本文主要是介绍力扣1122. 数组的相对排序(哈希表),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Problem: 1122. 数组的相对排序
文章目录
- 题目描述
- 思路及解法
- 复杂度
- Code
题目描述
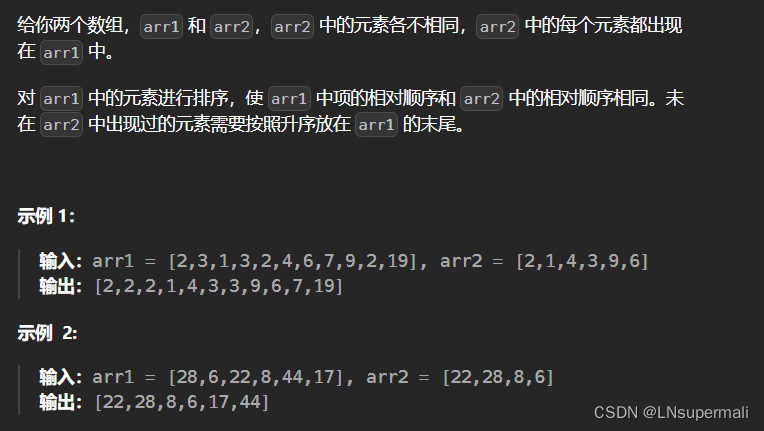
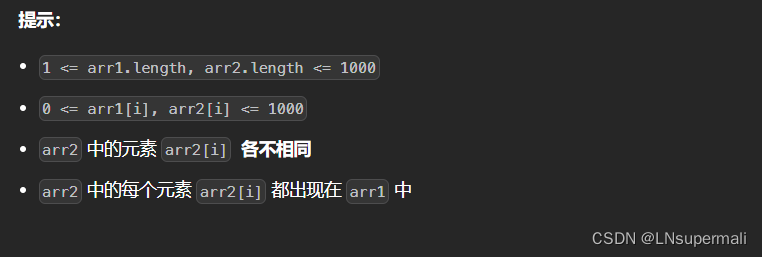
思路及解法
1.利用arr2创建一个无序映射(map集合),以其中的元素作为键,值默认设置为0;
2.扫描arr1数组统计arr2元素在其中的个数(将个数存入上述的map集合中);
3.按arr2中的元素的顺序将map集合中的值存入到一个数组中;
4.将arr1剩下的元素按升序存入到上述数组中;
复杂度
时间复杂度:
O ( n ) O(n) O(n);其中 n n n为arr1的长度
空间复杂度:
O ( n ) O(n) O(n)
Code
class Solution {
public:/*** Hsah** @param arr1 Given array1* @param arr2 Given array2* @return vector<int>*/vector<int> relativeSortArray(vector<int> &arr1, vector<int> &arr2) {// The number of times each number in arr2 appears in arr1unordered_map<int, int> counts;// Construct the hash table with arr2 firstfor (int i = 0; i < arr2.size(); ++i) {counts[arr2[i]] = 0;}// Scan arr1 Collects the number of occurrences of each digit in arr2 in arr1for (int i = 0; i < arr1.size(); ++i) {if (counts.find(arr1[i]) != counts.end()) {int oldCount = counts[arr1[i]];counts[arr1[i]] = oldCount + 1;}}vector<int> result(arr1.size());int k = 0;// Output count data in arr2 orderfor (int i = 0; i < arr2.size(); ++i) {int count = counts[arr2[i]];for (int j = 0; j < count; ++j) {result[k + j] = arr2[i];}k += count;}// Outputs data in arr1 that does not appear in arr2 in order to resultsort(arr1.begin(), arr1.end());for (int i = 0; i < arr1.size(); ++i) {if (counts.find(arr1[i]) == counts.end()) {result[k++] = arr1[i];}}return result;}
};
这篇关于力扣1122. 数组的相对排序(哈希表)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





