本文主要是介绍月结——Transformer之上的一些故事,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Transformer
- 模型解释
- Bert
- ERNIE
- Style Transformer
Transformer
传统seq2seq的问题一般用CNN或者RNN的方式来处理,将seq编码为一个固定长度的向量然后再进行解码。因为固定长度向量所能表征的信息有限,因此对于长序列来说,前面的信息容易被埋没,即具有长程依赖问题,同时这种方式是顺序执行,使得没有办法进行并行计算。于是,google的大神们,开创了先河,提出一种只需要注意力机制的方式,不但能够并行化处理,还能把效果达到 the-state-of-the-art。后续也被验证,Transformer是目前特征提取的最有效方式,确实牛逼~~~
论文地址:https://arxiv.org/pdf/1706.03762.pdf
模型解释
-
总结构
transformer沿袭seq2seq的编解码结构,分为编码器和解码器。其中Encoder由6个基本层堆叠起来,每个基本层包含两个子层,注意力机制层和全连接前向神经网络,在全连接层中引入了残差并进行layer normalization。Decoder也由6个基本层堆叠起来,每个基本层除了Encoder的注意力层和全连接层,还增加了一层注意力机制,同样引入残差边以及layer normalization。
对于整体结构
输入: Token embedding + position embedding
输出:自定义,一般为另一种Token的embedding
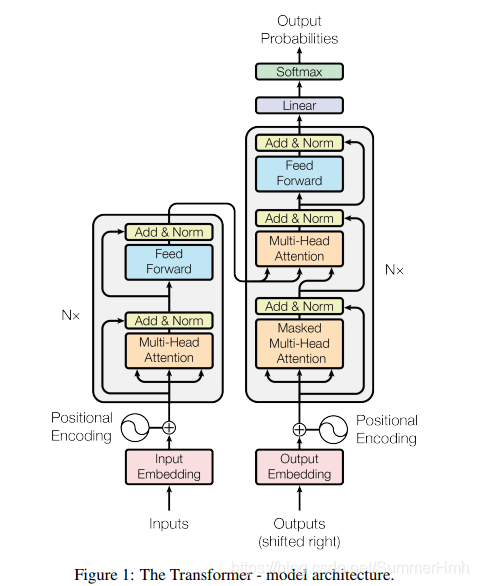
结构解析方面,网上资料已经很多,所以此处只描述一些有意思的点: -
注意力机制
- encoder self-attention
第一层的输入Q,K,V三者相同,均为Token embedding + position embedding,然后当前层的输入Q,K,V均为前一层的输出。这样能捕捉自身的相关关系 - encoder-decoder attention
encoder和decoder的交接层,每一层decoder的query输入来自前一层decoder的输出,k,v来自encoder的输出。这样decoder的每个位置都会去关注输入序列的所有位置 - decoder self-attention
输入Q,K,V三者相同,为上一层decoder输出 + position embedding,然后作为当前层decoder的输入query
- encoder self-attention
-
特点
- 多头的引入,能够将输入token进行多种transform,对于表征一词多义的场景很有提高
- 注意力机制的引入,能够对上下文信息进行关联,通过注意力机制,能够解决长程依赖的问题,但是有一个缺点,这个关联是无序的,相当于是一个词袋模型
- 位置编码方式,解决了无序问题,但是似乎也有点不足,待验证~~~
Bert
采用Transformer进行特征提取,Bert的模型基于Transformer,最大的特点在于
- 预训练模式:MLM,NSP
- 大量语料库
BERT验证了Transformer在解决一词多义问题上的超牛能力,同时也验证了google的有钱~~~~
具体可参考
https://blog.csdn.net/SummerHmh/article/details/91506347
ERNIE
此文的代言:为巨人进行锦上添花。整体的思路就是BERT+知识图谱,解决的问题主要是:
- 对知识图谱结构化的信息进行编码
- 异构信息进行融合
结构上,也是Transformer的花式应用
Style Transformer
这篇文章,很创新,既有巨人的影子,又有开创巨人的趋势,思路太6了
首先无监督的数据改造成有监督方式
其次采用gan的思路进行风格转换~~~~
参考:
https://yq.aliyun.com/articles/342508
https://www.jianshu.com/p/b1030350aadb
这篇关于月结——Transformer之上的一些故事的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






