本文主要是介绍python分析数据走势_Python数据可视化:2018年北上广深空气质量分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
有态度地学习
就在这周偶然看到一个学弟吐槽天津的空气,不禁想起那段厚德载雾,自强不吸的日子。
无图无真相,下图为证。
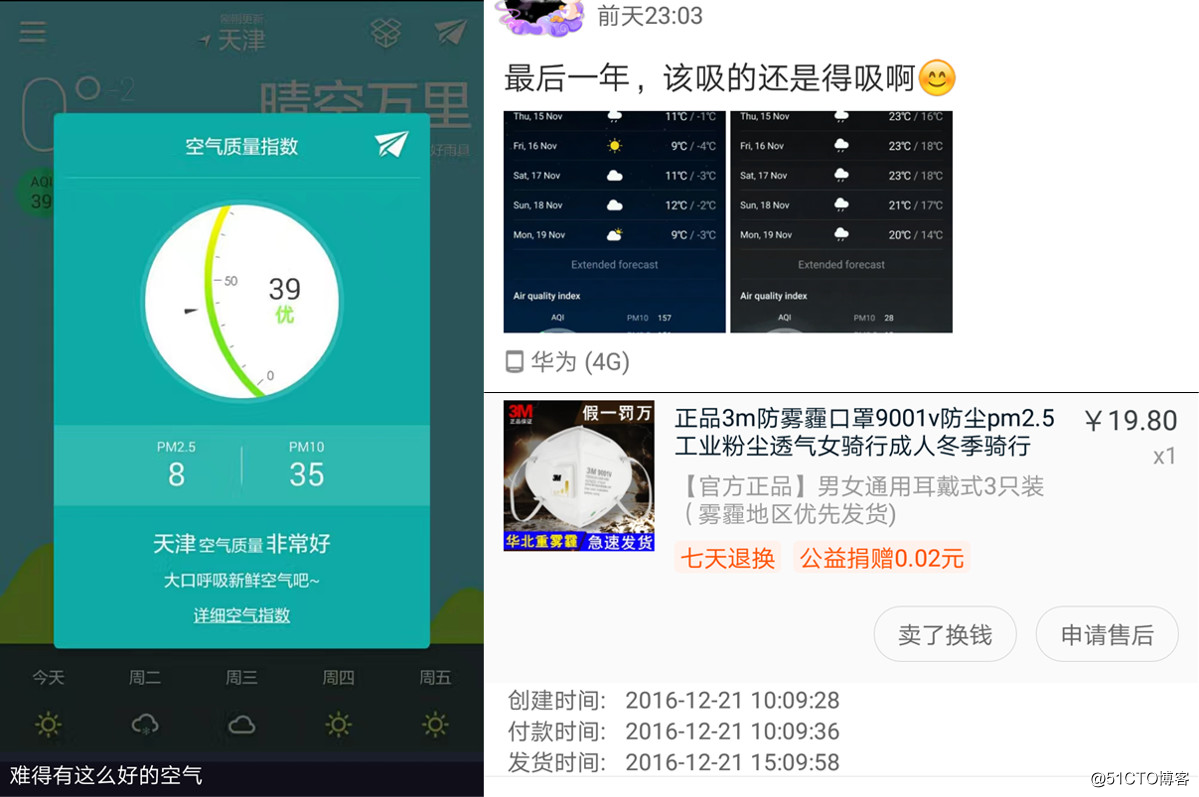
左边的图是去年2月份的时候,这样的空气真的难得一见!
右边的是吐槽以及我个人第一次买口罩!!!
口罩用的还行,因为那个时候做课设,经常要两个校区跑,基本上空气不好我就会带上。
题目好像是有关液压及气压的传动系统,手画A0图...
这应该是快两年前的事了,时光飞逝呐。
所以这回先对2017年天津的空气质量情况进行分析,然后再是北上广深。
/ 01 / 网页分析
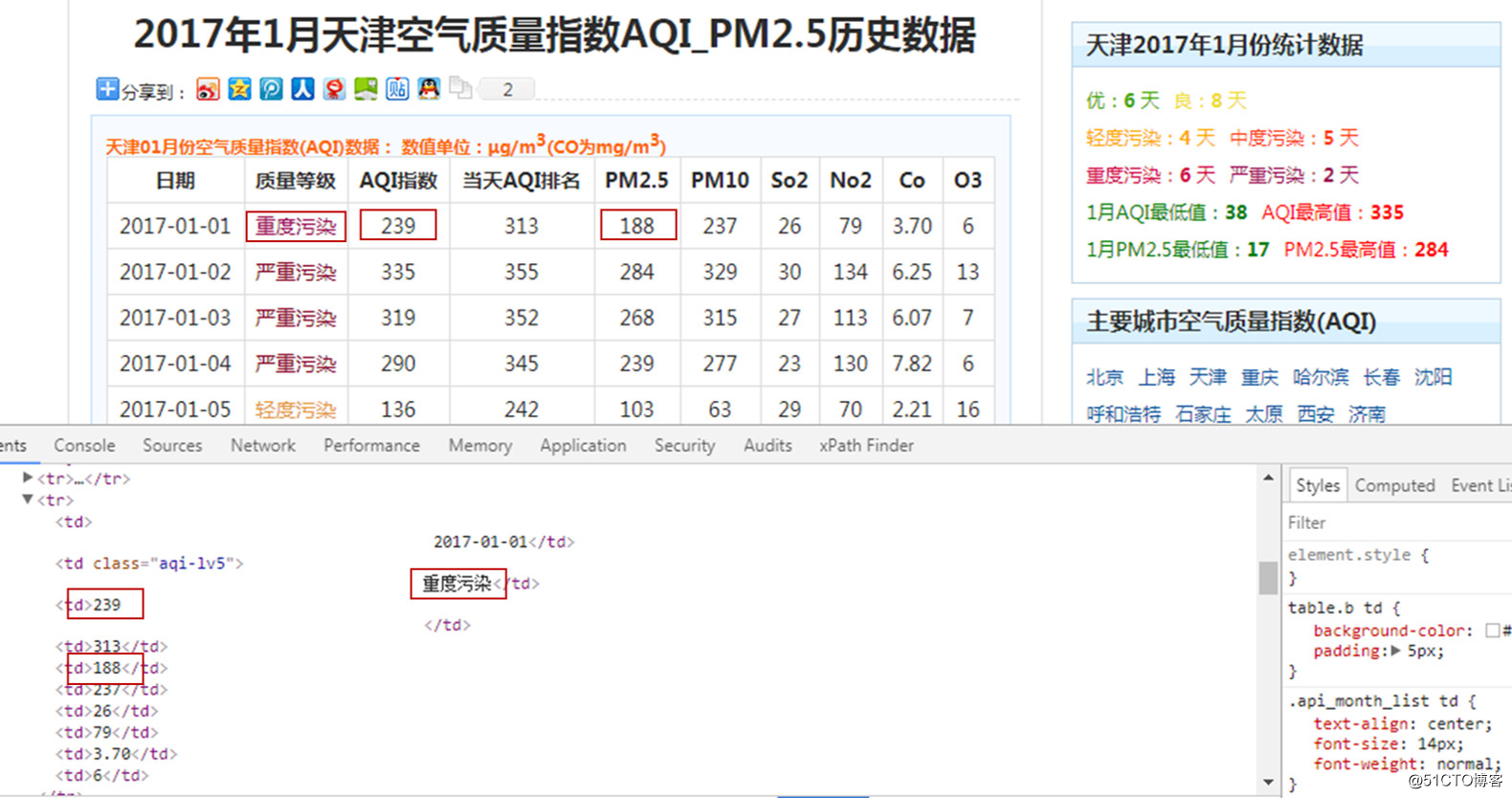
网站没有反爬,所以直接抓取信息就好了。
看见没有,妥妥的严重污染,2016年12月份买的口罩派上用场啦!
这里简单给大家科普一下有关AQI,PM2.5的知识。

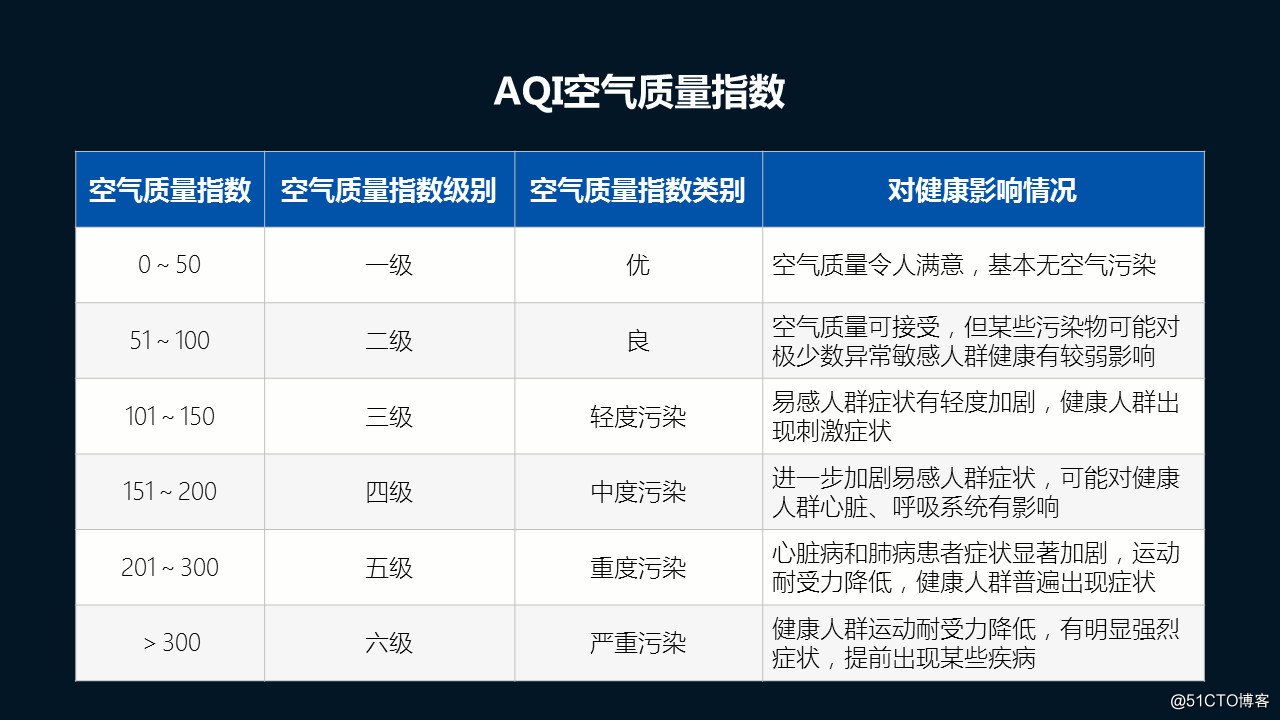
又是重操旧业,我的PPT水平还是很水呢~
/ 02 / 数据获取
获取代码如下所示。
import time
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
for i in range(1, 13):
time.sleep(5)
# 把1转换为01
url = 'http://www.tianqihoubao.com/aqi/tianjin-2017' + str("%02d" % i) + '.html'
response = requests.get(url=url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
tr = soup.find_all('tr')
# 去除标签栏
for j in tr[1:]:
td = j.find_all('td')
Date = td[0].get_text().strip()
Quality_grade = td[1].get_text().strip()
AQI = td[2].get_text().strip()
AQI_rank = td[3].get_text().strip()
PM = td[4].get_text()
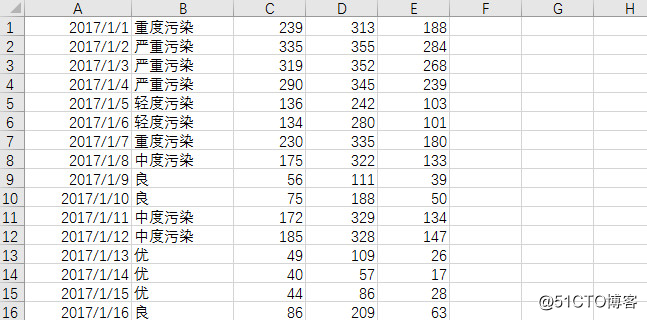
with open('air_tianjin_2017.csv', 'a+', encoding='utf-8-sig') as f:
f.write(Date + ',' + Quality_grade + ',' + AQI + ',' + AQI_rank + ',' + PM + '\n')
成功获取数据。
/ 03 / 天津
同样不上源码,这里有必要说一波,因为我觉得源码放上去排版就不好看了...
其次我要秉承以前混迹P圈(PPT)得到的优良传统,热爱分享,百度云盘你值得拥有。
所以公众号回复天气。即可获取全部可视化源码及相关文件。
以前天天去下载PPT大神的大作,然后观摩,可惜的是PPT水平还是那么菜~
01 AQI全年走势图
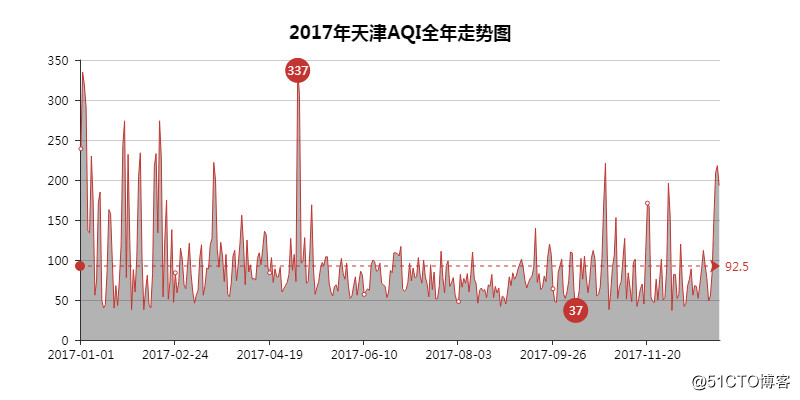
92.5是年均AQI值,从上面科普知识里可以知道,2017年天津整体空气质量只能是「良」中的下下等水平,与轻度污染近在咫尺。
02 AQI月均走势图
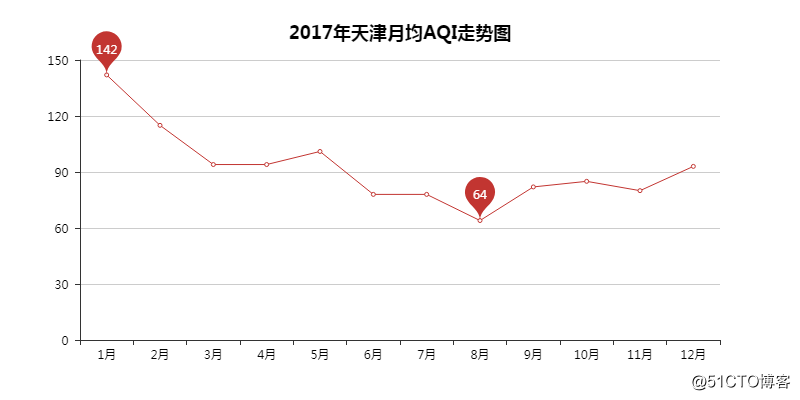
从月均的走势图就能看出,1月的空气质量最差,8月的空气质量最好,当也并不是有多好,充其量也就是个「良」!
03 AQI季度箱形图
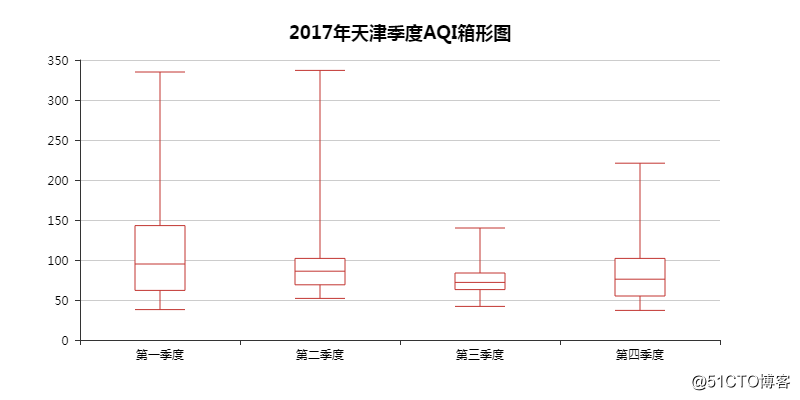
箱形图,显示一组数据分散情况资料的统计图。
数据里有最大值、最小值、中位数和两个四分位数。
这里可以看出,2017年天津的季度AQI均值差距不是很大。
但是一、二、四季度有明显的波动,空气质量有时会变得很差。
04 PM2.5全年走势图
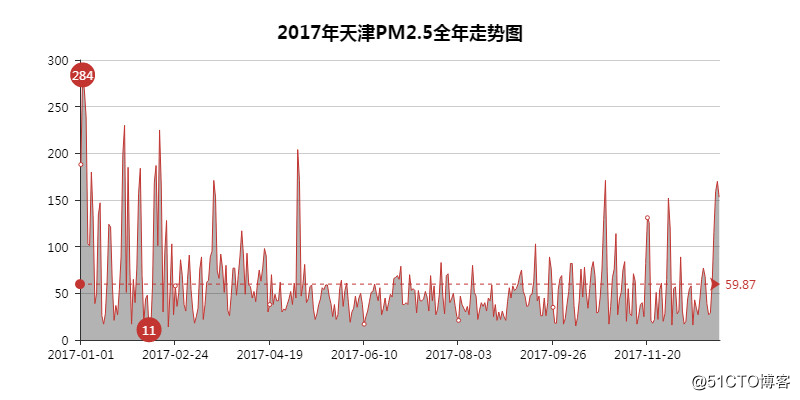
59.87是年均PM2.5值,已经远超过国家二级标准限值35了。
其实天津给我留下的印象就是天气经常灰蒙蒙,时常还会变点颜色,比如黄色~
一年下不了几次雨,及其干燥。所以那个最低值11,我猜那时候估计是刮大风。
05 PM2.5月均走势图
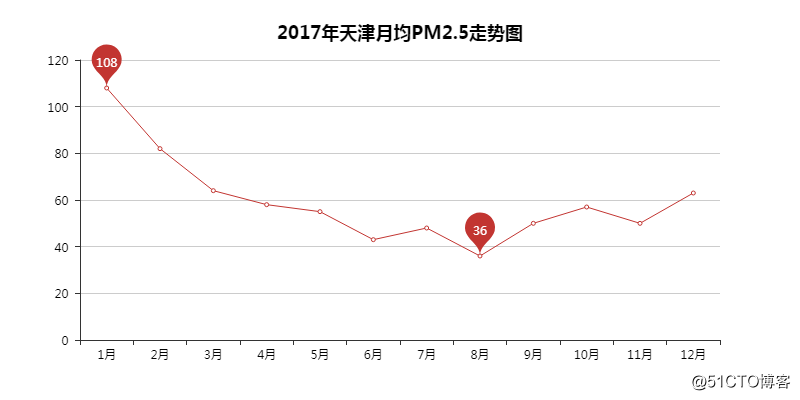
和AQI的走势差不多,同样是1月最高,8月最低。
06 PM2.5季度箱形图
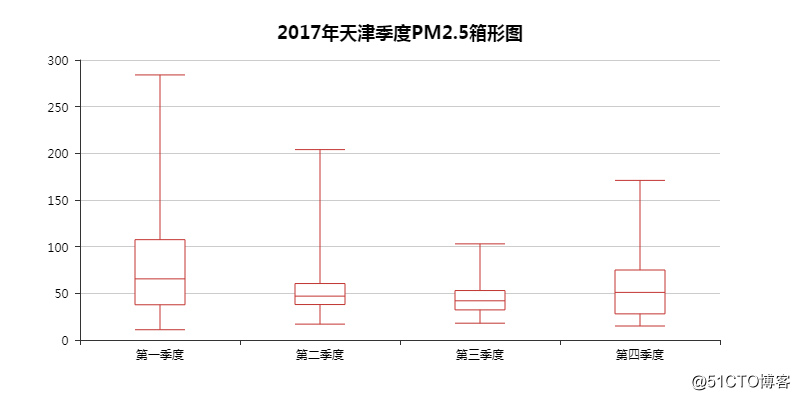
说实话,看了这个图,我不知道天津的「大哥」及「姐姐」们是如何做到自强不吸的。
基本上四个季度都超标了,一年不超标的估计也就那么几次。
07 PM2.5指数日历图
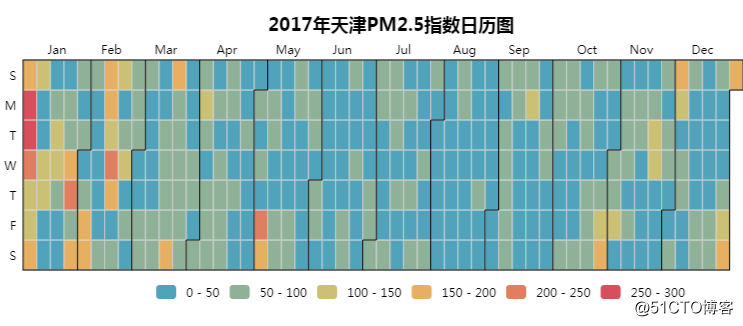
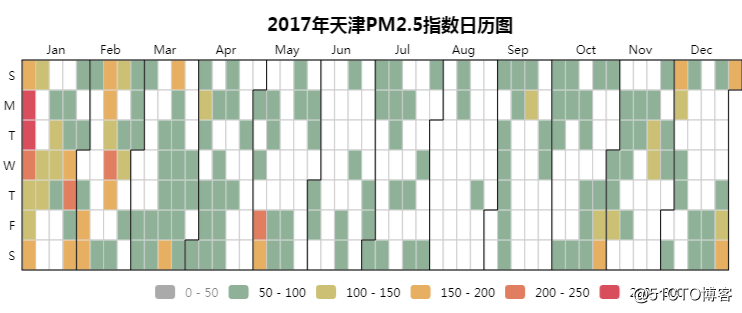
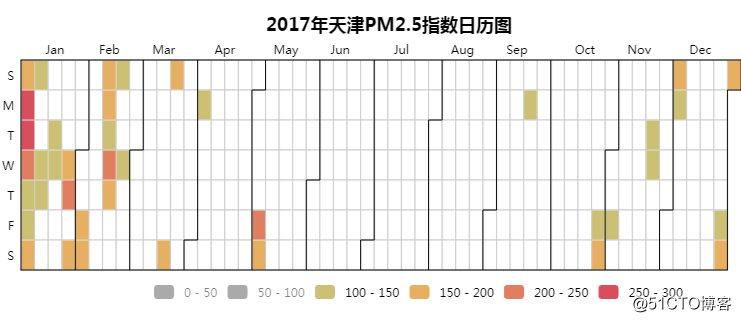
日均PM2.5国家二级标准为75,从上面的热力图看,基本上轻度污染过半了。
另外一月还是重灾区,天色黄黄的...
其实每逢雾霾,基本上就是待宿舍了。而且1月份是考试月,刚好窝宿舍预习课本~
08 天津全年空气质量情况
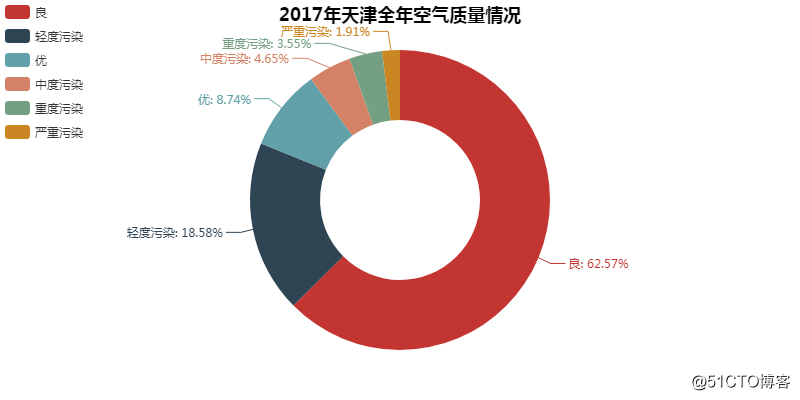
「良」和「轻度污染」占了大头,「优」只能在角落里瑟瑟发抖,足以说明空气之差。
不过该上课还是要上课,谁叫那时宿舍和教室离得近(走过去5分钟不到)。
/ 04 / 北上广深
01 北上广深AQI全年走势图
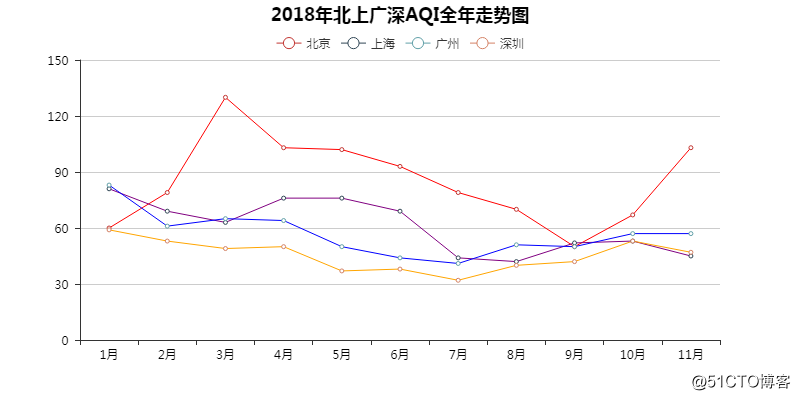
北京月均AQI最低也就50左右,看来今年全年差不多都在「优」以下了。
不过相比前几年,京津冀空气已经好了不少(政策),真的。
上海和广州差不多,深圳与北京算是鲜明对比。
02 北上广深PM2.5全年走势图
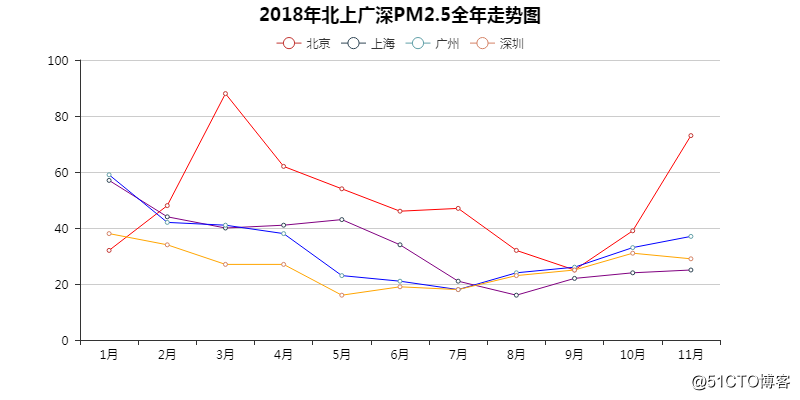
北京一如既往的高调。
03 北上广深全年空气质量情况
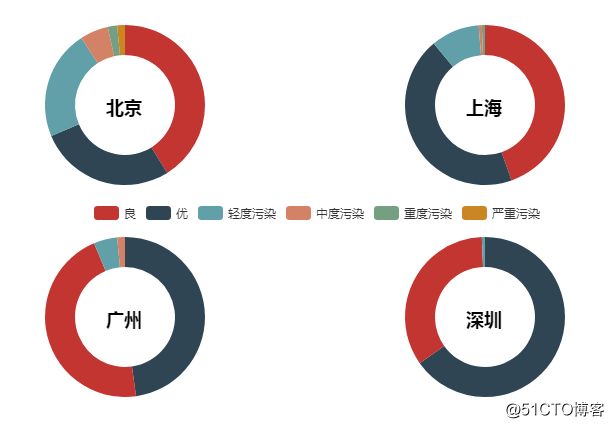
深圳几乎都是「优」和「良」,上海和广州和上面说的一样,北京的「优」已经不少了。
那么你所在的城市空气质量又是如何?
公众号回复天气。即可获取全部源码。
文末点个赞,比心!!!
··· END ···
这篇关于python分析数据走势_Python数据可视化:2018年北上广深空气质量分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





