本文主要是介绍直击2022数博会丨数字经济场景下,数据要素市场化改革之路如何走?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
科技云报道原创。
从2014年大数据第一次被写入政府报告,到2022年政府报告中明确指出“培育数据要素市场,释放数据要素潜力”,数据作为新型生产要素的市场化改革之路,已经走过了八年。
在顶层战略清晰、政策扶持、市场规模可观等多重利好叠加下,数据要素市场的发展前景可谓一片大好。据国家工业信息安全发展研究中心最新测算,预计到2025年,中国数据要素市场规模将突破1749亿元,整体进入高速发展阶段。
但值得注意的是,我国数据要素市场流通依然存在制度体系弱、市场培育难、过程监管难、安全保障难等现实困境,在数据要素的开发利用上并不充分。相关数据显示,我国每年全社会数据量增长约40%,但真正被利用的数据增长率只有5.4%。
随着数字经济下大量数字化场景的爆发,我国数据要素的市场化路径应如何有效打通,才能匹配当前数字场景的需求?
5月26日,在2022中国国际大数据产业博览会(以下简称“数博会”)上,“场景大数据”论坛对这一问题展开了深入探讨。
本次论坛围绕“场景定义数据交易”主题,讨论了数据交易全流程的法律法规、技术应用、市场供需、监管机制等多个方面,切实推动场景大数据数据要素的价值发挥。

促进公共数据的开放和利用,向数字经济场景赋能
当前,我国数据供给的动力机制尚不完善,数据流通活力不足。以公共数据为例,政务服务、教育、医疗、交通、能源等领域还存在大量沉睡数据。
复旦大学国际关系与公共事务学院教授、数字与移动治理实验室主任郑磊表示,近年来我国在政府数据开放方面取得了很大的进步,但依然存在“不充分、不平衡、不协同、不可持续”的挑战,对于数据开放进一步发展形成制约。
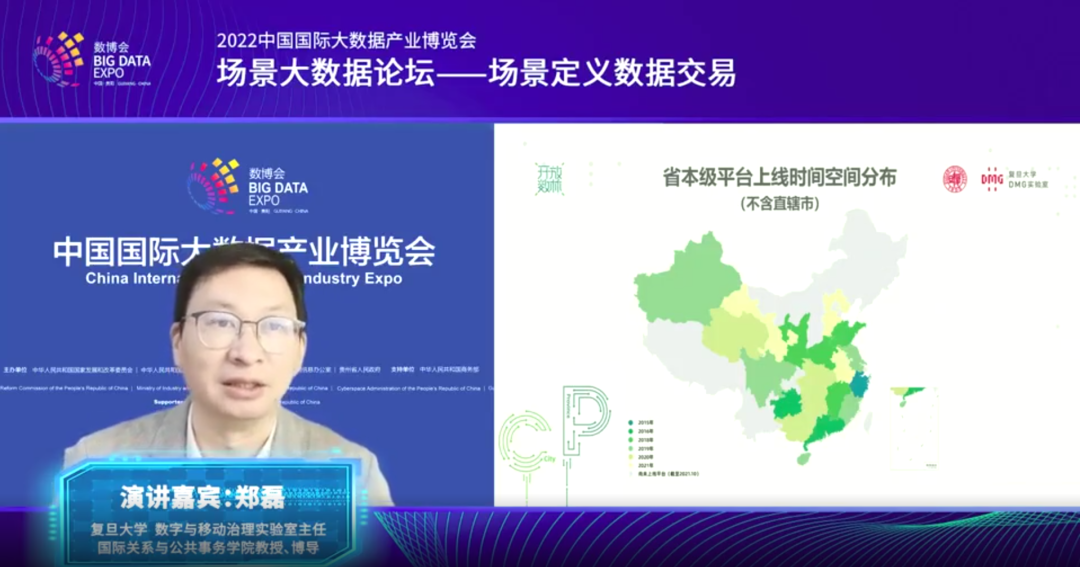
据复旦大学数字与移动治理实验室连续5年发布的《中国地方政府数据开放报告》显示,2012年-2021年,我国政府数据开放平台的数量从3个平台上升到193个平台,但目前全国地级、副省级和省级开放平台仍然只占全国覆盖率一半,且数据容量低、颗粒度较粗、开放质量不高。同时,开放数据的容量、开放平台的数量等在全国各个地区之间分布不平衡。
郑磊指出,目前我国在政府开放数据平台的运营方面也存在挑战:一方面,各省市的数据开放平台没有打通,是碎片化的孤立平台;另一方面,平台运营服务不稳定,数据开放服务不可持续。
事实上,这种现状也反映了当下数字政府在推进过程中存在的问题。数据的开放和利用,并不仅仅是为了开放和利用本身,而是两者形成正向循环,促进数据被利用,然后利用成效使得数据开放者得到正向反馈,从而愿意开放更多的数据。
郑磊表示,促进公共数据的开放和利用,能够向数字经济赋能,从而推动转型、培育新兴产业和新业态。例如,在推动购物消费、居家生活、旅游休闲、交通出行、社区治理等各类数字经济场景中,公共数据是必需的一类数据。当这些数据开放给社会,在利用数据的过程中,也会反过来向数字政府提出新需求。
最终,“数字经济场景、数字社会场景、数字政府场景”三个大场景之间,也能够形成多向循环关系,互相之间相辅相成、互相支撑,形成一个面向场景的公共数据开放利用体系。
推动场景与数据的三次融合,实现场景大数据价值最大化
众所周知,数据的价值在于流通交易,但完成数据从资源-资产-资本的三次“蝶变”何谈容易?
究其原因,数据具有非排他、可共享复用等区别于传统要素的特殊属性。由于对数据的定价高度依赖于用途和场景,数据对于不同用户的使用价值差别巨大,难以形成统一的定价标准,因此也导致了难以形成大规模、常态化交易行为的现状。
对此,全国政协委员、北京国际城市发展研究院院长、贵阳创新驱动发展战略研究院院长、大数据战略重点实验室主任连玉明指出,“三次融合”是场景大数据价值最大化的基本进阶循环之路:第一次融合“场景×数据”实现数据价值再造;第二次融合“场景×数权”破解数据价值最大化;第三次融合“场景×交易”催生数据交易市场。

在场景与数据的融合上,两者融合的程度,决定着数据价值释放有多大、有多深、有多广。场景大数据的持续运维、迭代升级遵循“场景大数据—行业大数据—城市大数据”融合创新的基本规律。
在场景与数权的融合上,往往会遇到数据交易的三大难题:确权难、定价难、监管难,其中最难的是数据的确权,会随着场景的变化而变化。从国内外实践来看,各界对数据产权的界定方式远远没有达成共识,更没有形成权威的方式方法。
对此,连玉明表示,采取场景化的方式来界定和划分数据产权,最重要的就是将数据产权的核心抽象为数据利益,从区分利益的角度,对数据产权进行界定和划分,并以此为基础找到数据确权的内在规律。
在场景与交易的融合上,数据运营是数据交易的起点,核心是数据授权;数据交易离不开权利,核心是数权流转;数据市场离不开规则,核心是数权制度。
实践出真知数据要素流通路径,交由市场检验
数据要素作为一种新型生产要素,在市场化的过程中面临着确权、计量、定价、监管等多重挑战,因此不能简单以传统生产要素市场化的方式来推进数据要素的市场化,而是要通过产品化和场景化、产业化才能发挥最大价值。
十四五规划提出,以实际应用需求为导向,探索建立多样化的数据开发利用机制。如何走通数据要素市场化的路径,还需要市场各方通过实践进行探索和验证。
中国联通作为数字技术融合创新的排头兵,2016年在通信类企业中率先成立了专业化大数据公司,积累了深厚的数据价值化和要素化的市场经验。联通数科作为中国联通的大数据对外商用服务的出口,早已开启数据要素市场化的改革试点工作,总结出一套赋能数据要素流通的“联通模式”。
联通数字科技有限公司总裁李广聚表示,基于联通数据资源开发利用的实践经验,以及服务各地数字政府的建设经验,联通数科初步形成了数智链技术融合创新的产品体系和商业运营体系,总结形成了“一前提、四步走”的数据要素市场化的路径,即在数据安全汇聚治理的基础前提下,按照数据共享、数据开放、开发利用、交易流通四个环节来进行推进。

目前,联通数科在支撑政企市场数据产品落地和数据要素市场化流通方面,已形成了自主可信、端网融合、跨云跨链、开放合作的特色优势,并实践了多个数据共享、数据开放利用模式的应用场景。
同时,联通数科也探索出“以授权运营方为中心”的服务流通机制,以加快数据要素的市场化。例如,在上海市大数据中心数据要素开发利用试点项目中,联通数科作为运营支撑方,协助上海大数据中心构建了政府数据授权运营的六方责任模式,并在大数据中心的统筹下,以普惠金融2.0为牵引,开展了实验性的运转,目前已经取得了良好的成效。
李广聚表示,无论是数据工场还是数据市场,数据要素安全有序的流通是底线。联通依托自身四亿的用户数据安全管理实践,结合服务浙江、安徽、海南等地的数字政府经验,为数据要素市场化构建了三横四纵的安全有序流通保障体系,做好数据的看门人。
结语
数字经济和实体经济的融合日益紧密,随着大量新场景的出现,对数据要素市场化的需求越来越急迫。如何做到最大限度激发数据要素潜力,发挥数据要素价值,既考验着我国数字政府的治理水平,也离不开社会各方的合力推进。
【关于科技云报道】
专注于原创的企业级内容行家——科技云报道。成立于2015年,是前沿企业级IT领域Top10媒体。获工信部权威认可,可信云、全球云计算大会官方指定传播媒体之一。深入原创报道云计算、大数据、人工智能、区块链等领域。
这篇关于直击2022数博会丨数字经济场景下,数据要素市场化改革之路如何走?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




