本文主要是介绍基于Keras和LSTM单参数预测中兴通讯股票走势,结果震惊,含代码数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.前言
昨天用分类算法预测大A各个股票的第二天行情,预测结果出现了千股下跌的场景,结果着实让我震惊,预测结果如下图,有没有可能预测第二天究竟涨了多少或者跌了多少呢?毕竟短线交易见好就收呢?

通过查找资料,选择了长短记忆神经网络LSTM,并且通过python爬虫技术获取了中兴通讯连续200个交易日的情况,做一个单参数的LSTM模型,所谓单参数,就是根据历史收盘价预测明日收盘价。当然收盘价和换手率,成交量甚至周几都有关系,但是今天只研究收盘价预测收盘价。
2.数据集
通过爬虫技术获取中兴通讯连续200个交易日的收盘情况。
数据集下载 https://download.csdn.net/download/qq_14945847/88833483
数据集内容如图所示:
3.LSTM神经网络代码编写
python代码如下:
from pandas import DataFrame
from pandas import concat
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
import matplotlib.dates as mdates
import random as randomrandom.seed(1234)
# 读取数据
dataSource = pd.read_csv("data/中兴通讯Lstm训练数据集-2024-02-14.csv",encoding='gbk',header=0)
sequence = np.array(dataSource["收盘价"])
#将序列转换为竖直排列的格式
df = DataFrame(sequence)
print(df)
# 创建一个监督序列数据,axis=1表示对列操作(拼接成多列),axis=0表示对行操作(拼接成一列多行)
# concat将多个df序列合并成一个集合,shift(1)将当前列向下移动,shift(-1)向上移动
df = concat([df.shift(1), df], axis=1)
print(df)
# 删除有na值的行
df.dropna(inplace=True)
print(df)
# 使用reshape方法,把监督型序列转换为LSTM可识别的数组格式
values = df.values
print(values)
X, y = values[:, 0], values[:, 1]
print(X)
print(X.shape)
X = X.reshape(len(X), 1, 1)
print(X.shape)
# print(X)
# 1. 定义网络类型
model = Sequential()
#每个样本步长为1,并且有1个特征值
model.add(LSTM(64, input_shape=(1,1)))
model.add(Dense(1))
# 2. 编译网络,设置损失参数
model.compile(optimizer='adam', loss='mean_squared_error')
# 3. 调用网络开始训练模型,对数据训练1000次
history = model.fit(X, y, epochs=1000, batch_size=len(X), verbose=0)
# 4. 评估网络
loss = model.evaluate(X, y, verbose=0)
print("损失")
print(loss)
# 5. 利用训练好的模型,带入原始的X进行单步预测
predictions = model.predict(X, verbose=0)
print("预测结果")
predict = predictions[:, 0]
print(predict)time = np.array(dataSource["time"])
# 使用切片操作让数组变短 目标:丢弃指针0位置的数据并且让数组变短
# 比如我们想获取从索引1(包含)到索引4(不包含)的子数组
shortened_array = time[1:time.size]# 将字符串日期转换为datetime对象
dates = [datetime.strptime(date, '%Y-%m-%d') for date in shortened_array]
# 转换日期到matplotlib理解的格式
date_format = mdates.DateFormatter("%Y-%m-%d")
x_values = mdates.date2num(dates)x_data = x_values
y_data = values[:, 1]
y_data2 = predict
# 解决图标题中文乱码问题
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
plt.figure(figsize=(8, 6)) # 单位为英寸
plt.title('中兴通讯预测',fontsize=20)
in1, = plt.plot(x_data,y_data,color='red')
in2, = plt.plot(x_data,y_data2,color='blue')
plt.legend(handles = [in1,in2],labels=['实际走势','预测走势'],loc=2)
# 设置x轴的日期格式
ax = plt.gca()
ax.xaxis.set_major_formatter(date_format)
plt.show()print("预测情况总结")
print("当前交易日收盘价:",y[y.size-1])
print("预测明日收盘价:",predict[predict.size-1])
print("涨幅:",predict[predict.size-1]-y[y.size-1])
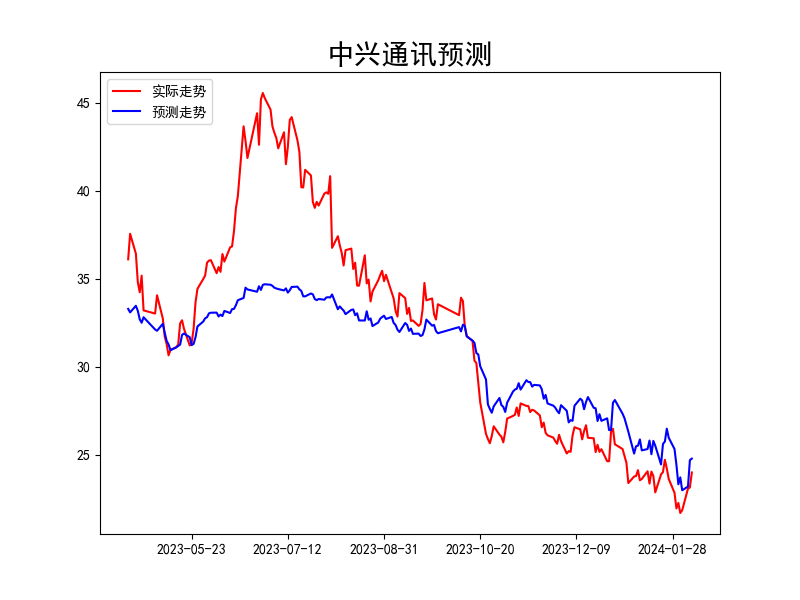
3.结果分析
预测情况总结
当前中兴通讯交易日收盘价: 24.0
预测明日中兴通讯收盘价: 24.785267
中兴通讯明日预测涨幅: 0.7852668762207031
损失
14.042476654052734
预测结果
[33.28453 33.087986 33.462406 33.176243 32.696243 32.499676 32.8116532.115696 32.043694 32.43946 31.928625 31.471443 31.26379 30.94032131.102417 31.178799 31.258833 31.809721 31.886604 31.677944 31.22899431.298296 31.673471 32.28919 32.56555 32.751354 32.814785 33.03397833.06823 33.073887 32.85522 32.961037 32.879795 33.170822 33.0511633.271606 33.28453 33.49759 33.777615 33.90775 34.489586 34.38947334.2593 34.570927 34.361244 34.65027 34.684044 34.656948 34.59274734.488438 34.44617 34.41078 34.33494 34.449764 34.208538 34.3455434.53005 34.547485 34.393265 34.30664 33.998684 33.996956 34.16024434.11008 33.84591 33.781593 33.847816 33.80723 33.93507 33.94765533.933266 34.103676 33.263817 33.429 33.299942 33.18973 32.98753733.229725 33.25338 32.92825 33.033978 32.62998 32.62662 33.15175632.669926 32.741707 32.311634 32.513668 32.72879 32.821045 32.8980732.712566 32.82729 32.489136 32.374382 32.103798 31.97428 32.4820932.381687 32.035603 32.17066 31.86966 31.882374 31.7488 31.79675532.11965 32.679825 32.333927 32.374382 32.02748 31.903473 32.25142332.007122 32.38896 32.31908 31.722383 31.485548 31.356815 30.77787230.700132 30.031746 29.281406 27.864197 27.60847 27.391043 27.75050428.22954 27.829378 27.724052 27.436777 27.959213 28.586708 28.70471228.751392 29.069828 28.704712 29.238176 29.136208 29.128862 28.874428.972795 28.942669 28.72809 28.187895 28.402079 27.91616 27.79441527.679781 27.50042 27.363483 27.820646 27.50042 26.843403 26.9689126.930464 27.785648 28.187895 28.087051 27.590555 28.002048 28.2792227.670897 27.6442 26.920828 27.308128 26.930464 27.073858 26.40656326.406563 27.959213 28.112381 27.335854 27.083342 26.706436 26.31489625.072882 25.486929 25.519894 25.87658 25.253626 25.331886 25.81253425.038702 25.79111 25.519894 24.455591 25.618254 25.758894 26.48738325.971972 25.331886 24.431736 23.328856 23.722181 22.991442 23.19989824.703596 24.785267]
预测情况总结
当前交易日收盘价: 24.0
预测明日收盘价: 24.785267
涨幅: 0.7852668762207031
4.图例分析
短期看来中兴通讯走势是向上的。
5.遗留问题
1.每次预测结果不一样,已经通过random.seed来解决。
2.为什么lstm是预测的一整个序列,我想想中的应该只预测最后一个值才对,这个后续会研究。
3.股票第二天涨跌肯定要和成交量,换手率等有关系,后续会做多参数模型的训练。
4.如何确保模型的参数为最优参数,目前还不会解决这个问题。昨天MLPClassifier是通过GridSearchCV技术来解决的,计算出了最优参数。那lstm如何获取最优参数呢?
5.为什么蓝线和红线趋势一样,但是高度还是差别较大,如何解释这些问题呢?
最后:路漫漫其修远兮,吾将成为一个新韭菜!!
这篇关于基于Keras和LSTM单参数预测中兴通讯股票走势,结果震惊,含代码数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




