本文主要是介绍书生·浦语大模型第四课作业,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基础作业:
构建数据集,使用 XTuner 微调 InternLM-Chat-7B 模型, 让模型学习到它是你的智能小助手,效果如下图所示,本作业训练出来的模型的输出需要将不要葱姜蒜大佬替换成自己名字或昵称!
1.安装
# 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 2.0.1 的环境:
/root/share/install_conda_env_internlm_base.sh xtuner0.1.9
# 如果你是在其他平台:
conda create --name xtuner0.1.9 python=3.10 -y# 激活环境
conda activate xtuner0.1.9
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
mkdir xtuner019 && cd xtuner019# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner# 进入源码目录
cd xtuner# 从源码安装 XTuner
pip install -e '.[all]'安装完后,就开始搞搞准备工作了。(准备在 oasst1 数据集上微调 internlm-7b-chat)
# 创建一个微调 oasst1 数据集的工作路径,进入
mkdir ~/ft-oasst1 && cd ~/ft-oasst12.3 微调
2.3.1 准备配置文件
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看
# 列出所有内置配置
xtuner list-cfg在本案例中即:(注意最后有个英文句号,代表复制到当前路径)
cd ~/ft-oasst1
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .配置文件名的解释:
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
| 模型名 | internlm_chat_7b |
|---|---|
| 使用算法 | qlora |
| 数据集 | oasst1 |
| 把数据集跑几次 | 跑3次:e3 (epoch 3 ) |
2.3.2 模型下载
由于下载模型很慢,用教学平台的同学可以直接复制模型。
ln -s /share/temp/model_repos/internlm-chat-7b ~/ft-oasst1/2.3.3 数据集下载
https://huggingface.co/datasets/timdettmers/openassistant-guanaco/tree/main
由于 huggingface 网络问题,咱们已经给大家提前下载好了,复制到正确位置即可:
cd ~/ft-oasst1
# ...-guanaco 后面有个空格和英文句号啊
cp -r /root/share/temp/datasets/openassistant-guanaco .此时,当前路径的文件应该长这样:
|-- internlm-chat-7b
| |-- README.md
| |-- config.json
| |-- configuration.json
| |-- configuration_internlm.py
| |-- generation_config.json
| |-- modeling_internlm.py
| |-- pytorch_model-00001-of-00008.bin
| |-- pytorch_model-00002-of-00008.bin
| |-- pytorch_model-00003-of-00008.bin
| |-- pytorch_model-00004-of-00008.bin
| |-- pytorch_model-00005-of-00008.bin
| |-- pytorch_model-00006-of-00008.bin
| |-- pytorch_model-00007-of-00008.bin
| |-- pytorch_model-00008-of-00008.bin
| |-- pytorch_model.bin.index.json
| |-- special_tokens_map.json
| |-- tokenization_internlm.py
| |-- tokenizer.model
| `-- tokenizer_config.json
|-- internlm_chat_7b_qlora_oasst1_e3_copy.py
`-- openassistant-guanaco|-- openassistant_best_replies_eval.jsonl`-- openassistant_best_replies_train.jsonl2.3.4 修改配置文件
修改其中的模型和数据集为 本地路径
cd ~/ft-oasst1
vim internlm_chat_7b_qlora_oasst1_e3_copy.py在vim界面完成修改后,请输入:wq退出。假如认为改错了可以用:q!退出且不保存。当然我们也可以考虑打开python文件直接修改,但注意修改完后需要按下Ctrl+S进行保存。
减号代表要删除的行,加号代表要增加的行。
# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'# 修改训练数据集为本地路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = './openassistant-guanaco'常用超参
| 参数名 | 解释 |
|---|---|
| data_path | 数据路径或 HuggingFace 仓库名 |
| max_length | 单条数据最大 Token 数,超过则截断 |
| pack_to_max_length | 是否将多条短数据拼接到 max_length,提高 GPU 利用率 |
| accumulative_counts | 梯度累积,每多少次 backward 更新一次参数 |
| evaluation_inputs | 训练过程中,会根据给定的问题进行推理,便于观测训练状态 |
| evaluation_freq | Evaluation 的评测间隔 iter 数 |
| ...... | ...... |
如果想把显卡的现存吃满,充分利用显卡资源,可以将
max_length和batch_size这两个参数调大。
2.3.5 开始微调
训练:
xtuner train ${CONFIG_NAME_OR_PATH}
也可以增加 deepspeed 进行训练加速:
xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2
例如,我们可以利用 QLoRA 算法在 oasst1 数据集上微调 InternLM-7B:
# 单卡
## 用刚才改好的config文件训练
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py# 多卡
NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py# 若要开启 deepspeed 加速,增加 --deepspeed deepspeed_zero2 即可
微调得到的 PTH 模型文件和其他杂七杂八的文件都默认在当前的 ./work_dirs 中。
跑完训练后,当前路径应该长这样:
|-- internlm-chat-7b
|-- internlm_chat_7b_qlora_oasst1_e3_copy.py
|-- openassistant-guanaco
| |-- openassistant_best_replies_eval.jsonl
| `-- openassistant_best_replies_train.jsonl
`-- work_dirs`-- internlm_chat_7b_qlora_oasst1_e3_copy|-- 20231101_152923| |-- 20231101_152923.log| `-- vis_data| |-- 20231101_152923.json| |-- config.py| `-- scalars.json|-- epoch_1.pth|-- epoch_2.pth|-- epoch_3.pth|-- internlm_chat_7b_qlora_oasst1_e3_copy.py`-- last_checkpoint
2.3.6 将得到的 PTH 模型转换为 HuggingFace 模型,即:生成 Adapter 文件夹
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf

2.4 部署与测试
2.4.1 将 HuggingFace adapter 合并到大语言模型:
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
# xtuner convert merge \
# ${NAME_OR_PATH_TO_LLM} \
# ${NAME_OR_PATH_TO_ADAPTER} \
# ${SAVE_PATH} \
# --max-shard-size 2GB

2.4.2 与合并后的模型对话:
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat# 4 bit 量化加载
# xtuner chat ./merged --bits 4 --prompt-template internlm_chat
2.4.3 Demo
- 修改
cli_demo.py中的模型路径
- model_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b" + model_name_or_path = "merged"
vim /root/code/InternLM/cli_demo.py
微调过程截图: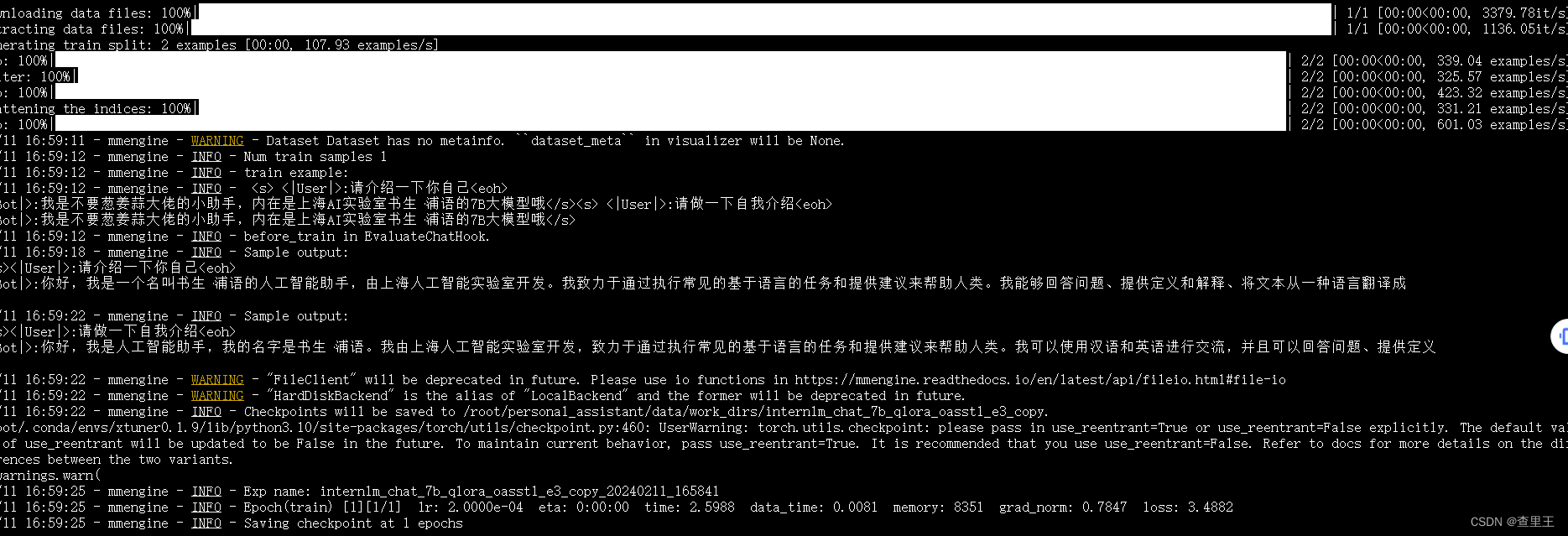
微调过程截图:
微调过程截图:
 微调过程截图:
微调过程截图: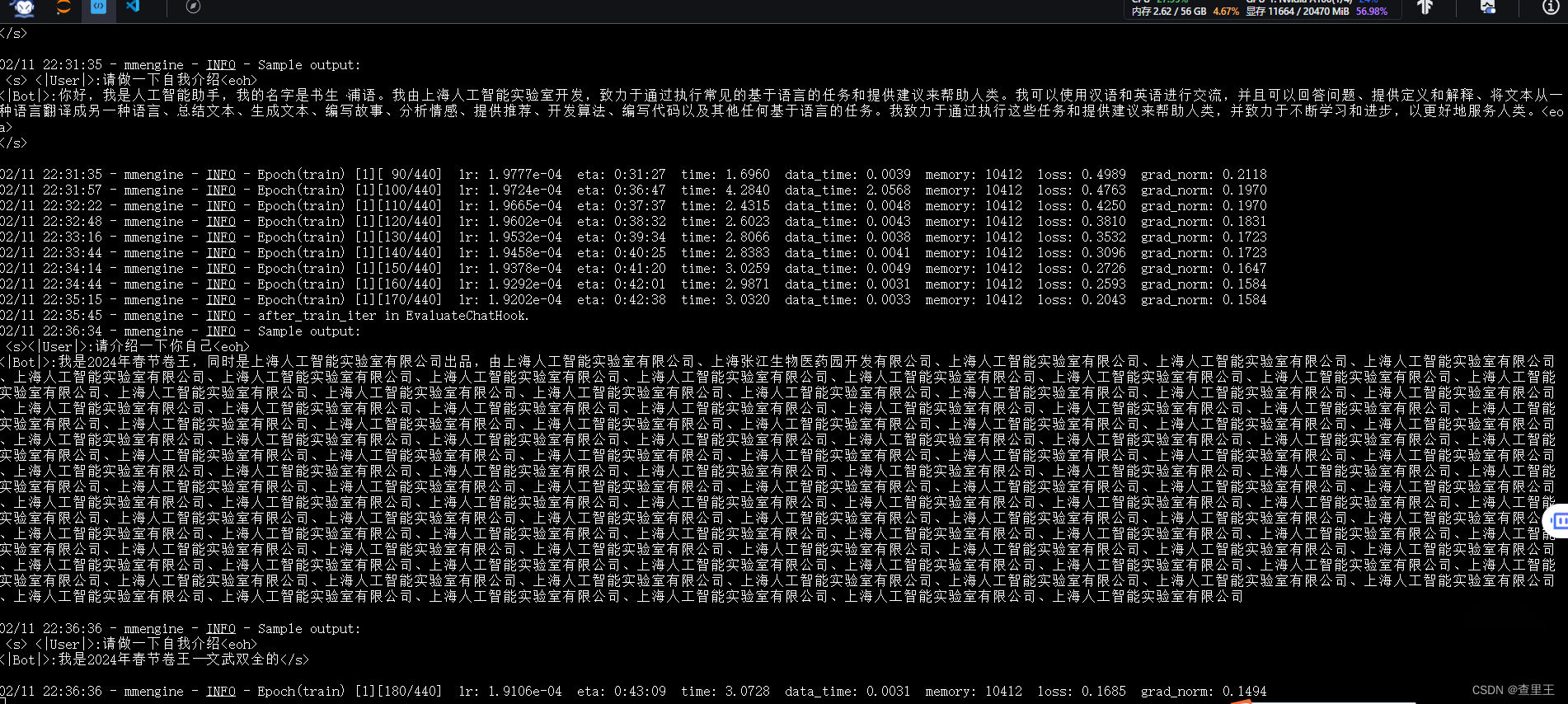
训练完成后,AI人设已经变成了我定义的内容:目前只跑通了CLI命令行的测试验证效果:

执行的脚本内容:cli_demo.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name_or_path = "/root/personal_assistant/config/work_dirs/hf_merge"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
model = model.eval()system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""messages = [(system_prompt, '')]print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")while True:input_text = input("User >>> ")input_text.replace(' ', '')if input_text == "exit":breakresponse, history = model.chat(tokenizer, input_text, history=messages)messages.append((input_text, response))print(f"robot >>> {response}")补充:
建议复制以下内容到 personal_assistant目录里,否则缺少必要的脚本
cp -r /root/code/InternLM/ /root/personal_assistant/code/InternLM/这篇关于书生·浦语大模型第四课作业的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








