本文主要是介绍Dca策略 类马丁,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.策略原理
Dca:Dollar cost averaging 美元平均成本
使用均线确定趋势
均线金叉后 买入初始 N% 量
然后确定十条网格线 (网格之间间距越来越大)
每个网格线买入点的量倍投
止盈:持仓成本固定 1.5%
止损:第十条网格价格线的 N%
于普通马丁和网格不同,带有止损不会被套和爆仓
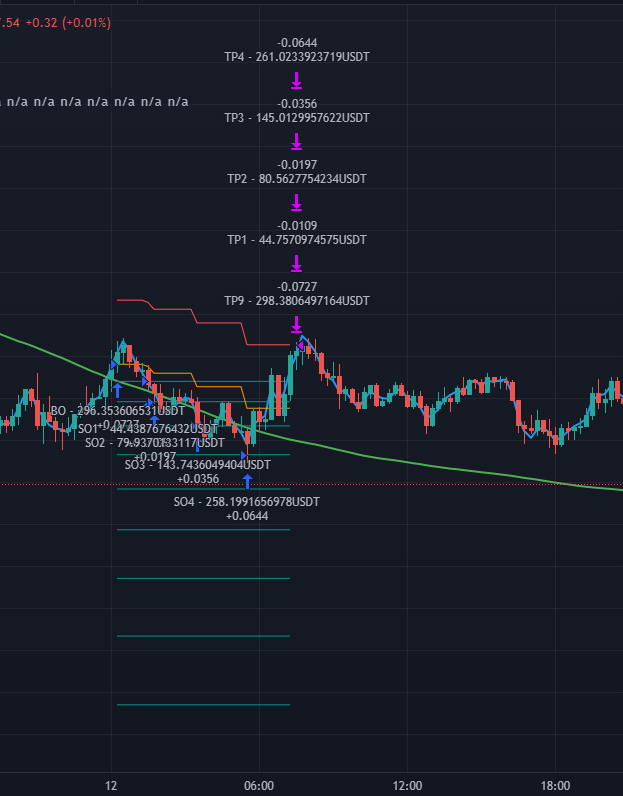
网格线和加仓量计算代码:
seting = {'base_size': 5, #初始下单量 %'safety_size': 2, #马丁初始下单 %'max_trades': 9, #最大交易数'wangge_price': 0.4 * 0.01, #网格间距'wangge_price_scale': 1.19, #网格乘数'wangge_volume_scale': 1.8, #马丁乘数
}class DcaClass():def __init__(self, seting):self.close = 0 #初始开仓价格self.seting = setingself.i = 1#参数i为第几条网格线def step(self, i):pd = self.seting['wan这篇关于Dca策略 类马丁的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




