本文主要是介绍电动汽车充电站充电桩数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

需要的同学私信联系,推荐关注上面图片右下角的订阅号平台 自取下载。
随着环保意识的不断增强和能源危机的加剧,新能源汽车作为一种清洁、高效、可持续的出行方式在未来出行中扮演着重要角色。而AI技术的迅猛发展也为新能源汽车的智能驱动提供了广阔的应用空间。
AI技术可以深度融入能源管理系统,系统可以根据车辆的行驶路线和充电需求,在合适的时间和地点安排充电,最大限度地延长电池寿命,提高续航里程。同时,系统还可以通过分析车辆行驶数据和能源消耗模型,预先感知车辆可能发生的故障,实时评估车辆的健康度指标,优化车辆的能源消耗策略,降低能源消耗,提高能源利用效率。因此小编整理了一份超完整的AI+新能源汽车数据合集,包含5+细分场景数据集,助力AI+新能源汽车的研究与创新。来吧,涨涨知识~
1. 粤港澳大湾区新能源汽车健康度数据集
2. 电动汽车充电站用户行为数据集
3. 电动汽车充电站充电运营数据集
4. 中国城市电动汽车充电桩数据集
5. 电动汽车充电需求时空数据集
01
—
粤港澳大湾区新能源汽车健康度数据集

【数据背景】为了有效应对新能源汽车大数据引起的挑战,同时充分利用大数据带来的机遇,以资源统筹、共享、开放为切入点,协助有关部门建立“用数据说话、用数据决策、用数据管理、用数据创新”的新能源汽车科学治理方式,需紧密结合新能源汽车实际运行情况,利用大数据挖掘方法,针对性建立相关模型,以分析新能源汽车运行情况和性能变化。
【应用领域】AI+新能源汽车生命周期管理
【数据任务】基于本数据集可以进行如下3个任务的深入研究:
任务1:新能源汽车故障预测与健康管理
新能源汽车由动力电池、电机、电控等系统组成,是一个复杂的控制系统。车辆经过长时间运行后,其故障发生概率会升高、整车健康状态会降低,而且这种变化是不可逆的。因此,本任务以广州市新能源智能汽车大数据监测平台的数据为基础,要求挖掘影响整车、动力电池、电机、电控等方面的安全要素,分析时间、行驶里程等维度下的关键部件安全特征规律,构建新能源汽车运行安全特征分析模型。可以一个关键部件的故障预测与健康管理为依托,通过融合其他关键部件信息进行整车故障预测与管理。
通过提供的车辆运行数据,基于车辆运行过程中的SOC、里程、速度、电流、电压、温度等数据,建立新能源汽车故障预警模型、整车健康评估模型,并形成最终方案。
任务2:新能源汽车动态能耗估计与剩余里程预测
新能源汽车实时的能耗与剩余里程会随着车辆驾驶状况的变化而变化,但目前关于实时能耗与剩余里程的精确估计尚缺少有效的方法,从而导致里程焦虑成为现阶段新能源汽车推广中所遇到的较为普遍的问题,这是由于驾驶过程的动态能耗估计与剩余里程预测并未系统性的考虑车主个人驾驶习惯、历史道路情况。
通过提供的车辆运行数据,基于车辆运行过程中的SOC、里程、速度等数据,以及外部公开数据,如天气数据(外部公开数据非必须采用的数据),建立新能源汽车整车实时能耗估计模型与剩余里程预测模型,并形成最终方案。
任务3:新能源汽车用户行为分析与分类
新能源汽车车主个性化的驾驶行为导致每台新能源汽车在用户驾驶风险、驾驶习惯、充电习惯、出行规律等方面均存在差异。车企、保险公司、二手车交易对不同的驾驶习惯会采取差异性的规则。因此,对新能源汽车用户行为的分析与分类,有利于新能源汽车售后服务、城市规划的开展。利用新能源车辆状态数据分析充换电行为的空间分布与时间分布,结合新能源汽车的使用特征,有效评价和评估充换电设施空间布局网络。
通过提供的车辆运行数据,基于车辆运行过程中的多维数据数据,以及外部公开数据(外部公开数据非必须采用的数据),建立新能源汽车用户行为分析与分类模型,并形成最终方案。
【数据目录】包含车型A和车型B共2个数据文件夹
【数据说明】为保障数据隐私安全,数据已进行了适当的脱敏处理,删除了部分敏感信息。数据存在缺失现象,是正常缺失,可能是车辆物联网卡故障导致的缺失。数据集涵盖A、B两种车型各5台纯电新能源汽车半年多的运行数据。根目录下分为A车型、B车型两个文件夹,文件夹内各有5辆车的运行数据,车辆运行数据文件夹内每一个文件为一台车一个月的运行数据,如文件名为:CL1_20220101000000_20220131235959的文件,代表车辆1,2022年1月1日00:00:00至2022年1月31日23:59:59之间的运行数据。车辆运行数据中的字段信息非常丰富,包含35+数据字段,具体如下:
1. 数据时间
2. 最高报警等级
3. 车速
4. 车辆状态
5. 充电状态
6. 运行模式
7. 累计里程
8. 总电压
9. 总电流
10. SOC
11. DC-DC状态
12. 挡位
13. 挡位驱动力
14. 绝缘电阻
15. 最高电压电池子系统号
16. 最高电压电池单体代号
17. 电池单体电压最高值
18. 最低电压电池子系统号
19. 最低电压电池单体代号
20. 电池单体电压最低值
21. 最高温度子系统号
22. 最高温度探针单体代号
23. 最高温度值
24. 最低温度子系统号
25. 最低温度探针子系统代号
26. 最低温度值
27. 通用报警标志
28. 可充电储能装置故障总数
29. 驱动电机故障总数
30. 可充电储能装置故障代码列表
31. 驱动电机故障代码列表
32. 发动机故障总数
33. 发动机故障代码列表
34. 其他故障总数
35. 其他故障代码列表
上述数据字段的具体含义可参考GB/T 32960-2016,并结合《电动汽车远程服务与管理系统技术规范 第3部分:通信协议及数据格式》进行相关资料查询。
02
—
电动汽车充电站用户行为数据集

【数据背景】电动汽车在全球越来越受欢迎。大规模充电将需要新的架构和调度,以避免对电网的不利影响,同时降低资本和运营成本。然而,从理论到实践的转变需要处理实践系统的复杂性,在简化的理论模型中,这些复杂性往往被忽视。ACN是一个工具数据集,旨在帮助研究人员和其他利益相关者了解大规模电动汽车充电的挑战,并为这些挑战制定切实可行的解决方案。为了帮助研究人员获取电动汽车充电的真实数据,数据通过与美国自适应充电网络运营商PowerFlex Systems的密切合作整理得到。
【应用领域】AI+电动汽车充电网络
【数据简介】这是一个电动汽车充电站点的动态数据集,数据集中的每个条目都包含关于单个充电站点的会话信息,目前包括30000多个会话,每天都会增加更多会话。数据集共包含3个站点:
Caltech:位于加利福尼亚州帕萨迪纳的一所研究型大学,目前在一个校园车库中收集了54台电动车辆的数据,大多数用户来自教职员工和学生
JPL:位于加利福尼亚州La Canada的一个国家研究实验室,目前有50个电动汽车供电设备(Electric Vehicle Supply Equipment,EVSE),仅对员工开放,可以表示正常的工作日程
Office001:位于硅谷地区的一座办公楼,目前有8个EVSE,仅供员工使用
【数据目录】Caltech.json、JPL.json和Office1.json
【数据说明】包含上述3个充电站点的json格式的用户行为日志数据,数据字段的具体情况如下所示:
1. _id:string,充电会话记录的唯一标识符
2. chargingCurrent:timeseries,充电会话期间电动车辆供电设备测量电流消耗的时间序列
3. clusterID:string,站点内EVSE的唯一标识符
4. connectionTime:datetime,电动汽车接通电源的时间
5. disconnectTime:datetime,电动汽车断开电源的时间
6. doneChargingTime:datetime,最近一次记录的非零电流消耗的时间
7. kWhDelivered:float,充电会话期间传递的能量
8. pilotSignal:timeseries,会话期间电动车辆供电设备导频信号的时间序列
9. sessionID:string,充电会话的唯一标识符
10. siteID:string,充电站点的唯一标识符
11. spaceID:string,停车位的唯一标识符
12. stationID:string,电动汽车供电设备的唯一标识符
13. timezone:string,基于pytz格式的站点时区
14. userID:string,用户的唯一标识符
15. userInputs:list,用户提供的输入,由于输入可以随时间变化,可能有多个用户输入对象
User Inputs
16. WhPerMile:float,电动汽车的效率,单位为Wh/英里
17. kWhRequested:float,用户要求的电量(kWh)
18. milesRequested:float,用户请求的英里数
19. minutesAvailable:float,用户估计的充电会话时长
20. modifiedAt:datetime,用户输入被提供的时间
21. paymentRequired:bool,用户是否需要为充电会话付费
22. requestedDeparture:datetime,用户预计出发时间
23. userID:string,用户的唯一标识符
Time Series
24. timestamps:list(datetime),时间戳列表
25. pilot/current:list(float),每个时间戳一个值的列表
03
—
电动汽车充电站充电运营数据集

【数据背景】在电动汽车充电站运营管理中,准确预测充电站的电量需求对于提高充电站运营服务水平和优化区域电网供给能力非常关键。数据集的创建旨在建立站点充电量预测模型,根据充电站的相关信息和历史电量数据,准确预测未来某段时间内充电站的充电量需求。利用机器学习、深度学习、时间序列等相关技术,建立预测模型来预测未来一段时间内的需求电量,优化充电场站的运营和效益,帮助管理者提高充电站的运营效益和服务水平,促进电动汽车行业的整体发展。
【应用领域】AI+充电量需求预测
【数据简介】数据集提供了电动汽车充电站的场站编号、位置信息、历史电量等基本信息。根据所提供的电动汽车充电站多维度脱敏数据,构造合理特征及算法模型,预估站点未来一周每日的充电量(以小时为单位),并在已有数据的基础上补充或构造额外的特征,以获得更好的预测性能。
【数据目录】包含的数据表如下:
power_forecast_history.csv
power.csv
stub_info.csv
【数据说明】共包含3个csv数据表,power_forecast_history.csv 为站点运营数据,power.csv为站点充电量数据,stub_info.csv为站点静态数据,训练集为历史一年的数据,测试集为未来一周的数据。数据字段的具体情况如下所示:
power_forecast_history.csv
1. id_encode:场站编码
2. hour:小时
3. ele_price:电费
4. ser_price:服务费
5. after_ser_price:折后服务费
6. total_price:总费用
7. f1:业务指标1(见备注2)
8. f2:业务指标2(见备注2)
9. f3:业务指标3(见备注2)
10. ds:日期
power.csv
1. id_encode:场站编码
2. hour:小时
3. power:充电量
4. ds:日期
stub_info.csv
1. id_encode:场站编码
2. parking_free:停车收费,0表示收费,1—9表示免费小时数
3. flag:场站标签(见备注2)
4. h3:h3编码(见备注1)
5. ac_equipment_kw:交流桩额定功率
6. dc_equipment_kw:直流桩额定功率
备注:
(1)h3编码是一种用于分层地理编码的系统,可以将地球划分为不同的六边形网格,可以尝试使用 h3 编码来构造与地理位置相关的额外特征;
(2)脱敏字段,不提供字段业务描述,供自由探索。
04
—
中国城市电动汽车充电桩数据集

【数据背景】电动汽车充电桩会产生各种与电动汽车和充电桩有关的数据,例如充电桩的位置、充电桩的类型、充电桩的功率、充电桩的使用情况等。基于这样的数据集可以用于许多应用,例如:通过分析充电桩数据集,可以确定在哪些地区或特定位置需要建设新的充电桩,以满足电动车用户的需求。通过分析历史的充电桩使用数据,可以预测未来的充电需求,并优化充电桩的分布和管理。将充电桩数据集与其他数据集(如交通流量数据、天气数据等)结合分析,可以获得有关充电桩使用的更深入洞察。这些洞察可以用于政策制定、市场研究等领域。
【应用领域】AI+电动汽车充电桩
【文件目录】original_data和processed data在内的2个数据文件夹
【数据说明】包括来自中国北京、上海和深圳9个充电站共27个充电桩的充电数据。原始文件包括充电桩地理信息、时间、车辆状态、SOC、电流、电压等信息。数据点的采样时间约为18秒,数据跨度为一年半。
original_data文件夹包含的是原始数据csv和充电桩信息xlsx,其中原始数据csv有6个数据字段,分别为:
1. time,表示时间
2. vehicle state:车辆状态
3. voltage:充电电压,单位为V
4. current:充电电流,单位为A
5. SOC:充电车辆SOC,单位为%
6. 充电电量:车辆充电电量,单位为度
充电桩信息xlsx包含27个充电桩及其地理固有属性字段,分别为桩功率(单位为kW)、桩ID、桩群地址、区域编码、纬度、经度、省、市和区。
processed data文件夹包含的是处理后的数据,分别生成了18s和1h两份不同分辨率的数据。以18s resolution的数据为例,/18s resolution含有的表名为“fixed2_18seconds_10069936.csv”,表示桩ID为10069936的18s分辨率的处理后数据,csv包含时间和桩充电功率2个数据字段。
05
—
电动汽车充电需求时空数据集
【数据背景】时空预测已受到越来越多的研究关注,尤其是智能交通领域,因其提供的未来信息能够很好地帮助政策制定。在时空交通预测领域,很多成熟的数据集,比如交通流预测、交通速度预测数据集,给研究者提供了很好的研究平台,推动了智能交通系统的发展。而随着近年来电动汽车保有量的爆炸性增长,电动汽车充电需求的时空预测却缺少一个数据质量良好的城市级别数据集,导致在该方向上的很多重要研究(比如动态充电定价、充电桩推荐等等)受到了阻碍。为了填补这一研究空缺,本文收集和整理了一个来自真实世界的数据集。
【应用领域】AI+充电需求时空预测
【数据描述】数据采集来自深圳市18,061个公共充电桩一个月(2022年6月19日—2022年7月18日)的使用记录 。在时序维度,数据集的时间颗粒度为5min,共有8640个时间戳。在空间维度,它覆盖了深圳市的247个交通小区(节点)及其 1006条相邻关系(边),构成了如下图所示的图结构数据。

此外,该数据集还包括了各个区域所采用的充电定价方案:在这247个交通区中,有57个(红线框内)采用分时段收费方案,其他则采用固定收费方案。更多统计详情见下表。
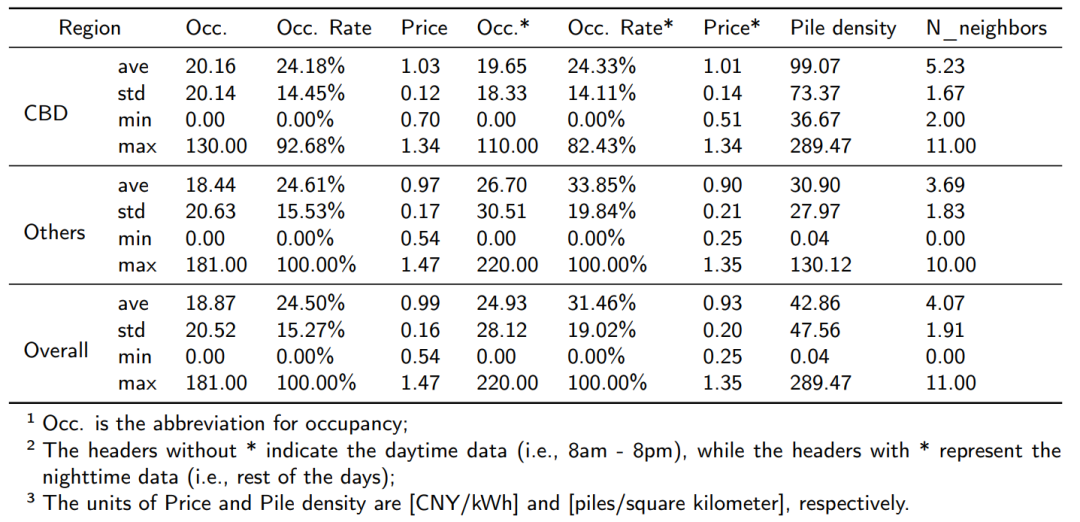
【数据说明】/Datasets为数据文件夹,/ST-EVCDP-main为官方项目源码,2309.05259.pdf为基于该数据集的已发表论文,数据集详细情况可以参考/ST-EVCDP-main和2309.05259.pdf。
/Datasets包含以下7份数据文件:
adj.csv:研究区域的相邻矩阵,1表示两个交通区域相邻,反之不相邻
distance.csv:节点之间的距离
information.csv:数据基本信息,包括桩容量、经度、纬度、是否位于中央商务区(1:是,0:否)以及是否基于时间定价方案(1:是,0:否)
occupancy.csv:研究区域的实时电动汽车充电占用率
price.csv:研究地区的实时电动汽车充电定价
time.csv:研究期间的时间戳
Shenzhen.qgz:深圳市QGIS地图文件
Shenzhen.qgz存储的是深圳市交通小区数据,使用免费轻量版工具QGIS即可打开。
06
—
结束语
以上就是AI+新能源汽车数据集的所有内容了,更多数据集下载请关注文章顶部图片右下角平台即可获取。
这篇关于电动汽车充电站充电桩数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





