本文主要是介绍[~ Tue, 26 July 2016] Deep Learning in arxiv,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Deep3D:Fully Automatic 2D-to-3D Video Conversion with Deep Convolutional NeuralNetworks
论文:http://homes.cs.washington.edu/~jxie/pdf/deep3d.pdf
代码:https://github.com/piiswrong/deep3d
用DL做2D转3D的尝试
SqueezeNet: AlexNet-level accuracy with 50x fewerparameters and <0.5MB model size
论文:http://arxiv.org/pdf/1602.07360v3.pdf
代码:https://github.com/DeepScale/SqueezeNet
模型压缩中比较实用的一篇论文
Training Region-based Object Detectors with Online Hard Example Mining
论文:http://arxiv.org/pdf/1604.03540v1.pdf
在训练frcnn的同时,加入了hard example mining的机制,可以简单的认为,在每次bath forward的时候,根据loss的排序选取loss较大的前k名(绿色部分);然后用这前k名样例进行前向以及后向更新(红色部分)。该策略具有通用性,是一个比较好的工程策略用来提升模型精度。
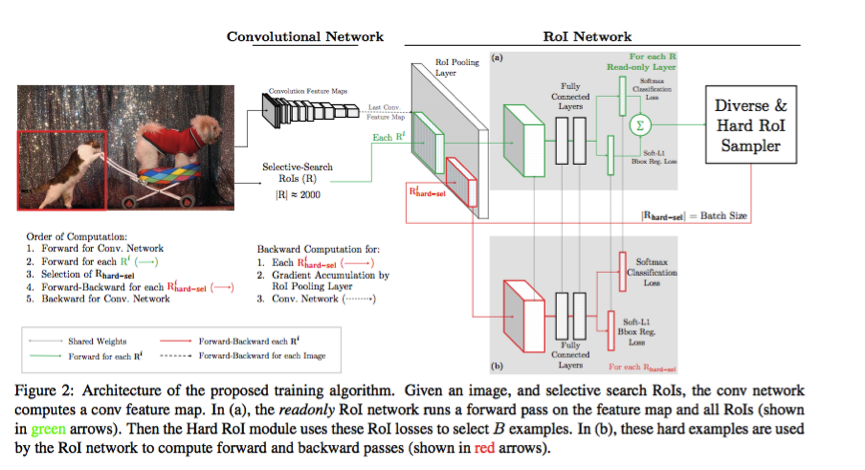
分割训练技巧。
DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINEDQUANTIZATION AND HUFFMAN CODING
a three stage pipeline: pruning, trained quantization and Huffman coding, that work together to reduce the storage requirement of neural networks by 35× to49× without affecting their accuracy. Our method first prunes the network by learning only the important connections. Next, we quantize the weights to enforce weight sharing, finally, we apply Huffman coding. After the first two steps we retrain the network to fine tune the remaining connections and the quantized centroids. Pruning, reduces the number of connections by 9× to 13×;Quantization then reduces the number of bits that represent each connection from 32 to 5. On the ImageNet dataset, our method reduced the storage required by AlexNet by 35×, from 240MB to 6.9MB, without loss of accuracy.
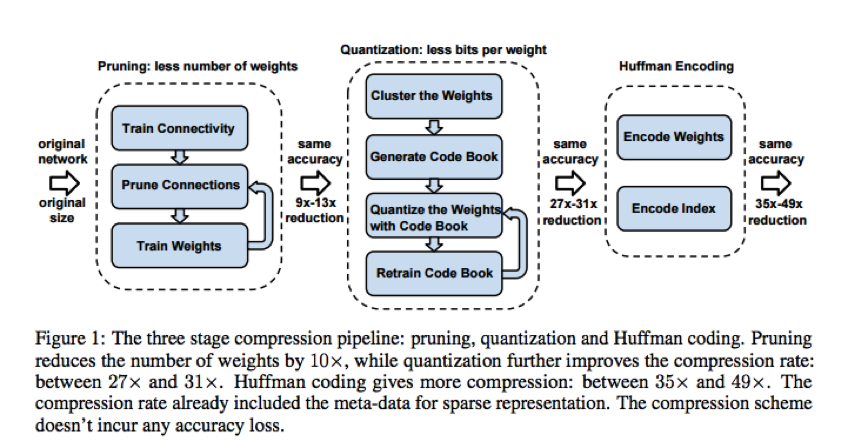
Pruning:训练网络->修剪连接(根据阈值)->训练修剪后的网络;该阶段可以为alexnet和vgg-16分别减少了9x与13x的参数。
Quantization:kmeans+linear initialization做weight sharing(目标是类内差总和最小),然后再基于quantization的网络再做更新;加上该阶段可以减少大概27x到31x倍的参数。
HUFFMANCODING:霍夫曼编码可以节省20%~30%的参数;加上该阶段可以减少大概35x到49x倍的参数。
模型压缩
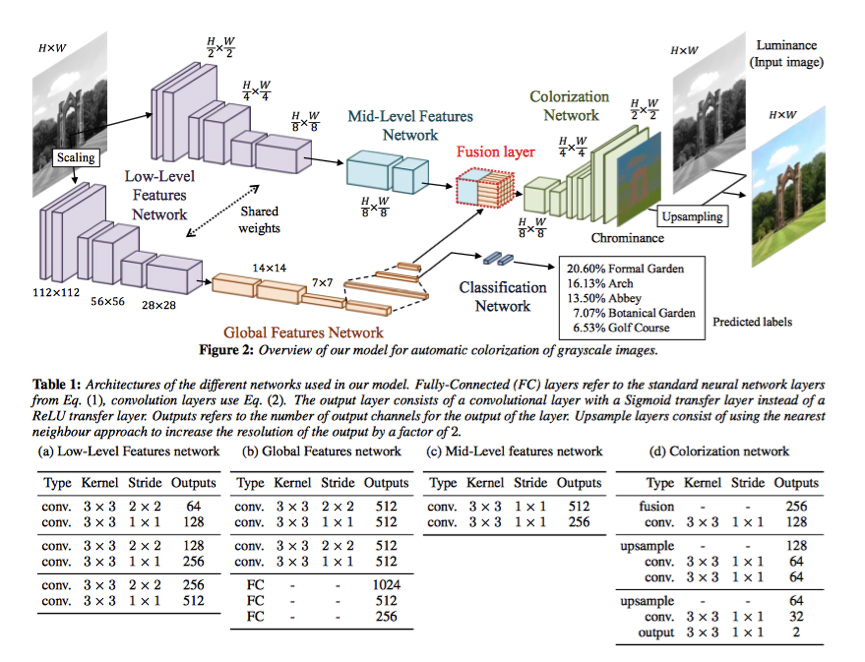
Let there be Color: Joint End-to-endLearning of Global and Local Image Priors for Automatic Image Colorization withSimultaneous Classification
论文:http://hi.cs.waseda.ac.jp/~iizuka/projects/colorization/data/colorization_sig2016.pdf
代码:https://github.com/satoshiiizuka/siggraph2016_colorization
SIGGRAPH 2016
网络结构图:
效果图:

图片着色,非常犀利的应用点
Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
http://research.microsoft.com/en-us/um/people/jfgao/paper/2013/cikm2013_DSSM_fullversion.pdf
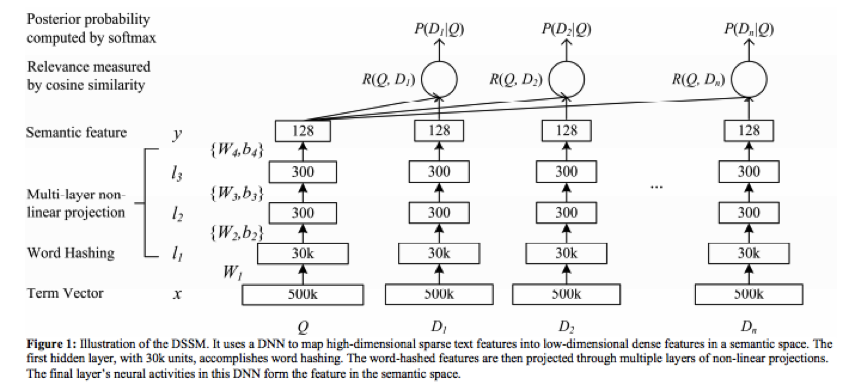
微软的dssm用于ctr相关
Benchmarking Deep Reinforcement Learning for Continuous Control
http://arxiv.org/pdf/1604.06778v2.pdf
https://github.com/rllab/rllab
该文章提出了reinforcement learning的benchmark,给出了一系列task,以及相应baseline算法的效果。
Exploiting Cyclic Symmetry in Convolutional Neural Networks
http://arxiv.org/pdf/1602.02660v1.pdf
基于theano的代码,https://github.com/benanne/kaggle-ndsb
卷积层与pooling层的联合效果解决了部分平移不变性(小尺度),该文章提出了如何将部分旋转不变性(0度、90度、180度、270度)做到模型架构里。
尝试将数据多样性直接encode到网络中
Pixel Recurrent Neural Networks
http://arxiv.org/pdf/1601.06759v2.pdf
效果图:

网络结构:

该文章尝试构建image色彩分布,利用该色彩分布模型完成图像补全,效果还是蛮有意思的。
Disturb Label:Regularizing CNN on the Loss Layer
http://research.microsoft.com/en-us/um/people/jingdw/pubs%5CCVPR16-DisturbLabel.pdf
CNN训练model regularization包括:weight decay, model averaging, data augmentation
DisturbLabel按照generalized Bernoulli分布对样本选择disturb or not,然后按均匀分布选择将disturb的标置为哪个类。
训练时的数据干扰,来加强模型的鲁棒性,也算一种模型归一化
这篇关于[~ Tue, 26 July 2016] Deep Learning in arxiv的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









