本文主要是介绍【Tauri】(2):使用Tauri应用开发,使用开源的Chatgpt-web应用做前端,使用rust 的candle做后端,本地运行小模型桌面应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
视频演示地址
https://www.bilibili.com/video/BV17j421X7Zc/
【Tauri】(2):使用Tauri应用开发,使用开源的Chatgpt-web应用做前端,使用rust 的candle做后端,本地运行小模型桌面应用
1,做一个免费的桌面端的gpt软件方案
使用CPU 运行小模型运行 qwen 1.8B
https://www.modelscope.cn/models/qwen/Qwen-1_8B-Chat-Int4/summary
介绍(Introduction)
通义千问-1.8B(Qwen-1.8B) 是阿里云研发的通义千问大模型系列的18亿参数规模的模型。Qwen-1.8B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-1.8B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-1.8B-Chat。本仓库为Qwen-1.8B-Chat的Int4量化模型的仓库。
通义千问-1.8B(Qwen-1.8B)主要有以下特点:
低成本部署:提供int8和int4量化版本,推理最低仅需不到2GB显存,生成2048 tokens仅需3GB显存占用。微调最低仅需6GB。
大规模高质量训练语料:使用超过2.2万亿tokens的数据进行预训练,包含高质量中、英、多语言、代码、数学等数据,涵盖通用及专业领域的训练语料。通过大量对比实验对预训练语料分布进行了优化。
优秀的性能:Qwen-1.8B支持8192上下文长度,在多个中英文下游评测任务上(涵盖常识推理、代码、数学、翻译等),效果显著超越现有的相近规模开源模型,具体评测结果请详见下文。
覆盖更全面的词表:相比目前以中英词表为主的开源模型,Qwen-1.8B使用了约15万大小的词表。该词表对多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强和扩展。
系统指令跟随:Qwen-1.8B-Chat可以通过调整系统指令,实现角色扮演,语言风格迁移,任务设定,和行为设定等能力。
2,前端界面界面参考使用
开源的Chatgpt-web应用
https://blog.csdn.net/freewebsys/article/details/129679034
3,后端使用rust 的candle 项目
本地启动小模型的chatgpt服务
https://github.com/huggingface/candle
已经可以支持 chatglm 和 qwen 大模型了
https://github.com/huggingface/candle/blob/main/candle-examples/examples/chatglm/main.rs
然后就可以进行前后的连调了。
4,整个设计方案,和用到的技术
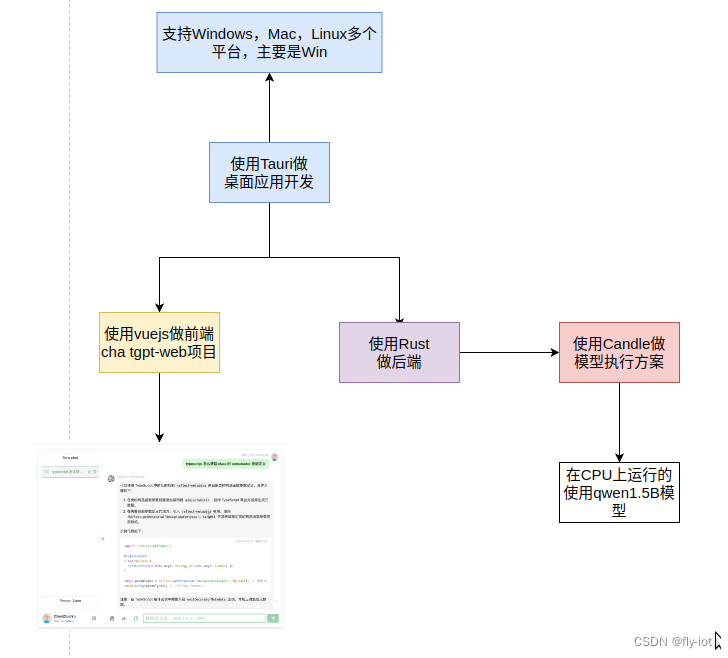
这篇关于【Tauri】(2):使用Tauri应用开发,使用开源的Chatgpt-web应用做前端,使用rust 的candle做后端,本地运行小模型桌面应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




