本文主要是介绍postgresql 手动清理wal日志的101个坑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
新年的第一天,总结下去年遇到的关于WAL日志清理的101个坑,以及如何相对安全地进行清理。前面是关于WAL日志堆积的原因分析,清理相关可以直接看第三部分。
首先说明,手动清理wal日志是一个高风险的操作,尤其对于带主从的生产大库,能不用尽量不要用。
一、 常见的WAL 堆积原因
其实之前有总结过(第8题) 《PostgreSQL面试题集锦》学习与回答-CSDN博客
去年遇到的两次都是因为WAL日志生成量过大,而pg 10中归档进程又仅支持单进程串行归档,下面单独列一下这个问题。
二、 PG 10中WAL日志归档的瓶颈
1. 归档流程
每当WAL日志切换时,就可以通知对该日志进行归档:
- 产生日志切换的进程在pg_wal/archive_status下生成与待归档日志同名的.ready文件
- 发送信号通知archiver process(我们是pgbackrest的archive push),其只关心是否有.ready文件存在,不关心其内容
- archiver process(pgbackrest的archive push)按照archive_command进行日志归档
- 执行完成后,archiver process循环将.ready文件重命名为.done文件
2. 归档的瓶颈
由于我们使用的是pgbackrest,在上面步骤中,前三步都可以并行完成,唯独第四步,需要靠archiver process单独工作(pg 15版本引入了新特性,可以64个文件为一组进行操作)。
/** pgarch_ArchiverCopyLoop** Archives all outstanding xlogs then returns*/
static void
pgarch_ArchiverCopyLoop(void)
{char xlog[MAX_XFN_CHARS + 1];/** 循环处理.ready文件*/while (pgarch_readyXlog(xlog)){int failures = 0;int failures_orphan = 0;for (;;){struct stat stat_buf;char pathname[MAXPGPATH];…/* 进行日志归档 */if (pgarch_archiveXlog(xlog)){/* successful,归档成功,将.ready改为.done文件 */pgarch_archiveDone(xlog);/** Tell the collector about the WAL file that we successfully archived*/pgstat_send_archiver(xlog, false);/* 开始处理下一个日志 */break; /* out of inner retry loop */}/* 归档失败 */
...}}
}在WAL日志量不大,archive_status中文件不多时,循环查找文件并重命名是很快的,经观察:
- 在archive_status中约5000个文件时,archiver process每秒可以处理8~10个.ready文件
- 而在问题期间,archive_status中日志多达百万个,每次循环异常耗时,每秒仅能处理3~4个.ready文件(对应每小时约168~225G WAL日志)
- 在业务高峰期,每小时产生WAL日志基本都在200G以上,有时高达400G,远远高于其处理速度,导致archive_status目录中堆积文件更多,处理速度更慢
- 由于archiver process进程处理速度远远落后pgbackrest执行的archive_command命令,pgbackrest也认为自己无需再工作,因此未再启动
在pg中,只有已经归档的WAL日志(生成.done文件的)才能被回收或删除,由于归档速度过慢,导致可以被清理的WAL日志很少,而新增的WAL日志量又很大,最终导致WAL日志堆积,/data目录剩余空间持续下降。
...if (XLogArchiveCheckDone(xlde->d_name)){/* Update the last removed location in shared memory first,首先在共享内存中更新已被删除的位置 */UpdateLastRemovedPtr(xlde->d_name);/* 调用RemoveXlogFile函数进行删除或重命名,函数里使用unlink删除日志 */RemoveXlogFile(xlde->d_name, recycleSegNo, &endlogSegNo);}
...三、 WAL日志清理的101个坑
1. WAL日志的重命名
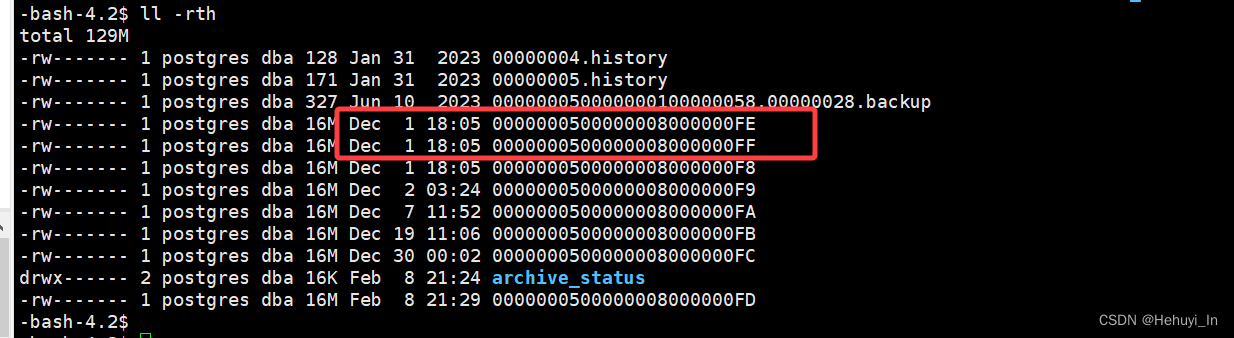
非常危险的一点,概括而言,pg会将最旧的一些wal日志重命名为最新的名字,但利用ll -rth排序查看时,其时间并不会变化。而pg_archivecleanup工具只根据文件名进行判断,很可能导致需要的文件被删除。具体分析参考postgresql源码学习(58)—— 删除or重命名WAL日志?这是一个问题、-CSDN博客
如下图,实际上FE和FF结尾的文件是重命名后的,但显示的时间并没有变化,按时间排序还是在最上面。
① 主库需要的日志被删除
这是最危险的情况,可能导致:
- 主库crash:在某些情况下,可能会由于数据不一致或者持续性错误导致主库宕机。这点目前没有测试出来,但风险肯定是存在的。
- 主库crash后无法启动:删除wal日志后kill pg进程即可复现,结合前一点,如果主库真的异常崩溃,很可能根本都无法启动
不幸中的万幸主库还活着,也存在以下风险:
- 主库数据丢失:未写入磁盘的事务可能会丢失,因为相关的WAL日志已经被删除。
- 数据不一致:如果已经提交的事务所对应的 WAL 日志被删除,那么这些事务的修改可能无法被正确地应用到从库上,从而导致数据不一致。
- 主从同步中断:相当于从库需要的日志被删除
- 旧备份无法恢复到最新状态:理论上建议立即发起一个全备,因为之前的备份链已经断了
来整点高危操作模拟一下,测试版本为pg 14
- 删除正在用的WAL日志,主库是否会crash
- 删除正在用的WAL日志,正常停库,能否启动
- 删除正在用的WAL日志,kill pg进程,能否启动
查看主库当前在用的wal日志
-bash-4.2$ pg_controldata
…
Latest checkpoint's REDO WAL file: 0000000500000008000000FD试试将其删除会发生什么
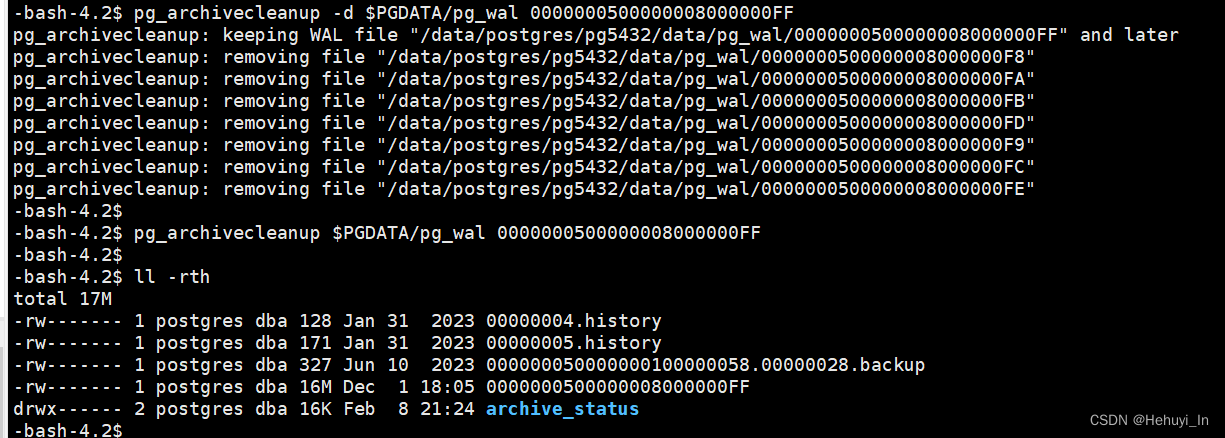
可以看到pg进程还在(当然不保证每次都会还在)

造点数据执行checkpoint,会发现它重新生成了FD的文件,但其实原来文件里的数据已经丢失了。

挪走FD文件,尝试正常停库再启动

发现能起来,并且它切换到了用FE文件

挪走FE文件,kill pg进程 再启动,这下悲剧了
再启动,这下悲剧了

看看日志报错

这只能走点更极端的路子,把pg_wal给reset掉,影响当然就更大了
pg_resetwal -f /data/postgres/pg5432/data

② 从库需要的文件被删除
- 导致主从中断,由于pg原生不支持并行备份,大库的搭建耗时耗力。
- 如果主库生成的wal日志量非常大(例如每天TB级),那更是雪上加霜,甚至需要停主库业务来搭建。
③ 新特性
在pg 12中,新增了wal_recycle参数,可以关闭wal日志的重命名,并且不需重启生效。虽然引入的原因是在COW文件系统中新建日志会更快,但也在很大程度上规避了误删wal日志的风险。
2. 孤儿.ready文件
这部分特别感谢熊灿灿老师帮忙一起分析,又学到不少新知识:
小心!孤儿归档也可能将数据库整死!
① pg 12之前
如果你只删除wal日志,会导致其对应的.ready变成孤儿文件,归档进程归档失败,会反复尝试处理第一个失败的wal日志,最终的结果就是wal日志仍然无法归档,出现堆积,空间被占满。
以pg 10为例,相关代码如下。可以看到如果归档失败,它只会sleep一段时间然后重试,并不做额外处理,因此日志中会一直看到archiving write-ahead log file failed too many times, will try again later 的报错
static void
pgarch_ArchiverCopyLoop(void)
{char xlog[MAX_XFN_CHARS + 1];/** loop through all xlogs with archive_status of .ready and archive* them...mostly we expect this to be a single file, though it is possible* some backend will add files onto the list of those that need archiving* while we are still copying earlier archives*/while (pgarch_readyXlog(xlog)){int failures = 0;for (;;){/** Do not initiate any more archive commands after receiving* SIGTERM, nor after the postmaster has died unexpectedly. The* first condition is to try to keep from having init SIGKILL the* command, and the second is to avoid conflicts with another* archiver spawned by a newer postmaster.*/if (got_SIGTERM || !PostmasterIsAlive())return;/** Check for config update. This is so that we'll adopt a new* setting for archive_command as soon as possible, even if there* is a backlog of files to be archived.*/if (got_SIGHUP){got_SIGHUP = false;ProcessConfigFile(PGC_SIGHUP);}/* can't do anything if no command ... */if (!XLogArchiveCommandSet()){ereport(WARNING,(errmsg("archive_mode enabled, yet archive_command is not set")));return;}if (pgarch_archiveXlog(xlog)){/* successful */pgarch_archiveDone(xlog);/** Tell the collector about the WAL file that we successfully* archived*/pgstat_send_archiver(xlog, false);break; /* out of inner retry loop */}else{/** Tell the collector about the WAL file that we failed to* archive*/pgstat_send_archiver(xlog, true);if (++failures >= NUM_ARCHIVE_RETRIES){ereport(WARNING,(errmsg("archiving write-ahead log file \"%s\" failed too many times, will try again later",xlog)));return; /* give up archiving for now */}pg_usleep(1000000L); /* wait a bit before retrying */}}}
}② 新特性
pg 12开始引入了一个检查,如果归档过程中发现仅有.ready文件,而没有对应wal日志,pg会在日志输出一条告警并删除这个.ready文件。
以pg 14为例,它新增了一段代码
if (stat(pathname, &stat_buf) != 0 && errno == ENOENT){char xlogready[MAXPGPATH];StatusFilePath(xlogready, xlog, ".ready");if (unlink(xlogready) == 0){ereport(WARNING,(errmsg("removed orphan archive status file \"%s\"",xlogready)));/* leave loop and move to the next status file */break;}if (++failures_orphan >= NUM_ORPHAN_CLEANUP_RETRIES){ereport(WARNING,(errmsg("removal of orphan archive status file \"%s\" failed too many times, will try again later",xlogready)));/* give up cleanup of orphan status files */return;}/* wait a bit before retrying */pg_usleep(1000000L);continue;3. 孤儿wal文件会有什么效果
因为archive process的效率依赖于archive_status目录中的.ready文件数,当时还想了个办法——如果我不清wal日志,只把.ready mv走会怎么样?
事实证明是不可行的,pg检查到wal日志没有.ready文件后,会给它重新生成一个对应的.ready文件,然后开始给它做归档,相当于归档是正常进行的。
四、 如何相对安全地手动清理wal日志
1. 准备工作
① pg 12及以上版本
整体操作是类似的,但对于高版本pg,相当于还有两道保险操作
- 设置 wal_recycle 为off,调整不用重启,可以极大地避免误删除风险

- wal日志和.ready文件不要求完全对齐
虽说12版本开始pg会自动清理孤儿.ready文件,但当堆积量太大时,归档进程处理效率会极其低下,等它一个个报错清也要到猴年马月。不过好处是可以不必完全对齐,差个几十几百的,pg也能自己给你处理了。
② pg 12之前版本
这就得靠自己了,我们准备了以下几道保险:
- 与业务沟通停写入业务,尽量减少wal日志产生量。
- 查看主从库当前在用的wal日志,待清理日志必须小于这个日志号。
以下图为例,主库当前发送的日志是1759xxxx,那么删除时,我们最多只删1758xxx的日志号

- 以文件修改时间和文件名共同作为删除条件
当wal日志被重命名后,虽然ll -rth查看其时间未变,但stat命令可以看到其change time和modify time都是变化的。因此我们实际应该用ll -rcth排序,查看最旧的日志名。
理论上知道这个特点后,用pg_archivecleanup按文件名分批清理也是可以的,并且速度更快。但安全起见我们还是用find命令,以ctime,mtime,name条件共同限制
ll -crth |grep 0000000300174|more
ll -cth |grep 0000000300174|more
ll -cth |grep 0000000300174|wc -l# 输出结果
Jan 29 04:55 - 10:29 0000000300174*- 输出待清理的文件名
find /data/postgres/pg5432/data/pg_wal -maxdepth 1 -mtime +0 -ctime +0 -name "0000000300174*" -exec ls -lhc {} \; > /tmp/old_wal_174.txt检查输出的文件名及时间是否符合预期
2. 正式清理
- 业务停写入操作
- 停pgbackrest
pgbackrest stop- 删除对应wal日志
find /data/postgres/pg5432/data/pg_wal -maxdepth 1 -mtime +0 -ctime +0 -name "0000000300174*" -exec rm -rf {} \;- 挪走对应.ready文件
这步若是使用find+rm,在文件量大时耗时过长,例如24万个文件,find+rm耗时超过15分钟,而mv在1分钟内可完成。
mkdir -p /data/postgres/pg5432/data/pg_wal/archive_status_bak0129
cd /data/postgres/pg5432/data/pg_wal/archive_status
mv 0000000300174*ready ../archive_status_bak0129/- 循环执行以上步骤,直至删完待清理文件
- 启动pgbackrest
pgbackrest start
ps -ef|grep pgbackrest- 检查archiver process
应该开始处理剩余的wal日志并且逐步推进(正常每秒10个以上),没有报错
ps -ef|grep archiver- 检查.ready文件数,应该逐渐减少
cd /data/postgres/pg5432/data/pg_wal/archive_status
ll -h |grep ready|wc -l- 检查wal日志数,应该逐渐减少
cd /data/postgres/pg5432/data/pg_wal/
ll -h |wc -l- 启动应用
一段时间后.ready文件及wal日志数应该能稳定在一个水平线而非持续走高,以我们的库为例,大概在7000个wal日志,120G左右
- 新增告警线
新加了wal目录大小的监控及告警,及时发现日志堆积问题,尽早处理
select sum((pg_stat_file(file)).size) from (select dir||'/'||pg_ls_dir(dir) as file from (select setting as dir from pg_settings where name='log_directory') t)t where (pg_stat_file(file)).change>=current_date;这篇关于postgresql 手动清理wal日志的101个坑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





