本文主要是介绍推荐系统实现3:多任务精排算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
-
场景:精排(多任务学习)
-
模型:ESMM、MMOE
-
数据:Ali-CCP数据集
什么是精排?
精排的目标是粗排中输出的TopK数据,因此可以使用比粗排更多的特征,更复杂的模型和更精细的策略(用户的特征和行为在该层的大量使用和参与也是基于这个原因)。
什么是多任务学习?
多任务学习(multi-task learning),本质上是希望使用一个模型完成多个任务的建模。在推荐系统中,多任务学习一般即指多目标学习(multi-label learning),不同目标输入相同的feature进行联合训练,是迁移学习的一种。
为什么使用多任务学习精排算法?
1. 很多业界推荐的业务,天然就是一个多目标的建模场景,需要多目标共同优化。
2.工程便利,不用针对不同的任务训练不同的模型。一般推荐系统中排序模块延时需求在40ms左右,如果分别对每个任务单独训练一个模型,难以满足需求。出于控制成本的目的,需要将部分模型进行合并。合并之后,能更高效的利用训练资源和进行模型的迭代升级。
简单的多任务学习实现
一种最简单的实现多任务学习的方式是对不同任务的loss进行加权。例如谷歌的Youtube DNN论文中提到的一种加权交叉熵:
![]()
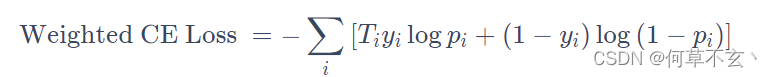
这种loss加权的方式优点如下:
- 模型简单,仅在训练时通过梯度乘以样本权重实现对其它目标的加权
- 模型上线简单,和base完全相同,不需要额外开销
缺点:
- 本质上并不是多目标建模,而是将不同的目标转化为同一个目标。样本的加权权重需要根据AB测试才能确定。
shared bottom
优点:
- 浅层参数共享,互相补充学习,任务相关性越高,模型loss优化效果越明显,也可以加速训练。
缺点:
- 任务不相关甚至优化目标相反时(例如新闻的点击与阅读时长),可能会带来负收益,多个任务性能一起下降。
一般把Shared-Bottom的结构称作“参数硬共享”,多任务学习网络结构设计的发展方向便是如何设计更灵活的共享机制,从而实现“参数软共享”。
(类似于Finetune)
ESMM
不同的目标由于业务逻辑,有显式的依赖关系,例如曝光→点击→转化。用户必然是在商品曝光界面中,先点击了商品,才有可能购买转化。阿里提出了ESMM(Entire Space Multi-Task Model)网络,显式建模具有依赖关系的任务联合训练。该模型虽然为多任务学习模型,但本质上是以CVR为主任务,引入CTR和CTCVR作为辅助任务,解决CVR预估的挑战:1.样本选择偏差。2.稀疏数据。
三个任务之间具有如下关系:

x表示曝光,y表示点击,z表示转化。模型结构如下图:
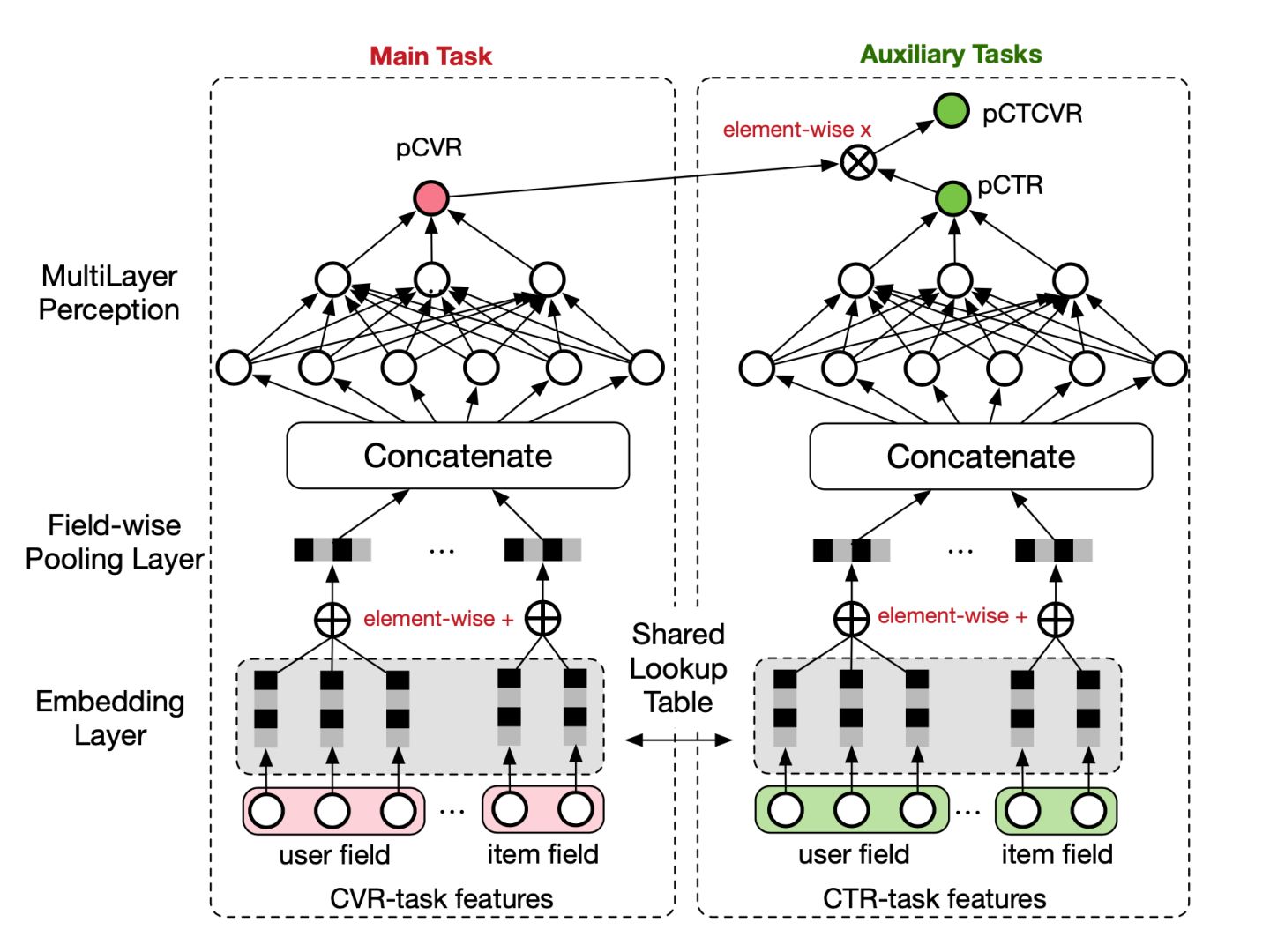
主任务和辅助任务共享特征,不同任务输出层使用不同的网络,将cvr的预测值*ctr的预测值作为ctcvr任务的预测值,利用ctcvr和ctr的label构造损失函数:
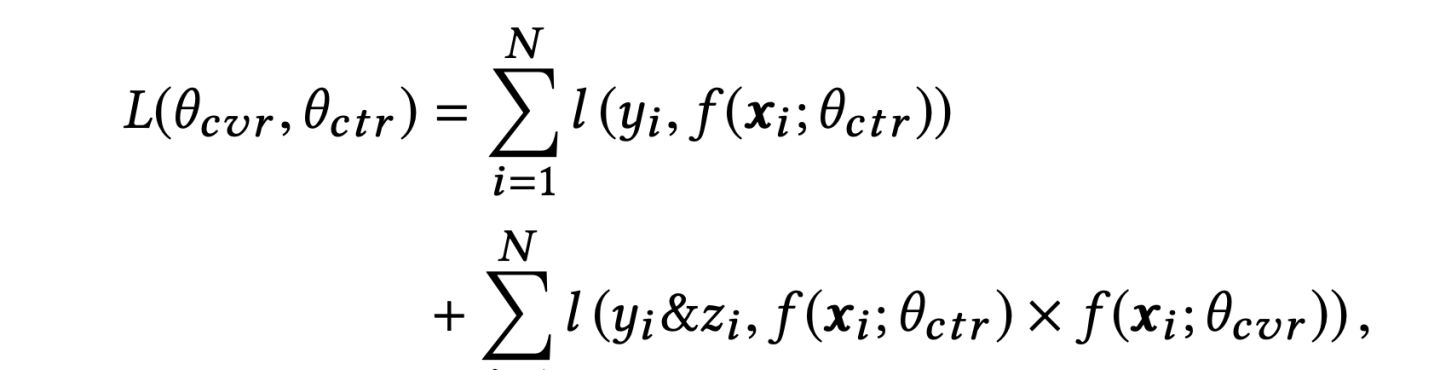
这种模型的策略类似于特征迁移,旨在特征层面学习到足够的相关信息,同时,这种学习方式帮助了主任务在一个完整的任务空间内进行学习,不是单独的曝光到转化,而是加入了点击这一中间辅助空间。
(未完待续)
这篇关于推荐系统实现3:多任务精排算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




