本文主要是介绍P1-YOLO学习1.1-YOLOV1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一.YOLOV1
1.Abstract
2.Core
3.NetWork
4.Training
5.Experiments
6.WebNet
7.Innovation point
一.YOLOV1
1.Abstract

分析:You Only Look Once 即你只看一遍即可。本文提出了一种不同与分类器检测的思想,即一种一个CNN解决一个回归问题。其优点为检测速度(FPS)和mAP很快,因此非常适合视频实时检测。

2.Core
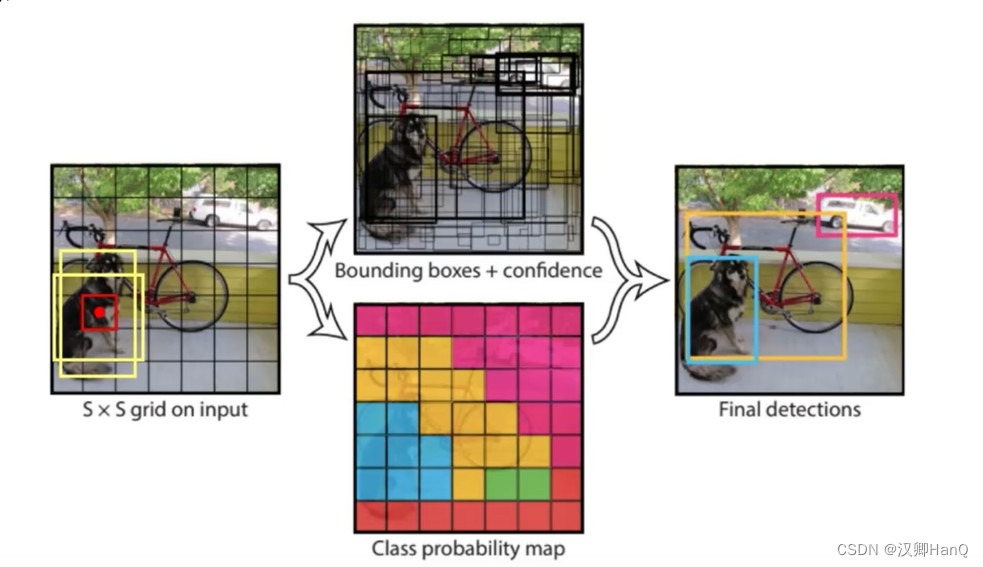
YOLOV1的核心思想是将图像分成S*S的小网格,如果物体的中心点落在了某一个网格内,那么就由这个网格来进行预测这个物体。
每个中心点产生两个候选框(YOLOV1中bicth=2)B1(x1,y1,w1,h1) B2(x2,y2,w2,h2),实现代码中对其进行归一化(分别除以图像的w和h),然后拿真实值算iou,谁的iou大进行微调,每个候选框有一个置信度confidence(当前这个点是物体还不是物体)或者大于某个阈值。每个格子预测一下格子内是什么物体。
Q1:多点产生重合的框怎么办?
NMS(非极大值抑制):按置信度进行排序,选最大的
Class probability map(类概率图):每个cell只负责预测一个类别
总结:YOLOV1核心思想是将目标检测问题转换为一个回归问题,通过一个单独的神经网络模型预测目标的位置和类别。
1>单次预测:YOLOV1采用一次向前传播,直接再整个图像上生成目标的预测,避免多次预测和区域划分的过程
2>网格划分:YOLOV1将图像分割成一个固定大小的网格,每个网格负责预测目标信息
3>边界框预测:每个边界框由一组坐标值表示,包括x,y,h,w,使用回归模型预测边界框的坐标,网络输出是相对网格单元的偏移量和边界框的宽高比
4>类别预测:对于每个网格,YOLOV1预测多个类别的概率。
5>损失函数:使用自定义的损失函数平衡边界框位置预测和类别预测的损失
3.NetWork

神经网络受GoogleNet启发采用24个卷积层和两个全连接层,但不同的是初始模块采用了1*1和3*3的卷积核
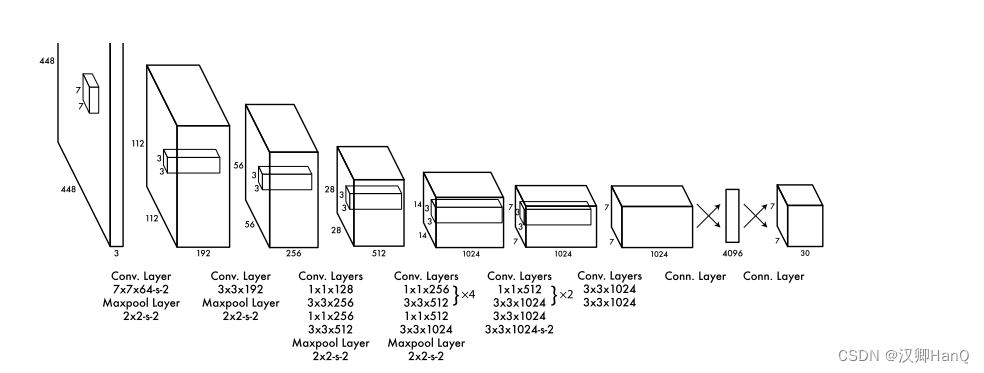
Q2:为什么是448*448*3?
受到了全链接层的限制,必须固定图片大小。
第一个全连接层转换为4096个特征
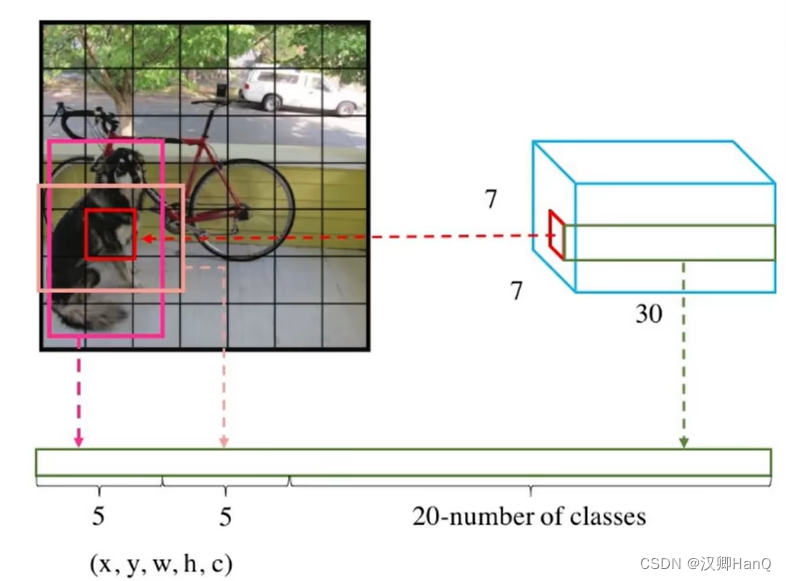
第二个全连接层为1470,其含义为7*7的格子,每个格子预测出30个值

Q3:为什么用来两个全连接层?
两个全连接层能够解决非线性问题
其中30的含义,前5为b1,再5为b2,剩余20为分类任务
4.Training


Q4:为什么位置误差中w,h加上了根号?
为了统一大小物体的误差
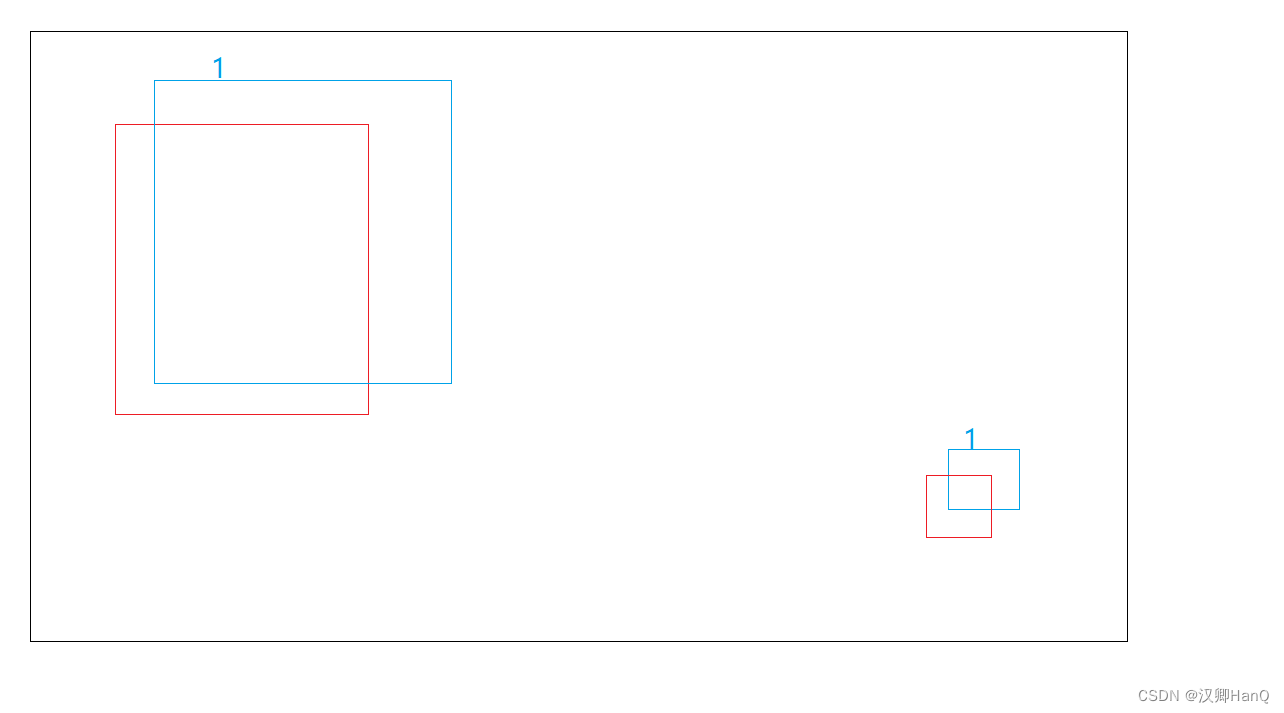

数值较小更敏感,但解决的不大,后面版本还有改进
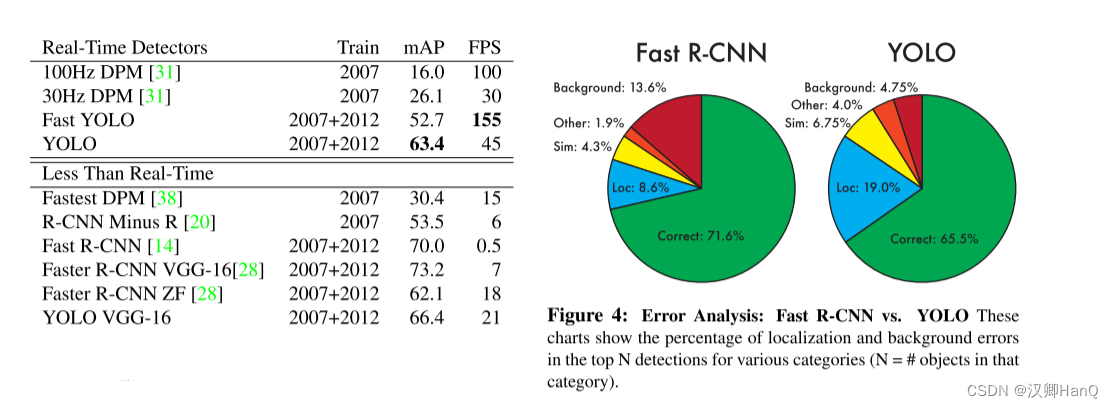
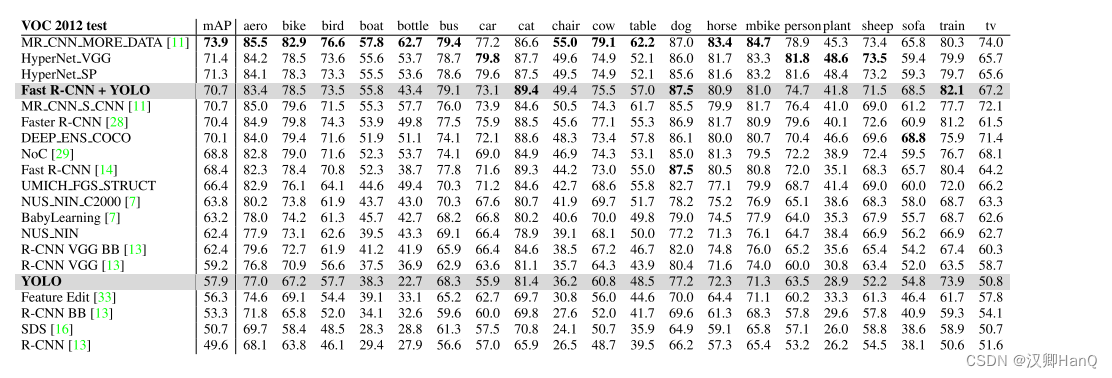
5.Experiments
6.WebNet
YOLO: Real-Time Object Detection
7.Innovation point
1>首次提出one-stage的概念实现end-to-end的图像检测,因其FPS远远高于同时期其他模型,因此YOLO更适用于实时检测
2>为了提高检测速度,每个检测点只选出两个候选框进行识别预测
3>提出了比较合理的损失函数
这篇关于P1-YOLO学习1.1-YOLOV1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








