本文主要是介绍tidb v6 数据管理303 笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
https://www.modb.pro/doc/124130 ptca v6 题库https://www.modb.pro/doc/123201 ptcp v6 题库

Lesson 01 TiDB Cluster 部署
- TiUP 是从 TiDB 4.0 引入的包管理器
- TiUP 在执行时,命令和组件 < component > 可以同时出现
- TiDB 集群启动顺序:PD => TiKV => TiDB => TiFlash;停止顺序是启动顺序倒序
tiup cluster start tidb-test --init安全启动,为 root 用户生成初始密码set password = password('new pwd');可修改密码
Lesson 02 TiDB 的连接管理
- 100% 兼容 MySQL 5.7 协议
- 支持 MySQL 5.7 常用的功能及语法
- 不支持的功能特性:存储过程与函数、触发器、外键、函数、全文索引、CREATE TABLE AS SELECT
- TiDB 默认端口 4000
- 查看 TiDB 版本:
select tidb_version()\G
Lesson 03 TiDB 的配置
- TiDB 配置分两类
- 系统配置:TiDB Server,跟 SQL 有关的,存在 TiKV 里,更新配置不需要重启,可以通过 MySQL 客户端进行修改,有作用域
- 集群配置:TiKV、PD、一部分的 TiDB Server,存在自己节点的配置文件中,重启节点方可生效,没有作用域
- TiDB 系统参数的作用域:SESSION(会话级别,默认)、GLOBAL(全局级别)、INSTANCE(实例级别)
- 修改集群配置:
tiup cluster edit-config tidb-test,之后tiup cluster reload tidb-test重启所有节点应用新配置。tiup cluster show-config tidb-test查看配置。 - 6.0 有在线修改集群配置,但是实验特性,所以集群配置的修改还是需要重启节点才能生效
Lesson 04 用户管理与安全
-
查看用户信息
select user, host, authentication_string from mysql.user;
-
创建/删除用户
create user 'jack'@'172.31.0.%' identified by 'pingcap';
drop user 'user3'@'localhost'; -
修改密码
SET PASSWORD FOR 'test'@'localhost'=password('mypass');
ALTER USER 'test'@'localhost' IDENTIFIED BY 'mypass'; -
创建/删除角色
create role r_emp@'172.31.0.159';
create role r_emp@'%';
create role r_emp;
drop role 'r_admin','r_dev'@'localhost'; -
授权
grant select,insert on test.emp to 'jack'@'172.31.0.159';
grant select,insert on test.emp to 'r_emp';
-- 赋予用户全部权限
grant all privileges on . to 'user2'@'localhost' with grant option;
-- 将角色赋予用户
grant r_emp to 'jack'@'172.31.0.%';
-- 拥有角色的用户登录后,需开启角色
set role all;
-- 查看授权
show grants;
show grants for 'admin'@'localhost';
-- 回收用户全部权限
revoke all privileges on . from 'user2'@'localhost'; -
角色与用户相似之处为:
- 是被锁住(locked)的(不能用于登录)
- 没有密码
- 被存储在 mysql.user 表中
- 当用户登录后,必须使用
set role all命令开启用户被赋予的角色
- 忘记 root 密码的解决办法:
- 修改配置文件
[security]
skip-grant-table = true
- 重启数据库后生效
mysql -h 127.0.0.1 -P 4000 -u root
Lesson 05 监控 TiDB
- 两套体系:
- Grafana + Prometheus —— http://{grafana-ip}:3000,用户名密码默认 admin / admin
- TiDB Dashboard —— http://{pd-ip}:2379/dashboard,root / tidb
-
确认 TiDB 集群状态
$ tiup cluster display didb-test
-
报警项由低到高分为:警告、严重、紧急 三个级别
Lesson 06 TiDB 集群管理
- TiDB/TiKV/PD 在线扩容步骤:
- 编辑配置文件
- 执行扩容命令
tiup cluster scale-out tidb-test scale-out-tikv.yaml -uroot -p - 确认新节点是否加入
tiup cluster display tidb-test
- TiFlash 在线扩容
- 确认当前 TiDB 的版本支持 TiFlash
- Enable-plcaement-rules 开启参数
- 编辑配置文件
- 执行扩容命令
- 确认新节点加入
- TiDB/TiKV/PD 在线缩容步骤:
- 查看节点 ID 信息
tiup cluster display tidb-test - 执行缩容操作
tiup cluster scale-in tidb --node <node-IP>:<node-Port>,执行后节点变为Tombstone状态,可继续通过tiup cluster prune tidb-test命令清理节点 - 检查集群状态
- TiFlash 在线缩容
- 根据 TiFlash 剩余节点数调整数据表的副本数
alter table <db-name>.<table-name> set tiflash replica 0; - 确认表的副本已经被删除
SELECT * FROM information_schema.tiflash_replica WHERE TABLE_SCHEMA='<db_name>' and TABLE_NAME='<table_name>' - 查看节点 ID 信息
- 通过 TiUP 缩容 TiFlash 节点
- 检查集群状态
- 重命名集群
tiup cluster rename $ {cluster-name} $ {new-name} - 清理集群数据
tiup cluster clean $ {clust4er-name} --xxx,清理会停库,再使用需要重新启动 TiDB,清理后 root 用户没有密码了,可以直接登录
--log清理日志--data清理数据--all清理日志和数据
-
销毁集群
tiup cluster destroy tidb-test -
查看全局和 session 的时区:
select @@global.time_zone, @@session.time_zone;
-
设置 session 级别时区
set session time_zone='UTC';
-
Datetime 类型不受时区影响,timestamp 类型受时区影响
Lesson 07 升级 TiDB Cluster
-
升级集群上的所有 TiDB 实例,
-R指定要升级的组件,tidb、tikv、pd 等$ tiup cluster patch $ {cluster-name} /tmp/tidb-hotfix.tar.gz -R tidb
-
替换其中一个 TiDB 实例
$ tiup cluster patch $ {cluster-name} /tmp/tidb-hotfix.tar.gz -N $ {Node_IP}:$ {Node_Port}
-
升级 TiDB 集群分为不停机升级和停机升级
-
版本升级流程:升级 TiUP => 修改 TiUP Cluster 拓扑配置文件 => 检查当前集群健康状况 => 将集群升级到指定版本 => 验证
-
5.3 之前 TiFlash 不支持在线升级
-
升级时报错中断,处理完报错后如何继续
查看操作记录,找到失败的升级操作记录的 ID
$ tiup cluster audit
重试上次的升级操作记录
$ tiup cluster replay
-
升级过程中 evict leader 等待时间过长,如何跳过该步骤快速升级
$ tiup cluster upgrade --force
Lesson 08 备份恢复策略
- 备份的类型
- 热备份:允许读写,对性能有影响,TiDB 采用 MVCC 方式实现
- 冷备份:不允许读写
- 温备份:允许读,不允许写
- 按输出分类:
- 逻辑备份:SQL、CSV,可读性好,速度慢,支持异构数据迁移
- 物理备份:二进制副本,恢复速度快,不可读,只能同构恢复
- 基于复制增量备份:主从模式,对主库影响小,主库出问题备库能立即提供服务
- BR 是热备份 & 物理备份
Lesson 09 数据导出工具 Dumpling
-
用于完成逻辑上的全量备份或者导出,不支持增量导出
-
支持 table-filter,筛选数据导出
-
适用于数据量小于 50G 的导出场景
-
导出数据的一致性:通过 --consistency标识控制导出数据,默认是
Snapshot级别(获取指定时间戳的一致性快照),还有Flush(全库加只读锁),Lock(给要导出的表加读锁),None(不要一致性),Auto(根据数据库类型,如果是 TiDB,设置为 Snapshot,如果是 MySQL,设置为 Flush)$ ./dumpling --snapshot 417773951312461825
$ ./dumpling --snapshot "2020-07-02 17:12:45"
Lesson 10 使用 TiDB Lightning 导入数据
- TiDB Lightning 是导入 SQL、CSV 至 TiDB 的工具
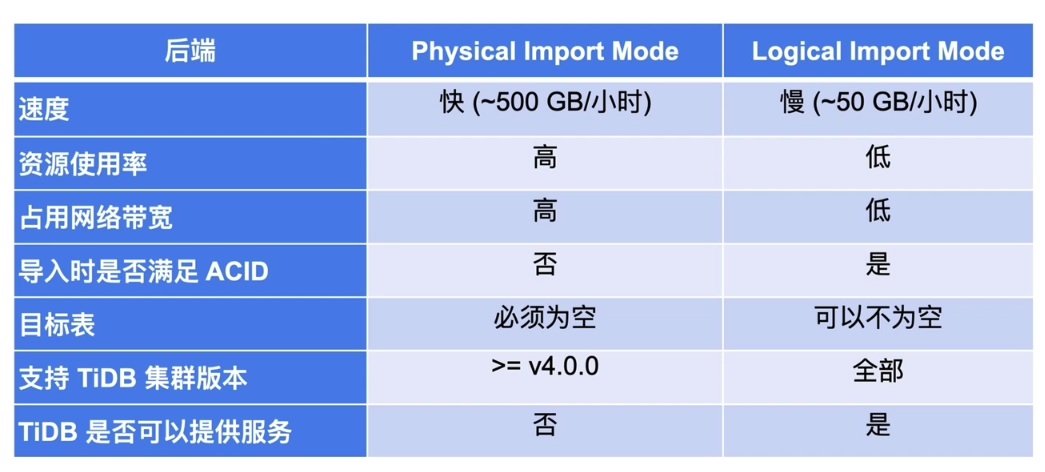
- TiDB Lightning 的两种导入模式:
- Physical Import Mode
- Logical Import Mode:连到 TiDB Server 上执行 SQL
- Physical Import Mode 原理
- 切换 TiKV 为导入模式
- Schema & 表创建
- 分割源数据
- 读取 dump 文件
- 写入本地临时文件(转换成 key-value 格式,并排序)
- 导入临时文件到 TiKV 集群
- 检验与分析
- 切换回普通模式
- 并行导入时,TiDB Lightning 实例数不宜超过 10 个
- 支持断点续传,断点可以存储在文件或数据库中
- 逻辑模式不直接写 TiKV,是向 TiDB Server 执行 SQL
Lesson 11 使用 BR 进行备份恢复
-
BR —— Backup & Restore
-
BR 直接与 PD 和 TiKV 交互,不经过 TiDB Server
-
BR 是二进制备份,只能恢复到 TiDB 数据库中
-
备份输出文件:SST 文件、backupmeta 文件、backup.lock 文件
-
TiDB 5.4 版本之后才开始支持 GBK 字符集
-
BR 恢复的工具无法通过 TiCDC 或 TiDB Binlog 同步到下游
-
备份时,每个 TiKV 备份自己 TiKV 节点里存储的数据
-
恢复时,要将各个节点的数据先进行汇总,保证每个节点都有全量的恢复数据,才能进行恢复
$ br backup/restore full/db/table \
--pd "$ {PDIP}:2379" \
--db test \
--table usertable \
--storage "s3://backup-data/table/" \
--ratelimit 128 \
--log-file backup.log -
增量备份需先获得最近一次备份的时间点,并传入备份指令
-
BR 是热备份,物理备份,支持增量备份 & 恢复
Lesson 12 使用 sync-diff-inspector 校验数据
- 原理:并行切分数据并行比较,比较时采用二分法,缩小逐行比较的范围
- 限制:
- 不支持 JSON、BIT、BINARY、BLOG 等类型的数据
- FLOAT、DOUBLE 等浮点数类型无法在 TiDB 和 MySQL 之间进行校验
- 不包含主键或者唯一索引的表可以进行校验,但修复 SQL 可能无法正确修复数据
- MySQL 与 TiDB 之间或者 MySQL 与 MySQL 之间的数据校验不支持数据同步在线校验
sharding选项默认打开,支持源端分表分库目标并表的验证
Lesson 13 使用 TiDB DataMigration(DM)同步数据
-
一个 DM worker 对应上游的一个数据库实例,读取上游 binlog 进行同步
-
数据源多于 worker 数量时,多出的 worker 空闲
-
DM 的目标端只能是 TiDB,源端可以是多个兼容 MySQL 协议的数据库
-
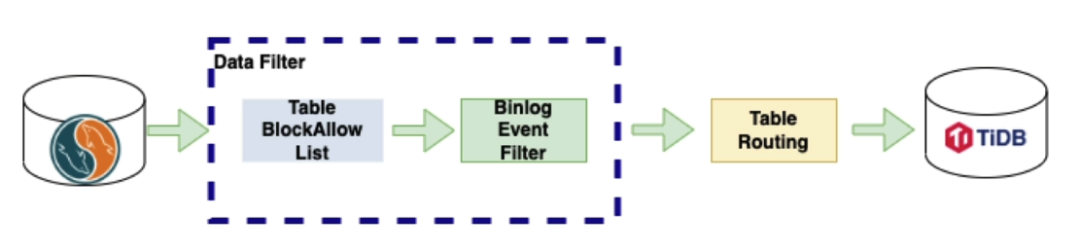
DM 依赖源端数据库开启 binlog,可以通过 binlog event filter 过滤某些操作不进行复制
-
用户通过 dmctl 命令行工具向 DM master 发送指令,DM master 再操作 DM worker 进行同步
-
支持全量及增量同步、源库表与目标库异构表的同步、进行分表分库的合并同步
-
DM 可以支持一定程度的异构表迁移,只要异构表存在包含关系(源库不能选择列,需要复制全部列;目标表的列可以多于源库表的列)
-
DM 部署相关命令
$ tiup install dm dmctl
$ tiup dm display dm-test
$ tiup dm start dm-test
$ tiup dm listDM 集群缩容
$ tiup dm scale-in dm-test -N 172.31.0.175:8262
DM 集群扩容
$ tiup dm scale-out dm-test dm-scale.yaml -uroot -p
$ tiup dm stop dm-test
$ tiup dm destory dm-test -
DM 的任务包含:源端、目标端、数据过滤(黑白名单、事件过滤)和表路由
检查与启动任务
$ tiup dmctl --master-addr=172.31.0.49:8261 start-task dm-task.yaml
暂停任务
$ tiup dmctl --master-addr=172.31.0.49:8261 pause-task dm-task.yaml
恢复任务
$ tiup dmctl --master-addr=172.31.0.49:8261 resume-task dm-task.yaml
查询任务
$ tiup dmctl --master-addr=172.31.0.49:8261 query-status dm-task.yaml
停止任务
$ tiup dmctl --master-addr=172.31.0.49:8261 stop-task dm-task.yaml
Lesson 14 使用 TiCDC 同步数据
- 数据源是 TiDB,下游是兼容 MySQL 协议的数据库或 kafka 等,与 DM 是反向的
- TiCDC 集群中的一个节点负责多个 TiKV
- TiCDC 读取的是 TiKV 的 changelog,比 TiDB Binlog 的效率高
- TiCDC 是异步复制,目标端与源端有时间延迟;源头数据库出现灾难后依然有丢失数据的可能
- TiCDC 只能同步至少存在一个有效索引的表
- 同步任务不能在线修改配置,需要先 pause,然后 update,再 resume
- TiCDC capture 可以有多个,并行从 TiKV 读取 changelog;导入目标端时,一个 capture 对应一个目标端,但是会将其他 capture 中的数据复制到自己这再向下游同步。只有负责汇聚数据的 capture 里才有全量的 changelog 数据
- TiCDC 目标端不支持 Oracle
- Changelog 抽取到 TiCDC 中时,会在本地进行排序
- TiCDC 可以通过 TiDB 集群的拓扑文件进行部署及扩缩容
Lesson 15 使用 TiDB Binlog 同步数据
- TiDB Binlog 的作用与 TiCDC 类似,TiDB 5.0 版本后,推荐使用 TiCDC 替代 TiDB Binlog
- 只能做增量复制,不能做全量复制
- 可以使用 tiup 工具为 TiDB 集群增加 TiDB Binlog 所使用的 pump 和 drainer 节点
- Pump 会先将数据进行排序,之后发送给 drainer,drainer 再进行合并排序
- TiDB Binlog 类似 MySQL row 格式的 binlog,记录的是已经提交的事务,默认未开启
- Pump 不是从 TiKV 读取,是直接从 TiDB 读取 TiDB 产生的 binlog 日志
- 一个 drainer 对应一个目标端
Lesson 16 数据库高可用概述
- 恢复时间目标(Recovery Time Objective,RTO)
- 恢复点目标(Recovery Point Objective,RPO)
- TiDB 支持 CP,不支持 AP,出现网络隔离时,保证一致性,不保证可用性
- TiDB 数据库提供强一致性,如不能保证强一致性,则拒绝服务
- 故障解决会伴随有服务的降级
Lesson 17 TiDB 数据库常用高可用架构
- 同城三中心:网络延迟小,RTO 较小,RPO 为 0
- 同城两中心(50km 内),中心之间同步复制,DR AutoSync,建议四副本,3 voter 1 leaner,非极端情况可保证 RPO = 0
- 两地三中心,城市之间是异步复制,不能保证 RPO = 0 和一致性恢复
- 异步复制是通过 TiDB Binlog 或 CDC 组件完成,会丢失数据(RPO 不为 0),有损恢复后,保证一致性
墨力计划
最后修改时间:2024-01-18 14:37:29
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
赞赏
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
墨天轮国产数据库排行榜年终总结-2023年
陈举超
2548次阅读
2023-12-21 15:06:42
实战-RAC迁移项目(1/3):RAC-RAC的DG搭建
徐sir
1245次阅读
2023-12-20 01:10:05
【提名公布】2023年度优秀原创作者评选完整提名名单公布!
墨天轮编辑部
905次阅读
2024-01-08 17:16:13
使用AutoUpgrade升级单实例Oracle 11G到Oracle 19C
董大威
833次阅读
2023-12-29 17:16:41
磐维数据库2.0系列:双中心容灾配置
#5z#
801次阅读
2024-01-06 10:43:38
简化流程:通过响应文件在Red Hat 7.6上静默安装Oracle 19C
董大威
685次阅读
2023-12-22 11:02:21
实用小技巧:UNDO 100%占用不释放解决办法
徐sir
663次阅读
2023-12-26 22:25:28
如何正确在windows server core(无图形界面)安装Oracle 19c
徐sir
659次阅读
2023-12-29 22:56:51
也谈IT从业者的35岁魔咒——DBA篇
多明戈教你玩狼人杀
611次阅读
2024-01-10 12:32:56
恼人的“龙天“(䶮)--谈谈从GBK转到GB18030的特殊情况
DarkAthena
581次阅读
2024-01-12 19:01:07
大圣11
关注
4
文章
0
粉丝
191
浏览量

内容获得1次评论
热门文章
tidb v6 认证
2024-01-1036浏览
tidb 原理与架构101 (PCTA 笔记分享)
1天前28浏览
Oracle godbengae 同步实验
2024-01-1020浏览
快讯:达梦数据库科创板上市已获证监会批准
2023-12-204275浏览
墨天轮国产数据库排行榜年终总结-2023年
2023-12-212548浏览
最新文章
tidb 原理与架构101 (PCTA 笔记分享)
1天前28浏览
Oracle godbengae 同步实验
2024-01-1020浏览
tidb v6 认证
2024-01-1036浏览
国产数据库要不要支持?
4小时前36浏览
一则罕见的流复制延迟案例
14小时前45浏览
这篇关于tidb v6 数据管理303 笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







