本文主要是介绍###好好好#####BOOM!推荐系统遇上多模态信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
推荐已经成为许多在线内容共享服务的核心组成部分,从图像、博客公众号、音乐推荐、短视频推荐等等。与传统推荐不一样的地方,就是这些项目内容包含着丰富的多媒体信息-帧、音轨和描述,涉及多种形式的视觉、声学和文本信息。
「那么如此丰富的多媒体、多模态信息如何融合到推荐中呢?」
最普通也是最直接的方式可能就是对多模态抽特征,然后多模态融合直接作为side Information或者item的representation之后参与到推荐中的。
本篇博文主要整理三篇整合多模态信息到表示中的文章,一篇是通用的融合结果,其他两篇中一篇涉及到了GCN,一篇涉及到了KG,可能需要补充相关基础知识可见博主以往整理过的系列文章[1]。还有其他关于多模态的+比较有意义的论文也欢迎在博文后面留言推荐。
LOGO
论文:Hashtag Our Stories: Hashtag Recommendation for Micro-Videos via Harnessing Multiple Modalities
地址:https://www.sciencedirect.com/science/article/abs/pii/S0950705120303798
代码:https://tagrec.wixsite.com/logo
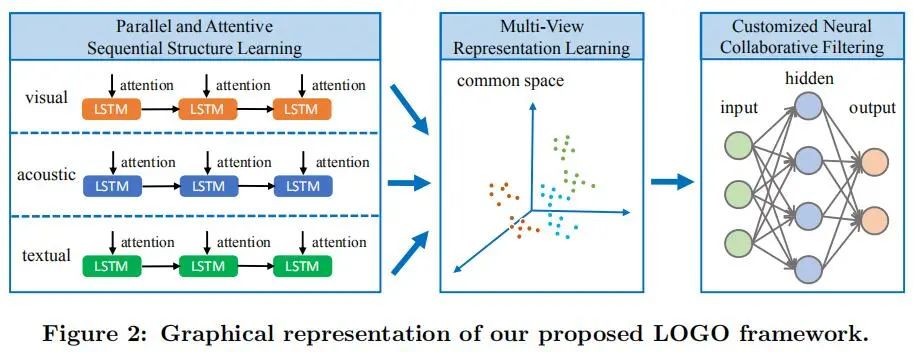
领域是短视频标签推荐。这篇文章就是使用比较直观的手段,分为三个步骤:
-
「抽取特征:」 对视觉,声音,文本三个模态都用LSTM+Attention进行模态抽取。
-
「共同空间投影:」 投影到Common space之后以弥合不同模态之间的表达gap。
-
「NCF推荐:」 直接使用NCF推荐tag就可以了。
模型较为简单清晰,直接看代码结构
-
class LOGO(nn.Module): -
def __init__(self, img_in, img_h, au_in, au_h, text_in, text_h, common_size): -
super(LOGO, self).__init__() -
self.ilstm = ImageLSTM(img_in, img_h) -
self.alstm = AudioLSTM(au_in, au_h) -
self.tlstm = TextLSTM(text_in, text_h) -
# map into the common space -
self.ilinear = MLP(img_h, common_size) -
self.alinear = MLP(au_h, common_size) -
self.tlinear = MLP(text_h, common_size) -
def forward(self, image, audio, text): -
# lstm + attention -
h_i = self.ilstm(image) # batch*img_h -
h_a = self.alstm(audio) # batch*au_h -
h_t = self.tlstm(text) # batch*text_h -
# map into the common space -
x_i = self.ilinear(h_i) # batch*common_size -
x_a = self.alinear(h_a) # batch*common_size -
x_t = self.tlinear(h_t) # batch*common_size -
# return three kind of features -
return x_i, x_a, x_t
UHMAN
论文:User Conditional Hashtag Recommendation for Micro-Videos
地址:https://ieeexplore.ieee.org/document/9102824

这个也是短视频标签推荐,旨在给出能够反映短视频主题或内容的标签,且满足用户的偏好。文章的motivation在于:大多数用户在看视频时只关注帧的某些特定区域和整个视频的某些特定帧。所以方法上是融合了用户信息+视频时空注意力最后得到结果。
完整模型如上,视频的时空两方面的信息都会在multi-head attention习得到融合,同时结合了很多用户信息,如性别、年龄、国家等等一起参与到模型预测中。
然后以上沿着这个经典线路,可以把多模态融合的很多技术手段拿进来做魔改,就不再单独展开。
MMGCN
论文:Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video
地址:http://staff.ustc.edu.cn/~hexn/papers/mm19-MMGCN.pdf
代码:https://github.com/weiyinwei/MMGCN
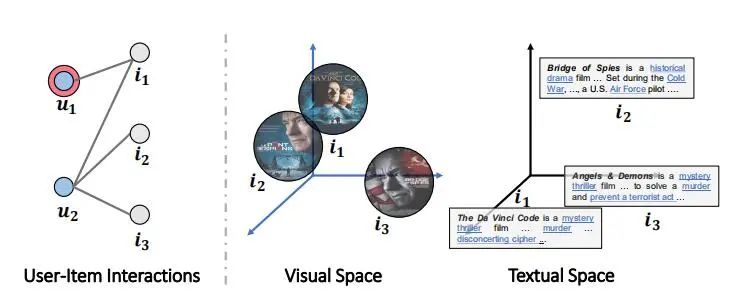
出自MM2019,为了基于多媒体推荐,那么不仅要求能够理解User-item交互,还得考虑item内容本身多模态的特征。但是,目前的多模态推荐方法主要是利用item本身的多模态内容来丰富item侧的表示;但是很少会考虑用它来提升 user侧的表示,然而捕获这种表示是能够提高用户对不同模态特征的细粒度偏好的。主要涉及到有三点:
-
不同模态的语义差异。如上图中,战争片和恐怖片在视觉模态空间很相似,但是在文本模态空间却并不相似,它们的主题并不一样。所以同时融合多模态对item的理解是有意义的。
-
同一个用户对不同模态的不同偏好。有些人在意画面,而有些人却喜欢bgm。
-
不同的模式可以作为探索用户兴趣的不同渠道。结合用户的交互,体现了多模态信息是能够加强用户特征理解的,即喜欢画面就多推画面精彩的item,喜欢bgm就多推相应的item就好。
所以作者提出用User-item交互来引导模态表示,并反过来捕获在特定模态内容下用户的偏好。具体的实现如下图,在User-item二部图上按视频,音频,文本各自可得到三个图,然后先item聚合,再user聚合得到表示,其中这里的每步都会额外加入id和content一起,最后得到预测结果。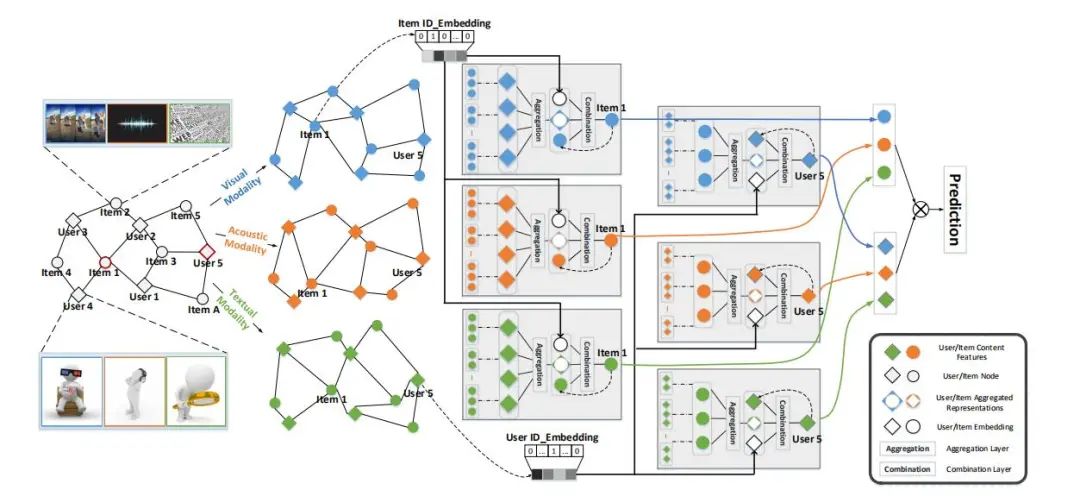
-
Aggregation Layer。user从item聚合,item从user聚合,这和以往GNN在推荐中的用法一致。这里作者提到了两种聚合机制,平均和最大,看一下公式:
值得注意的是,因为分成了三个模态的图,所以这里是需要按modal-specific来汇聚邻居,jm表示对应模态m下的表示,然后用leakyrelu线性变换,最后用平均池化汇聚,平均是假设了所有领域节点的影响是等价的。另一个就是max聚合,
好处是不同的邻域结点的影响力不同。
-
Combination Layer。融合三个信息,结构化信息hm(前一层消息传递后的特征),自有信息um(各模态原始特征表示原内容特征)和模态间信息uid(所有模态共享的id信息)。具体操作是先融合um和uid,然后再和hm进行融合,公式如下:
其实代码实现比文章更好理解。做了三个gcn之后得到平均的表示再预测就行:
-
#gcn部分的forward -
def forward(self, features, id_embedding): -
temp_features = self.MLP(features) if self.dim_latent else features -
x = torch.cat((self.preference, temp_features),dim=0) -
x = F.normalize(x).cuda() -
h = F.leaky_relu(self.conv_embed_1(x, self.edge_index))#equation 1 -
x_hat = F.leaky_relu(self.linear_layer1(x)) + id_embedding if self.has_id else F.leaky_relu(self.linear_layer1(x))#equation 5 -
x = F.leaky_relu(self.g_layer1(torch.cat((h, x_hat), dim=1))) if self.concate else F.leaky_relu(self.g_layer1(h)+x_hat) -
h = F.leaky_relu(self.conv_embed_2(x, self.edge_index))#equation 1 -
x_hat = F.leaky_relu(self.linear_layer2(x)) + id_embedding if self.has_id else F.leaky_relu(self.linear_layer2(x))#equation 5 -
x = F.leaky_relu(self.g_layer2(torch.cat((h, x_hat), dim=1))) if self.concate else F.leaky_relu(self.g_layer2(h)+x_hat) -
h = F.leaky_relu(self.conv_embed_3(x, self.edge_index))#equation 1 -
x_hat = F.leaky_relu(self.linear_layer3(x)) + id_embedding if self.has_id else F.leaky_relu(self.linear_layer3(x))#equation 5 -
x = F.leaky_relu(self.g_layer3(torch.cat((h, x_hat), dim=1))) if self.concate else F.leaky_relu(self.g_layer3(h)+x_hat) -
return x -
#模型部分的forward -
def forward(self): -
#得到三个模态的表示 -
v_rep = self.v_gcn(self.v_feat, self.id_embedding) -
a_rep = self.a_gcn(self.a_feat, self.id_embedding) -
# # self.t_feat = torch.tensor(scatter_('mean', self.word_embedding(self.words_tensor[1]), self.words_tensor[0])).cuda() -
t_rep = self.t_gcn(self.t_feat, self.id_embedding) -
-
representation = (v_rep+a_rep+t_rep)/3 -
self.result = representation -
return representation
MKGAT
论文:Multi-modal Knowledge Graphs for Recommender Systems
地址:https://zheng-kai.com/paper/cikm_2020_sun.pdf
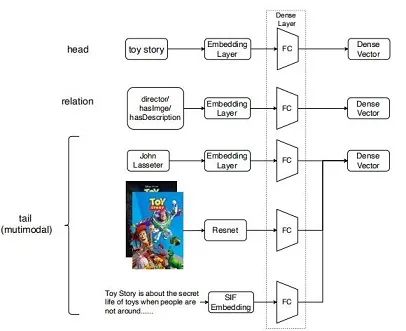
出自CIKM20,作者提出了多模态知识图关注网络(MKGAT)。这篇文章通过利用多模态知识图谱来更好地增强推荐系统。看起来很不错,首先需要考虑的是如何构建一个多模态知识图谱呢?
作者认为多模态信息实质是对原实体信息的补充,所以整个图将会存在四种节点:user,item,entity,mm(多模态补充信息将会一起处理,如上图所示,tail的multimodl表示包含了tag,image,sentence等等,他们会统一抽特征然后表示)。
然后根据这个MMKG,模型主要可以做:
-
实体信息聚合,将实体的邻居节点信息聚合起来,丰富实体本身
-
实体关系推理,通过三重(例如TransE)的评分函数构造推理关系)
模型的构建如下图,就模型设计上主要是加了层次GAT。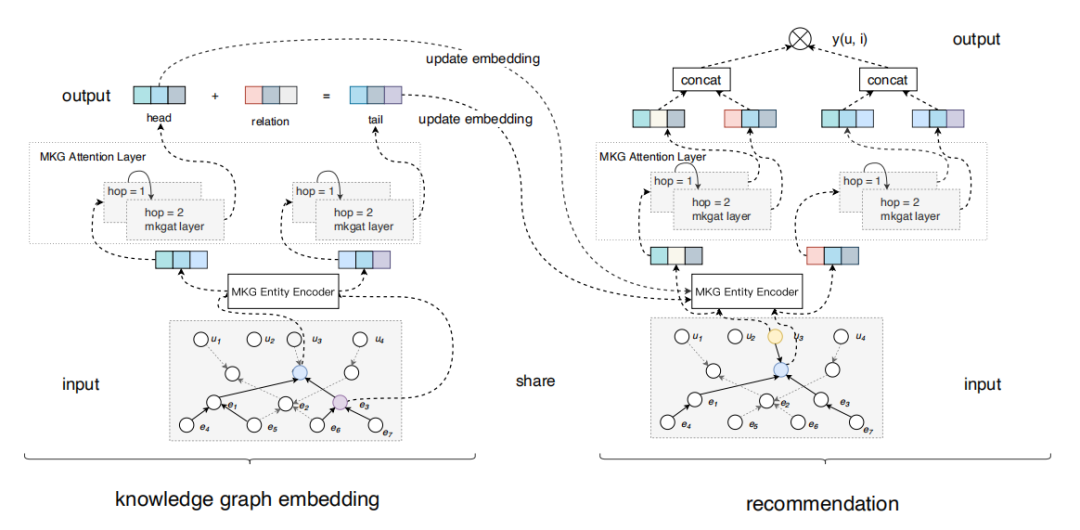
-
Propagation layer。实体嵌入用transE,关于KG的部分博主做过整理了,不做赘述,传送门[2]。公式如下:
-
Aggregation layer。聚合层是得到关于实体的新表示,也是有多种表示方法,如加和和拼接:
-
然后可以得到训练KG的公式:
再利用score对三元组进行训练:
-
推荐部分直接内积就行,其中e会合并所有层的表示:
这篇关于###好好好#####BOOM!推荐系统遇上多模态信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








