本文主要是介绍AliMe Chat: A Sequence to Sequence and Rerank based Chatbot Engine论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
阿里小蜜是开放域的问答系统,是检索式问答系统和生成式问答系统的结合体。
框架
直接上流程图,比较清晰
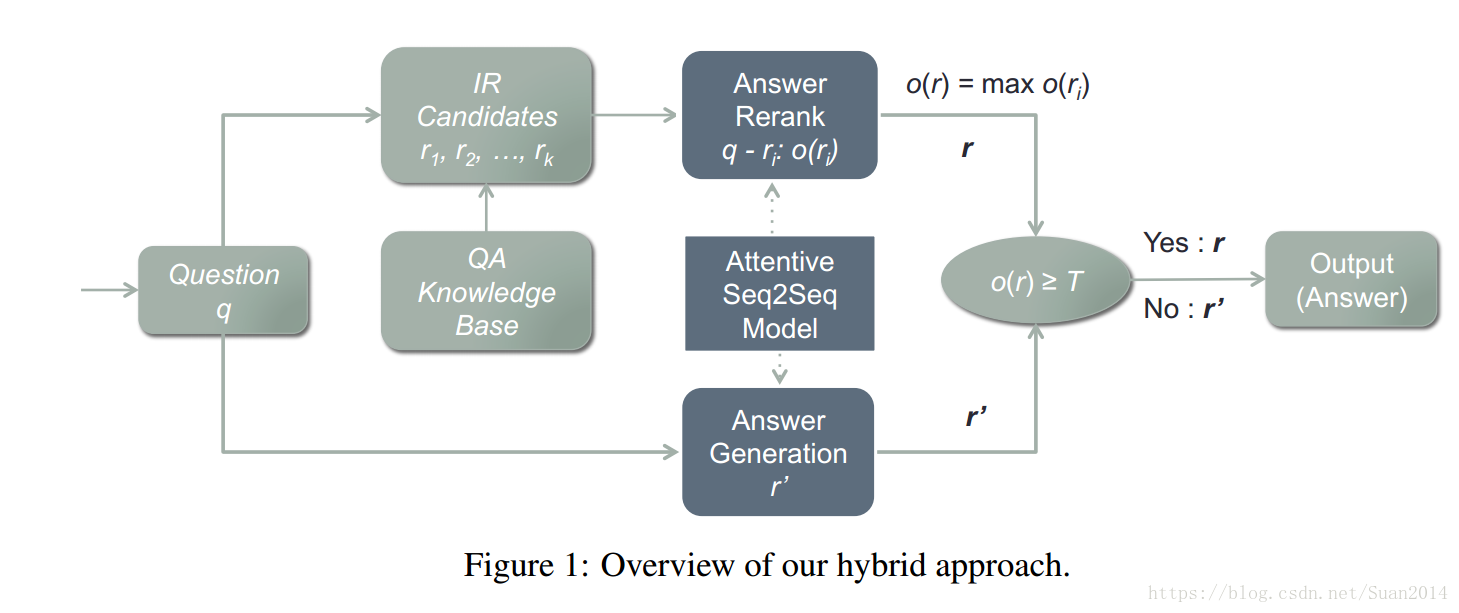
用户输入一个问题q,先采用IR(Information Retrieval)模型检索出一些数据库中的QA对作为候选,然后采用attentive Seq2Seq模型对上述检索出的候选答案进行重新排序,如果排名第一的候选答案的得分高于某个阈值,将此答案作为标准答案输出,否则输出基于attentive Seq2Seq模型生产的答案。
此框架包含三个模型:1)IR模型;2)生成式模型; 3)重排模型(对候选答案进行重排)
模块讲解
IR模型
采用的算法为BM25,主要是计算用户问题和语料库中问题的相似度,将最相似k个(论文中k=10)QA对作为候选集。在采用BM25之前,对语料库中的所有问题进行分词(不做word embedding),然后通过将每个次映射到包含该词的方式对所有问题建立倒序索引(原文:we build an inverted index for the set of all 9,164,834 questions by mapping each word to a set of questions that contain that word,PS:具体做法和这么做得目的我还没想清楚,希望知道的留下自己的idea);对于用户的问题,进行分词、去停用词、利用近义词扩展相关性,然后采用BM25算法找回k个最相似的QA对。
生成式模型
采用的是 attentive Seq2Seq框架。假设,在位置i产生词yi的概率为
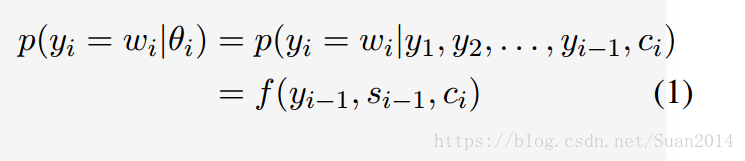
其中f为计算概率的非线性函数,si-1为输出位置i-1处的隐含层状态,ci为取决于的上下文向量,
为输入序列的隐含层状态,
,
,下图所示为i=3,m=4时的情况
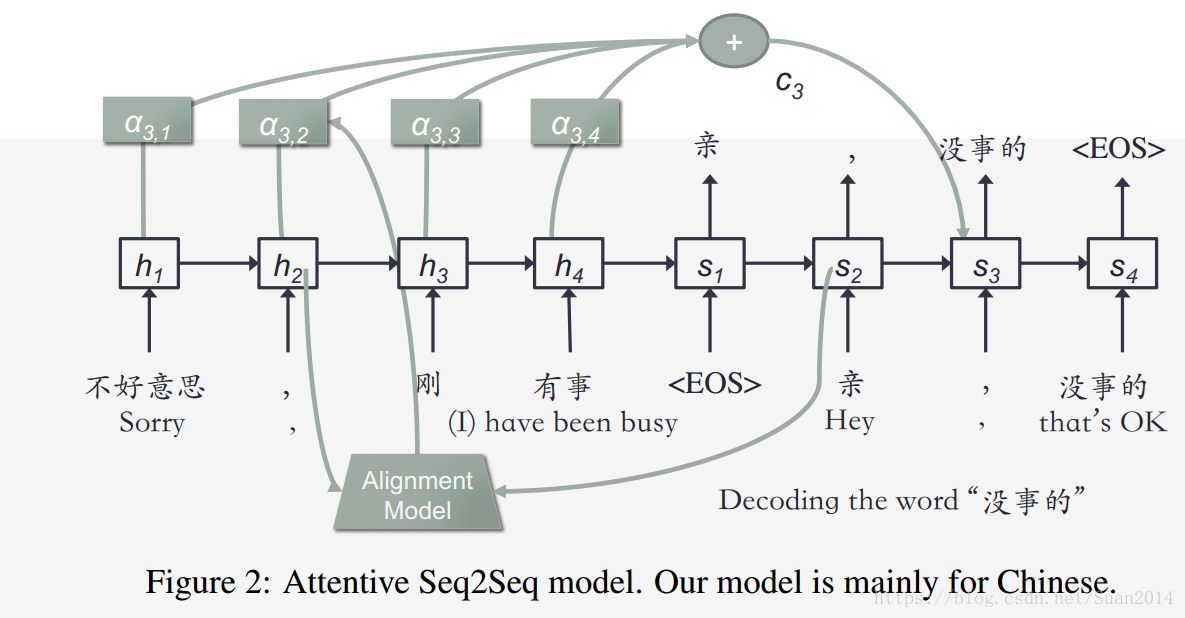
循环网络单元选用的是GRU,输入数据处理采用Bucketing和pading,定义五个(5,5)(5,10)(10,15)(20,30)(45,60)五个buckets,假如问题为4个词,答案为8个词,要采用(5,10),即通过添加“_PAD”符号,将问题扩展为5个词,将答案扩展为10个词放到Attentive Seq2Seq中处理
Attentive Seq2Seq的输出采用Beam search,每time step包含top-k(k=10)
重排模型
还是采用Attentive Seq2Seq模型,采用平均概率作为得分如下,将每个候选答案当作词序列
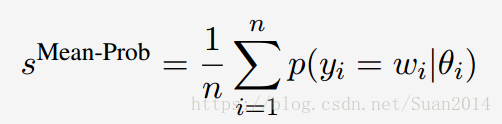
实验
实验就不细讲了,比较简单,无非就是以某些标准和现有的chatbot进行pk然后赢了的故事,直接上一张图

这篇关于AliMe Chat: A Sequence to Sequence and Rerank based Chatbot Engine论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







