本文主要是介绍Waymo数据集下载与使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在撰写论文时,接触到一个自动驾驶数据集Waymo Dataset
论文链接为:https://arxiv.org/abs/1912.04838v7
项目链接为:https://github.com/waymo-research/waymo-open-dataset
数据集链接为:https://waymo.com/open
waymo提供了两种数据集,motion与perception两种,其中motion是鸟瞰图,官网中有介绍,主要用于轨迹预测之类的任务,perception主要用于目标检测跟踪之类的任务,是第一视角,有相机和雷达信息。
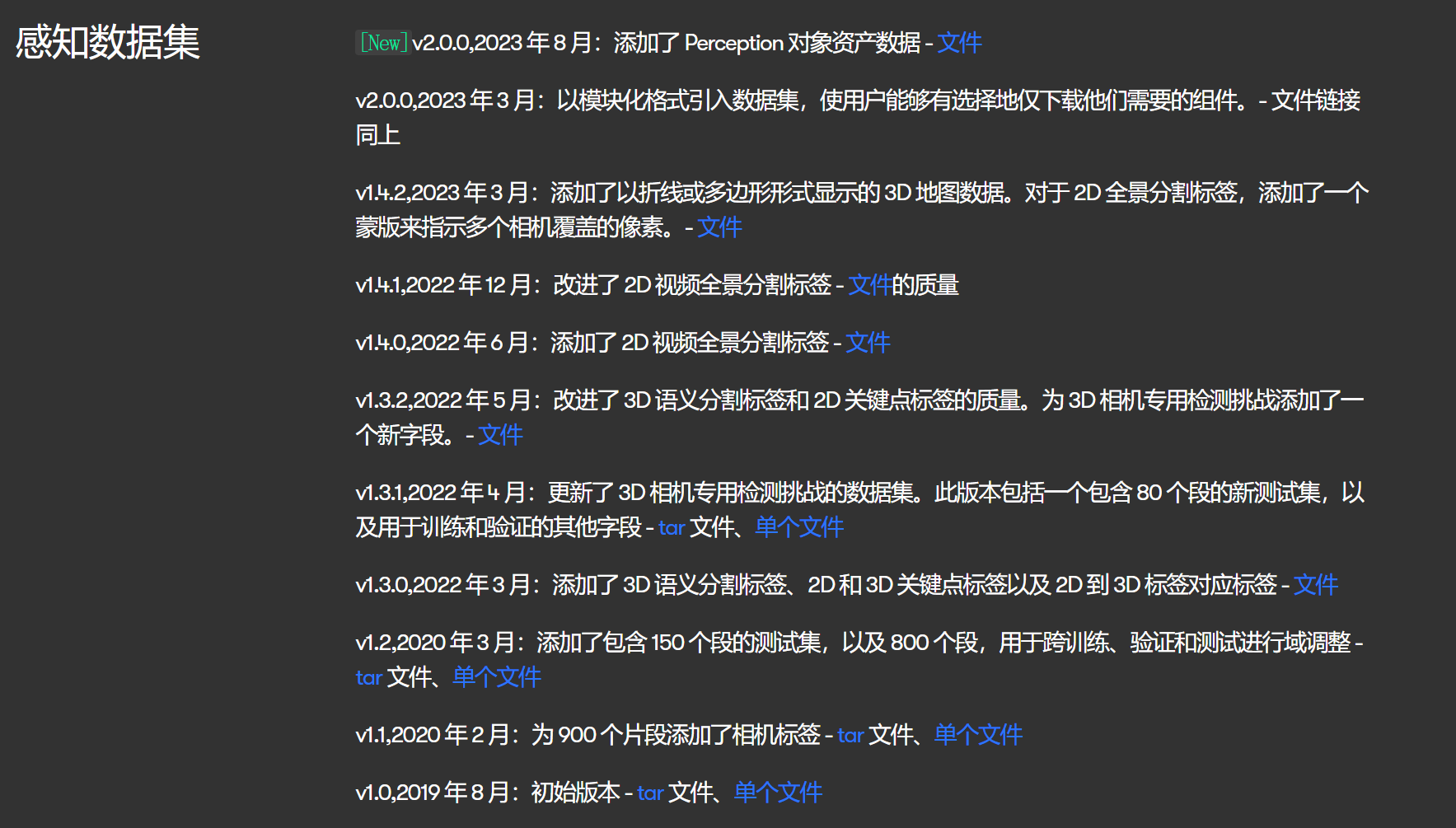
由于该数据集极为庞大,因此要想使用完整版只能前往官网下载。由于博主研究的是2D目标检测,因此只需要使用v1.1版本即可,该数据集提供了两个下载链接,一个是封装好的tar文件,另一个是单个文件,我们分别下载了两个数据集文件进行解析。
在实验中,并不需要将所有的数据集,因此博主只下载了train_0000.tar文件,该数据集也达到近23G。
tar文件展示:
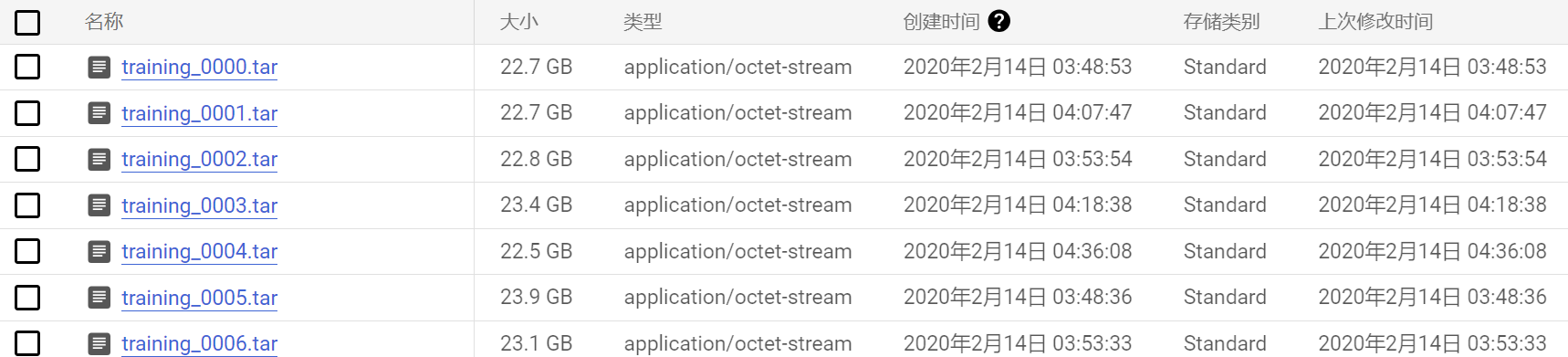
里面的内容是tensorflow读取格式的文件。
如果觉得23个G下载起来太过费时,也可以选择下载单个文件。
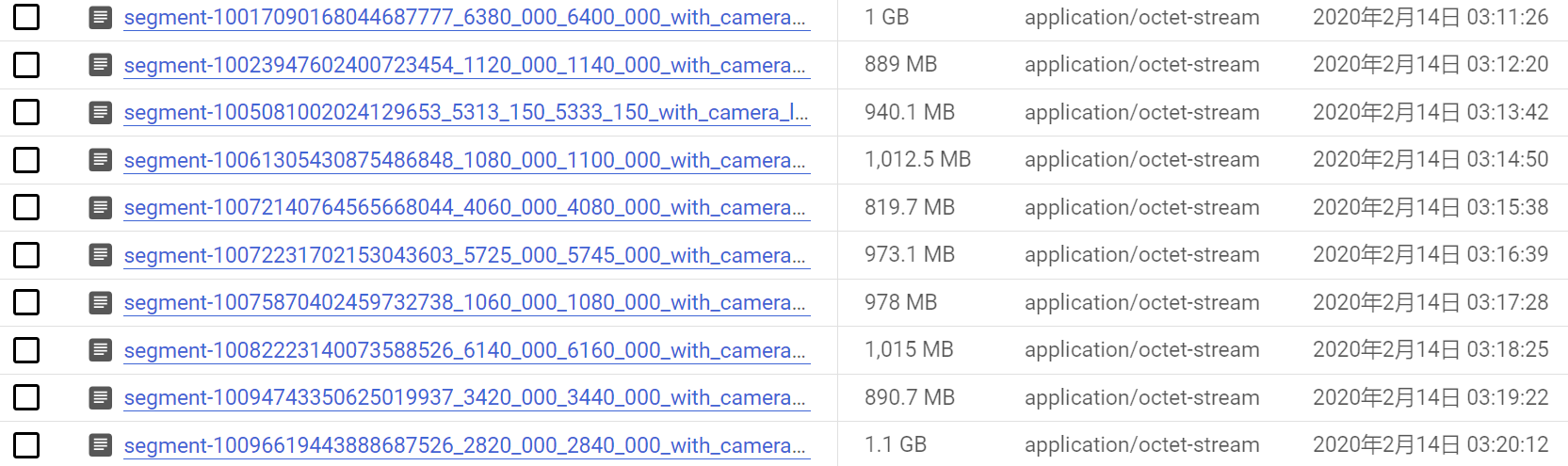
将数据集下载完毕后,该数据集的内容是无法查看的,因为其使用的是Tensorflow读取格式。
那么接下来便有两条路,一条是将我们的模型中的数据集加载方式改为Tensorflow形式,另一种则是将Tensorflow格式的数据集文件重新解码,转换为我们平时使用的数据集形式,博主果断采用第二种。
由于博主使用的数据集类型是COCO格式,因此可以使用下面的方法将Waymo数据集转换为COCO格式。代码下载地址如下:
https://github.com/shinya7y/WaymoCOCO
在该项目的readme中记录了Linux系统下载Waymo数据集并转换的过程,这里博主由于使用的是Windows系统,因此这里博主就不按照他的要求进行了,只需要下载protbuf依赖包即可。
随后按照下面的格式运行代码即可。
python convert_waymo_to_coco.py --tfrecord_dir ${HOME}/data/waymotfrecord/validation/ #tfrecord的存放文件夹路径--work_dir ${HOME}/data/waymococo_f0/ #保存文件夹地址--image_dirname val2020 #保存的图片路径--image_filename_prefix val #val--label_filename instances_val2020.json #保存的json文件--add_waymo_info --frame_index_ones_place 0 #保存的index
之后便将原本tensorflow格式的数据转换为COCO格式了。
这篇关于Waymo数据集下载与使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






