本文主要是介绍静态时序分析:静态时序分析的原理及其两种模式PBA、GBA,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
相关阅读
静态时序分析![]() https://blog.csdn.net/weixin_45791458/category_12567571.html?spm=1001.2014.3001.5482
https://blog.csdn.net/weixin_45791458/category_12567571.html?spm=1001.2014.3001.5482
静态时序分析有两种模式:PBA(Path Based Analysis)和GBA(Graph Based Analysis),PBA是基于路径的分析模式而GBA则是基于图的分析模式。在Design Compiler中,时序分析是使用GBA模式;而在PrimeTime中,既可以使用默认的GBA模式也可以使用PBA模式进行时序分析。下面将详细讨论这两种模式的区别与联系。
首先我们需要知道一条时序路径是由一条一条的时序弧组成的,而时序弧分为单元内部时序弧(Cell Arc)和线网弧(Net Arc)。Cell Arc指的是从单元的一个输入引脚到一个输出引脚的时序弧而Net Arc指的是单元之间的互连时序弧,下面将举例说明。
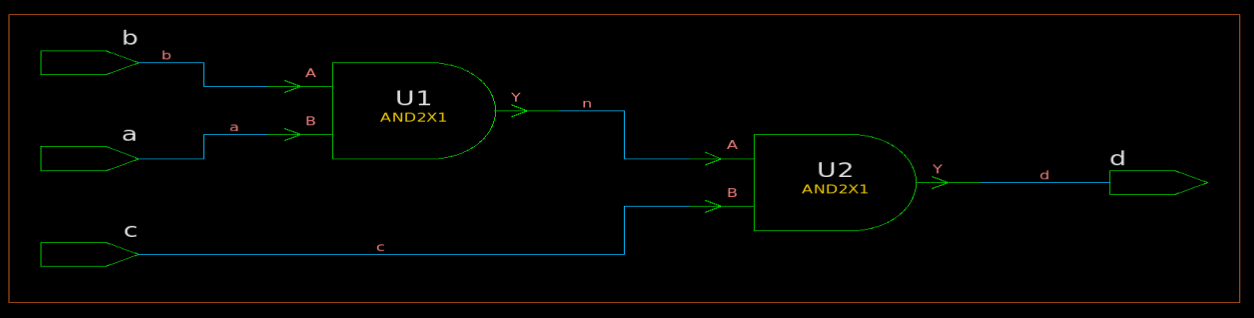
图1 一个简单的例子
图1是一个简单的例子,其中有两个标准单元两输入与门U1和U2。图中一共存在九条时序弧,分别为:输入端口b到U1的输入引脚A的Net Arc、输入端口a到U1的输入引脚B的Net Arc、U1的输入引脚A到U1的输出引脚Y的Cell Arc、U1的输入引脚B到U1的输出引脚Y的Cell Arc、U1的输出引脚Y到U2的输入引脚A的Net Arc、输入端口c到U2的输入引脚B的Net Arc、U2的输入引脚A到U2的输出引脚Y的Cell Arc、U2的输入引脚B到U2的输出引脚Y的Cell Arc、U2的输出引脚Y到输出端口d的Net Arc。
时序路径是由上面的九条时序弧组成的,时序弧的起点只能是输入端口或寄存器引脚,时序弧的终点只能是输出端口或寄存器输入引脚。因此图1中存在三条时序路径,分别为:
- 输入端口b到输出端口d的时序路径,它由输入端口b到U1的输入引脚A的Net Arc、U1的输入引脚A到U1的输出引脚Y的Cell Arc、U1的输出引脚Y到U2的输入引脚A的Net Arc、U2的输入引脚A到U2的输出引脚Y的Cell Arc和U2的输出引脚Y到输出端口d的Net Arc这五条时序弧组成。
- 输入端口a到输出端口d的时序路径,它由输入端口a到U1的输入引脚A的Net Arc、U1的输入引脚A到U1的输出引脚Y的Cell Arc、U1的输出引脚Y到U2的输入引脚A的Net Arc、U2的输入引脚A到U2的输出引脚Y的Cell Arc和U2的输出引脚Y到输出端口d的Net Arc这五条时序弧组成。
- 输入端口c到输出端口d的时序路径,它由输入端口c到U2的输入引脚B的Net Arc、U2的输入引脚B到U2的输出引脚Y的Cell Arc和U2的输出引脚Y到输出端口d的Net Arc这三条时序弧组成。
GBA模式和PBA模式决定了在时序分析时,每条时序路径是半独立地进行分析还是完全独立地进行分析,下面我们首先说明时序路径大致是如何分析的。
用第一条时序路径举例,在Design Compiler进行时序分析时,首先会在输入端口b给出一个理想的上升沿和理想的下降沿(它们是默认的),并将这个翻转沿着时序路径传播,在传播过程中,不在路径中的单元的其他输入引脚需要取一组特定的值以使翻转传播(对于非单调的时序弧,需要取更多组特定的值,因为其在不同情况下有多种单调性),例如对于与门U1,其输入引脚B在进行分析时需要取1;对于与门U2,其输入引脚B在进行分析时也需要取1。传播过程中,要注意各单元时序弧的单调性(见上一章静态时序分析:时序弧以及其时序敏感(单调性)-CSDN博客)由于U1/U2是正单调的,输入端口的上升\下降沿会导致输出的上升/下降沿,因此这条时序路径的翻转情况可能是两种:输入端口b上升沿,一路沿时序路径传播导致输出端口d上升沿;输入端口b下降沿,一路沿时序路径传播导致输出端口d下降沿。注意,这个取值并不一定会真实能取到(即不考虑逻辑),只是为了分析时序路径,例如图2所示的情况。
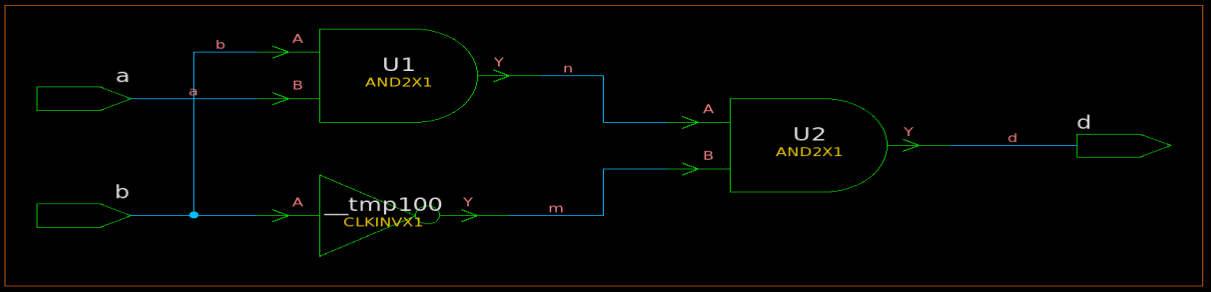
图2 一个愚蠢的例子
在图2中分析从输入端口a到输出端口d的时序路径时,U1和U2的B端口根本不可能同时取1,甚至可以发现输出d恒为0(d=abb'),但是Design Compiler依然会傻傻地将输入端口a的上升/下降沿传播至输出端口d并进行时序分析(在这里,我们假设Design Compiler不会对此进行逻辑优化)。
有了上面的基础,下面我们进入正题。在使用PBA模式分析图1中的第一条时序路径时,假设输入端口b给出理想上升沿(转换时间为0),上升沿翻转沿线网b传播至U1的输入引脚A,此时延迟为0(假设没有线网延迟),转换时间为0(假设没有转换时间衰减)。DC根据单元库中的U1器件的非线性延迟模型(NLDM)查表得出U1的单元延迟(从输入引脚A到输出引脚Y,假设为0.5ns)和输出引脚Y的转换时间(假设为0.1ns),接着上升沿翻转从U1的输出引脚Y传播至U2的输入引脚A,此时延迟为0.5ns,翻转时间为0.1ns,DC根据单元库中的U2器件的非线性延迟模型(NLDM)查表得出U2的单元延迟(从输入引脚A到输出引脚Y,假设为0.4ns)和输出引脚Y的转换时间(假设为0.05ns),最终翻转从U2的输出引脚Y传播至输出端口d。因此这条时序路径的延迟为0.5+0.4=0.9ns,而输出的转换时间为0.05ns。对于输入a是下降沿的情况,也是如此分析。我们可以注意到,第一条时序路径的分析是和其他时序路径无关的,这就是PBA模式的特点。
在使用GBA模式分析图1中的第一条时序路径时,大部分过程与PBA模式是一样的,但是不同的是,引脚Y的转换时间不只取决于U1的输入引脚A,而是与输入引脚B也有关。假设进行的是最大延迟分析(建立时间),DC会选择引脚A和引脚B导致的最差的转换时间作为Y引脚的转换时间,即Y引脚的上升翻转时间是A引脚的上升沿导致的Y引脚的上升翻转时间和B引脚的上升沿导致的Y引脚的上升翻转时间中最大的那个。对于输入端口b的下降沿在传播时也是如此分析,即Y引脚的下降翻转时间是A引脚的下降沿导致的Y引脚的下降翻转时间和B引脚的下降沿导致的Y引脚的下降翻转时间中最大的那个。B引脚的上升沿和下降沿相关的数据是在输入端口a到输出端口d的时序路径即第二条时序路径的计算中得到的。如果进行的是最小延迟分析(保持时间),DC会选择引脚A和引脚B导致的最好的转换时间作为Y引脚的转换时间。
如何验证上述原理呢?可以在Design Compiler中使用report_delay_calculation命令报告U1的输入引脚A和B到输出引脚Y的转换时间的计算过程,并使用report_net命令报告线网n即U1的输出引脚Y的转换时间。其实当使用report_net命令时就可以发现,线网n会存储两组上升沿\下降沿转换时间,分别用于建立时间和保持时间的时序分析,即使用GBA模式。而如果是PBA模式,线网n需要为每个输入引脚保存一组上升沿\下降沿转换时间(在此例中是两组),这在线网扇入大时会显著提升分析难度与时间。
综上所述,GBA模式和PBA模式中,PBA模式更为准确但耗时长(实际上就算是PBA也是保守的,如图2所示的那样),而GBA模式更保守但更快。顺带一提,动态时序分析(时序仿真)才是最准确的时序分析方式。
这篇关于静态时序分析:静态时序分析的原理及其两种模式PBA、GBA的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






