本文主要是介绍endnote中文文献,et al如何改为等,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.问题说明
如下图所示,当中文文献超过3个作者时,中文的话应该显示
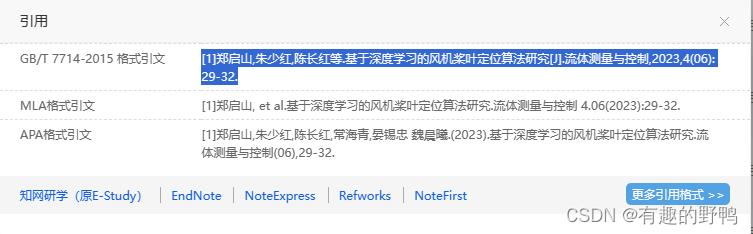
标准的中文引用格式应该如下:
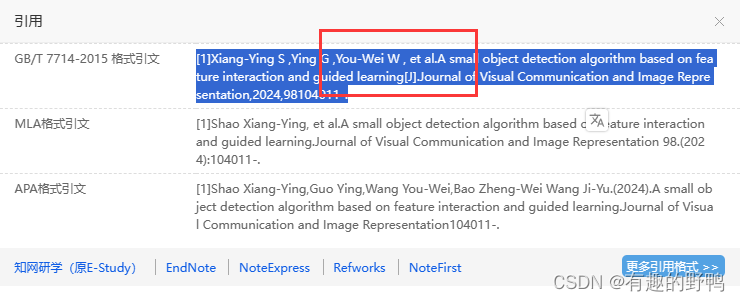
endnote英文是对的,但是中文是错误的
方法1-投机取巧
如果文献比较少,可以直接把超过3个作者的第四个作者及后面作者信息删除,将第三个人改成姓名+等。
有些引用使用的是:,等,也是一样的
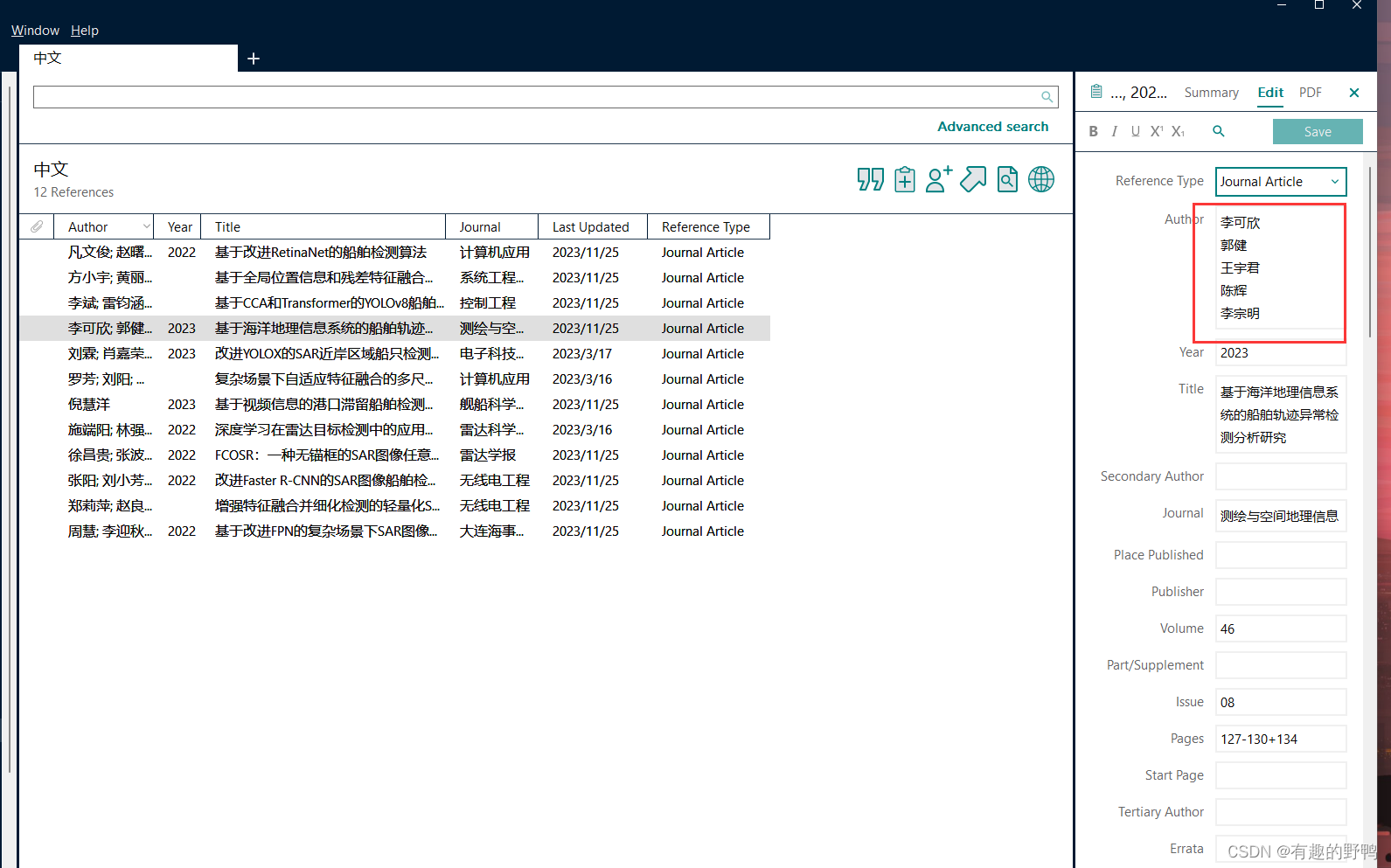
改成如下:
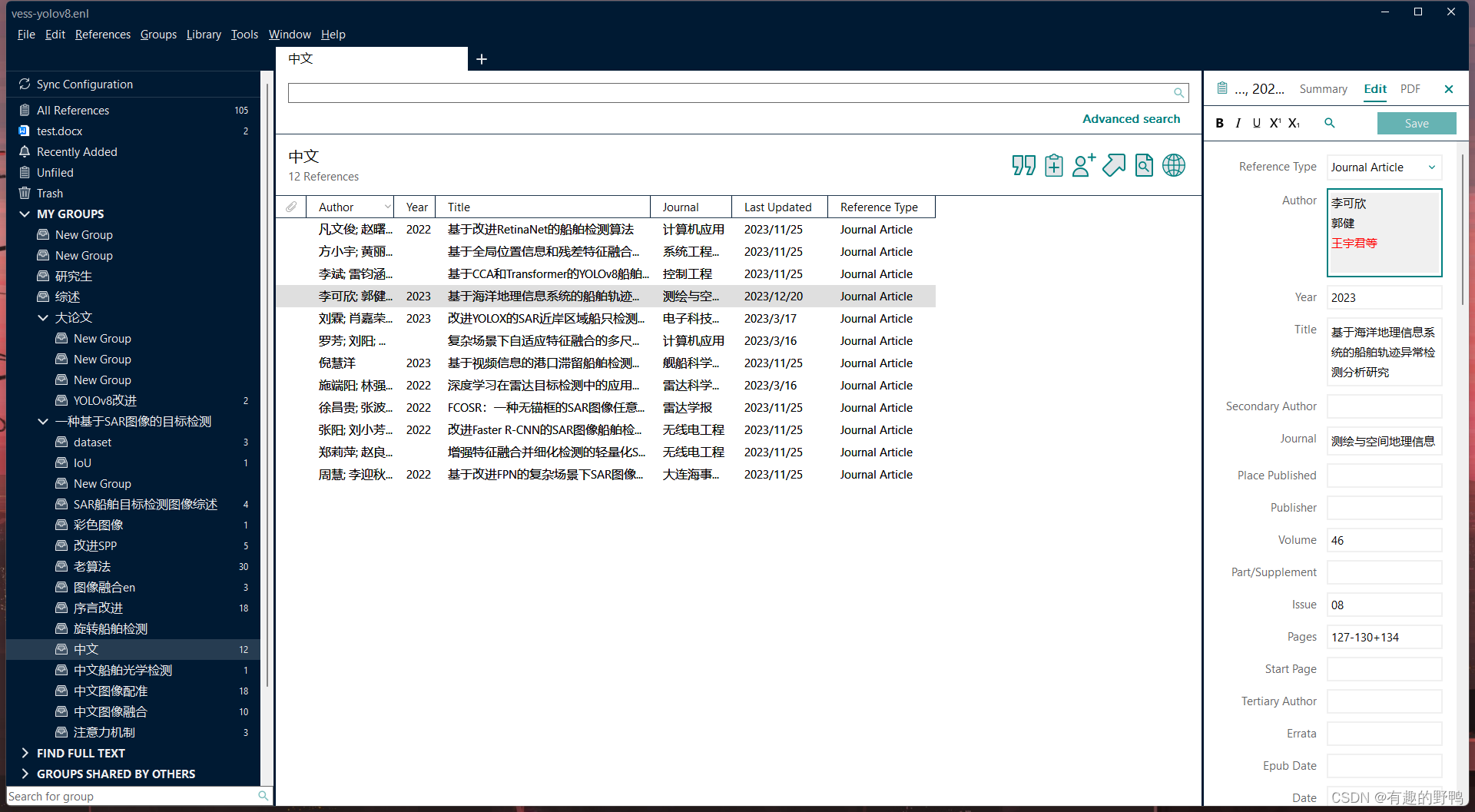
然后update信息即可
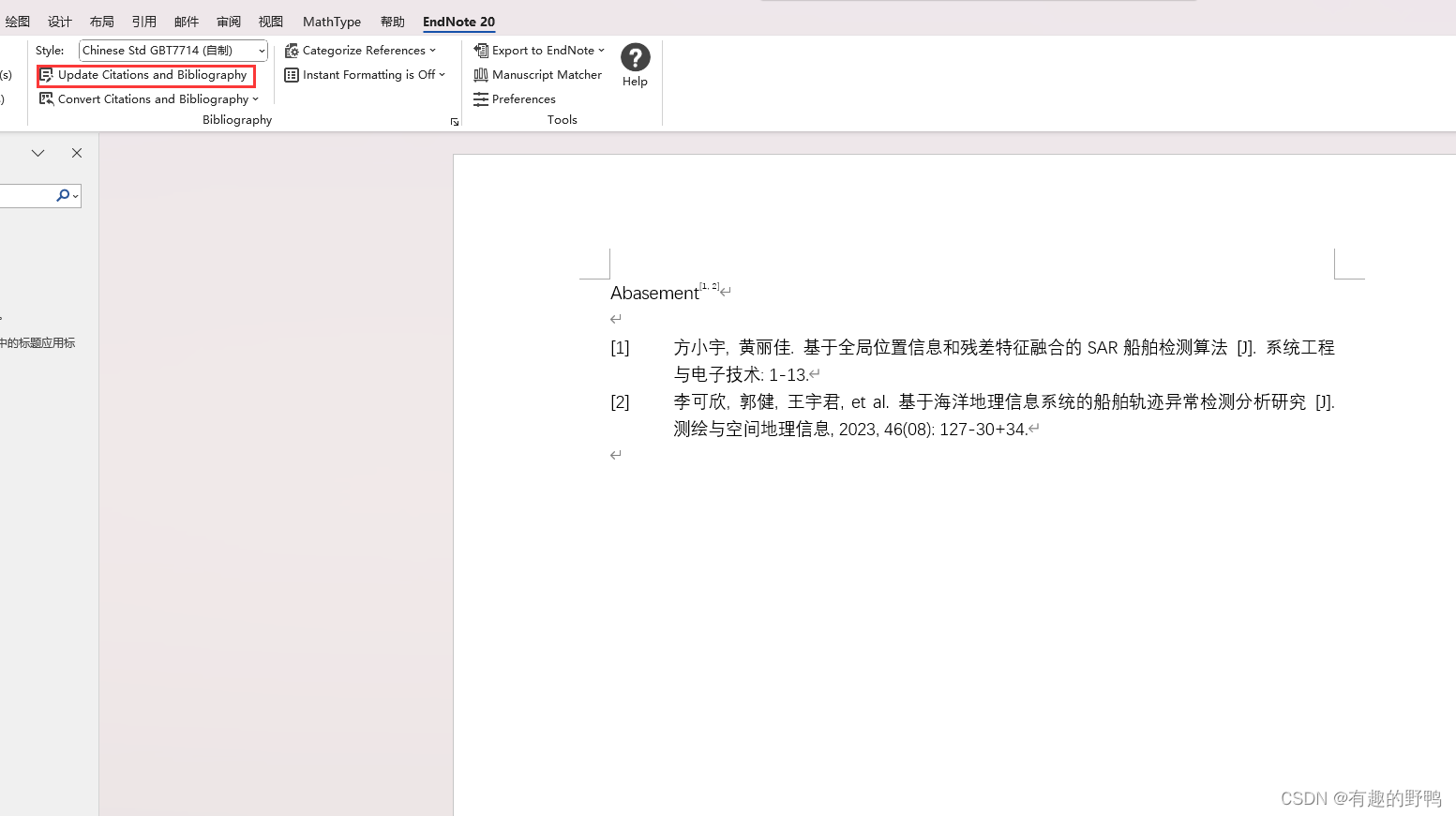
完成任务。

方法2-一劳永逸法
这个方法我不会(以后有兴趣再说)
这篇关于endnote中文文献,et al如何改为等的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!