本文主要是介绍Python爬虫教材,批量下载素材公社的任意类型图片,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
**整体思路大致就是 输入你想要爬取的图片分类 加上你想下载的几页 即可实现批量下载
下面展示分步骤代码+具体的思路:
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:961562169
一、生成一个保存图片的文件夹
这里是把文件夹创建在.py文件的同级目录了 可以根据自己设定
path = os.getcwd() #获取当前文件所在路径
path_name = path + '/' + '素材公社'
if not os.path.exists(path_name):os.mkdir(path_name)
二、获取图片分类选项和url 生成字典
这里要下载的分类选项不包括风景图片 人物图片等大类
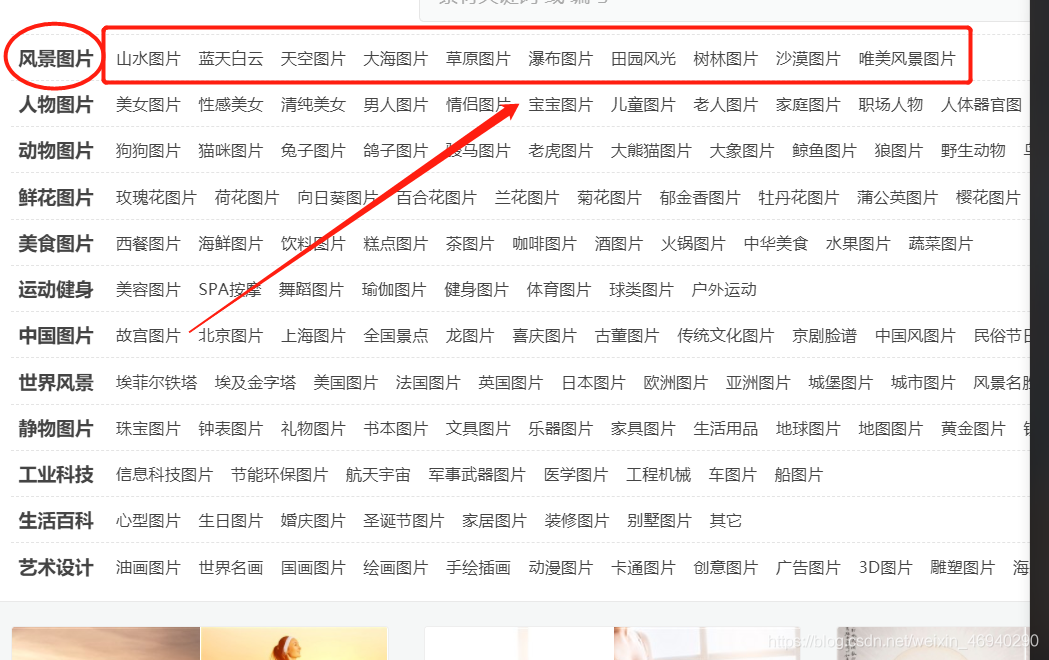
观察链接末尾在推导式中用if条件语句可将大类选项筛选掉

def get_meun():url = 'https://www.tooopen.com/img'res = requests.get(url, headers=headers)html = etree.HTML(res.text)urls = html.xpath('/html/body/div[3]/div/div/ul/li/a/@href')names = html.xpath('/html/body/div[3]/div//div/ul/li/a/text()')dic = {k: v for k, v in zip(names, urls) if '_' in v}return dic三 、 下载图片
检查源码观察我们发现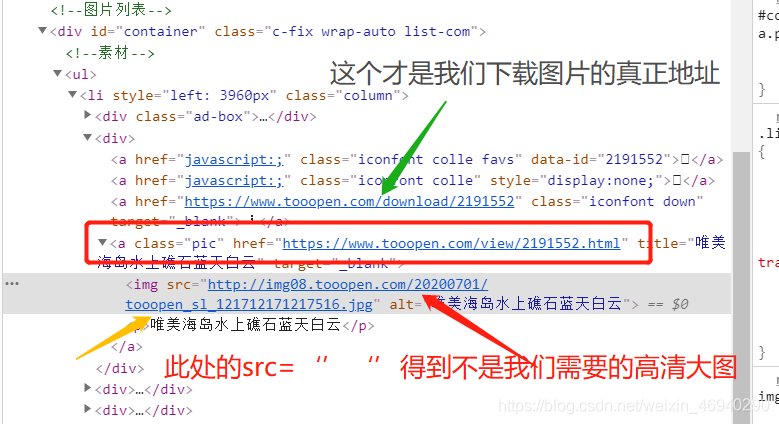
这篇关于Python爬虫教材,批量下载素材公社的任意类型图片的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




