本文主要是介绍OpenCV改变图像的对比度和亮度!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目标
在本教程中,您将学习如何:
- 访问像素值
- 用零初始化矩阵
- 了解 cv::saturate_cast 的作用以及它为什么有用
- 获取有关像素转换的一些很酷的信息
- 在实际示例中提高图像的亮度
理论
注意
下面的解释属于Richard Szeliski的《计算机视觉:算法和应用》一书
图像处理
- 一般图像处理算子是获取一个或多个输入图像并生成输出图像的函数。
- 图像转换可以看作是:
- 点运算符(像素变换)
- 邻里(基于区域)运营商
像素变换
- 在这种图像处理转换中,每个输出像素的值仅取决于相应的输入像素值(以及可能收集的一些全局收集的信息或参数)。
- 此类运算符的示例包括亮度和对比度调整以及颜色校正和转换。
亮度和对比度调整
-
两个常用的点过程是乘法和加法,具有常数:
\[g(x) = \alpha f(x) + \beta\]
- 参数 \(\alpha > 0\) 和 \(\beta\) 通常称为增益和参数;有时据说这些参数分别控制α>0和亮度。
-
您可以将 \(f(x)\) 视为源图像像素,将 \(g(x)\) 视为输出图像像素。然后,更方便的是,我们可以将表达式写成:
\[g(i,j) = \alpha \cdot f(i,j) + \beta\]
其中 \(i\) 和 \(j\) 表示像素位于第 i 行和第 j 列中。
法典
C++爪哇岛蟒
- 可下载代码: 点击这里
- 以下代码执行操作 \(g(i,j) = \alpha \cdot f(i,j) + \beta\) : #include“opencv2/imgcodecs.hpp”#include“opencv2/highgui.hpp”#include < iostream>我们在这里不是“使用命名空间 std”,以避免 c++17 中 beta 变量和 std::beta 之间的冲突使用 std::cin;使用 std::cout;使用 std::endl;使用命名空间 CV;int main( int argc, char** argv ){CommandLineParser 解析器( argc, argv, “{@input |莉娜.jpg |输入图像}” );垫子图像 = imread( samples::findFile( parser.get<String>( “@input” ) ) );if( 图像。空() ){cout << “无法打开或找到图像!\n” << endl;cout << “用法:” << argv[0] << “<输入图像>” << endl;返回 -1;}垫子 new_image = Mat::zeros( 图像。size()、图像。类型() );双阿尔法 = 1.0;/*< 简单的对比度控制 */int beta = 0;/*< 简单的亮度控制 */cout << “基本线性变换” << endl;cout << “-------------------------” << endl;cout << “* 输入 alpha 值 [1.0-3.0]: ”;Cin >> Alpha;cout << “* 输入 beta 值 [0-100]: ”;Cin >> β;for( int y = 0; y <图像。行;y++ ) {for( int x = 0; x <图像。列;x++ ) {for( int c = 0; c <图像。通道();c++){new_image。at<Vec3b>(y,x)[c] =saturate_cast<uchar>( alpha*图像。at<Vec3b>(y,x)[c] + beta );}}}imshow(“原始图像”,图像);imshow(“新形象”, new_image);等待键();返回 0;}
解释
C++爪哇岛蟒
- 我们使用 cv::imread 加载图像并将其保存在 Mat 对象中:
CommandLineParser parser( argc, argv, “{@input |莉娜.jpg |输入图像}” );垫子图像 = imread( samples::findFile( parser.get<String>( “@input” ) ) );如果( 图像.empty() ) ){cout << "Could not open or find the image!\n" << endl;cout << "Usage: " << argv[0] << " <Input image>" << endl;return -1;}
- Now, since we will make some transformations to this image, we need a new Mat object to store it. Also, we want this to have the following features:
- Initial pixel values equal to zero
- Same size and type as the original image
Mat new_image = Mat::zeros( image.size(), image.type() );We observe that cv::Mat::zeros returns a Matlab-style zero initializer based on image.size() and image.type()
- We ask now the values of \alpha and \beta to be entered by the user:αβ
double alpha = 1.0; /*< Simple contrast control */int beta = 0;/*< 简单的亮度控制 */cout << “基本线性变换” << endl;cout << “-------------------------” << endl;cout << “* 输入 alpha 值 [1.0-3.0]: ”;Cin >> Alpha;cout << “* 输入 beta 值 [0-100]: ”;Cin >> β;
- 现在,要执行操作 g(i,j) = \alpha \cdot f(i,j) + \beta,我们将访问图像中的每个像素。由于我们使用的是 BGR 图像,因此我们将为每个像素(B、G 和 R)提供三个值,因此我们也将单独访问它们。这是一段代码:g( i,j)=α⋅f(i,j)+β
for( int y = 0; y <图像。行;y++ ) {for( int x = 0; x < image.cols; x++ ) {for( int c = 0; c < image.channels(); c++ ) {new_image.at<Vec3b>(y,x)[c] =saturate_cast<uchar>( alpha*image.at<Vec3b>(y,x)[c] + beta );}}}
请注意以下内容(仅限 C++ 代码):
- 为了访问图像中的每个像素,我们使用以下语法:image.at<Vec3b>(y,x)[c],其中y是行,x是列,c是B,G或R(0,1或2)。
- 由于运算 \alpha \cdot p(i,j) + \beta 可以给出超出范围的值或不是整数(如果 \alpha 是浮点数),因此我们使用 cv::saturate_cast 来确保值有效。α⋅p(i,j)+βα
- 最后,我们以通常的方式创建窗口并显示图像。
注意
与其使用 for 循环来访问每个像素,不如简单地使用以下命令:
其中 cv::Mat::convertTo 将有效地执行 *new_image = a*image + beta*。但是,我们想向您展示如何访问每个像素。无论如何,这两种方法都会给出相同的结果,但 convertTo 更优化并且工作速度更快。
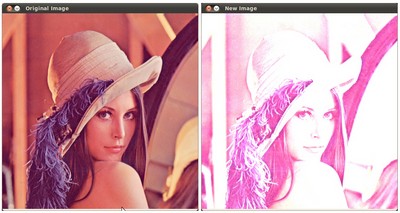
结果
- 运行我们的代码并使用 \alpha = 2.2 和 \beta = 50α=2.2β=50 $ ./BasicLinearTransforms lena.jpg基本线性变换-------------------------* 输入 alpha 值 [1.0-3.0]:2.2* 输入 beta 值 [0-100]:50
-
我们得到这个:
实例
在本段中,我们将通过调整图像的亮度和对比度来校正曝光不足的图像所学到的知识付诸实践。我们还将看到另一种校正图像亮度的技术,称为伽玛校正。
亮度和对比度调整
增加(/减少)\beta 值将为每个像素添加(/减去)一个常量值。超出 [0 ; 255] 范围的像素值将饱和(即高于(/小于)255 (/ 0) 的像素值将被限制为 255 (/ 0))。β
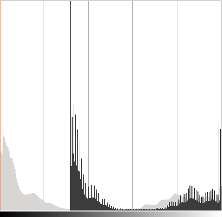
直方图表示每个颜色级别的像素数。深色图像将具有许多低色值的像素,因此直方图将在其左侧呈现峰值。当添加恒定偏差时,直方图会向右移动,因为我们为所有像素添加了恒定偏差。
\alpha 参数将修改级别的分布方式。如果 \alpha < 1 ,则颜色级别将被压缩,结果将是对比度较低的图像。αα<1
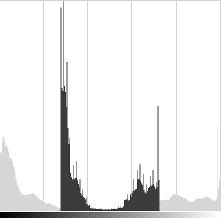
请注意,这些直方图是使用 Gimp 软件中的亮度对比度工具获得的。亮度工具应与 \beta 偏置参数相同,但对比度工具似乎与 \alpha 增益不同,其中输出范围似乎以 Gimp 为中心(如上一条直方图所示)。βα
可能会发生这样的情况:使用 \beta 偏差会提高亮度,但同时,由于对比度会降低,图像会出现轻微的面纱。\alpha 增益可用于减弱这种影响,但由于饱和,我们将丢失原始明亮区域中的一些细节。βα
伽玛校正
Gamma 校正可用于通过在输入值和映射输出值之间使用非线性变换来校正图像的亮度:

由于这种关系是非线性的,因此所有像素的效果都不相同,并且取决于它们的原始值。
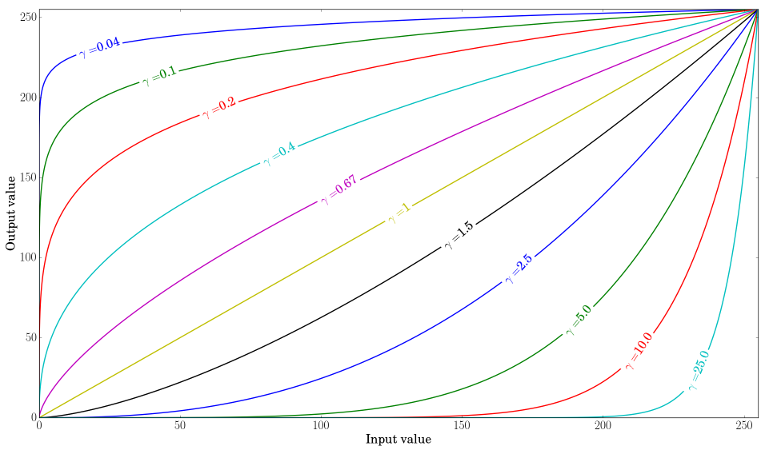
当 \gamma < 1 时,原始暗区会更亮,直方图会向右移动,而 \gamma > 1 则相反。γ<1γ>1
校正曝光不足的图像
下图已更正为:\ alpha = 1.3 和 \beta = 40。α=1.3β=40

整体亮度已得到改善,但您可以注意到,由于所用实现的数值饱和(摄影中的高光剪切),云层现在非常饱和。
下图已更正为:\ gamma = 0.4 。γ=0.4

伽马校正应该倾向于增加较少的饱和效应,因为映射是非线性的,并且不可能像以前的方法那样出现数值饱和。

上图比较了三个图像的直方图(三个直方图之间的 y 范围不同)。您可以注意到,大多数像素值都位于原始图像直方图的下部。在 \alpha , \beta 修正之后,由于饱和以及向右移动,我们可以观察到 255 处有一个大峰值。伽马校正后,直方图向右移动,但黑暗区域的像素比明亮区域的像素移动更多(参见伽马曲线图)。αβ
在本教程中,您已经了解了两种调整图像对比度和亮度的简单方法。它们是基本技术,不能用作光栅图形编辑器的替代品!
法典
C++爪哇岛蟒
教程的代码在这里。
伽玛校正代码:
查找表用于提高计算性能,因为只需计算一次 256 个值。
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓


人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓


这篇关于OpenCV改变图像的对比度和亮度!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






