本文主要是介绍基于CRF的命名实体识别思路与实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文参考了https://github.com/liuhuanyong的CRF实现分词的思路
CRF的实现思路类似于HMM,需要求解几个概率(词与词的转移概率,状态与状态的转移概率、发射概率、初始词概率),然后用verbiter方法求解,verbiter方法的原理简单来说就是给出当前状态,求解最有可能转移至该状态的上一个状态,这个原理和思路也是实现CRF的核心。
首先给出宗成庆老师PPT的一个关于CRF中文分词例子(实体识别无非是把字转为词,训练样本是带有标记的):
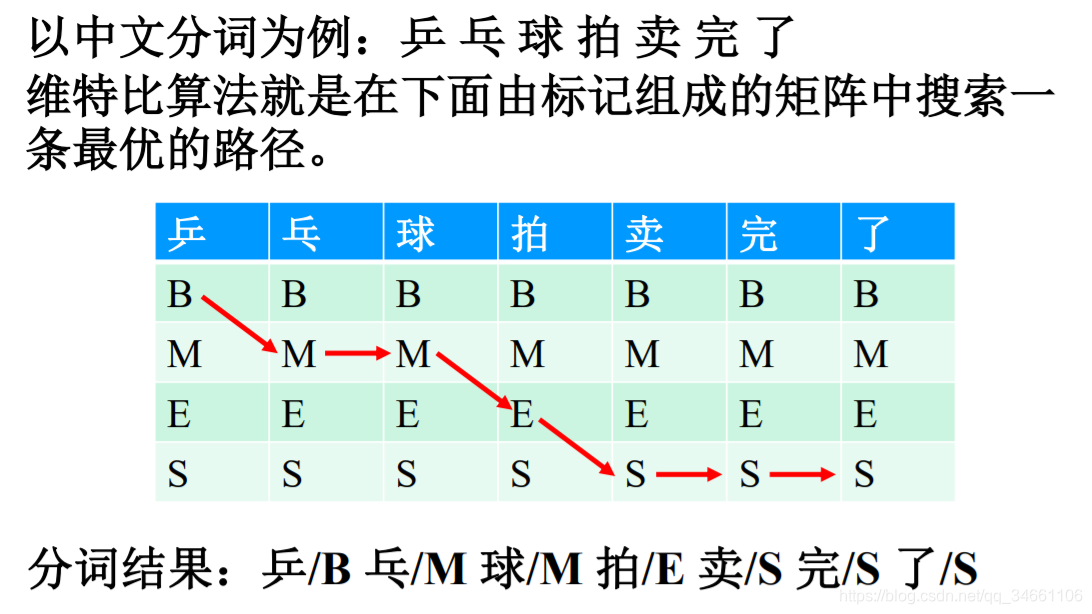
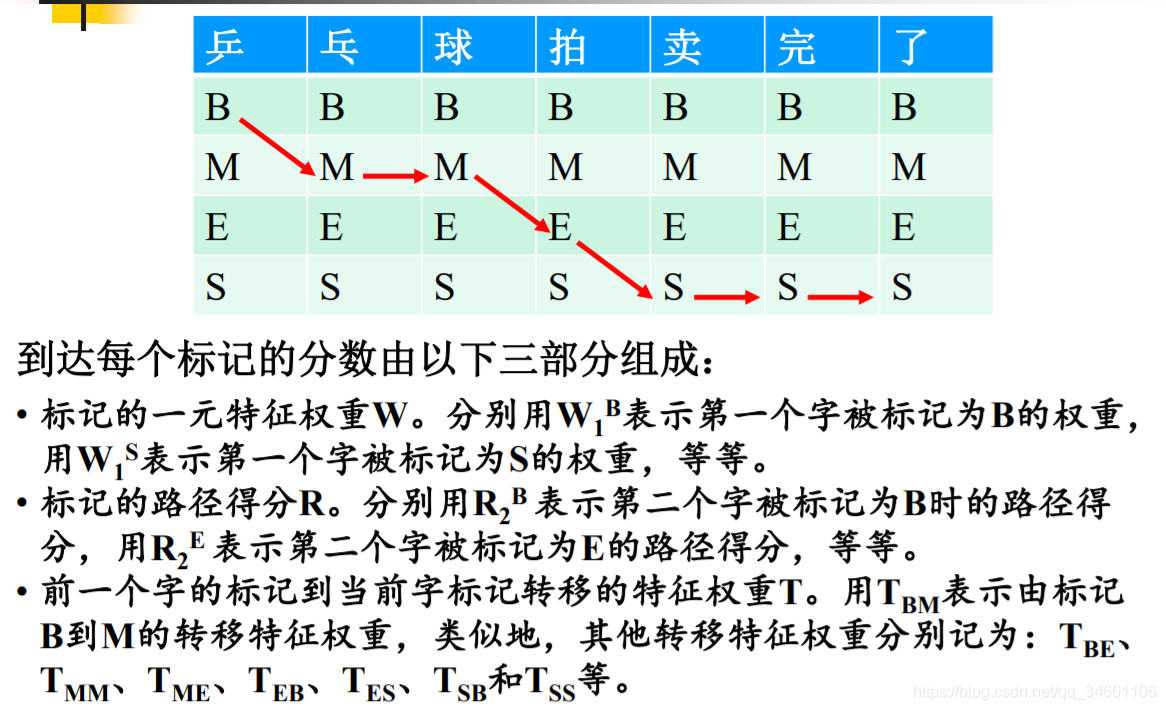

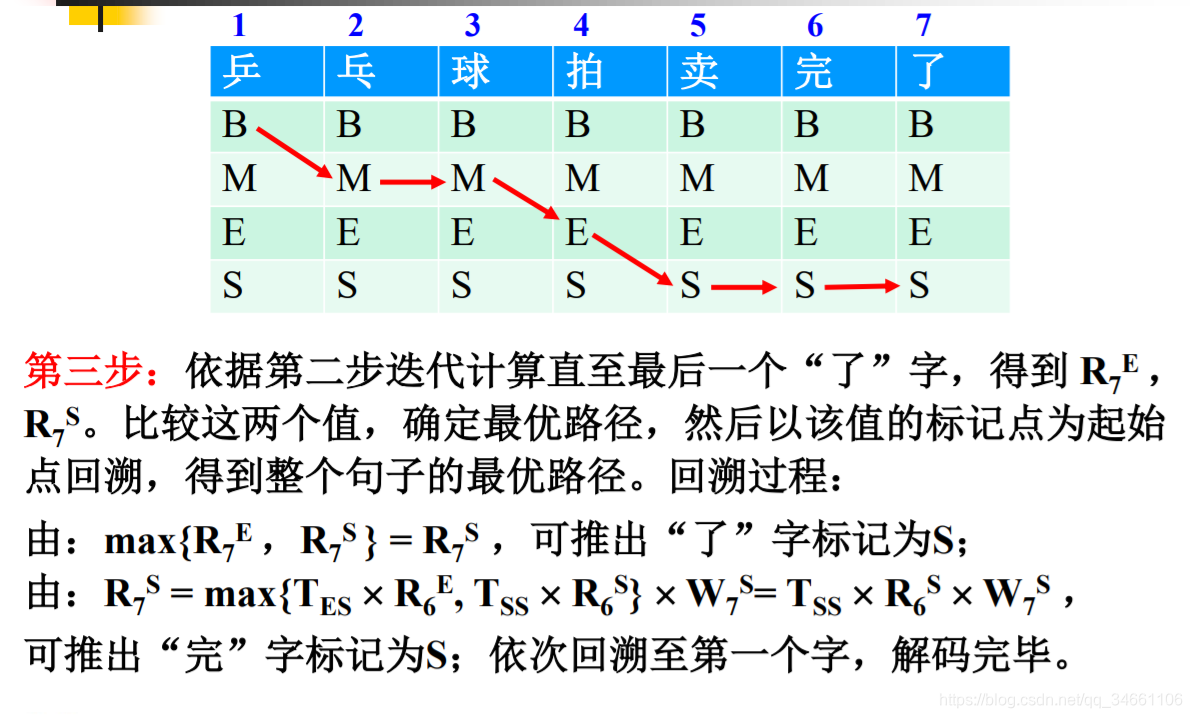
由宗成庆老师PPT的例子可以看到,若使用CRF实现中文分词,总结需要以下几个概率:
1.词与词的转移概率:如下图第一项当前字被标记为B时上一个字为null的概率,但是在本人的实现中,仅仅计算了词与词之间的转移概率,即某词和词之间转移概率不为None,则f为1,λ为某词和词之间的转移概率,否则f=0。如下图若第三项'乒'转移至'乒'的概率不为None,则f(乒,乓,B) = word_trans(乒,乓)
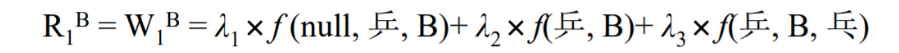
2.初始词概率:从上图第一项f(null,乒,B)则发现又要计算一个概率:null->句子的首词的转移概率,本人的实现中,直接计算每个句子的首词在训练样本中出现的概率strat_word(乒)代替f(null,乒,B)
3.发射概率:即上图的第二项f(乒,B),所谓发射概率即为在某个状态中,某个词出现的可能性有多大。如状态B中有['乒':0.03,'乓':0.02,'我':0.06]
4.转移概率:verbiter方法的原理简单来说就是给出当前状态,求解最有可能转移至该状态的上一个状态。基于这种思路,和原理,下图的式子便很好理解了,即若当前状态为B,求解最有可能转移至状态B的上一状态,式中Teb则是E转移至B的概率,Tsb则是S转移至B的概率
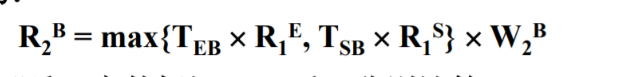
故求解出以上几个概率,则实现verbiter方法无非是套公式了。
现给出实现思路:
1.根据语料库求解状态转移概率 (根据tag求解 B-LOG --> I--LOG)
2.根据语料库求解词与词的转移概率
3.根据语料库求解发射概率 (B-LOG中南京的概率)
4.根据语料库求解初始词概率
5.根据vebiter方法求解
句子:陈鼎立毕业于西南科技大学
输入分词结果:陈 鼎立 毕业 于 西南 科技 大学
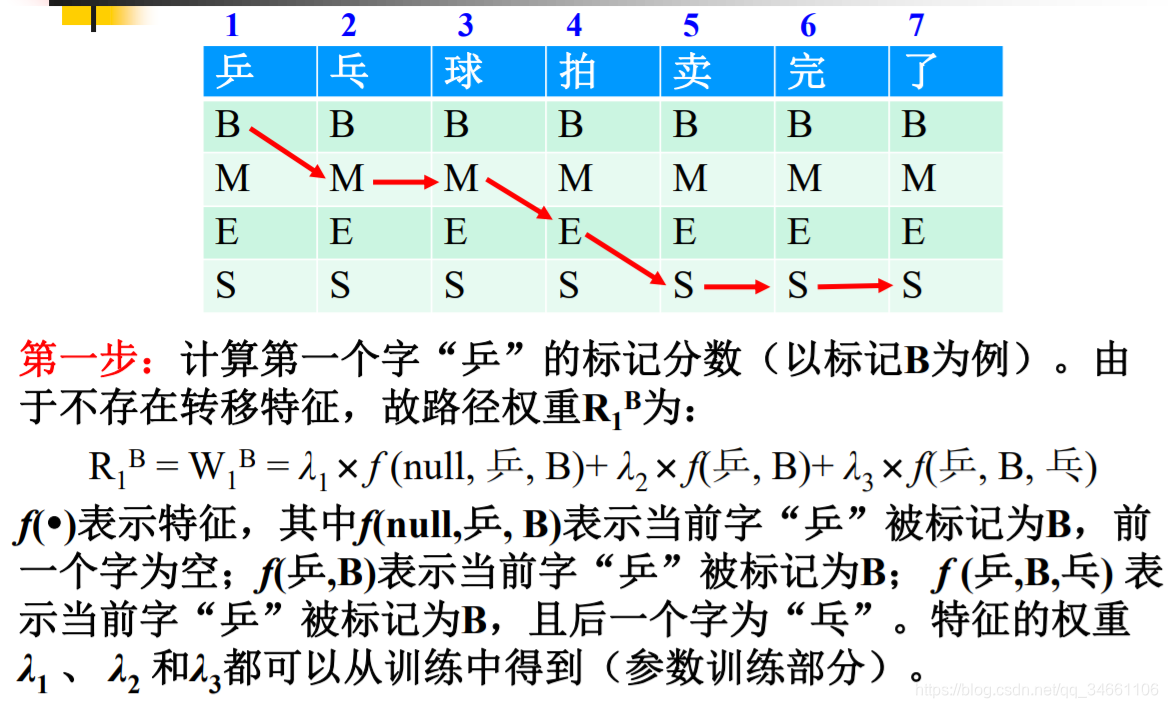
1)初始化, R1x = W1x = l1*f(null,陈,B) + l2*f(陈,B) + l3*f(陈,B,鼎立)
约定:第一项的初始词为陈的概率,第二项为状态B中陈的发射概率,第三项为陈->鼎立的转移概率
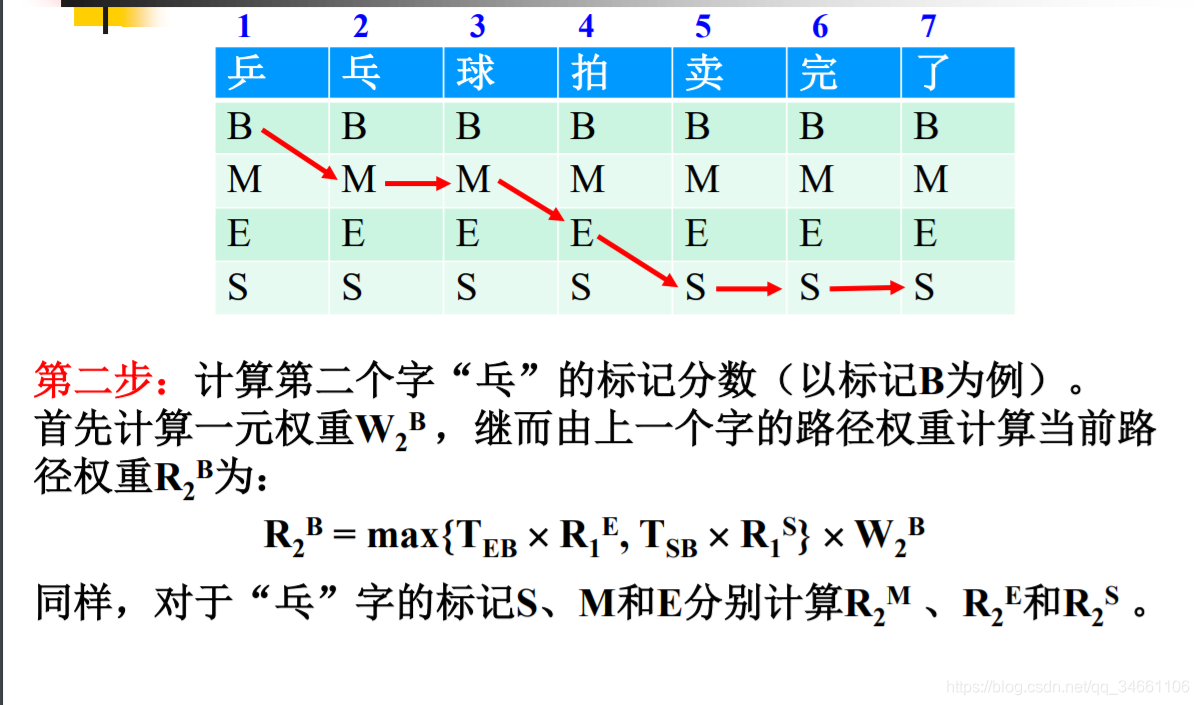
注意:句子的第二个词开始则是第i-1个词转移至第i个词的概率 + 第i个词属于某个状态的概率 + 第i个词转移至第i+1个词的概率
2)循环,Rb = max{Teb*Re,Tsb*Rs}*Wb
约定:Teb为E--B的权重
3)回溯
根据最后一个词的状态回溯路径
代码:首先说明,本人在实现的过程中忘记有几个概率要求,故训练模型(参数估计)部分代码写的非常混乱,不过理解上面的内容和思路,本人的代码是否参考都无太大意义。
1.训练状态转移概率和发射概率
class CRF_train:def __init__(self):self.state_list = ['O','B-LOCATION','I-LOCATION','O-LOCATION','B-ORGANIZATION','I-ORGANIZATION','O-ORGANIZATION','B-PERSON','B-TIME']self.trans_dict = {}self.emit_dict = {}self.count_dict = {}self.word_trans = {}self.word_count = {}self.words_list = []def init(self):for state in self.state_list:self.emit_dict[state] = {}self.count_dict[state] = 0for state in self.state_list:self.trans_dict[state] = {}for state1 in self.state_list:self.trans_dict[state][state1] = 0def train(self):self.init()for line in open('../data/train.txt',encoding='utf-8'):if line:line = line.strip()word_list = line.split(' ')char_list = []for word in word_list:word1,tag = word.split('/')char_list.append((word1,tag))for i in range(len(char_list) - 1):self.trans_dict[char_list[i][1]][char_list[i+1][1]] += 1self.count_dict[char_list[i][1]] += 1for i in range(len(char_list)):state = char_list[i][1]word = char_list[i][0]if word not in self.emit_dict[state]:self.emit_dict[state][word] = 1else:self.emit_dict[state][word] += 1for i in range(len(char_list)):word = char_list[i][0]if word not in self.word_count:self.word_count[word] = 1else:self.word_count[word] += 1else:continuefor state in self.state_list:for state1 in self.state_list:self.trans_dict[state][state1] = self.trans_dict[state][state1] / self.count_dict[state]for state in self.state_list:for word in self.emit_dict[state]:self.emit_dict[state][word] = self.emit_dict[state][word] / self.count_dict[state]self.save_model(self.emit_dict, './model/emit_dict.txt')self.save_model(self.trans_dict, './model/trans_dict.txt')def save_model(self,word_dict,model_path):f = open(model_path,'w')f.write(str(word_dict))f.close()if __name__ == '__main__':ct = CRF_train()ct.train()
2.训练词与词之间的转移概率,注意的是求解词与词之间的转移概率前,首先需要将训练样本中的不重复的词提取出来,然后凭此来求解词与词之间的转移概率,还有的是,在我的实际实现中,训练样本中不重复的词有80000多个,若采用求解状态转移概率的思路,初始化和计算一个80000乘80000的矩阵是非常不现实的,故正确的思路是应像是求解发射概率的思路,即先初始化各个词为 {词1:{},词2:{}},然后根据训练样本统计词与词转移的词频,再除以每个词出现的总次数(需要统计每个词出现的频率,即词1、词2出现的频率)即求解出词与词之间的转移概率。结果应如{词1:{词2:0.03,词3:0.05},词2:{词1:0.02}}的形式。
def save_model(model_path, word_dict):f = open(model_path, 'w')f.write(str(word_dict))f.close()def load_model(model_path):f = open(model_path,'r')a = f.read()word_dict = eval(a)f.close()return word_dictdef init(word_dict):word_trans = {}for word in word_dict:word_trans[word] = {}return word_transif __name__ == '__main__':word_dict = load_model('./model/set_list.txt')word_trans = init(word_dict)count_dict = {}for line in open('../data/train.txt', encoding='utf-8'):words_list = []if line:line = line.strip()wl = line.split(' ')for w in wl:word,tag = w.split('/')words_list.append(word)if word not in count_dict:count_dict[word] = 1else:count_dict[word] += 1for i in range(len(words_list) - 1):if words_list[i+1] not in word_trans[words_list[i]]:word_trans[words_list[i]][words_list[i + 1]] = 1else:word_trans[words_list[i]][words_list[i + 1]] += 1save_model('./model/word_trans.txt', word_trans)save_model('./model/count_dict.txt', word_trans)for key in word_trans.keys():for key1 in word_trans[key].keys():word_trans[key][key1] = word_trans[key][key1]/count_dict[key]save_model('./model/prob_word_trans.txt',word_trans)3.初始词概率,你懂的,就那么求
def save_model(word_dict,model_path):f = open(model_path,'w')f.write(str(word_dict))f.close()if __name__ == '__main__':start_dict = {}line_index = 0for line in open('../data/train.txt', encoding='utf-8'):if line:line = line.strip()word_list = line.split(' ')init_word,init_tag = word_list[0].split('/')if init_word not in start_dict:start_dict[init_word] = 1else:start_dict[init_word] += 1line_index += 1for key in start_dict:start_dict[key] = start_dict[key] / line_indexsave_model(start_dict,'./model/start_word.txt')4.实体识别代码
verbiter的原理我上面说过,就是在当前状态下,求解上一最有可能转移至该状态的状态。
class CRF_ner:def __init__(self):trans_path = './model/trans_dict.txt'emit_path = './model/emit_dict.txt'word_trans_path = './model/prob_word_trans.txt'start_word_path = './model/start_word.txt'self.prob_trans = self.load_model(trans_path)self.prob_emit = self.load_model(emit_path)self.prob_word_trans = self.load_model(word_trans_path)self.prob_start_word = self.load_model(start_word_path)def load_model(self,model_path):f = open(model_path,'r')a = f.read()word_dict = eval(a)f.close()return word_dictdef verbiter(self,sent,state_list):V = [{}]path = {}#state_list = ['O', 'B-LOCATION', 'I-LOCATION', 'O-LOCATION', 'B-ORGANIZATION', 'I-ORGANIZATION',#'O-ORGANIZATION', 'B-PERSON', 'B-TIME']#初始化for state in state_list:if self.prob_word_trans.get(sent[0],0) == 0:V[0][state] = self.prob_start_word.get(sent[0],0) + self.prob_emit[state].get(sent[0],0)else:V[0][state] = self.prob_start_word.get(sent[0], 0) + self.prob_emit[state].get(sent[0], 0) + self.prob_word_trans[sent[0]].get(sent[1], 0)path[state] = [state]for i in range(1,len(sent)):V.append({})newpath = {}state_path = []for state in state_list:if i == len(sent) - 1:if self.prob_word_trans.get(sent[i-1], 0) == 0:W = self.prob_emit[state].get(sent[i], 0)else:W = self.prob_word_trans[sent[i - 1]].get(sent[i], 0) + self.prob_emit[state].get(sent[i], 0)else:W = (self.prob_word_trans[sent[i - 1]].get(sent[i], 0) if self.prob_word_trans.get(sent[i-1],0) != 0 else 0) + self.prob_emit[state].get(sent[i],0) + (self.prob_word_trans[sent[i]].get(sent[i + 1], 0) if self.prob_word_trans.get(sent[i],0) != 0 else 0)for state1 in state_list:R = V[i-1][state1] * self.prob_trans[state1].get(state,0)state_path.append((R,state1))if state_path == []:(prob,y) = (0.0,'O')else:(prob,y) = max(state_path)V[i][state] = prob * Wnewpath[state] = path[y] + [state]path = newpath(prob, state) = max([(V[len(sent) - 1][y], y) for y in state_list])return (prob,path[state])def cut(self,sent):print('========开始计算========')state_list = ['O', 'B-LOCATION', 'I-LOCATION', 'O-LOCATION', 'B-ORGANIZATION', 'I-ORGANIZATION','O-ORGANIZATION', 'B-PERSON', 'B-TIME']prob,pos_list = self.verbiter(sent,state_list)result = []sub_result = []for i in range(len(pos_list)-1):if pos_list[i] in ['B-ORGANIZATION','I-ORGANIZATION','O-ORGANIZATION'] and pos_list[i+1] in ['B-ORGANIZATION','I-ORGANIZATION','O-ORGANIZATION']:sub_result.append(sent[i])elif pos_list[i] in ['B-ORGANIZATION','I-ORGANIZATION','O-ORGANIZATION'] and pos_list[i+1] not in ['B-ORGANIZATION','I-ORGANIZATION','O-ORGANIZATION']:result.append(sub_result)sub_result = []last = len(pos_list) - 1print(pos_list)if pos_list[last-1] in ['B-ORGANIZATION','I-ORGANIZATION','O-ORGANIZATION'] and pos_list[last] in ['B-ORGANIZATION','I-ORGANIZATION','O-ORGANIZATION']:sub_result.append(sent[last])result.append(sub_result)elif pos_list[last-1] not in ['B-ORGANIZATION','I-ORGANIZATION','O-ORGANIZATION'] and pos_list[last] in ['B-ORGANIZATION','I-ORGANIZATION','O-ORGANIZATION']:sub_result.append(sent[last])result.append(sub_result)entities = []for entity_list in result:entity = ''for tmp in entity_list:entity += tmpentities.append(entity)return entitiesif __name__ == '__main__':sent = ['陈','鼎立','毕业','于','西南','科技','大学']# sent = ['中国','政府','要求','美方','遵守','条约']# sent = ['清华大学', '在', '北京市', '海', '淀', '区', '清', '华', '园', '1', '号']# sent = ['清华大学','副','校长','尤政','宣布','成立','人工','智能','研究院','张钹','院士','担任','新','研究院','院长']ce = CRF_ner()result = ce.cut(sent)print(result)
以上就是全部内容,各位看官需要注意的是在计算词与词的转移概率之前,需要在训练样本提取不重复的各词作为训练词与词转移概率的前提,在代码中没有给出(因为写完就给删了。。。。。懒的写),没几行,看官可以自行实现。
本人水平较差。若没有使有缘看到此文的看官浪费时间 ,便好。
本文中没有给出CRF的公式详细推导和原理介绍,我觉得给出一个例子用以实现代码这样效果是最好的,若各位看官需要详细学习和了解CRF,嗯,自行百度
这篇关于基于CRF的命名实体识别思路与实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







