本文主要是介绍【mysql项目】模拟银行数据合并,一个身份证号可开通多个银行的信用卡的数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
需求
拉取过来的数据(比如浦发,兴业,农行等),格式如:
兴业:
手机号,姓名,开通信用卡功能(10万条)
浦发:
手机号,姓名,开通信用卡功能(10万条)
......
将上面的数据合并,因为每个身份证号有可能在多家银行开有信用卡,需要将20万条数据,假如这时只有18万不重复身份证号的数据。
数据效果展示
原始数据(黄色底为重复身份证号的数据):
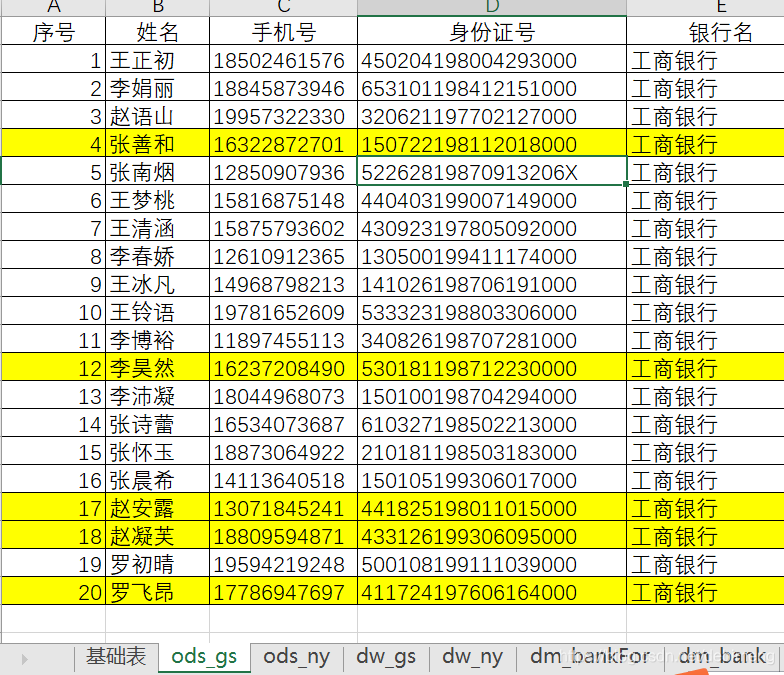
工商银行(共20条)
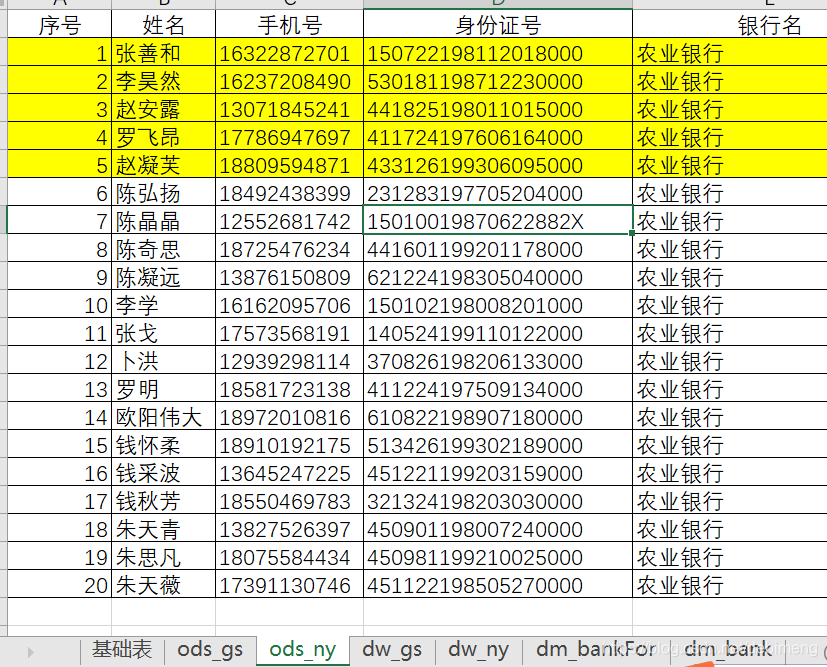
农业银行(共20条):
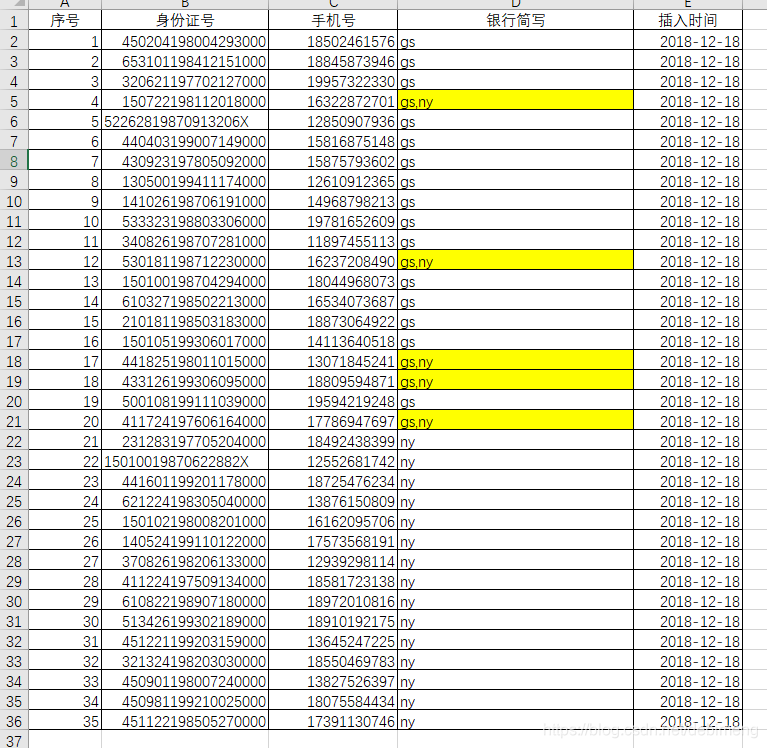
去重后的数据:
此时因为有五个身份证号在两个银行开通了信用卡业务,故该五个身份证在两个表中都存在,去重后剩下35条数据,并记录开通的银行业务名称。
基础表:

备注:对于身份证、手机号和姓名等敏感数据均从网络随机生成,如有雷同纯属巧合。
数据存放的环境
系统版本:CentOS 7.5
数据库:MySQL 5.7.23
-
数据库设计
-
设计概述
-
ODS表为原始数据,数据从客户业务系统拉取,包含中文数据;
DW表去掉中文后的数据,数据从ODS表获取;
DM为展示的数据,即系统最后需求的数据;
T为基础表。
银行表:t_bank
原始数据表:
ods_bankData_gs,ods_bankData_ny,ods_bankData_zg,ods_bankData_js……
DW数据表:
dw_bankData_gs,dw_bankData_ny,dw_bankData_zg,dw_bankData_js……
DM展示表:dm_bankFor
-
- 具体设计
#创建数据库
create database dbBank;/*
需求:
拉取过来的数据(比如浦发,兴业,农行等),格式如:
兴业:
手机号,姓名,开通信用卡功能(10万条)
浦发:
手机号,姓名,开通信用卡功能(10万条)
......
将上面的数据合并,因为每个身份证号有可能在多家银行开有信用卡,需要将20万条数据,假如这时只有18万不重复身份证号的数据
*/
#################################################
################## BASE ##################
#################################################
/*银行表:t_bank
序号,代码,银行名,银行简写
bankId<
这篇关于【mysql项目】模拟银行数据合并,一个身份证号可开通多个银行的信用卡的数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





