本文主要是介绍pytorch花式索引提取topk的张量,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- pytorch花式索引提取topk的张量
- 问题设定
- 代码实现
- 索引方法
- gather方法
- 验证
- 补充知识
- expand方法
- gather方法
- randint
pytorch花式索引提取topk的张量
问题设定

或者说,有一个(bs, dim, L)的大张量,索引的index形状为(bs, X),想得到一个(bs, dim, X)的reduced向量。我们在进行topk操作(以减少计算量)的时候经常碰到这种情况。
给出如下两种实现方法,分别使用花式索引(参考informer的代码)以及pytorch的gather方法
代码实现
索引方法
参考https://blog.csdn.net/qq_36560894/article/details/122005808
feature = torch.rand(2,16,4*4)
indices = torch.randint(0,16, (2, 3))
indices
indices_expand = indices.unsqueeze(1).expand(-1, dim, -1).to(torch.long) # (bs, dim, H*W)
indices_expand.shape
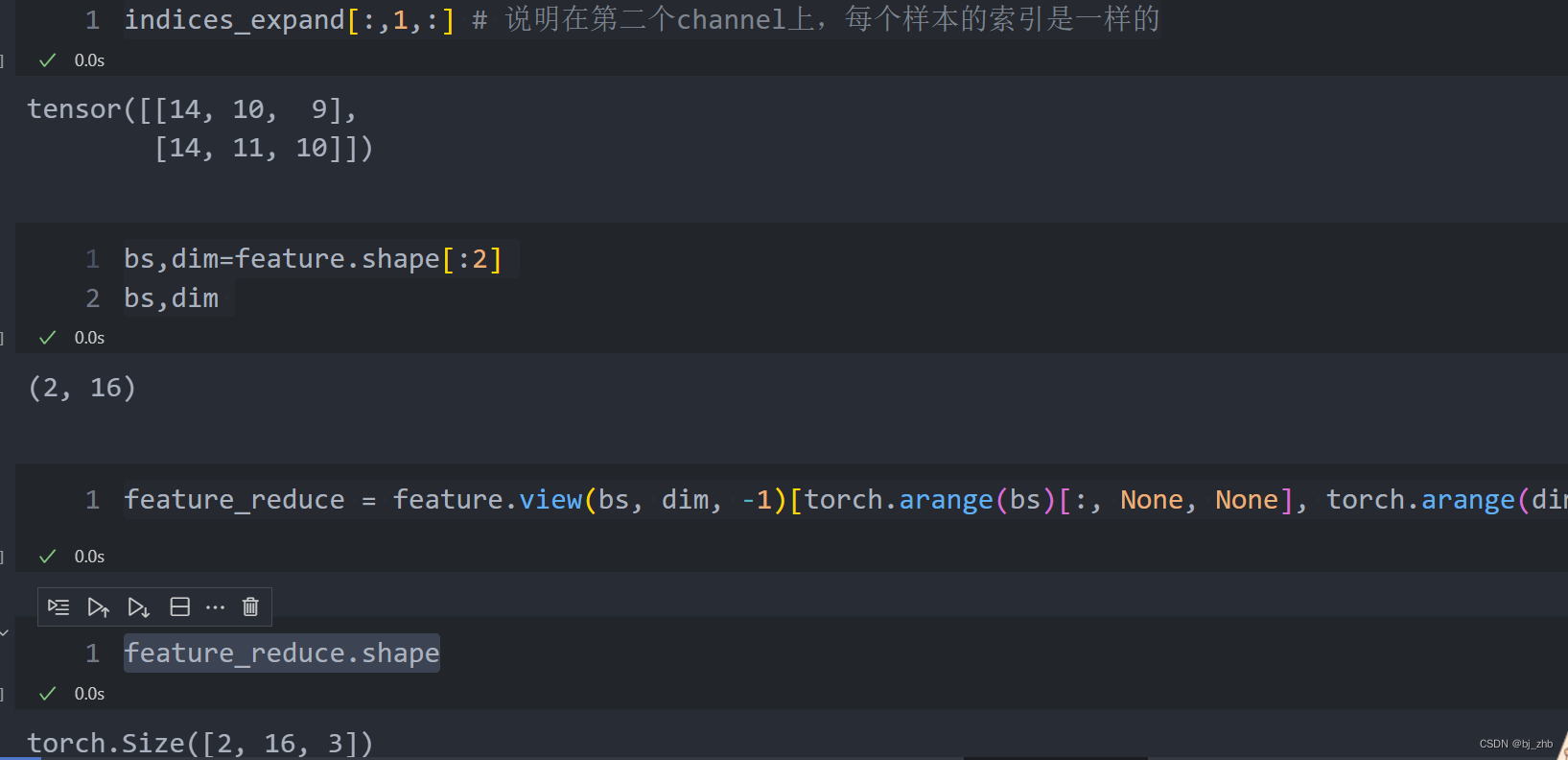
indices_expand[:,1,:] # 结果和indices一致,说明在第二个channel上,每个样本的索引是一样的
bs,dim=feature.shape[:2]
bs,dim
feature_reduce = feature.view(bs, dim, -1)[torch.arange(bs)[:, None, None], torch.arange(dim)[None,:,None], indices_expand]
feature_reduce.shape

gather方法
reduce_feature = torch.gather(feature, 2, indices_expand)
验证
两种方法得到的结果完全相同

补充知识
expand方法
在 PyTorch 中,expand() 方法用于扩展张量的大小。它会在不实际复制数据的情况下,重复张量的元素以填充新的形状。这个方法可以用于广播操作,以便在执行一些需要相同形状的张量之间的数学运算时,使它们具有相同的形状。
下面是使用 expand() 方法的基本用法:
import torch# 创建一个原始张量
x = torch.tensor([[1, 2, 3],[4, 5, 6]])# 使用 expand 扩展张量的大小
expanded_x = x.expand(2, 3, 4) # 扩展成维度为(2, 3, 4)的张量print(expanded_x)
在上面的例子中,我们首先创建了一个形状为 (2, 3) 的原始张量 x。然后,我们使用 expand() 方法将其扩展成一个维度为 (2, 3, 4) 的新张量 expanded_x,该张量的形状是在原始张量形状的基础上每个维度都扩展了一倍。
需要注意的是,expand() 方法只能用于增加张量的大小,不能减小。另外,扩展后的张量与原始张量共享底层数据,因此在原始张量上进行的任何修改都会反映在扩展后的张量上,反之亦然。
gather方法
在 PyTorch 中,gather() 方法用于从输入张量中按照指定索引提取元素。这个方法通常用于根据索引收集特定的元素,例如根据类别索引从分类得分张量中获取对应类别的得分。
下面是使用 gather() 方法的基本用法:
import torch# 创建一个输入张量
input_tensor = torch.tensor([[1, 2],[3, 4],[5, 6]])# 创建一个索引张量
indices = torch.tensor([[0, 0],[1, 0]])# 使用 gather 方法根据索引收集元素
output_tensor = torch.gather(input_tensor, dim=1, index=indices)print(output_tensor)
在上面的例子中,我们首先创建了一个形状为 (3, 2) 的输入张量 input_tensor,以及一个形状为 (2, 2) 的索引张量 indices。然后,我们使用 gather() 方法从输入张量 input_tensor 中按照索引张量 indices 收集元素。
在 gather() 方法中,参数 dim 指定了在哪个维度上进行收集操作,而 index 参数指定了收集元素所使用的索引张量。
需要注意的是,索引张量 indices 的形状必须与输出张量的形状一致,或者是可以广播成与输出张量形状一致的形状。
randint
torch.randint() 是 PyTorch 中用于生成随机整数张量的函数。它可以生成一个张量,其中的元素是在指定范围内随机抽样的整数。
下面是 torch.randint() 的基本用法示例:
import torch# 生成一个形状为 (3, 3) 的随机整数张量,范围是 [0, 10)
random_integers = torch.randint(low=0, high=10, size=(3, 3))print(random_integers)
在上面的示例中,我们使用了 torch.randint() 函数来生成一个形状为 (3, 3) 的随机整数张量,其中的元素取值范围在闭区间 [low, high) 内,即从 0 到 9。
torch.randint() 函数的主要参数包括:
low:生成的随机整数的最小值(包含)。high:生成的随机整数的最大值(不包含)。size:生成的张量的形状。
你也可以不指定 low 参数,默认情况下它为 0。此外,还可以使用其他参数来控制生成的随机整数张量的设备类型、数据类型等。
这篇关于pytorch花式索引提取topk的张量的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





