本文主要是介绍LLM之LangChain(七)| 使用LangChain,LangSmith实现Prompt工程ToT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
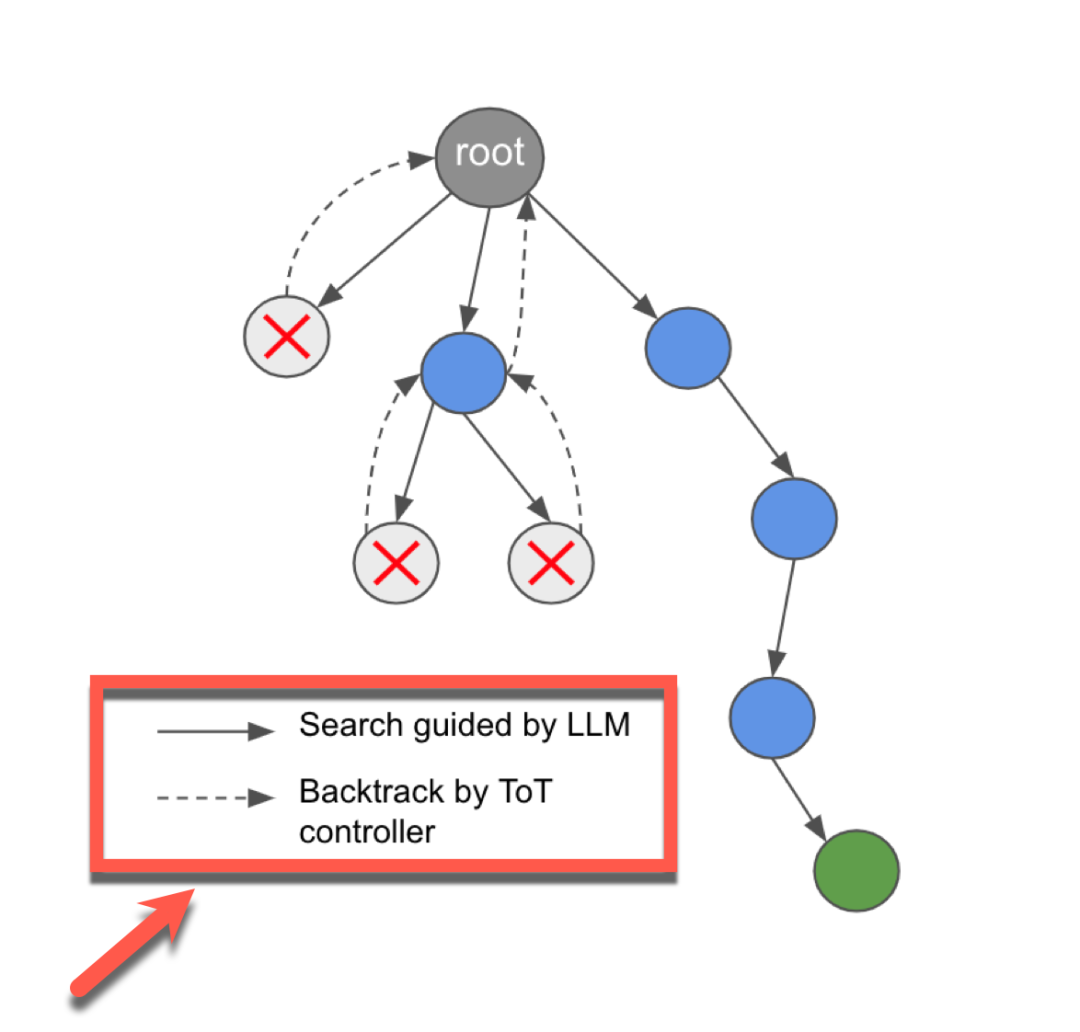
如下图所示,LLM仍然是自治代理的backbone,可以通过给LLM增加以下模块来增强LLM功能:
- Prompter Agent
- Checker Module
- Memory module
- ToT controller

当解决具体问题时,这些模块与LLM进行多轮对话。这是基于LLM的自治代理的典型情况,其中动态创建链并按顺序执行,同时多次轮询LLM。
下图是LangSmith[1]的界面,从图中可以看到使用的tokens总数以及两个延迟类别。
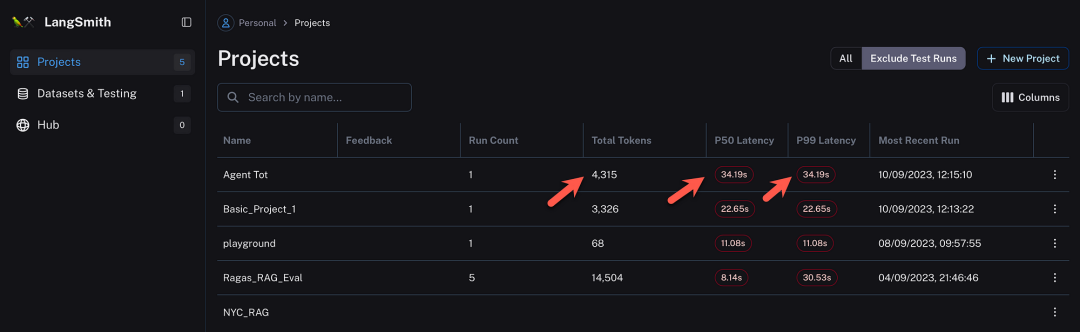
此图显示了Trace部分,其中包含为该代理创建的完整链,以及输入和输出。LangSmith在链的每一步都给出了详细的分解,包括成本(tokens)和延迟。

会话和状态历史记录(上下文)存储在内存模块中,这使代理可以参考思维过程的先前部分,并可能从历史记忆采取不同的路线。
为了验证ToT技术的有效性,本文实现了一个基于ToT的代理来解决数独难题。
论文[2]实验结果表明,ToT框架可以显著提高数独解谜的成功率
论文指出的一个漏洞是LLM是基于前面的序列生成内容,而忽略了向后编辑。然而,当我们人类解决一个问题时,如果派生的步骤不正确,我们很可能会回溯到以前的迭代。这种回溯方法否定了LLM达到不确定或无答案场景的危险。
其次,为了建立确保正确性,我们人类的一种做法是在解决问题的每一步都进行测试,这确保了最终解决方案的可信度。本文统计了自回归语言模型在基于以前的token生成新token时,不会显式执行逻辑正确性检查,这限制了LLM纠正自身错误的能力。随着模型生成更多的tokens,一个小错误可能会被放大,这通常被称为级联。因此这会导致生成质量下降,并使其难以从错误中恢复。级联很早就被认为是手动创建提示链的一种危险。然而,考虑到自主代理在运行中创建了一系列提示,它仍然容易受到级联的影响。
该策略[2]通过LLM和提示器代理之间的多轮对话来解决问题。
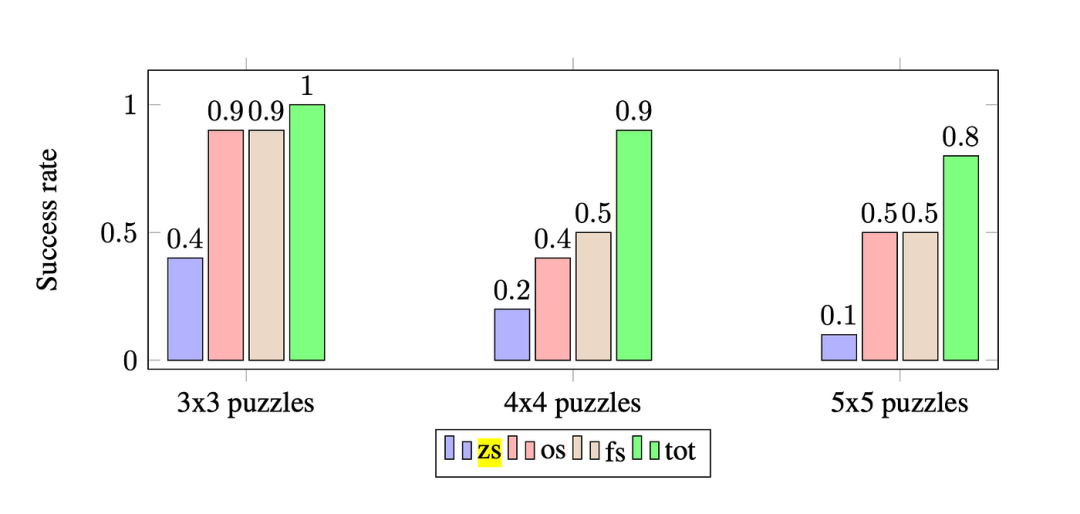
上图显示了四种方法的成功率:zero-shot(zs)、one-shot(os)、few-shot(fs)和Tree-of-Thought(tot)。
以下是ToT代理的完整代码,您可以将其复制并粘贴到笔记本中。您需要更新的只是OpenAI API密钥和LangSmith API密钥。
pip install langchainpip install langchain_experimentalpip install -U langsmithpip install openai#######import osfrom uuid import uuid4unique_id = uuid4().hex[0:8]os.environ["LANGCHAIN_TRACING_V2"] = "true"os.environ["LANGCHAIN_PROJECT"] = f"Agent Tot"os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"os.environ["LANGCHAIN_API_KEY"] = "xxxxxxxxxxxxxxxxxxxxxxxx"os.environ['OPENAI_API_KEY'] = str("xxxxxxxxxxxxxxxxxxxxxxxx")#######from langchain.llms import OpenAIllm = OpenAI(temperature=1, max_tokens=512, model="text-davinci-003")#######sudoku_puzzle = "3,*,*,2|1,*,3,*|*,1,*,3|4,*,*,1"sudoku_solution = "3,4,1,2|1,2,3,4|2,1,4,3|4,3,2,1"problem_description = f"""{sudoku_puzzle}- This is a 4x4 Sudoku puzzle.- The * represents a cell to be filled.- The | character separates rows.- At each step, replace one or more * with digits 1-4.- There must be no duplicate digits in any row, column or 2x2 subgrid.- Keep the known digits from previous valid thoughts in place.- Each thought can be a partial or the final solution.""".strip()print(problem_description)######## The following code implement a simple rule based checker for# a specific 4x4 sudoku puzzle.#######from typing import Tuplefrom langchain_experimental.tot.checker import ToTCheckerfrom langchain_experimental.tot.thought import ThoughtValidityimport reclass MyChecker(ToTChecker):def evaluate(self, problem_description: str, thoughts: Tuple[str, ...] = ()) -> ThoughtValidity:last_thought = thoughts[-1]clean_solution = last_thought.replace(" ", "").replace('"', "")regex_solution = clean_solution.replace("*", ".").replace("|", "\\|")if sudoku_solution in clean_solution:return ThoughtValidity.VALID_FINALelif re.search(regex_solution, sudoku_solution):return ThoughtValidity.VALID_INTERMEDIATEelse:return ThoughtValidity.INVALID######## Testing the MyChecker class above:#######checker = MyChecker()assert checker.evaluate("", ("3,*,*,2|1,*,3,*|*,1,*,3|4,*,*,1",)) == ThoughtValidity.VALID_INTERMEDIATEassert checker.evaluate("", ("3,4,1,2|1,2,3,4|2,1,4,3|4,3,2,1",)) == ThoughtValidity.VALID_FINALassert checker.evaluate("", ("3,4,1,2|1,2,3,4|2,1,4,3|4,3,*,1",)) == ThoughtValidity.VALID_INTERMEDIATEassert checker.evaluate("", ("3,4,1,2|1,2,3,4|2,1,4,3|4,*,3,1",)) == ThoughtValidity.INVALID######## Initialize and run the ToT chain,# with maximum number of interactions k set to 30 and# the maximum number child thoughts c set to 8.#######from langchain_experimental.tot.base import ToTChaintot_chain = ToTChain(llm=llm, checker=MyChecker(), k=30, c=5, verbose=True, verbose_llm=False)tot_chain.run(problem_description=problem_description)#######
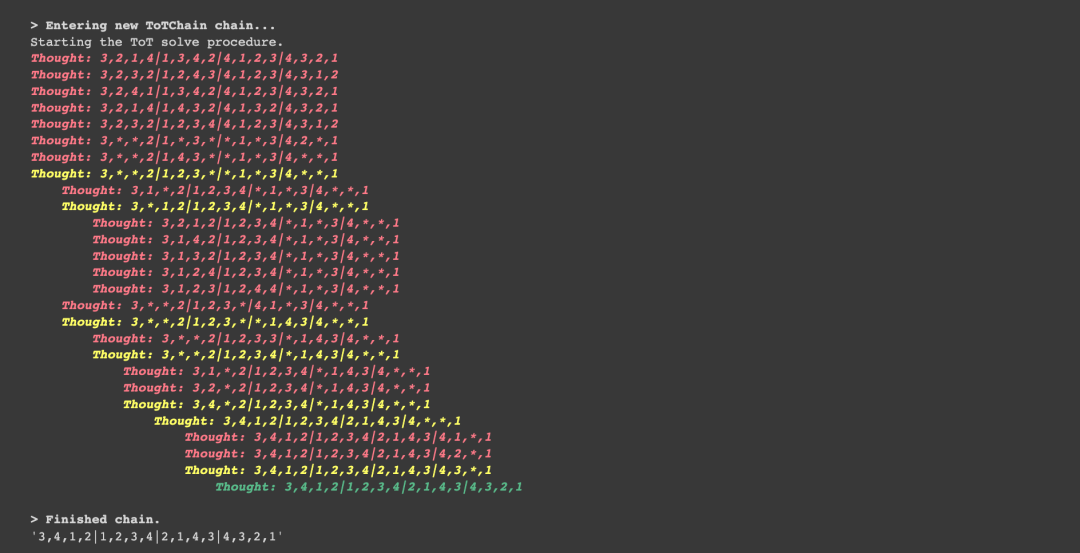
代理的输出、迭代和回溯可以在输出中看到:
> Entering new ToTChain chain...Starting the ToT solve procedure./usr/local/lib/python3.10/dist-packages/langchain/chains/llm.py:278: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.warnings.warn(Thought: 3,4,*,2|1,*,3,*|*,1,*,3|4,*,*,1Thought: 3,4,1,2|1,*,3,*|*,1,*,3|4,*,*,1Thought: 3,4,1,2|1,2,3,*|*,1,*,3|4,*,*,1Thought: 3,4,1,2|1,2,3,4|*,1,*,3|4,*,*,1Thought: 3,4,1,2|1,2,3,*|1,1,*,3|4,*,*,1Thought: 3,4,1,2|1,2,3,*|*,2,*,3|4,*,*,1Thought: 3,4,1,2|1,2,3,*|*,1,1,3|4,*,*,1Thought: 3,4,1,2|1,2,3,*|*,1,*,4|4,*,*,1Thought: 3,4,1,2|1,2,3,*|*,1,*,1|4,4,*,1Thought: 3,4,1,2|1,2,3,*|1,1,*,3|4,*,*,1Thought: 3,4,1,2|1,2,3,*|*,1,2,3|4,*,*,1Thought: 3,4,1,2|1,2,3,*|*,1,*,3|4,1,*,1Thought: 3,4,1,2|1,2,3,*|*,1,*,3|4,*,1,1Thought: 3,4,1,2|1,*,3,4|*,1,*,3|4,*,*,1Thought: 3,4,1,2|1,2,3,4|*,1,*,3|4,*,*,1Thought: 3,4,1,2|1,2,3,4|2,1,*,3|4,*,*,1Thought: 3,4,1,2|1,2,3,4|2,1,4,3|4,*,*,1Thought: 3,4,1,2|1,2,3,4|2,1,4,3|4,1,*,*Thought: 3,4,1,2|1,2,3,4|2,1,4,3|4,2,*,*Thought: 3,4,1,2|1,2,3,4|2,1,4,3|4,3,*,*Thought: 3,4,1,2|1,2,3,4|2,1,4,3|4,3,1,*Thought: 3,4,1,2|1,2,3,4|2,1,4,3|4,3,2,*Thought: 3,4,1,2|1,2,3,4|2,1,4,3|4,3,2,1> Finished chain.3,4,1,2|1,2,3,4|2,1,4,3|4,3,2,1
在Colab笔记本中查看的输出如下所示:
参考文献:
[1] https://cobusgreyling.medium.com/langsmith-1dd01049c3fb
[2] https://arxiv.org/pdf/2305.08291.pdf
[3] https://cobusgreyling.medium.com/langchain-langsmith-llm-guided-tree-of-thought-47a2cd5bcfca
这篇关于LLM之LangChain(七)| 使用LangChain,LangSmith实现Prompt工程ToT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






