rechub
- FunRec教程
- 推荐系统入门
这篇关于【datawhale202206】pyTorch推荐系统:精排模型 DeepFMDIN的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






