本文主要是介绍HMM隐尔马科夫模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
HMM概念
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。
举一个经典的例子:一个东京的朋友每天根据天气{下雨,天晴}决定当天的活动{公园散步,购物,清理房间}中的一种,我每天只能在twitter上看到她发的推“啊,我前天公园散步、昨天购物、今天清理房间了!”,那么我可以根据她发的推特推断东京这三天的天气。在这个例子里,显状态是活动,隐状态是天气。
以下为一个简单的隐马尔科夫模型,如下图所示:

马尔科夫假设和马尔科夫链
随机过程中各个状态St的概率分布,只与它的前一个状态St-1有关,即P(St|S1,S2,S3,…,St-1) = P(St|St-1)。
符合马尔可夫假设的随机过程称为马尔可夫过程,也称为马尔可夫链。
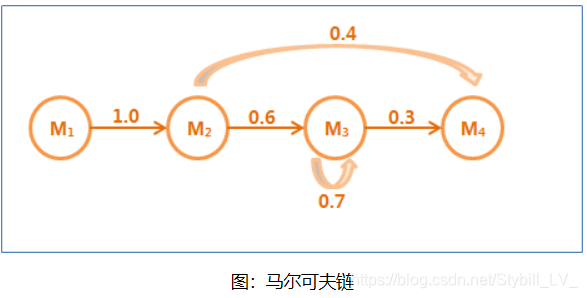
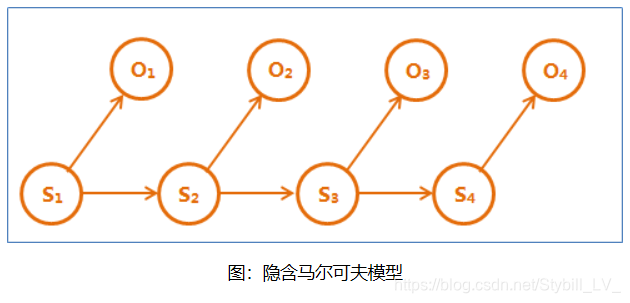
在这个马尔可夫链中,四个圈表示四个状态,每条边表示一个可能的状态转换,边上的权值是转移概率。隐含马尔可夫链是上述马尔可夫链的一个扩展:任一时刻t的状态St是不可见的。所以观察者没法通过观察到一个状态序列S1,S2,S3,…,ST来推测转移概率等参数。但是隐含马尔可夫模型在每个时刻t会输出一个符号Ot,而且Ot和St相关且仅和St相关。这称为独立输出假设。隐含马尔可夫模型的结构如下图,其中隐含的状态S1,S2,S3,…是一个典型的马尔可夫链。鲍姆把这种模型称为“隐含”马尔可夫模型。
基本算法
*1 评估问题: 前向算法
*2 解码问题: Viterbi算法
*3 学习问题: Baum-Welch算法(向前向后算法)
隐含马尔可夫模型的三个基本问题
1. 评估问题
给定观测序列 O=O1O2O3…Ot和模型参数λ=(A,B,π),怎样有效计算某一观测序列的概率,进而可对该HMM做出相关评估。例如,已有一些模型参数各异的HMM,给定观测序列O=O1O2O3…Ot,我们想知道哪个HMM模型最可能生成该观测序列。通常我们利用forward算法分别计算每个HMM产生给定观测序列O的概率,然后从中选出最优的HMM模型。
这类评估的问题的一个经典例子是语音识别。在描述语言识别的隐马尔科夫模型中,每个单词生成一个对应的HMM,每个观测序列由一个单词的语音构成,单词的识别是通过评估进而选出最有可能产生观测序列所代表的读音的HMM而实现的。
2.解码问题
给定观测序列 O=O1O2O3…Ot 和模型参数λ=(A,B,π),怎样寻找某种意义上最优的隐状态序列。在这类问题中,我们感兴趣的是马尔科夫模型中隐含状态,这些状态不能直接观测但却更具有价值,通常利用Viterbi算法来寻找。
这类问题的一个实际例子是中文分词,即把一个句子如何划分其构成才合适。例如,句子“发展中国家”是划分成“发展-中-国家”,还是“发展-中国-家”。这个问题可以用隐马尔科夫模型来解决。句子的分词方法可以看成是隐含状态,而句子则可以看成是给定的可观测状态,从而通过建HMM来寻找出最可能正确的分词方法。
3. 学习问题。
即HMM的模型参数λ=(A,B,π)未知,如何调整这些参数以使观测序列O=O1O2O3…Ot的概率尽可能的大。通常使用Baum-Welch算法以及Reversed Viterbi算法解决。
怎样调整模型参数λ=(A,B,π),使观测序列 O=O1O2O3…Ot的概率最大?
隐马尔可夫模型的五元组
隐马尔可夫模型(HMM)可以用五个元素来描述,包括2个状态集合和3个概率矩阵:
1. 隐含状态 S
这些状态之间满足马尔可夫性质,是马尔可夫模型中实际所隐含的状态。这些状态通常无法通过直接观测而得到。(例如S1、S2、S3等等)
2. 可观测状态 O
在模型中与隐含状态相关联,可通过直接观测而得到。(例如O1、O2、O3等等,可观测状态的数目不一定要和隐含状态的数目一致。)
3. 初始状态概率矩阵 π
表示隐含状态在初始时刻t=1的概率矩阵,(例如t=1时,P(S1)=p1、P(S2)=P2、P(S3)=p3,则初始状态概率矩阵 π=[ p1 p2 p3 ].
4. 隐含状态转移概率矩阵 A。
描述了HMM模型中各个状态之间的转移概率。
其中Aij = P( Sj | Si ),1≤i,,j≤N.
表示在 t 时刻、状态为 Si 的条件下,在 t+1 时刻状态是 Sj 的概率。
5. 观测状态转移概率矩阵 B (英文名为Confusion Matrix,直译为混淆矩阵不太易于从字面理解)。
令N代表隐含状态数目,M代表可观测状态数目,则:
Bij = P( Oi | Sj ), 1≤i≤M,1≤j≤N.
表示在 t 时刻、隐含状态是 Sj 条件下,观察状态为 Oi 的概率。
总结:一般的,可以用λ=(A,B,π)三元组来简洁的表示一个隐马尔可夫模型。隐马尔可夫模型实际上是标准马尔可夫模型的扩展,添加了可观测状态集合和这些状态与隐含状态之间的概率关系。

实例分析:
A 和B是好朋友,但是他们离得比较远,每天都是通过电话了解对方那天作了什么.B仅仅对三种活动感兴趣:公园散步,购物以及清理房间.他选择做什么事情只凭当天天气.A对于B所住的地方的天气情况并不了解,但是知道总的趋势.在B告诉A每天所做的事情基础上,A想要猜测B所在地的天气情况.
A认为天气的运行就像一个马尔可夫链. 其有两个状态 “雨”和”晴”,但是无法直接观察它们,也就是说,它们对于A是隐藏的.每天,B有一定的概率进行下列活动:”散步”, “购物”, 或 “清理”. 因为B会告诉A他的活动,所以这些活动就是A的观察数据.这整个系统就是一个隐马尔可夫模型HMM.
A知道这个地区的总的天气趋势,并且平时知道B会做的事情.也就是说这个隐马尔可夫模型的参数是已知的.下面是概率转移矩阵和两种天气下各种活动的概率:
雨天 晴天
雨天 0.7 0.3
晴天 0.4 0.6
散步 购物 清理
雨天 0.1 0.4 0.5
晴天 0.6 0.3 0.1
下面是一段程序来描述各个变量。
#状态数目,两个状态:雨或晴
states = (‘Rainy’, ‘Sunny’)
#每个状态下可能的观察值
observations = (‘walk’, ‘shop’, ‘clean’)
#初始状态空间的概率分布
start_probability = {‘Rainy’: 0.6, ‘Sunny’: 0.4}
#与时间无关的状态转移概率矩阵
transition_probability = {
’Rainy’ : {‘Rainy’: 0.7, ‘Sunny’: 0.3},
’Sunny’ : {‘Rainy’: 0.4, ‘Sunny’: 0.6},
}
#给定状态下,观察值概率分布,发射概率
emission_probability = {
’Rainy’ : {‘walk’: 0.1, ‘shop’: 0.4, ‘clean’: 0.5},
’Sunny’ : {‘walk’: 0.6, ‘shop’: 0.3, ‘clean’: 0.1},
}在这些代码中,start_probability代表了A对于B第一次给她打电话时的天气情况的不确定性(A知道的只是那个地方平均起来下雨多些).在这里,这个特定的概率分布并非平衡的,平衡概率应该接近(在给定变迁概率的情况下){‘Rainy’: 0.571, ‘Sunny’: 0.429}。 transition_probability 表示马尔可夫链下的天气变迁情况,在这个例子中,如果今天下雨,那么明天天晴的概率只有30%.代码emission_probability 表示了B每天作某件事的概率.如果下雨,有 50% 的概率他在清理房间;如果天晴,则有60%的概率他在外头散步。
更多内容,还可以参考:https://www.cnblogs.com/skyme/p/4651331.html
这篇关于HMM隐尔马科夫模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








