本文主要是介绍声音事件检测metric:PSDS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文;A FRAMEWORK FOR THE ROBUST EVALUATION OF SOUND EVENT DETECTION
Abstract
这项工作为多声道声音事件检测(SED)系统的性能评估定义了一个新的框架,它克服了传统的collar-based事件决定、事件F-cores和事件错误率的限制。拟议的框架引入了对事件检测的定义,该定义对标签的主观性更为稳健。它还采用了多声道接收器操作特性(ROC)曲线,以提供比F1分数更全面的系统性能洞察力,并建议将这些曲线简化为单一的多声道声音检测分数(PSDS),这允许系统独立于操作点(OPs)进行比较。所提出的方法还能更好地了解不同声音类别的数据偏差和分类稳定性。此外,它可以根据不同的应用进行调整,以满足各种用户体验要求。通过重新评估DCASE 2019年任务4中的baseline和两个表现最好的系统,证明了拟议方法的好处。
Introduction
在[9,10]中提出了按事件划分的错误率和按段划分的错误率,并在最近的DCASE版本[5-8]中部署,作为以前基于帧的衡量标准[4]的一个进步。然而,他们目前的形式仍然忽略了以下关键问题。
对操作点的依赖性:在同一指标下,具有不同决策阈值的同一系统可能得到不同的性能排名。换句话说,这种指标将声音事件建模的评价与操作点调整的评价混为一谈[11]。这个问题在信号检测理论中得到了很好的研究,特别是在二元分类、关键词识别和说话人识别中[12-14],其中ROC曲线[15]、检测误差权衡(DET)曲线[16]或曲线下面积 (AUC)指标[17]被用来评估一个给定系统在一系列操作点上的整体性。然而,这种做法还没有被SED界广泛采用。
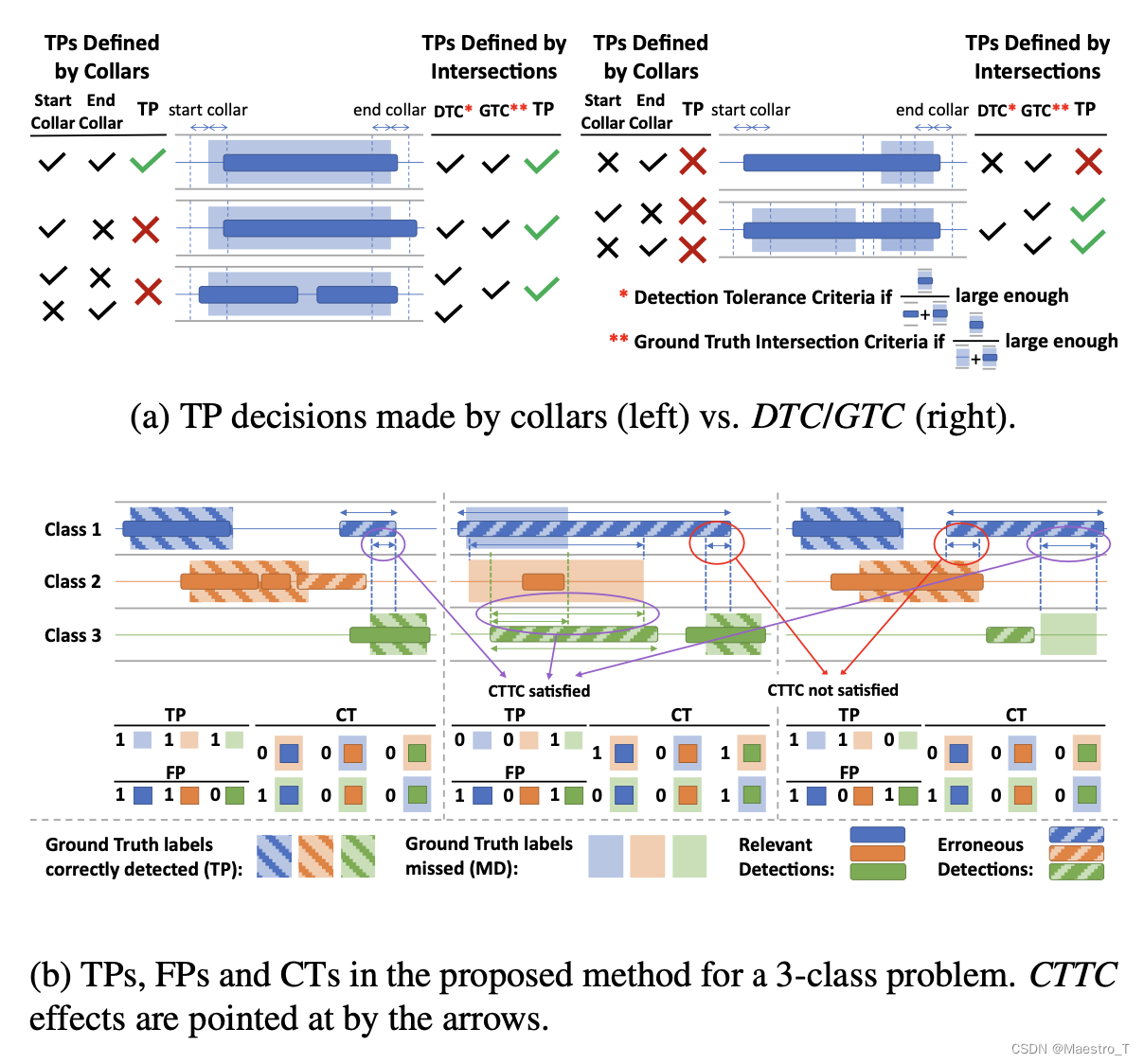
声音事件的定义:[9、10] 中定义的基于事件的指标依赖于collar,collar是对检测到的事件相对于标记的ground truth事件 [5-8] 的开始和结束时间的约束。 collar的使用本质上非常强调声音事件的开始和结束时间,而这些时间可能在人类标注员的主观反馈。 因此,为了模型的稳定性,评估标准应该为解释实时ground truth和检测时间的时间结构留出足够的空间。 在这方面,[18] 提议通过依赖实时ground truth和检测到的事件之间的交集百分比来决定时间序列数据异常检测的真阳性(TPs)和误报(FPs)
多类系统中的先验概率、假阳性和交叉触发器:交叉触发器(CTs)cross-trigger是与多类系统中另一个标记的类别相匹配的假阳性子集。将CTs的行为与FPs的原始数量区分开来,可以深入了解数据的偏差,对于声学上相似的声音类别尤其如此。事实上,多类评估数据集可能会变得有偏见,即对某些目标类的TP进行可靠评估所需的数据量可能会与现场先验不一致。例如,破窗玻璃在实践中很少发生,然而对破窗玻璃的TP的可靠评价需要大量的阳性类样本,这又可能人为地增加其他冲击性类的FP计数。因此,对CT的核算有助于分析FP是否是由数据偏差而非声学模型缺陷造成的。
Background
2.1 声音事件检测的定义
Definition1(Event-Based SED Evaluation Task)
Y = U c ∈ C Y c Y=U_{c∈C } Y_c Y=Uc∈CYc是一个数据集,它是每个类别c∈C的ground truth子集的联合
定义为 Y c = { y i = ( t s , i , t e , i , c i ) : c i = c } Y_c = \{y_i = (t_{s,i}, t_{e,i}, c_i): c_i = c\} Yc={yi=(ts,i,te,i,ci):ci=c}
其中每个真实标签 y i y_i yi是由其类别 c i c_i ci、开始时间 t s , i t_{s,i} ts,i和结束时间 t e , i t_{e,i} te,i定义。
X ∗ = U c ∈ C X c ∗ X^{∗} = U_{c∈C} {X^∗_c} X∗=Uc∈CXc∗是一个检测集合,是每个类别c∈C的检测子集的联合,定义为 X c ∗ = { x j = ( t s , j , t e , j , c j ) : c j = c } X^∗_c = \{xj = (t_{s,j}, t_{e,j}, c_j): c_j = c\} Xc∗={xj=(ts,j,te,j,cj):cj=c},其中每个检测 x j x_j xj由其类别 c j c_j cj、开始时间 t s , j t_{s,j} ts,j和结束时间 t e , j t_{e,j} te,j定义,其中星级符号∗表示对操作点参数 τ c \tau_c τc的依赖。
SED评价任务被定义为衡量系统在给定的 Y Y Y下输出 X ∗ X^∗ X∗的性能。
重要的是,评估中的SED系统是在给定工作点(OP)参数 τ c \tau_c τc, ∀c∈C的情况下发出检测集合。一般来说, τ c \tau_c τc的作用是调整SED系统的容许性(permissiveness)。例如,对于发出分类分数的SED系统,如类别概率, τ c \tau_c τc可能是一组与类别相关的阈值,其中较高的阈值会使系统更有控制性,即发出系统更有信心的声音检测,而较低的阈值会让更多的检测通过,从而使系统更有容许性。这里可以采用各种优化策略:一些系统可能会选择在将框架决策纳入事件检测之前优化框架分类,而其他系统可能会在优化事件级阈值之前形成事件分数。本文提出的评估方法旨在涵盖所有操作点可以改变的SED系统,无论其颗粒度如何。
2.2 传统collar-based方法的限制
collar-based方法中对于 y i y_i yi被正确检出的标准是:
∃ x i ∈ X c ∗ \exists x_i \in X^*_c ∃xi∈Xc∗ such that ( t s , i − t c ) ≤ t s , j ≤ ( t s , i + t c ) (t_{s,i} − t_c) ≤ t_{s,j} ≤ (t_{s,i} + t_c) (ts,i−tc)≤ts,j≤(ts,i+tc)
A N D ( t e , i − t ˉ c ) ≤ t e , j ≤ ( t e , i + t ˉ c ) AND (t_{e,i} − \bar t_c) ≤ t_{e,j} ≤ (t_{e,i} + \bar t_c) AND(te,i−tˉc)≤te,j≤(te,i+tˉc)
t c t_c tc : collar duration
t ˉ c \bar t_c tˉc: collar duration 和 预定义比例的 ground truth duration
即:检测出的start和end在collar的限定范围内
然而,collar引入了一个限制,可能会阻碍系统评估。事实上,SED的现场应用经常遇到这样的情况:由于对声音事件的时间结构的主观解释,一个声音可以被合理地标记为一种以上的方式。例如,一只狗反复吠叫,人类听众可以合理地解释为一只狗的吠叫事件,也可以解释为几只单独的狗的吠叫事件,详尽的标签规格在实践中难以定义和执行。使用collar的效果是迫使这些解释中的一个或另一个产生分类错误,而更理想的是SED评估在设计上对这种合理的groundtruth标记的变化变得稳健。
3. PROPOSED EVALUATION FRAMEWORK
3.1 对SED任务的TPs、FPs和CTs的更有力的定义
Definition 2 (Detection Tolerance Criterion - DTC)

X D T C , c ∗ X^*_{DTC,c} XDTC,c∗:检出的事件的检测结果与ground truth的重合部分 / 检测结果的duration >= 阈值
False Positive: 个类别 X ˉ D T C , c ∗ \bar X^*_{DTC,c} XˉDTC,c∗的集合, X ˉ D T C , c ∗ \bar X^*_{DTC,c} XˉDTC,c∗定义为 X c ∗ X^*_{c} Xc∗中排除KaTeX parse error: Undefined control sequence: \X at position 1: \̲X̲^*_{DTC,c}的部分,即未达到阈值的部分。
Definition 3 (Ground Truth intersection Criterion - GTC)

GTC创建了一个正确检测到的ground truth事件集
Y G T C , c ∗ Y^*_{GTC,c} YGTC,c∗ DTC和ground truth的重合部分 / ground truth duration >= 阈值
DTC和GTC计算ground truth标签和检测到的事件之间的交集百分比。我们的方法的不同之处在于,在计算最终的性能数字之前,对交叉点进行阈值计算,以计算TPs/FPs。在我们的工业数据集上观察到,标签者之间的分歧主要发生在事件的边界,例如,声音事件逐渐消失或由边界有待解释的单元组成,基于交集公差而不是边界领的方法本质上更稳健,如图2a所示。
回到定义2,一些FP可能是由于特定的数据偏差,可能会浮现为目标声音类别之间的混淆。因此,定义4中引入了交叉触发容忍度准则(CTTC),允许单独计算CT,如图2b所示。
Definition 4 (Cross-Trigger Tolerance Criterion - CTTC)

事件i的ground truth与事件j的检出的重合 / 事件j的检出duration >= 阈值 (i不等于j)
3.2. Performance metrics relevant to user experience
用户体验会收到FPs出现频率的影响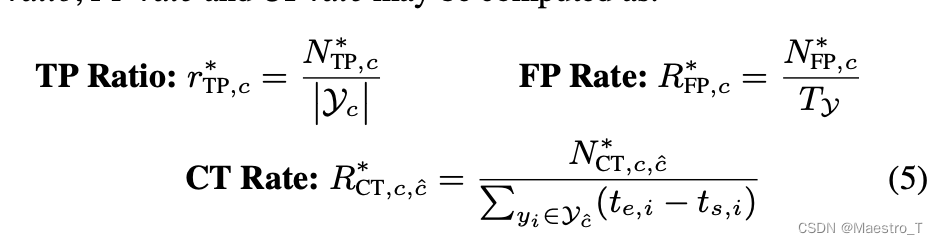
其中 T y T_y Ty 是数据集所有音频的 total duration
TP的性能是以检测到的事件的比例来衡量的,而FP和CT的性能是每单位时间的比率。
针对已识别的声音类的交叉触发可能会引发更多的负面用户体验,effective FP rate (eFPR):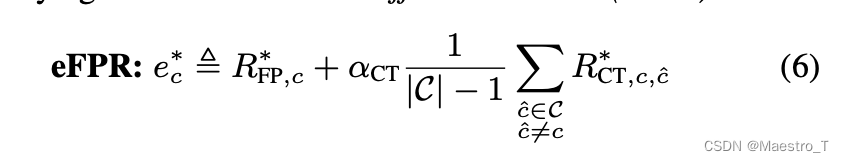
参数 α c t \alpha_ct αct 代表CT在评估的SED应用中对用户体验的成本。
系统行为可能无法保证每个操作点都形成凸的或单调的类相关ROC曲线,可能会有一些操作点会较其他操作点在更高的 eFPR 生成更低的 TP 比率。
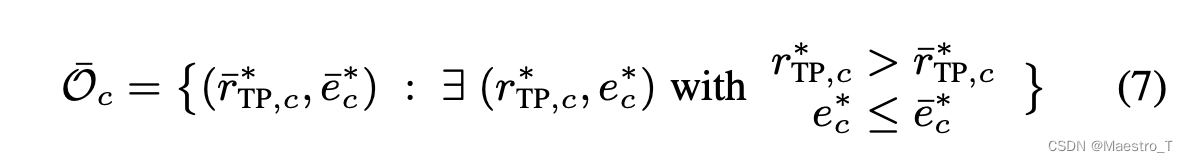
如果相邻的点能提供更好的权衡,这些点将永远不会被选为产品的实际操作,这些操作点最后会被丢弃掉以形成一个最大的best case操作点集合: O ^ c = O c − O ˉ c \hat O_c = O_c - \bar O_c O^c=Oc−Oˉc
然而,跨类性能的稳定性是评估的重点:跨类TP比率变化小得多的系统可能更受欢迎,因为它对性能最差(或最难)的类具有更好的性能。出于这个原因,有效TP比(eTPR)使用跨类TP比的平均值和标准偏差进行定义: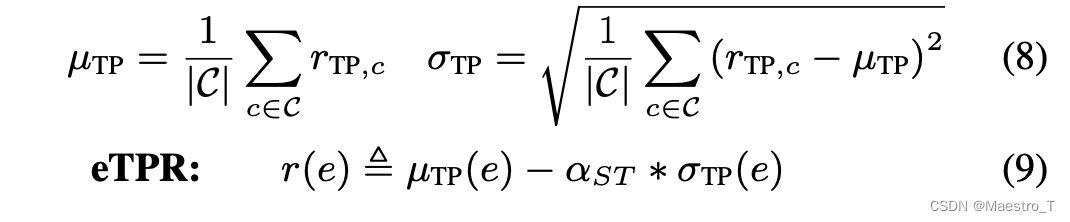
其中参数αST调整了所评估的SED任务的跨类不稳定成本。
Definition5(Polyphonic Sound Detection Score)

这篇关于声音事件检测metric:PSDS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






